基于递减预测步长的模型预测控制方法与流程
本发明涉及工业控制领域,具体涉及一种基于递减预测步长的模型预测控制方法。
背景技术:
模型预测控制具有处理系统约束、多变量系统优化问题的能力以及可以滚动优化系统性能指标,因此也被称为滚动优化控制,已经在控制领域引起了广泛关注。最近的“双模式”模型预测控制提出一种假设,当系统状态进入指定的终端约束集时,就可以利用预定的控制律稳定系统。因此,控制问题就可以分成两步,首先利用变步长控制策略引导系统状态进入终端约束集,其次利用预定的控制律稳定系统。如果系统状态能够在有限步数甚至是指定步数内进入终端约束集,这种控制方法将具有重要的理论与实际意义。
传统技术存在以下技术问题:
固定步长预测控制可以使系统状态在有限时间内到达终端集,然而具体到达时间无法预知,更无法保证在指定时间内到达。
技术实现要素:
本发明要解决的技术问题是提供一种基于递减预测步长的模型预测控制方法,利用具有先验状态记忆的仿射状态反馈控制律引导系统状态在指定步数内进入终端约束集,同时利用型成本函数优化系统性能。
为了解决上述技术问题,本发明提供了一种基于递减预测步长的模型预测控制方法,包括:
建立线性时不变系统模型,其输入满足一定约束以及范数有界的干扰,系统的预测输出可由系统模型获得;
采用h∞型成本函数,通过调制成本函数的参数矩阵,可以决定分配给系统状态或者控制输入的权重;
引入具有先验状态记忆的仿射状态反馈控制律,通过一种非线性变量变化,可以将不能凸优化求解的控制律参数进行凸优化求解;
采用预测步长递减的模型预测控制算法,将最小化成本函数及输入约束、状态终端约束的优化问题转变为在线凸优化求解过程,并给出整个算法流程;
对算法可行性和指定到达时间进行论证,引出定理:如果优化问题在k时刻有解,那么它在k+1时刻也有解;并对定理进行验证,进而衍生出如果优化问题初始有解,那么第n步系统状态一定在终端约束集里,这就保证了指定的到达时间。
在其中一个实施例中,“建立线性时不变系统模型,其输入满足一定约束以及范数有界的干扰,系统的预测输出可由系统模型获得;”中,所述的满足输入约束以及范数有界干扰的线性时不变模型,其数学描述如式(1)所示:
x(k+1)=ax(k)+bu(k)+ed(k)(1)
其中,x(k)∈rn是状态矢量,u(k)∈rm是输入矢量,d(k)∈rp是误差矢量,a,b和e是常数矩阵;假设状态x(k)在每个采样时刻可测,u(k)和d(k)满足范数有界的约束。
在其中一个实施例中,“采用h∞型成本函数,通过调制成本函数的参数矩阵,可以决定分配给系统状态或者控制输入的权重;”中,所述的可自由分配权重的h∞型成本函数,其数学描述如式(2)所示:
其中,
τ是正常数,其值越小则闭环系统控制性能越好,在选定状态终端集时计算合适的τ值。
在其中一个实施例中,“引入具有先验状态记忆的仿射状态反馈控制律,通过一种非线性变量变化,可以将不能凸优化求解的控制律参数进行凸优化求解;”中,首先定义系统在k时刻的状态、输入和干扰序列如下:
x(k):=[x(k),x(k+1|k),…,x(k+nk|k)]t,
u(k):=[u(k),u(k+1|k),…,u(k+nk-1|k)]t,
d(k):=[d(k),d(k+1|k),…,d(k+nk-1|k)]t.
