一种运动目标视频定位测速系统及方法与流程
1.本发明涉及一种运动目标视频定位测速系统及方法,属于电子行业智能测量领域,提供了运动参数,改进训练方法。
背景技术:
2.目前,目标视频定位技术多用于工业场景,测量幅面较小,而针对大幅面的运动场景进行定位测速的应用较少。目标跟踪包含目标检测和跟踪两部分,其中检测是跟踪的基础。一种常用的方式为采取yolo+deepsort的方法,其中yolo实现目标检测,而deepsort实现目标跟踪。其中由于yolo本身存在定位精度不高的问题,从而不适用于需要高精度定位的场合。
技术实现要素:
3.本发明所解决的技术问题是:克服现有技术的不足,提供一种运动目标视频定位测速系统及方法,提高目标检测定位精度。
4.本发明的技术方案是:一种运动目标视频定位测速系统,该系统包括m个相机、运动目标检测跟踪模块、运动目标速度识别模块;m个相机的总视场覆盖运动目标的整个运动场景,m大于1;
5.相机,在同步采集指令的驱动下,拍摄视场内的图像,形成图像数据帧发送给运动目标检测跟踪模块;
6.运动目标检测跟踪模块,采集各相机拍摄的图像,并记录图像采集时间,对各相机拍摄的图像进行畸变校正,采用yolo模型对同一时刻拍摄的每一张校正后的图像进行目标检测,得到图像中所有运动目标在像素坐标系下的粗略边界框,再基于边缘检测方法,得到各运动目标在像素坐标系下的精确位置和精准边界框,之后,采用deepsort算法对同一运动目标不同时刻的精准边界框进行匹配,实现不同时刻各运动目标的精准边界框的跟踪;通过透视投影矩阵将每个运动目标在像素坐标系下的坐标转换为对应相机视场覆盖区域世界坐标系下的坐标,根据各相机视场覆盖区域间的位置关系,计算出各运动目标不同时刻在运动场景全局世界坐标系下的坐标,并发送给运动目标速度识别模块;
7.运动目标速度识别模块,将各运动目标不同时刻在运动场景全局世界坐标系下的坐标序列滤波去噪后进行差分处理,得到运动目标在运动场景世界坐标系下的速度。
8.所述运动目标检测跟踪模块采用计算机视觉库opencv中的undistort函数对各相机拍摄的图像进行畸变校正,所述undistort函数如下:
9.voidundistort(inputarraysrc,outputarraydst,inputarraycameramatrix,inputarraydistcoeffs,inputarraynewcameramatrix)
10.src为原始图像的像素矩阵,dst为校正后的图像的像素矩阵;
11.cameramatrix为相机内参:
[0012][0013]
其中,f
x
=f/dx称为相机x轴方向上的归一化焦距,fy=f/dy称为相机y 轴方向上的归一化焦距,单位为像素;f为相机的焦距,dx、dy分别为像素在相机x、y轴方向上的物理尺寸;(u0,v0)为图像中心在像素坐标系坐标,单位为像素。
[0014]
distcoeffs为畸变参数:
[0015]
distcoeffs=[k1,k2,p1,p2,k3]
[0016]
其中,k1为径向畸变二次项系数、k2为径向畸变四次项系数、k3为径向畸变六次项系数;p1、p2分别为第一切向畸变参数、第二切向畸变参数,inputarraynewcameramatrix为全0矩阵。
[0017]
所述相机内参cameramatrix和畸变参数distcoeffs的标定过程如下:
[0018]
s1.1、准备一个张正友标定法棋盘格作为标定板,用相机对标定板进行不同角度的拍摄,得到一组n张棋盘格图像,15≤n≤30;
[0019]
s1.2、采用matlab工具箱中的相机标定工具camera calibration,加载步骤s1.1拍摄得到的n张棋盘格图像,对棋盘格中的角点进行自动检测,获得角点在像素坐标系下的坐标;
[0020]
s1.3、将棋盘格的单元格实际尺寸输入至标定工具camera calibration,由标定工具camera calibration计算得到角点的世界坐标;
[0021]
