一种水电机组劣化趋势区间预测方法与系统与流程
本发明属于水电机组性能监测技术领域,更具体地,涉及一种水电机组劣化趋势区间预测方法与系统。
背景技术:
随着累积运行时间的增加,水电机组各设备开始疲劳,不断劣化,由于缺乏故障样本,目前水电机组主要采用静态报警阈值,这种报警策略忽略了机组不同工况下的机组性能差异,缺少对机组早期潜在故障的预警能力,远不足以充分反映机组的运行状态,还不能满足现场需求。如何有效地判断机组的真实运行状态,更好地预测出机组的劣化趋势,以便及时进行异常状态预警,提高水电机组运行维护的水平,减少故障导致的停机损失,是水电机组向状态检修转变的重要研究方向。
现有的水电机组故障预测技术研究侧重于信号特征提取方法和智能模式识别方法,未能充分考虑运行工况对故障信号特征的影响。因此,当将其应该于实际机组故障诊断时,不能满足水轮发电机组故障诊断的工程需求。此外,水轮发电机组健康状态评估与故障预测在传统研究中没有得到足够的重视,水轮发电机组劣化状态预测处于起步阶段。
技术实现要素:
针对现有技术的不足,本发明提供了一种水电机组劣化趋势区间预测方法与系统,能够获取未来时间内劣化趋势的概率分布,从而获取比确定性的单值预测更多的信息,避免了传统单值预测无法实现对预测值区间范围与概率分布的评估,更无法在此基础上实现一定的风险分析的问题。
一种水电机组劣化趋势区间预测方法,包括离线训练阶段s和在线检测阶段t;
所述离线训练阶段s具体为:
s1:利用健康状态下的水电机组状态训练数据建立水电机组健康模型,即以水电机组健康运行状态下的功率p(t)和水头h(t)为输入,水电机组振动v(t)为输出,通过曲面拟合建立水电机组健康状态模型v(t)=f[p(t),h(t)],t表示水电机组状态监测时刻;
s2:利用故障状态下的水电机组状态训练数据建立机组劣化趋势模型,即以水电机组故障运行状态下的功率
s3:依据机组劣化度d(t)构造时间序列上、下界
s4:分别取时间序列上界
s5:分别对数据对
s6:分别使用归一化后的数据对
在线预测阶段具体为:
t1:实时采集待预测水电机组运行状态下的功率和水头,按照离线训练阶段s1-s5的方式得到待预测上、下界的输入属性矩阵;将待预测上、下界的输入属性矩阵分别代入劣化区间上限值和下限值预测模型,得到待预测水电机组的劣化趋势区间。
进一步地,所述训练二型模糊模型的具体实现方式为:
s601:初始化参数,包括两个模糊因子m1和m2、聚类总数c、距离调节参数η、最大迭代次数tmax、停止迭代阈值ε;利用模糊c均值进行粗聚类获取一型隶属度矩阵u=[uik],令初始
s602:利用下式计算每个聚类的上下超平面参数:
αi=[xtpix]-1xtpiy
其中,x=[x1]∈rn×(m+1):y为训练数据实际的水电机组劣化趋势数据矩阵;
s603:利用类型还原
s604:按照下式计算上下隶属度函数
s605:利用上下隶属度函数
s606:令t=t+1,转至步骤s602,直到相邻两次迭代的差值||αicurrent-αilast||>ε,进入步骤s607,αicurrent是当前迭代的第i类超平面参数,αilast是上一次迭代的第i类超平面参数,ε是停止迭代阈值,或者t>tmax时,停止迭代;
s607:计算输入数据点距离上下超平面的距离:
s608:依据下式计算数据点分别隶属于上下超平面型的高斯隶属度函数
s609:计算模糊权重
s610:将模糊权重ωi(xk)输入t-s模糊模型训练确定模型参数。
进一步地,还包括步骤s7:对所述劣化区间上限值和下限值预测模型进行优化,具体为:
s701:选取预测模型待优化变量为
s702:确定待优化变量的上下界[bl,bu],
s703:提取水电机组运行状态下的功率和水头验证数据,按照离线训练阶段s1-s5的方式得到上、下界的验证数据对;
