单目视觉里程计定位方法及系统与流程
[0001]
本发明涉及计算机视觉技术领域,特别涉及一种slam(simultaneous localization and mapping,同步定位与建图)的基于局部全局信息融合和动态物体感知的单目视觉里程计定位方法及系统。
背景技术:
[0002]
视觉里程计是移动机器人、自主导航以及增强现实中的重要环节。视觉里程计按照使用的相机数量可以分为单目视觉里程计(monocular vo)和双目视觉里程计(stereo vo)。单目vo通常比双目vo更具挑战性,但是因其只需要一架相机,更加轻巧、便宜而得到广泛的研究。经典的视觉里程计算法包括相机矫正、特征检测、特征匹配、外点剔除、运动估计、尺度估计以及后端优化。此类算法在大部分情况下都能取得较好的效果,但是面对遮挡、光照变化大、无纹理等场景仍然会存在失败的情况。
[0003]
近年来,深度学习技术已成功运用在人脸识别、目标跟踪、语音识别、机器翻译等方面。以卷积神经网络为代表的深度学习方法在计算机视觉领域发挥了非常重要的作用,这些深度网络在提取图片特征,找出潜在规律等方面比传统方法效果显著,所以很多学者考虑将深度学习应用到位姿估计等领域,直接让深度网络学习图片之间的几何关系,实现端到端的位姿估计。这种端到端的方式完全摒弃了传统方法中的特征提取、特征匹配、相机标定、图优化等步骤,根据输入图片直接得到相机姿态。尽管卷积网络能够应对一些极端情况,但是整体精度还是低于传统方法,此外网络的泛化能力也是影响深度网络实际应用的重要原因。此外,大多数深度学习方法并没有考虑场景中动态物体的影响,导致定位精度也比较低。
技术实现要素:
[0004]
为了解决现有技术中的上述问题,即为了提高定位精度,本发明的目的在于提供一种单目视觉里程计定位方法及系统。
[0005]
为解决上述技术问题,本发明提供了如下方案:
[0006]
一种单目视觉里程计定位方法,所述单目视觉里程计定位方法包括:
[0007]
获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0008]
根据各视频序列,建立单目视觉里程计定位模型;
[0009]
其中,所述根据各视频序列,建立单目视觉里程计定位模型,具体包括:
[0010]
对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0011]
通过flownet编码器,从各堆叠图像中提取高维特征;
[0012]
通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0013]
根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿;
[0014]
基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0015]
可选地,所述通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息,具体包括:
[0016]
将各高维特征分别和k组3d卷积核进行卷积操作,得到不同长度的局部信息,其中第k组卷积核大小为k
×3×
3,且
[0017]
基于bi-convlstm,从各高维特征中提取视频序列的全局信息。
[0018]
可选地,相对位姿包括位移和姿态;
[0019]
所述根据各视频序列,建立单目视觉里程计定位模型还包括:
[0020]
根据以下公式,计算位移损失值l
trans
和姿态损失值l
rot
:
[0021][0022][0023]
其中,为预测出的位移,为预测出的角度,p
t
,φ
t
为对应真值,t表示图像序号,t=1,2,
…
,t,t表示图像数量;表示二范数;
[0024]
根据位移损失值l
trans
和姿态损失值l
rot
确定总损失值;
[0025]
根据所述总损失值调整所述单目视觉里程计定位模型。
[0026]
可选地,所述总损失值还包括光流损失值、约束损失值及极对损失值;
[0027]
所述根据各视频序列,建立单目视觉里程计定位模型还包括:
[0028]
通过光流和掩膜估计模块,根据各相邻帧图像及flownet编码器输出的光流,确定光流损失值l
ptotometric
、约束损失值l
reg
及极对损失值l
e
;
[0029]
根据位移损失值l
trans
、姿态损失值l
rot
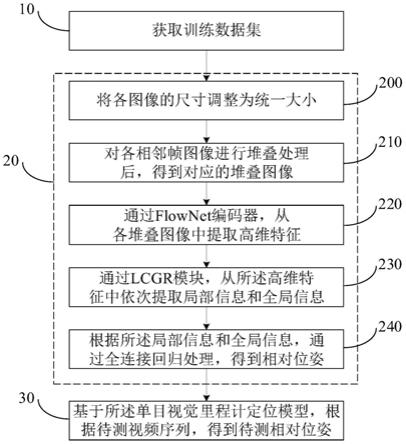
、光流损失值l
ptotometric
、约束损失值l
reg
及极对损失值l
e
确定总损失值。
[0030]
可选地,根据以下公式,确定所述光流损失值l
ptotometric
、约束损失值l
reg
、极对损失值l
e
及总损失值l
total
:
[0031][0032][0033][0034]
l
e
=|q
t
a-t
[r]
×
rk-1
p|;
[0035]
l
total
=l
trans
+100l
rot
+l
ptotometric
+l
e
+l
reg
;
[0036]
其中,(i,j)表示像素坐标位置,i
t
表示第t帧图像,i
′
(i,j,t+1)表示两帧连续的图像i(i,j,t)和i(i,j,t+1)以及flownet编码器输出光流合成的图像;c(i,j)是(i,j)位置的掩膜值,表示该像素能被成功合成的置信度;两帧连续的图像i(i,j,t)和i(i,j,t+1),通过估计出的光流提供源图像和目标图像之前的像素对应关系,q是目标图像中的像素位置,p表示对应的在源图像中的像素位置,a是相机内参,r和r是源图像和目标图像之间的相对位姿。