s1.4、标定工具camera calibration根据n张图像中的角点在像素坐标系下的坐标与在世界坐标系下的坐标,进行参数解算,得到相机内参 intrinsicmatrix、畸变参数distcoeffs。
[0022]
优选地,运动目标检测跟踪模块调用计算机视觉库opencv中的perspectivetransform函数将运动目标在像素坐标系下的坐标转换为相机视场覆盖区域世界坐标系下的坐标。
[0023]
优选地,所述透视投影矩阵的获取过程如下:
[0024]
s2.1、在运动目标的运动场景布置好相机并固定,使得m个相机的总视场覆盖运动目标的整个运动场景,且相邻相机画面有重叠区域;
[0025]
s2.2、定义运动场景的场地平面为全局世界坐标系的xoy平面,在场地平面布置r行c列标志点,标志点的行与全局世界坐标系的x轴平行,标志点的列与全局世界坐标系的y轴平行,每个标志点上设有菱形图案,菱形图案相对的顶点连线与全局世界坐标系的x轴、y轴平行,菱形中心点位置作为标志的位置;每个相机视场内包含a2个标志点,标志点以a*a矩阵形式均匀分布,位于周边的各标志点靠近相机视场边缘,相邻相机视场重叠区域包含a个公共标志点;
[0026]
s2.3、对于每个相机,选定相机视场内左上角的标志点作为原点,即坐标为(0,0),建立相机视场区域世界坐标系,测量各个标志点相对于原点的位置,得到a2个标志点在相机视场区域世界坐标系下的坐标;
[0027]
s2.4、通过相机拍摄,每个相机得到包含a2个标志点的一张图像;
[0028]
s2.5、将相机拍摄的图像进行畸变校正;
[0029]
s2.6、确定每个相机拍摄的畸变校正后图像中的a2个标志点在像素坐标系下的坐标;
[0030]
s2.7、对于每个相机,将每个标志点在像素坐标系下的坐标和对应相机视场区域世界坐标系下的坐标,记为一组坐标,a2组坐标传入计算机视觉库 opencv中的findhomography函数,计算出相机的透视投影矩阵。
[0031]
优选地,确定畸变校正后图像中a2个标志点在像素坐标系下的坐标的具体方法为:
[0032]
通过matlab显示畸变校正后图像,使用impixelinfo命令显示鼠标指向的点在图像中的位置,将鼠标指向到菱形标志的中心,得到a2个标志在图像中的位置,将图像中左上角的菱形标志的中心定义为像素坐标系原点,坐标记为(0,0),将其余a
2-1个非原点标志点与原点的相对位置,记为其像素坐标系下的坐标。
[0033]
优选地,运动目标检测跟踪模块通过如下方法得到各运动目标在像素坐标系下的精确位置和精准边界框:
[0034]
s3.1、对由yolo检测得到的运动目标的粗略边界框标示区域进行灰度化和高斯滤波处理;
[0035]
s3.2、采用canny-devernay算法对运动目标的粗略边界框标示区域进行边缘检测,得到运动目标的精确轮廓,获得运动目标轮廓点坐标集合;
[0036]
s3.3、根据运动目标轮廓点坐标,计算轮廓的特征矩;
[0037]
s3.4、用轮廓的特征矩计算运动目标的质心即运动目标在像素坐标系下的精确位置;
[0038]
s3.5、取目标轮廓的最小外接矩形作为运动目标精准边界框。
[0039]
优选地,运动目标检测跟踪模块采用deepsort方法对不同时刻各运动目标的精准边界框进行跟踪。
[0040]
优选地,相机采用有线方式与运动目标检测跟踪模块通信。
[0041]
本发明的另一个技术方案是:一种运动目标视频定位测速方法,该方法包括如下步骤:
[0042]
s1、在同步采集指令的驱动下,利用多个相机拍摄运动目标运动场景下的图像,形成图像数据帧发送给运动目标检测跟踪模块;m个相机的总视场覆盖运动目标的整个运动场景;
[0043]
s2、对各相机拍摄的图像进行畸变校正,采用yolo模型对同一时刻拍摄的每一张校正后的图像进行目标识别,识别出图像中所有运动目标在像素坐标系下的粗略边界框;
[0044]
s3、以运动目标在像素坐标系下的粗略边界框为基础,基于边缘检测方法,得到各运动目标在像素坐标系下的精确位置和精准边界框;
[0045]
s4、采用deepsort算法对同一运动目标不同时刻的精准边界框进行匹配,,实现不同时刻各运动目标的精准边界框的跟踪;