s704:将上、下界的验证数据对中的上、下界的输入属性矩阵带入劣化区间上限值和下限值预测模型,得到验证用的预测区间;
s705:将验证用的预测区间反归一化,得到验证用的劣化趋势预测区间的上界和下界
s706:计算预测区间覆盖率picp以及预测区间宽度pinaw,以及综合指标cwc;
式中,n为采样总数,r是验证数据的实际劣化趋势的最大值与最小值之间的差值;
式中,ci是验证数据处于劣化趋势预测区间的计数;
式中,ξ为惩罚系数,δ为置信阈值;
s707:计算个体xi的目标函数值:
fiti(t)=t1*cwctrain(t)+t2*cwcopt(t)
其中,t1+t2=1
cwctrain(t)为训练数据的综合指标,cwcopt(t)为验证数据的综合指标;
s708:gsa优化迭代,过程如下:
计算所有个体的引力常数gi(t),i=1,...,n0:
其中,g0为引力常数初始值,β为衰减系数,t为当前迭代次数,nitmax为最大迭代次数;
根据目标函数值fiti计算粒子质量mi:
其中,
计算第i个粒子受到第j个粒子的作用力
其中,gi(t)是第i个个体引力时间常数,mi(t)是第j个粒子的引力质量,mj(t)是第i个粒子的引力质量,xi(t)是第i个粒子的位置向量,xj(t)是第j个粒子的位置向量,
计算所有个体的万有引力fi:
其中,randj为(0,1)之间随机数,t为当前迭代次数;
计算所有个体的加速度
其中,mi(t)为第t次迭代的第i个个体质量,t为当前迭代次数;
更新所有个体的速度vi和位置xi:
其中:randi为(0,1)之间随机数,d表示位置向量的第d维,t为当前迭代次数;
s709:令t=t+1,重复步骤s703-s708,直至迭代次数t大于最大迭代次数nitmax。
进一步地,利用模糊c均值进行粗聚类获取一型隶属度矩阵。
进一步地,机组劣化度d(t)计算方式如下:
一种水电机组劣化趋势区间预测系统,包括离线训练部分s和在线检测部分t;
所述离线训练部分s包括:
s1模块,用于利用健康状态下的水电机组状态训练数据建立水电机组健康模型,即以水电机组健康运行状态下的功率p(t)和水头h(t)为输入,水电机组振动v(t)为输出,通过曲面拟合建立水电机组健康状态模型v(t)=f[p(t),h(t)],t表示水电机组状态监测时刻;
s2模块,用于利用故障状态下的水电机组状态训练数据建立机组劣化趋势模型,即以水电机组故障运行状态下的功率
s3模块,用于依据机组劣化度d(t)构造时间序列上、下界
s4模块,用于分别取时间序列上界
s5模块,用于分别对数据对
s6模块,用于分别使用归一化后的数据对
在线预测部分t包括:
t1模块,用于实时采集待预测水电机组运行状态下的功率和水头,按照离线训练阶段s1-s5的方式得到待预测上、下界的输入属性矩阵;将待预测上、下界的输入属性矩阵分别代入劣化区间上限值和下限值预测模型,得到待预测水电机组的劣化趋势区间。
进一步地,所述s6模块包括:
s601子模块,用于初始化参数,包括两个模糊因子m1和m2、聚类总数c、距离调节参数η、最大迭代次数tmax、停止迭代阈值ε;利用模糊c均值进行粗聚类获取一型隶属度矩阵u=[uik],令初始
s602子模块,用于利用下式计算每个聚类的上下超平面参数:
αi=[xtpix]-1xtpiy
其中,x=[x1]∈rn×(m+1):y为训练数据实际的水电机组劣化趋势数据矩阵;
s603子模块,用于利用类型还原
s604子模块,用于按照下式计算上下隶属度函数
s605子模块,用于利用上下隶属度函数
