基于多阶段ICA‑SVDD的间歇过程故障监测方法与流程
本发明涉及基于多阶段ica-svdd的间歇过程故障监测方法,属于工业过程故障诊断和软测量领域。
背景技术:
间歇过程是一种比较重要的工业生产方式,其工艺机理复杂并存在多个操作阶段,而且产品质量易受不确定性因素的影响。为了保证间歇生产过程的安全可靠运行以及产品的高质量追求,需要建立有效的过程监控系统对间歇生产过程进行故障监控。多元统计过程控制方法已经广泛的应用到间歇过程监测中,如多向主元分析(multiwayprincipalcomponentanalysis,mpca)和多向偏最小二乘分析(multiwaypartialleastsquares,mpls)。但是大多数与主成分分析和偏最小二乘分析相关的数据描述方法都有数据符合高斯分布和不同的变量之间的关系是线性的限制。
针对间歇过程数据的非高斯特性,独立成分分析(independentcomponentanalysis,ica)被引入到过程监控领域,为了适应对间歇过程的故障监测,一些学者把ica方法扩展为多向独立成分分析(multiwayica,mica)方法。虽然可以处理非高斯数据,但是在确定过程监控统计量的置信限时,基于核密度估计方法计算过程复杂并且参数无法准确获得,当变量维数较大时,无法避免核密度估计带来的“维数灾难”等问题。此外,对于非线性间歇过程的监控,传统的mpca/mpls方法也扩展到其非线性形式,如多向核pca和多向核pls,然而,基于这些非线性方法的过程监控方法也需要服从高斯分布。
多操作阶段是许多间歇过程的一个固有特性,如果采用单一建模方式实现整个批次过程的监控,会导致模型在不同阶段内的监测效果不佳。针对这一特性,国内外学者已经做了大量的研究,通过对批次过程进行合理的阶段划分并在子阶段内建立过程的监测模型,从而提高监测性能。
过程监测可以认为是一个单值分类问题,因为监测的任务是将正常数据与故障数据分离。支持向量数据描述(supportvectordatadescription,svdd)算法是一种最初由tax和duin提出的单值分类方法。通过非线性变换将正常数据样本空间映射到高维特征空间并建立一个模型,从而将正常数据与故障数据分离,达到过程故障监测的目的。使用svdd算法进行故障监测便可以同时处理不符合高斯分布和变量间是非线性关系的数据。svdd已经被用于损伤检测、图像分类、模式识别等领域,在过程监控领域中的应用也开始得到重视。
一种基于独立成分分析和支持向量数据描述的多阶段间歇过程的故障监测方法,可以有效提高间歇过程的故障监测性能。由于大多数与主成分分析和偏最小二乘分析相关的数据描述方法都有数据符合高斯分布和不同的变量之间的关系是线性的限制。该方法可以同时解决过程数据非高斯和非线性的监测问题,具有更佳的故障监测效果。
技术实现要素:
针对于间歇过程呈现的多阶段、非高斯性和非线性,工艺机理复杂,而且产品质量易受不确定性因素的影响,为了提高对多阶段间歇过程的故障监测性能,本发明提供一种基于多阶段ica-svdd的间歇过程故障监测方法。
首先把三维数据沿批次方向展开,根据各个时间片的相似度进行模糊阶段划分,可以得到初始的聚类个数,以便通过k均值算法进行精确的阶段划分;当确定阶段后,再把三维数据沿变量方向展开,然后对各阶段分别利用ica方法进行特征提取,提取出对应的非高斯特征信息和残差信息;最后分别对独立成分的非高斯空间和剩余的残差空间通过svdd算法建立统计分析模型,实现对整个过程的在线故障监测。