[0046]
s5、通过透视投影矩阵将每个运动目标在像素坐标系下的坐标转换为对应相机视场覆盖区域世界坐标系下的坐标,根据各相机视场覆盖区域间的位置关系,计算出各运动目标不同时刻在运动场景全局世界坐标系下的坐标,并发送给运动目标速度识别模块;
[0047]
s6、将各运动目标不同时刻在运动场景全局世界坐标系下的坐标序列滤波去噪后
进行差分处理,得到运动目标在运动场景世界坐标系下的速度。
[0048]
本发明与现有技术相比具有如下有益效果:
[0049]
(1)、本发明在yolo模型目标识别和deepsort跟踪之间增加了基于边缘检测将粗略边界框进一步识别,得到目标的精准位置和精准边界框,再采用deepsort对精准边界框进行跟踪,提高目标检测定位精度,适用于高精度定位场合。
[0050]
(2)、本发明提出了“扩展的九点标定法”不必使用大标定板,实现了实现了大范围较高精度的标定。
[0051]
(3)、本发明求解透视投影矩阵时,为了准确得到标志点的像素坐标,设置标志点形状为菱形,则无论拍摄距离远近,在拍摄的图像中,都能得到菱形的较为准确的角的位置,从而对其中心进行准确定位。
附图说明
[0052]
图1为本发明实施例张正友标定法棋盘格;
[0053]
图2为本发明实施例相机外参标定场地布置示意图;
[0054]
图3为本发明实施例yolo检测网格输出示意图;
[0055]
图4为本发明实施例边缘检测流程;
[0056]
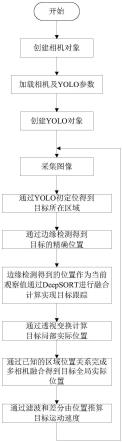
图5为本发明实施例视觉定位和检测方法流程图。
具体实施方式
[0057]
下面结合附图和具体实例对本发明作进一步的详细描述:
[0058]
本发明某一具体实施例给出了定位与测速系统,该定位与测速系统由用于图像采集的相机、运动目标检测跟踪模块、运动目标速度识别模块等软硬件组成。通过架设相机,在复杂的环境下,利用相机拍摄运动目标的视频,通过对视频进行一系列的图像分析、处理与跟踪,最终实现对运动目标识别、定位和测速功能。
[0059]
为了扩大视场范围,本实施例提供的运动目标视频定位测速系统包括m 个相机,m大于1。,m个相机的总视场覆盖运动目标的整个运动场景;相机采用有线方式与运动目标位置识别模块通信,以保证系统的实时性。
[0060]
相机,在同步采集指令的驱动下,拍摄视场内的图像,形成图像数据帧发送给运动目标检测跟踪模块;
[0061]
运动目标检测跟踪模块,采集各相机发送的图像数据帧,并记录图像采集时间,对各相机拍摄的图像进行畸变校正,采用yolo模型对同一时刻拍摄的每一张校正后的图像进行目标检测,得到图像中所有运动目标在像素坐标系下的边界框,再基于边缘检测方法,得到各运动目标在像素坐标系下的精确位置和精准边界框,采用deepsort算法对同一运动目标不同时刻的精准边界框进行匹配,实现不同时刻各运动目标的精准边界框的跟踪;通过透视投影矩阵将每个运动目标在像素坐标系下的坐标转换为对应相机视场覆盖区域世界坐标系下的坐标,根据各相机视场覆盖区域间的位置关系,计算出各运动目标不同时刻在运动场景全局世界坐标系下的坐标,并发送给运动目标速度识别模块;
[0062]
运动目标速度识别模块,将各运动目标不同时刻在运动场景全局世界坐标系下的坐标序列滤波去噪后进行差分处理,得到运动目标在运动场景世界坐标系下的速度。
[0063]
所述相机通过固定支架吊挂在运动场景上空,通过视频采集方式拍摄图像。
[0064]
相机使用前的一项重要工作为相机标定,相机标定分为内参标定和外参标定(获取透视投影矩阵),涉及图像的畸变校正和坐标映射,从而最终影响检测精度。其中外参标定对于应用环境依赖性比较大。目前的相关应用,主要用于小幅面的场景,运动类的大幅面场景下应用较少。大幅面场景,如果使用一个相机覆盖整个场地的话,检测精度较低,为达到检测精度要求,往往需要用到多个固定的相机,则问题在于如何对多相机进行外参标定。当前使用的方法为在每个相机下放置一个棋盘格标定板,分别对每个相机进行外参标定,再通过各标定板间的关系确定全局的参数。这里的第一步存在一些问题。因为大幅面场景下,每个相机视野覆盖的场地面积比较大,同时为有效利用每个相机,标定区域应覆盖到相机尽量大的视野,一般要达到80%左右,如果标定板较小,则被标定的相机视野比例较小,即单个相机有效测试的范围较小,而采用大标定板则不太现实。