s606子模块,用于令t=t+1,转至步骤s602,直到相邻两次迭代的差值||αicurrent-αilast||>ε,进入步骤s607,αicurrent是当前迭代的第i类超平面参数,αilast是上一次迭代的第i类超平面参数,ε是停止迭代阈值,或者t>tmax时,停止迭代;
s607子模块,用于计算输入数据点距离上下超平面的距离:
s608子模块,用于依据下式计算数据点分别隶属于上下超平面型的高斯隶属度函数
s609子模块,用于计算模糊权重
s610子模块,用于将模糊权重ωi(xk)输入t-s模糊模型训练确定模型参数。
进一步地,还包括s7模块,用于对所述劣化区间上限值和下限值预测模型进行优化,具体包括:
s701子模块,用于选取预测模型待优化变量为
s702子模块,用于确定待优化变量的上下界[bl,bu],
s703子模块,用于提取水电机组运行状态下的功率和水头验证数据,按照离线训练阶段s1-s5的方式得到上、下界的验证数据对;
s704子模块,用于将上、下界的验证数据对中的上、下界的输入属性矩阵带入劣化区间上限值和下限值预测模型,得到验证用的预测区间;
s705子模块,将验证用的预测区间反归一化,得到验证用的劣化趋势预测区间的上界和下界
s706子模块,计算预测区间覆盖率picp以及预测区间宽度pinaw,以及综合指标cwc;
式中,n为采样总数,r是验证数据的实际劣化趋势的最大值与最小值之间的差值;
式中,ci是验证数据处于劣化趋势预测区间的计数;
式中,ξ为惩罚系数,δ为置信阈值;
s707子模块,计算个体xi的目标函数值:
fiti(t)=t1*cwctrain(t)+t2*cwcopt(t)
其中,t1+t2=1
cwctrain(t)为训练数据的综合指标,cwcopt(t)为验证数据的综合指标;
s708子模块,gsa优化迭代,过程如下:
计算所有个体的引力常数gi(t),i=1,...,n0:
其中,g0为引力常数初始值,β为衰减系数,t为当前迭代次数,nitmax为最大迭代次数;
根据目标函数值fiti计算粒子质量mi:
其中,
计算第i个粒子受到第j个粒子的作用力
其中,gi(t)是第i个个体引力时间常数,mi(t)是第j个粒子的引力质量,mj(t)是第i个粒子的引力质量,xi(t)是第i个粒子的位置向量,xj(t)是第j个粒子的位置向量,
计算所有个体的万有引力fi:
其中,randj为(0,1)之间随机数,t为当前迭代次数;
计算所有个体的加速度
其中,mi(t)为第t次迭代的第i个个体质量,t为当前迭代次数;
更新所有个体的速度vi和位置xi:
其中:randi为(0,1)之间随机数,d表示位置向量的第d维,t为当前迭代次数;
s709子模块,令t=t+1,重复步骤s703-s708,直至迭代次数t大于最大迭代次数nitmax。
总体而言,通过本发明所构思的以上技术方案与现有技术相比:
本发明的一种水电机组劣化趋势区间预测方法,通过区间预测替代传统的点值预测,从而获取比点值预测更多的信息,实现对预测值区间范围与概率分布的评估,有利于在此基础上实现一定的风险分析。
进一步地,本发明的劣化趋势区间预测方法,所训练的二型模糊模型,优选t-s模糊模型,结构清晰。训练过程优选it-2fcr算法,结合二型模糊集合理论,将传统隶属度函数转换为上隶属度和下隶属度,囊括更多非线性自由度表达,提高t-s模糊模型辨识精度。
进一步地,本发明的水电机组劣化趋势区间预测方法,对所述劣化区间上限值和下限值预测模型进行优化,采用验证数据辅助优化预测模型,防止模型过拟合状态,提高在线试验预测模型精度。
附图说明
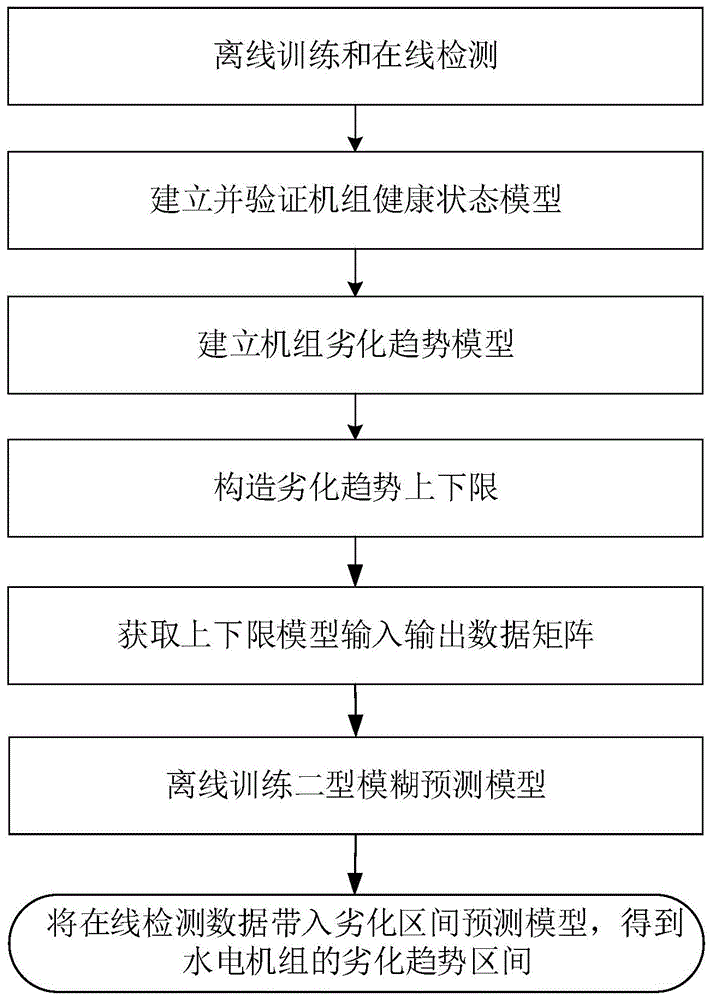
图1为本发明实施例提供的一种基于区间二型t-s模糊模型的水电机组劣化趋势区间预测方法流程图;
图2为本发明实施例提供的一种具体的基于区间二型t-s模糊模型的水电机组劣化趋势区间预测方法流程图;