[0037]
可选地,所述单目视觉里程计定位方法还包括:
[0038]
将各图像的尺寸调整为统一大小。
[0039]
为解决上述技术问题,本发明还提供了如下方案:
[0040]
一种单目视觉里程计定位系统,所述单目视觉里程计定位系统包括:
[0041]
获取单元,用于获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0042]
建模单元,用于根据各视频序列,建立单目视觉里程计定位模型;
[0043]
其中,所述建模单元包括:
[0044]
堆叠模块,用于对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0045]
特征提取模块,用于通过flownet编码器,从各堆叠图像中提取高维特征;
[0046]
信息提取模块,用于通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0047]
位姿确定模块,用于根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿;
[0048]
定位单元,用于基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0049]
可选地,所述建模单元包括:
[0050]
预处理模块,分别与所述获取单元及堆叠模块连接,用于将各图像的尺寸调整为统一大小,并发送至所述堆叠模块。
[0051]
为解决上述技术问题,本发明还提供了如下方案:
[0052]
一种单目视觉里程计定位系统,包括:
[0053]
处理器;以及
[0054]
被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器执行以下操作:
[0055]
获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0056]
根据各视频序列,建立单目视觉里程计定位模型;
[0057]
其中,所述根据各视频序列,建立单目视觉里程计定位模型,具体包括:
[0058]
对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0059]
通过flownet编码器,从各堆叠图像中提取高维特征;
[0060]
通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0061]
根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿;
[0062]
基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0063]
为解决上述技术问题,本发明还提供了如下方案:
[0064]
一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,所述一个或多个程序当被包括多个应用程序的电子设备执行时,使得所述电子设备执行以下操作:
[0065]
获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0066]
根据各视频序列,建立单目视觉里程计定位模型;
[0067]
其中,所述根据各视频序列,建立单目视觉里程计定位模型,具体包括:
[0068]
对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0069]
通过flownet编码器,从各堆叠图像中提取高维特征;
[0070]
通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0071]
根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿;
[0072]
基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0073]
根据本发明的实施例,本发明公开了以下技术效果:
[0074]
本发明通过flownet编码器从各堆叠图像中提取高维特征,通过lcgr模块从高维特征中依次提取局部信息和全局信息,进而通过全连接回归处理,得到相对位姿,建立单目视觉里程计定位模型,通过单目视觉里程计定位模型对待测视频序列进行定位,可准确确定相对位姿,提高定位精度。
附图说明
[0075]
图1是本发明单目视觉里程计定位方法的流程图;
[0076]
图2是本发明单目视觉里程计定位系统的模块结构示意图。
[0077]
符号说明:
[0078]
获取单元—1,建模单元—2,预处理模块—20,堆叠模块—21,特征提取模块—22,信息提取模块—23,位姿确定模块—24,定位单元—3。
具体实施方式
[0079]
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
[0080]
本发明的目的是提供一种单目视觉里程计定位方法,通过flownet编码器从各堆叠图像中提取高维特征,通过lcgr模块从高维特征中依次提取局部信息和全局信息,进而通过全连接回归处理,得到相对位姿,建立单目视觉里程计定位模型,通过单目视觉里程计定位模型对待测视频序列进行定位,可准确确定相对位姿,提高定位精度。