则系统状态可用矩阵描述为式(3)
x(k)=x0(k)+gu(k)+hd(k)(3)
其中,
在线计算的优化问题表述如下,在最坏扰动的情况下,通过控制输入序列最小化成本函数,同时满足系统约束,使得预测的nk步后系统状态在终端集内,用数学描述如式(4)所示:
为了实现上述优化,本发明采用带有记忆的仿射状态反馈控制律,即
用矩阵描述为式(5)
u(k)=kx(k)+c(5)
该控制器设计有利于增大优化问题的可行域,其中,k和c是有待设计的增益;然而,该控制器不能带入优化问题(4)进行凸优化求解,因此需要进行非线性变换,为此引入如下变量:
s:=k(i-gk)-1,t:=(i+sg)c。
在其中一个实施例中,“引入具有先验状态记忆的仿射状态反馈控制律,通过一种非线性变量变化,可以将不能凸优化求解的控制律参数进行凸优化求解;”中,所述的经过变量变换后的系统状态以及控制输入,其数学描述如式(6)所示:
在其中一个实施例中,进一步的,当终端约束集可以写成二次型时,约束x(k+nk|k)∈ω可以表示为如下线性矩阵不等式:
其中
在其中一个实施例中,“采用预测步长递减的模型预测控制算法,将最小化成本函数及输入约束、状态终端约束的优化问题转变为在线凸优化求解过程,并给出整个算法流程;”中,所述的递减步长模型预测控制算法的算法流程具体步骤如下:
s1:选定系统状态终端集ω以及τ值;
s2:在k时刻,检测系统状态x(k),如果系统状态已经进入终端集ω,就停止在线计算,否则设置预测步长nk为n-k,并进行步骤3;
s3:求解带约束的优化问题op,然后将优化控制输入序列的第一个元素作用于系统,并进行步骤4;
s4:等待采样时间k+1到来,重复s2。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
本发明的有益效果:
本发明在变步长预测控制基础上,将到达时间当作硬性约束,提出递减步长模型预测控制,保证了系统状态能够在指定时间内进入终端集,同时也减少了系统进入终端集的时间。
本发明在引导系统状态的同时,采用型成本函数优化系统性能,保证了系统达到既定目的,又能够满足控制要求与系统稳定。
本发明采用具有先验状态记忆的仿射状态反馈控制律,显著扩大了可行域,该优点在干扰较强时显得更为突出。
附图说明
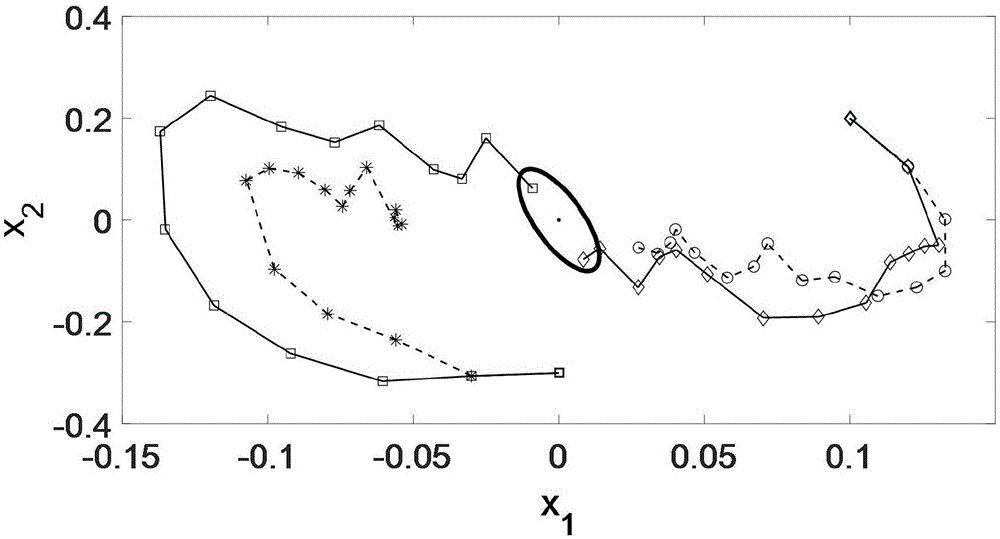
图1是本发明基于递减预测步长的模型预测控制方法的中数值算例的仿真状态图。
图2是本发明基于递减预测步长的模型预测控制方法中的连续搅拌釜反应器的仿真状态图。
图3是本发明基于递减预测步长的模型预测控制方法与开环控制律可行域对比示意图。
图4是本发明基于递减预测步长的模型预测控制方法与与参数不变仿射状态反馈控制律可行域对比示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
本发明的技术方案是:
一种基于递减预测步长的模型预测控制算法。主要包括:建立线性时不变系统模型、采用h∞型成本函数、引入具有先验状态记忆的仿射状态反馈控制律、提出递减步长模型预测控制算法、可行性和指定到达时间论证。
具体步骤包括如下:
s1,建立线性时不变系统模型,其输入满足一定约束以及范数有界的干扰,系统的预测输出可由系统模型获得。
s2,采用h∞型成本函数,通过调制成本函数的参数矩阵,可以决定分配给系统状态或者控制输入的权重。
s3,引入具有先验状态记忆的仿射状态反馈控制律,通过一种非线性变量变化,可以将不能凸优化求解的控制律参数进行凸优化求解。
s4,采用预测步长递减的模型预测控制算法,通过s-过程、舒尔补、线性矩阵不等式等数学方法,将最小化成本函数及输入约束、状态终端约束的优化问题转变为在线凸优化求解过程,并给出整个算法流程。
s5,对算法可行性和指定到达时间进行论证,引出定理:如果优化问题在k时刻有解,那么它在k+1时刻也有解。并对定理进行验证,进而衍生出如果优化问题初始有解,那么第n步系统状态一定在终端约束集里,这就保证了指定的到达时间。