图3是本发明实施例中对水电机组状态监测数据分析得到的功率-水头-振动关系图;
图4是本发明实施例中对水电机组状态监测数据分析得到的水头-振动关系图;
图5是本发明实施例中对水电机组状态监测数据分析得到的功率-振动关系图;
图6是本发明实施例中利用曲面拟合建立水电机组健康状态模型的曲面拟合结果;
图7是本发明实施例中水电机组劣化趋势时间序列;
图8是本发明实施例中以月为单位统计水电机组劣化趋势;
图9是本发明实施例中劣化趋势区间预测图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
图1为本发明说明书流程图,本发明包括离线训练阶段s和在线检测阶段t。
所述离线训练阶段s具体为:
s1:利用健康状态下的水电机组状态训练数据建立水电机组健康模型,即以水电机组健康运行状态下的功率p(t)和水头h(t)为输入,水电机组振动v(t)为输出,通过曲面拟合建立水电机组健康状态模型v(t)=f[p(t),h(t)],t表示水电机组状态监测时刻;
s2:利用故障状态下的水电机组状态训练数据建立机组劣化趋势模型,即以水电机组故障运行状态下的功率
s3:依据机组劣化度d(t)构造时间序列上、下界
s4:分别取时间序列上界
s5:分别对数据对
s6:分别使用归一化后的数据对
在线预测阶段:
实时采集待预测水电机组运行状态下的功率和水头,按照离线训练阶段s1-s5的方式得到待预测上、下界的输入属性矩阵;将待预测上、下界的输入属性矩阵分别代入劣化区间上限值和下限值预测模型,得到待预测水电机组的劣化趋势区间。
所述训练阶段的二型模糊模型可采用t-s模糊模型、tsk、概率模型中的任意一种。本发明优选t-s模糊模型。
首先对t-s模糊模型进行说明。t-s模糊模型是由一组“if-then”模糊规则来描述的非线性系统,每一个规则代表一个子系统,整个模糊系统即为各个子系统的线性组合。所述if-then模糊规则如下:
规则i:ifx1is
i=1…c,k=1…n,j=1…m
其中
本发明训练t-s模糊模型的具体实现方式为:
s601:初始化参数,包括两个模糊因子m1和m2、聚类总数c、距离调节参数η、最大迭代次数tmax、停止迭代阈值ε;利用模糊c均值进行粗聚类(也可采用随机初始化、k-means算法等)获取一型隶属度矩阵u=[uik],令初始
s602:利用下式计算每个聚类的上下超平面参数:
αi=[xtpix]-1xtpiy
其中,x=[x1]∈rn×(m+1):y为训练数据实际的水电机组劣化趋势数据矩阵;
s603:利用类型还原
s604:按照下式计算上下隶属度函数
s605:利用上下隶属度函数
s606:令t=t+1,转至步骤s602,直到相邻两次迭代的差值||αicurrent-αilast||>ε,进入步骤s607,αicurrent是当前迭代的第i类超平面参数,αilast是上一次迭代的第i类超平面参数,ε是停止迭代阈值,或者t>tmax时,停止迭代;
s607:计算输入数据点距离上下超平面的距离:
s608:依据下式计算数据点分别隶属于上下超平面型的高斯隶属度函数
s609:计算模糊权重
s610:将模糊权重ωi(xk)输入t-s模糊模型训练确定模型参数。
作为优化,本发明还进一步包括步骤s7提取历史数据作为验证数据,利用验证数据对训练得到的模型进行优化,具体的实现方式为:
s701:选取预测模型待优化变量为
s702:确定待优化变量的上下界[bl,bu],
s703:提取水电机组运行状态下的功率和水头验证数据,按照离线训练阶段s1-s5的方式得到上、下界的验证数据对;
s704:将上、下界的验证数据对中的上、下界的输入属性矩阵带入劣化区间上限值和下限值预测模型,得到验证用的预测区间;