[0081]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0082]
如图1所示,本发明单目视觉里程计定位方法包括:
[0083]
步骤10:获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0084]
步骤20:根据各视频序列,建立单目视觉里程计定位模型;
[0085]
步骤30:基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0086]
其中,在步骤20中,所述根据各视频序列,建立单目视觉里程计定位模型,具体包括:
[0087]
步骤210:对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0088]
步骤220:通过flownet(flow networks,光流网络)编码器,从各堆叠图像中提取高维特征;
[0089]
步骤230:通过lcgr(local convolution and global recurrent neural network局部卷积和全局循环神经网络)模块,从所述高维特征中依次提取局部信息和全局信息;
[0090]
步骤240:根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿。
[0091]
优选地,所述根据各视频序列,建立单目视觉里程计定位模型,还包括:步骤200:将各图像的尺寸调整为统一大小。在本实施例中,所述尺寸为384*1280像素。
[0092]
在步骤220中,给定从t到t+n的n+1帧连续的图像,堆叠后,通过flownet编码器可以获得n组6
×
20
×
1024的高维特征。
[0093]
在步骤230中,所述通过lcgr模块(如表1所示),从所述高维特征中依次提取局部信息和全局信息,具体包括:
[0094]
步骤231:将各高维特征分别和k组3d卷积核进行卷积操作,得到不同长度的局部信息,其中第k组卷积核大小为k
×3×
3,且以保证卷积后能够得到更加紧凑的高维特征。
[0095]
在本实施例中,k=2,卷积的步长均为1,c
k
均为128。
[0096]
表1
[0097][0098]
步骤232:基于bi-convlstm(bidirectional convolutional long short-term memory,双向长短时记忆卷积),从各高维特征中提取视频序列的全局信息。
[0099]
进一步地,相对位姿包括位移和姿态。
[0100]
在步骤240中,所述根据各视频序列,建立单目视觉里程计定位模型还包括:
[0101]
步骤241:根据以下公式,计算位移损失值l
trans
和姿态损失值l
rot
:
[0102]
[0103][0104]
其中,为预测出的位移,为预测出的角度,p
t
,φ
t
为对应真值,t表示图像序号,t=1,2,
…
,t,t表示图像数量;表示二范数;
[0105]
步骤242:根据位移损失值l
trans
和姿态损失值l
rot
确定总损失值;
[0106]
步骤243:根据所述总损失值调整所述单目视觉里程计定位模型。
[0107]
进一步地,所述总损失值还包括光流损失值、约束损失值及极对损失值。
[0108]
对应地,所述根据各视频序列,建立单目视觉里程计定位模型还包括:
[0109]
通过光流和掩膜估计模块,根据各相邻帧图像及flownet编码器输出的光流,确定光流损失值l
ptotometric
、约束损失值l
reg
及极对损失值l
e
;
[0110]
根据位移损失值l
trans
、姿态损失值l
rot
、光流损失值l
ptotometric
、约束损失值l
reg
及极对损失值l
e
确定总损失值。
[0111]
其中,根据以下公式,确定所述光流损失值l
ptotometric
、约束损失值l
reg
、极对损失值l
e
及总损失值l
total
:
[0112][0113][0114][0115]
l
e
=|q
t
a-t
[r]
×
rk-1
p|;
[0116]
l
total
=l
trans
+100l
rot
+l
ptotometric
+l
e
+l
reg
;
[0117]
其中,(i,j)表示像素坐标位置,i
t
表示第t帧图像,i
′
(i,j,t+1)表示两帧连续的图像i(i,j,t)和i(i,j,t+1)以及flownet编码器输出光流合成的图像;c(i,j)是(i,j)位置的掩膜值,表示该像素能被成功合成的置信度;两帧连续的图像i(i,j,t)和i(i,j,t+1),通过估计出的光流提供源图像和目标图像之前的像素对应关系,q是目标图像中的像素位置,p表不对应的在源图像中的像素位置,a是相机内参,r和r是源图像和目标图像之间的相对位姿。
[0118]
其中,光流和掩膜估计模块:给定两张连续的图片i(i,j,t)和i(i,j,t+1)以及flownet编码器输出的光流,可以合成:
[0119]
i
′
(i,j,t+1)=i(i+u
i,j
,j+v
i,j
,t),
[0120]
光度误差可以通过计算合成的i
′
(i,j,t+1)和原始的i(i,j,t+1)得到,即:
[0121][0122]
其中u,v是光流的水平和垂直分量。这个过程可以通过可微分的双线性插值实现。给定一个序列的图片i1,i2,...i
t
,总的损失函数为:
[0123][0124]