[0065]
基于单相机的九点标定法进行扩展进行外参标定。首先布置多台相机覆盖整个运动场地,相邻相机视野间留有一定的重叠区域。然后布置标志点,并使得相邻相机视野重复区域含有公共的三个标志点,对每台相机使用九点标定法进行单独标定获取各自的投影矩阵。实际测试时,先通过每个相机检测到本区域内目标的坐标,之后再通过全场范围内标志点的相对位置确定目标在全场的全局坐标,即完成了多相机数据的融合。该方法称之为“扩展的九点标定法”。
[0066]
以下对本发明的要点进行介绍:
[0067]
1、相机内部参数与畸变参数的标定
[0068]
1.1原理介绍
[0069]
相机拍摄的图像会产生畸变,包括径向畸变和切向畸变,因此在进一步处理前,需要对图像进行畸变校正。畸变校正需要用到相机的内部参数和畸变参数,它们需要通过内参标定来获得。
[0070]
相机成像原理由如下公式表示:
[0071][0072]
其中,(u,v)为像素坐标,(xw,yw,zw)为世界坐标。
[0073]
m1为内参矩阵,其中,f
x
=f/dx称为相机x轴方向上的归一化焦距, fy=f/dy称为相机y轴方向上的归一化焦距,单位为像素;f为相机的焦距, dx、dy分别为像素在相机x、y轴方向上的物理尺寸;(u0,v0)为图像中心在像素坐标系坐标,单位为像素。
[0074]
m2为外参矩阵。
[0075]
径向畸变公式如下:
[0076][0077][0078]
k1为径向畸变二次项系数、k2为径向畸变四次项系数、k3为径向畸变六次项系数;
[0079]
切向畸变公式如下:
[0080][0081][0082]
p1为第一切向畸变系数、p2为第二切向畸变系数;式中,(x,y)为理想无畸变的图像坐标,为畸变后的图像坐标,r为图像中某点到图像中心点的距离,即r2=x2+y2。
[0083]
1.2应用方式
[0084]
运动目标检测及跟踪模块采用计算机视觉库opencv中的undistort函数对各相机拍摄的图像进行畸变校正,所述undistort函数如下:
[0085]
voidundistort(inputarraysrc,outputarraydst,inputarraycameramatrix,inputarraydistcoeffs,inputarraynewcameramatrix)
[0086]
src为原始图像的像素矩阵。
[0087]
dst为校正后的图像的像素矩阵。
[0088]
cameramatrix为相机内参子阵:
[0089][0090]
distcoeffs为畸变参数矩阵:
[0091]
distcoeffs=[k1,k2,p1,p2,k3]
[0092]
inputarraynewcameramatrix为全0矩阵。
[0093]
1.3标定步骤
[0094]
本发明所述相机内部参数cameramatrix与畸变参数distcoeffs的标定过程如下:
[0095]
s1.1、准备一个张正友标定法棋盘格作为标定板,用相机对标定板进行不同角度的拍摄,得到一组n张棋盘格图像,15≤n≤30;本发明某一具体实施例中,n取值为18;
[0096]
s1.2、采用matlab工具箱中的相机标定工具cameracalibration,加载步骤s1.1拍摄得到的n张棋盘格图像,对棋盘格图像中的角点进行自动检测,获得角点在像素坐标系下的坐标;
[0097]
s1.3、将棋盘格的单元格实际尺寸输入至标定工具cameracalibration,由标定工具cameracalibration计算得到角点的世界坐标;
[0098]
s1.4、标定工具cameracalibration根据n张图像中的角点在像素坐标系下的坐标与在世界坐标系下的坐标,进行参数解算,得到相机内参intrinsicmatrix、畸变参数distcoeffs。
[0099]