进一步的,步骤1中,所述的满足输入约束以及范数有界干扰的线性时不变模型,其数学描述如式(1)所示:
x(k+1)=ax(k)+bu(k)+ed(k)(1)
其中,x(k)∈rn是状态矢量,u(k)∈rm是输入矢量,d(k)∈rp是误差矢量,a,b和e是常数矩阵。假设状态x(k)在每个采样时刻可测,u(k)和d(k)满足范数有界的约束。
进一步的,步骤2中,所述的可自由分配权重的h∞型成本函数,其数学描述如式(2)所示:
其中,
进一步的,步骤3中,首先定义系统在k时刻的状态、输入和干扰序列如下:
则系统状态可用矩阵描述为式(3)
x(k)=x0(k)+gu(k)+hd(k)(3)
其中,
在线计算的优化问题表述如下,在最坏扰动的情况下,通过控制输入序列最小化成本函数,同时满足系统约束,使得预测的nk步后系统状态在终端集内,用数学描述如式(4)所示:
为了实现上述优化,本发明采用带有记忆的仿射状态反馈控制律,即
用矩阵描述为式(5)
u(k)=kx(k)+c(5)
该控制器设计有利于增大优化问题的可行域,其中,k和c是有待设计的增益。然而,该控制器不能带入优化问题(4)进行凸优化求解,因此需要进行非线性变换,为此引入如下变量:
s:=k(i-gk)-1,t:=(i+sg)c
进一步的,步骤3中,所述的经过变量变换后的系统状态以及控制输入,其数学描述如式(6)所示:
进一步的,当终端约束集可以写成二次型时,约束x(k+nk|k)∈ω可以表示为如下线性矩阵不等式:
其中
进一步的,步骤4中,所述的递减步长模型预测控制算法的算法流程具体步骤如下:
s1:选定系统状态终端集ω以及τ值。
s2:在k时刻,检测系统状态x(k),如果系统状态已经进入终端集ω,就停止在线计算,否则设置预测步长nk为n-k,并进行步骤3。
s3:求解带约束的优化问题op,然后将优化控制输入序列的第一个元素作用于系统,并进行步骤4。
s4:等待采样时间k+1到来,重复s2。
下面结合仿真实例谈谈具体的实施方式:
在图1数值仿真中,首先考虑离散时间线性系统模型:
x(k+1)=ax(k)+bu(k)+ed(k)
其中,
考虑系统输入约束以及干扰:|u(k)≤3,
采用h∞型成本函数优化系统性能,确定成本函数参数。其中q、r、τ的取值分别为
值得一提的是,每一时刻计算机采集系统状态,并先判断系统状态是否进入终端集,若是,则停止优化,采用预定控制律控制系统;若否,则预测步长递减1步,并在线求解使得成本函数最小同时服从约束的仿射状态反馈控制器的参数k和c,将控制输入序列的第一个元素作用于系统,进行下一次采样。
在图2连续搅拌釜反应器仿真中,首先考虑系统的线性化模型:
x(k+1)=ax(k)+bu(k)+ed(k)
其中,
图1、图2给出的是以上两个实例中本专利递减预测步长方法与定步长方法的控制性能对比,设置到达时间为15步。其中,实线为本专利结果,虚线为定步长结果。对于两种不同的初始状态,本专利方法都能够引导系统状态在15步内进入终端集ω,而定步长方法却失败,由于递减预测步长,使得本专利方法执行时间也显著减少。
另外一项不能忽视的问题是可行吸引域的大小,图3和图4分别为采用本发明中使用的控制律与开环控制律u(k+i|k)=c(k+i|k)及控制律u(k+i|k)=kωx(k+i|k)+c(k+i|k)的可行吸引域对比,其中kω为终端约束集对应的反馈控制增益。
开环控制律时,优化问题中的变量s选为零矩阵,此时预测步长必须n≤3,超过3则无解。参数不变仿射状态反馈控制律时,参数kω=[-114,-14.9],预测步长选为6从而进行对比。从两幅图的对比能够看出,采用仿射状态反馈控制律显著扩大了可行吸引域的范围,在干扰强烈时更为明显。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!