s705:将验证用的预测区间反归一化,得到验证用的劣化趋势预测区间的上界和下界
s706:计算预测区间覆盖率picp以及预测区间宽度pinaw,以及综合指标cwc;
式中,n为采样总数,r是验证数据的实际劣化趋势的最大值与最小值之间的差值;
式中,ci是验证数据处于劣化趋势预测区间的计数;
式中,ξ为惩罚系数,δ为置信阈值;
s707:计算个体xi的目标函数值:
fiti(t)=t1*cwctrain(t)+t2*cwcopt(t)
其中,t1+t2=1
cwctrain(t)为训练数据的综合指标,cwcopt(t)为验证数据的综合指标;
s708:gsa优化迭代,过程如下:
计算所有个体的引力常数gi(i=1,...,n0):
其中,g0为引力常数初始值,β为衰减系数,t为当前迭代次数,nitmax为最大迭代次数。
根据目标函数值fiti计算粒子质量mi(i=1,...,n0):
其中,best=minfitj,worst=maxfitj;
计算第i个粒子受到第j个粒子的作用力
其中,gi(t)是第i个个体引力时间常数,mi(t)是第j个粒子的引力质量,mj(t)是第i个粒子的引力质量,xi(t)是第i个粒子的位置向量,xj(t)是第j个粒子的位置向量,
计算所有个体的万有引力fi:
其中,randj为(0,1)之间随机数。
计算所有个体的加速度ai:
其中,mi为第i个个体质量;
更新所有个体的速度vi和位置xi:
其中:randi为(0,1)之间随机数,d表示位置向量的第d维,t为当前迭代次数,。
s709:令t=t+1重复步骤s703-s708,直至迭代次数t大于最大迭代次数nitmax。
实施例:
步骤1、水电机组状态监测数据时间序列数据data分析,分析工作水头-振动关系图,功率-振动关系图,功率-工作水头-振动关系图,如图3-5所示,确定机组标准健康状态。
步骤2、利用无故障健康状态下(2008年7月24-2009年1月20日共计853条数据)的机组状态训练数据建立水电机组健康模型。以水电机组运行状态的功率p和水头h为输入,水电机组振动v为输出,通过matlab的曲面拟合建立水电机组健康状态模型v(t)=f[p(t),h(t)],拟合结果如图6所示,拟合精度误差控制在4.5%以内。
步骤3、利用故障状态下(2011年5月12日-2011年9月23,共计543条数据)的机组状态训练数据建立机组劣化趋势模型。将故障状态下的机组状态监测数据,功率p(t)和工作水头h(t),带入机组健康模型的到当前工况下的机组标准健康振动状态v(t),并与当前实际的机组振动状态r(t)对比,获得机组劣化度d(t)计算方式如下:
式中,t表示水电机组状态监测时刻。
图7为劣化趋势时间序列图,以月为单位分析机组劣化趋势的单调性,从图8可以看出劣化趋势呈单调递增趋势。
步骤4、预测水电机组劣化趋势区间,并进行模型整体优化。
初始化gsa算法最大迭代次数nitmax=50、群体规模n0=30、初始引力常数g0=100,衰减系数β=20;it2-fcr算法聚类规则数c=4、最大迭代次数tmax=100、停止迭代阈值ε=1e-5;
待优化变量的上下界[bl,bu],
l=7,ll=543;
it2-fcr算法聚类规则数c=4、最大迭代次数tmax=100、停止迭代阈值ε=1e-5;
最终水电机组劣化趋势上界预测模型和上界预测最佳模型参数为:
最终水电机组劣化趋势区间预测结果如图9,区间覆盖率picp=0.9,区间宽度pinaw=0.5655,综合指标cwc=0.5655,结果表明本发明方法实现机组劣化趋势区间预测,达到较高覆盖率和较小区间宽度,效果良好。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!