2、整体透视投影矩阵标定
[0100]
2.1原理介绍
[0101]
透视投影是将图片投影到一个新的视平面。它是二维(x,y)到三维(x,y,z),再到另一个二维(x
′
,y
′
)空间的映射。透视投影是通过矩阵乘法实现的,使用的是一个3x3的投影矩阵,矩阵的前两行(m11,m12,m13,m21,m22,m23)实现了线性变换和平移,第三行用于实现透视变换。
[0102][0103]
x=m11*x+m12*y+m13
[0104]
y=m21*x+m22*y+m23
[0105]
z=m31*x+m32*y+m33
[0106][0107][0108]
以上公式设变换之前的点是z值为1的点,它三维平面上的值是(x,y,1),在二维平面上的投影是(x,y),通过矩阵变换成三维中的点(x,y,z),再通过除以三维中z轴的值,转换成二维中的点(x
′
,y
′
)。
[0109]
对于相机来说,(x,y)相当于图像上的点,(x
′
,y
′
)相当于现实世界某平面上的点,两者构成一一对应关系。投影矩阵表达了世界坐标系到图像坐标系的转换关系。
[0110]
由于每一组坐标构成两个方程,转换矩阵含9个未知数,则由至少5组坐标(构成10个方程)即可求解出投影矩阵。实际采用9点标定法,得到9组坐标,会对投影矩阵进行优化。
[0111]
2.2应用方式
[0112]
运动目标检测及跟踪模块调用计算机视觉库opencv中的perspectivetransform函数将目标在像素坐标系下的坐标转换为相机视场覆盖区域世界坐标系下的坐标。
[0113]
perspectivetransform函数如下:
[0114]
voidperspectivetransform(inputarrayt_src,outputarrayt_dst,inputarraym);
[0115]
其中src为运动目标的像素坐标点,dst为运动目标世界坐标点,m为透视投影矩阵。
[0116]
2.3透视投影矩阵的获取过程如下:
[0117]
s2.1、在运动目标的运动场景布置好相机并其固定,使得m个相机的总视场覆盖运动目标的整个运动场景,且相邻相机画面有重叠区域;
[0118]
s2.2、定义运动场景的场地平面为全局世界坐标系的xoy平面,在场地平面布置r行c列标志点,标志点的行与全局世界坐标系的x轴平行,标志点的列与全局世界坐标系的y轴平行,每个标志点上设有菱形图案,菱形图案相对的顶点连线与全局世界坐标系的x轴、y轴平行,菱形中心点位置作为标志的位置;每个相机视场内包含a2个标志点,标志点以a*a矩阵形式均匀分布,且位于周边的各标志点靠近相机视场边缘,相邻相机视场重叠区域包含a个公共标志点,本发明某一具体实施例中,a取值为3。如图2所示,以相邻的两台相机c1和c2为例,c1覆盖以m11和m33为对角线的矩形区域,而c2覆盖以m31和m53为对角线的矩形区域;
[0119]
s2.3、对于每个相机,选定相机视场内左上角的标志点作为原点,即坐标为(0,0),
建立该相机视场区域世界坐标系,测量各个标志点相对于原点的位置,得到a2个标志点在相机视场区域世界坐标系下的坐标;
[0120]
s2.4、通过相机拍摄,每个相机得到包含a2个标志点的一张图像;
[0121]
s2.5、将相机拍摄的图像进行畸变校正;
[0122]
s2.6、确定每个相机拍摄的畸变校正后图像中的a2个标志点在像素坐标系下的坐标;具体方法为:
[0123]
通过matlab显示畸变校正后图像,使用impixelinfo命令显示鼠标指向的点在图像中的位置,将鼠标指向到菱形标志的中心,得到a2个标志在图像中的位置,将图像中左上角的菱形标志的中心定义为像素坐标系原点,坐标记为(0,0),将其余a
2-1个非原点标志点与原点的相对位置,记为其像素坐标系下的坐标。
[0124]
s2.7、对于每个相机,将每个标志点在像素坐标系下的坐标和对应相机视场区域世界坐标系下的坐标,记为一组坐标,a2组坐标传入计算机视觉库 opencv中的findhomography函数,可计算出该相机的透视投影矩阵。
[0125]