为了缓解场景中光度不一致区域的误差对梯度传播的影响,光流预测部分同时估计一个掩膜,掩膜的值表示每个像素能够被成功合成的概率。掩膜通过在flownet最后一层之前添加一个分支的卷积层估计得到,该卷积层的激活函数采用sigmoid函数。最后的损失函数变为:
[0125][0126]
此外,为了防止c(i,j)被优化为0,需要约束c(i,j)为1,这个约束的损失为:
[0127][0128]
为了解决场景中动态物体带来的问题,本发明利用位姿真值构造对极约束显式地促使网络对运动物体区域输出较低的掩膜值来缓解对梯度传播的影响。给定相邻帧两张图像,估计出的光流提供源图像和目标图像之间的像素对应关系。假设g是目标图像中的像素位置,其对应的在源图像中的像素位置为p,对极约束可以表示为:
[0129]
q
t
k-t
[t]
×
rk-1
p=0。
[0130]
最终的对极损失为:
[0131]
l
e
=|q
t
a-t
[r]
×
rk-1
p|。
[0132]
在kittivo/slam上训练本发明中的单目视觉里程计定位模型。其中,数据集包含22个视频序列,其中00~10提供了位姿真值,11~21只提供了原始的视频序列。这22个视频序列中包含很多动态物体,这对于单目vo非常具有挑战性。训练中的图片均被调整为384*1280像素,初始学习率为0.0001,batch size为2,每10个epoch,学习率减半。
[0133]
此外,本发明还提供一种单目视觉里程计定位系统,可提高定位精度。
[0134]
如图2所示,本发明单目视觉里程计定位系统包括获取单元1、建模单元2及定位单元3。
[0135]
其中,所述获取单元1用于获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0136]
所述建模单元2用于根据各视频序列,建立单目视觉里程计定位模型;
[0137]
所述定位单元3用于基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0138]
优选地,所述建模单元2包括堆叠模块21、特征提取模块22、信息提取模块23及位姿确定模块24。具体地,
[0139]
所述堆叠模块21用于对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0140]
所述特征提取模块22用于通过flownet编码器,从各堆叠图像中提取高维特征;
[0141]
所述信息提取模块23用于通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0142]
所述位姿确定模块24用于根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿。
[0143]
进一步地,所述建模单元2还包括预处理模块20,所述预处理模块20分别与所述获取单元1及堆叠模块21连接,述预处理模块20用于将各图像的尺寸调整为统一大小,并发送至所述堆叠模块21。
[0144]
此外,本发明还提供了如下方案:一种单目视觉里程计定位系统,包括:
[0145]
处理器;以及
[0146]
被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器执行以下操作:
[0147]
获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0148]
根据各视频序列,建立单目视觉里程计定位模型;
[0149]
其中,所述根据各视频序列,建立单目视觉里程计定位模型,具体包括:
[0150]
对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0151]
通过flownet编码器,从各堆叠图像中提取高维特征;
[0152]
通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0153]
根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿;
[0154]
基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0155]
此外,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,所述一个或多个程序当被包括多个应用程序的电子设备执行时,使得所述电子设备执行以下操作:
[0156]
获取训练数据集,所述训练数据集包括多个视频序列,各视频序列包括多帧连续图像;
[0157]
根据各视频序列,建立单目视觉里程计定位模型;
[0158]
其中,所述根据各视频序列,建立单目视觉里程计定位模型,具体包括:
[0159]
对各相邻帧图像进行堆叠处理后,得到对应的堆叠图像;
[0160]
通过flownet编码器,从各堆叠图像中提取高维特征;
[0161]
通过lcgr模块,从所述高维特征中依次提取局部信息和全局信息;
[0162]
根据所述局部信息和全局信息,通过全连接回归处理,得到相对位姿;
[0163]
基于所述单目视觉里程计定位模型,根据待测视频序列,得到待测相对位姿。
[0164]
相对于现有技术,本发明单目视觉里程计定位系统、计算机可读存储介质与上述单目视觉里程计定位方法的有益效果相同,在此不再赘述。
[0165]
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域
技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1