本发明的目的是通过以下技术方案实现的:
基于多阶段ica-svdd的间歇过程故障监测方法,所述方法包括以下过程:针对于间歇过程的多操作阶段特性,需要对生产过程进行合理的阶段划分,以便建立多个子模型进行故障监测。首先根据各个时间片的均值向量的相似度对生产过程进行模糊阶段划分,得到初步的阶段数目。然后通过k均值算法把数据特征相似的时刻归为一类,进而得到更精确的阶段划分。
对各阶段分别利用独立成分分析方法提取出非高斯的特征信息,当采用ica算法提取全部独立成分后,按照非高斯程度大小重新排列,选取前d个独立性较强的独立成分得到对应矩阵
最后引入支持向量数据描述算法对独立成分和剩余的高斯残差空间分别建立统计分析模型,实现对整个过程的故障监测。通过非线性变换将正常数据样本空间映射到高维特征空间并建立一个模型,从而将正常数据与故障数据分离,达到过程故障监测的目的。使用svdd算法进行故障监测便可以同时处理不符合高斯分布和变量间是非线性关系的数据。
附图说明
图1是基于多阶段ica-svdd的间歇过程监测方法流程图;
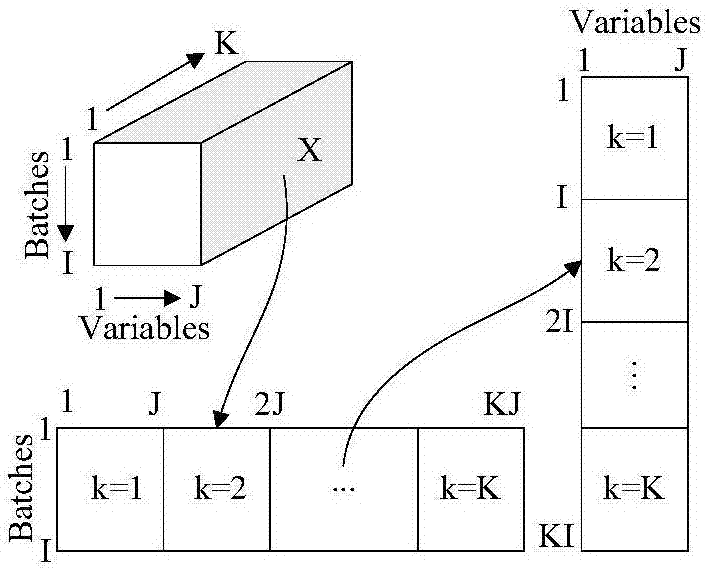
图2间歇过程数据展开;
图3多阶段划分结果;
图4正常批次监测结果;
图5故障tcp+50批次监测结果;
具体实施方式
下面结合图1所示,对本发明做进一步详述:
使用的研究数据是从一个实际的半导体蚀刻工艺过程中采集得到的,分别对半导体蚀刻的正常数据和故障数据进行故障监测。
步骤1:间歇过程的三维数据集x(i×j×k)进行二维展开,其中,i代表批量数,j代表变量数,k代表采样点数。采用沿批次方向和沿变量方向相结合的数据处理方式,先将三维形式的数据x(i×j×k)沿批次方向转化为二维矩阵x(i×kj),然后标准化二维矩阵;再按照变量方向重新组合,形成新的二维矩阵x(ki×j)。两步数据展开方法如图2所示。
步骤2:对生产过程进行合理的阶段划分,以便建立多个子模型进行故障监测。首先根据各个时间片的均值向量的相似度对生产过程进行模糊阶段划分,得到初步的阶段数目。然后通过k均值算法把数据特征相似的时刻归为一类,进而得到更精确的阶段划分。
step1:将三维过程数据x(i×j×k)先按批次方向展开得到二维矩阵x(i×kj),然后按时间轴方向切割为批次和变量组成的二维数据时间片矩阵xk(i×j),k=1,2,…,k。
step2:求取每一个时间片矩阵xk(i×j)的均值向量,记为
依次计算xbase后面的时间片和其相似度,并设定相似度阈值α,如果x2和xbase的相似度大于阈值α,则认为x2也属于当前时段,然后继续计算下一个时间片和xbase的相似度;否则,认为x2属于下一个阶段,并令xbase=x2,按上述步骤继续进行。
依据相似度把相似的时间片连接形成一个时间段,得到初步的模糊划分。可以得到对应的阶段个数p,这为后面用聚类算法选取聚类数提供了依据,但是,这种模糊划分法会出现某些点或者极少的连续点不能准确的划分到某个阶段。
step3:通过k-means聚类算法对时间片的均值向量进行聚类,算法输入是均值向量集合
步骤3:使用独立成分分析(independentcomponentanalysis,ica)进行特征信息提取,ica更加充分的利用了数据高阶统计信息,并且可从观测数据中进一步提取出相互独立的潜在变量,这些潜在变量可以更本质地提取反应过程特征。