所述findhomography函数如下:
[0126]
mat findhomography(inputarraysrcpoints,inputarraydstpoints,
[0127]
int method,double ransacreprojthreshold);
[0128]
srcpoints为像素坐标系下运动目标的坐标;
[0129]
dstpoints为世界坐标系下的运动目标的坐标;
[0130]
method为计算矩阵所用到方法;
[0131]
ransacreprojthreshold是将点对视为内点最大允许重投影错误阈值;
[0132]
函数返回透视投影矩阵。
[0133]
将各个标志点作为被测目标,并将像素坐标转换为世界坐标,与实际世界坐标进行对比,可对标定的精度亦即测试精度进行评估。
[0134]
3、目标检测与跟踪
[0135]
3.1 yolo模型
[0136]
yolo模型是一种基于深度神经网络的对象识别和定位算法,算法如下:
[0137]
(1)、将相机采集的图像分辨率转换为416*416,并分成sxs个网格 (grid cell)。本发明某一具体实施例中,s通常取值为7。
[0138]
(2)、每个网格会预测b个边界框(bbox,bounding box)以及边界框的置信度(confidence score)。本发明某一具体实施例中,b为2。
[0139]
(3)、边界框信息用4个值表示(x,y,w,h),其中(x,y)是边界框的中心坐标,而w和h是边界框的宽与高。
[0140]
(4)、置信度包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为pr(object),当边界框包含目标时, pr(object)=1,否则pr(object)=0(仅包含背景)。后者用预测框与实际框 (ground truth)的iou(intersection over union,交并比)来表征,记为则置信度定义为
[0141]
(5)、除了边界框,每个网格还要预测c个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率,记为 pr(classi|object)。
[0142]
综上,每个网格需要预测(b*5+c)个值。取b=2,c=20,则每个网格包含的数值如图2所示。
[0143]
如果将输入图片划分为s*s网格,那么最终预测值为s*s*(b*5+c)个。
[0144]
实际测试时,还要计算出各个边界框类别置信度(class-specificconfidencescores):
[0145][0146]
对于c个类别,i=1,2,...,c。
[0147]
得到每个边界框类别置信度以后,设置阈值(本实施例中阈值为0.5),滤掉得分低的边界框,对保留的边界框进行nms(非最大抑制算法)处理,就得到最终的检测结果。对于每个被检测到的目标,最终输出包含7个值:4个位置值(x,y,w,h)(即最终的边界框)、1个边界框置信度、1个类别置信度和1个类别代码。
[0148]
3.2、基于边缘检测的精确位置求解
[0149]
边缘检测对图像进行像素级处理,因此可以对目标进行像素级精确定位,处理流程如图3所示。运动目标检测跟踪模块对由yolo检测得到对边界框标示区域(下称roi,regionoflnterest)进行边缘检测等处理,得到各运动目标在像素坐标系下的精确位置和精准边界框:
[0150]
s3.1、对由yolo检测得到的运动目标的粗略边界框标示区域进行预处理,包括灰度化、高斯滤波等;
[0151]
s3.2、采用canny-devernay算法对运动目标的粗略边界框标示区域进行边缘检测,得到运动目标的精确轮廓,获得运动目标轮廓点坐标集合;canny-devernay算法具体包括采用图像求梯度、计算边缘点、边缘点链路编码、应用双阈值方法进行边缘检测和边缘连接。
[0152]
s3.3、根据运动目标轮廓点坐标,计算轮廓的特征矩;
[0153]
s3.4、用轮廓的特征矩计算运动目标的质心即运动目标在像素坐标系下的精确位置;
[0154]
具体为使用opencv函数cv::moments获取对象cv::moments,从中得到零阶矩m
00
和一阶矩m
10
、m
01
,有:
[0155][0156][0157]
s3.5、取与目标轮廓最小外接矩形作为运动目标精准边界框bbox。
[0158]
3.3、deepsort跟踪算法
[0159]
运动目标检测跟踪模块采用deepsort方法对不同时刻各运动目标的精准边界框进行跟踪。
[0160]
deepsort算法是对sort算法的扩展。sort算法是一种实现多目标跟踪的算法,它的计算过程为:
[0161]
跟踪以前,已由目标检测算法对全部运动目标完成检测。
[0162]
第一帧图像进来时,以检测到的目标bbox进行初始化并建立新的跟踪器,标注id;
[0163]
后面帧进来时,先到卡尔曼跟踪器(kalman filter)中获得由前面帧bbox 产生的状态预测和协方差预测。之后,求跟踪器全部目标状态与本帧检测的 bbox的iou,经过匈牙利算法(hungarian algorithm),获得iou最大的惟一匹配(数据关联部分),去掉匹配值小于iou_threshold(一般取0.3) 的匹配对。
[0164]
用本帧中匹配到的目标检测bbox去更新卡尔曼跟踪器,进行状态更新和协方差更新。并将状态更新值输出,做为本帧的跟踪bbox。对于本帧中没有匹配到的目标重新初始化跟踪器。之后,卡尔曼跟踪器进行下一轮预测。
[0165]
deepsort算法对sort整体框架没有大改,增加了级联匹配和目标的确认,从而增强了跟踪的有效性。
[0166]
4、速度求解
[0167]
对于目标在全局世界坐标系下的位置序列,采取分组求均值的方法进行滤波,然后对均值通过差分运算得到目标的运动速度。
[0168]
如图5所示,基于上述系统,本发明还提供了一种视觉定位和检测方法,步骤如下:
[0169]
s1、在同步采集指令的驱动下,利用多个相机拍摄运动目标运动场景下的图像,形成图像数据帧发送给运动目标检测跟踪模块,所述图像数据帧带有图像采集时间;m个相机的总视场覆盖运动目标的整个运动场景;
[0170]
s2、对各相机拍摄的图像进行畸变校正,采用yolo模型对同一时刻拍摄的每一张校正后的图像进行目标识别,识别出图像中所有运动目标在像素坐标系下的粗略边界框;
[0171]
s3、以运动目标在像素坐标系下的粗略边界框为基础,基于边缘检测方法,计算得到各运动目标在像素坐标系下的精确位置和精准边界框;
[0172]
s4、采用deepsort算法对同一运动目标不同时刻的精准边界框进行匹配,,实现不同时刻各运动目标的精准边界框的跟踪;
[0173]
s5、通过透视投影矩阵将每个运动目标在像素坐标系下的坐标转换为对应相机视场覆盖区域世界坐标系下的坐标,根据各相机视场覆盖区域间的位置关系,计算出各运动目标不同时刻在运动场景全局世界坐标系下的坐标,并发送给运动目标速度识别模块;
[0174]
s6、将各运动目标不同时刻在运动场景全局世界坐标系下的坐标序列滤波去噪后进行差分处理,得到运动目标在运动场景世界坐标系下的速度。实施例:
[0175]
本发明某一具体实施例中,相机采用大恒相机,通过调用大恒相机api 实现图像的采集。yolo模型目标类别设置为人物,即只将人物作为运动目标进行检测,实现了目标检测。为了提高执行效率,本实施例中,采用c++ 作为开发语言实现。如图5所示,首先对动目标视频定位测速系统进行了如下初始化:创建相机对象;加载相关参数,包括相机ip地址等基本配置参数、相机内参和畸变参数;创建yolo对象并进行初始化,之后采用上述方法实现视觉定位和检测方法,取得了较好的跟踪效果,定位精度达到2cm 以内。
[0176]
以上所述,仅为本发明最佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
[0177]
本发明说明书中未作详细描述的内容属于本领域专业技术人员的公知技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1