ica模型定义为
x=as+e(2)
其中x=[x(1),x(2),...,x(n)]∈rm×n是观测数据矩阵,a=[a1,a2,...,ad]∈rm×d是未知的混合矩阵,s=[s(1),s(2),...,s(n)]∈rd×n是隐藏的独立成分矩阵,e∈rm×n是残差矩阵。n为采集的样本个数,由d≤m可知,ica其实和pca类似也是一种数据压缩技术,通过尽可能少的数据来描述尽可能多的信息。
ica的目的是从观测数据x中估计出混合矩阵w和独立成分s,因此,ica目标:找到一个解混矩阵w,可从观测信号中分离出源信号,即
当d=m时,即解混矩阵w是混合矩阵a的逆时,
当采用ica算法提取全部独立成分后,按照非高斯程度大小重新排列,选取前d个独立性较强的独立成分得到对应矩阵
步骤4:采用支持向量数据描述(supportvectordatadescription,svdd)进行间歇过程的在线监测,svdd是一种单值分类算法,其基本思想是针对训练数据集x={xi,i=1,…,n},通过非线性转化φ:x→f将原始空间数据投影到特征空间{φ(xi),i=1,…,n},然后可以在特征空间中找到可以包含所有数据样本的最小体积的超球体,svdd通过核函数将输入空间映射到高维空间来学习得到灵活并且准确的数据描述模型,得到的超球体数据描述边界是通过一小部分的支持向量进行表示的。
为了构建这样的最小超球体,svdd需要解决以下优化问题:
式(4)中,a为超球体的球心,r为超球体的半径,惩罚系数c权衡了超球体的体积和训练样本的误分率,松弛变量ξi的引入代表对第i个训练样本产生误分的惩罚项,上述优化问题可以转化为解决相应的对偶问题:
此处是引入核函数k(xi,xj)代替内积函数(xi,xj),利用二次规划,可以求出ai,如果x0代表任意的一个支持向量,则超球体的球心和半径可表示为:
对于新来的样本xnew,可以得到其到超球体球心的距离:
如果distnew≤r则该样本正常;反之,该样本为异常样本。
采用ica对间歇过程的各个阶段进行特征提取后,可以分别得到独立成分的非高斯空间和剩余的残差空间的数据,通过svdd方法对提取出的独立成分
式中:
同样,再对残差矩阵e建立svdd模型如下:
那么,残差矩阵e所形成的svdd超球体的球心和半径如(11)式所示:
对于间歇过程的各个阶段,可以分别得到对应阶段的超球体半径r,在线过程监控时,当获得当前时刻的采样数据xnew时,通过数据预处理和ica特征提取后,分别求取独立成分
在对过程数据进行阶段划分和预处理后,为了比较单一建模和多阶段建模的故障监测效果,分别建立了单一和多阶段的pca、ica、ica-svdd的统计监控模型,所有统计量的统计控制限均设定为99%。图4给出了六种方法对正常批次的监控结果,可以看出六种方法对正常批次都能得到很好的监控结果。其中(a)、(b)、(c)为单一建模方法正常批次的故障监测图,(d)、(e)、(f)为多阶段建模方法正常批次的故障监测图。图5给出了tcp+50故障的故障监测图,其中(a)、(b)、(c)为单一建模方法故障批次的监测图,(d)、(e)、(f)为多阶段建模方法故障批次的监测图。从图5中可以看出,对于tcp+50故障,无论是单一模型还是多阶段模型的故障监测,ica-svdd都是明显优于其他两种方法。
- 还没有人留言评论。精彩留言会获得点赞!