一种基于DDPG算法的水下机器人推进器故障容错控制方法
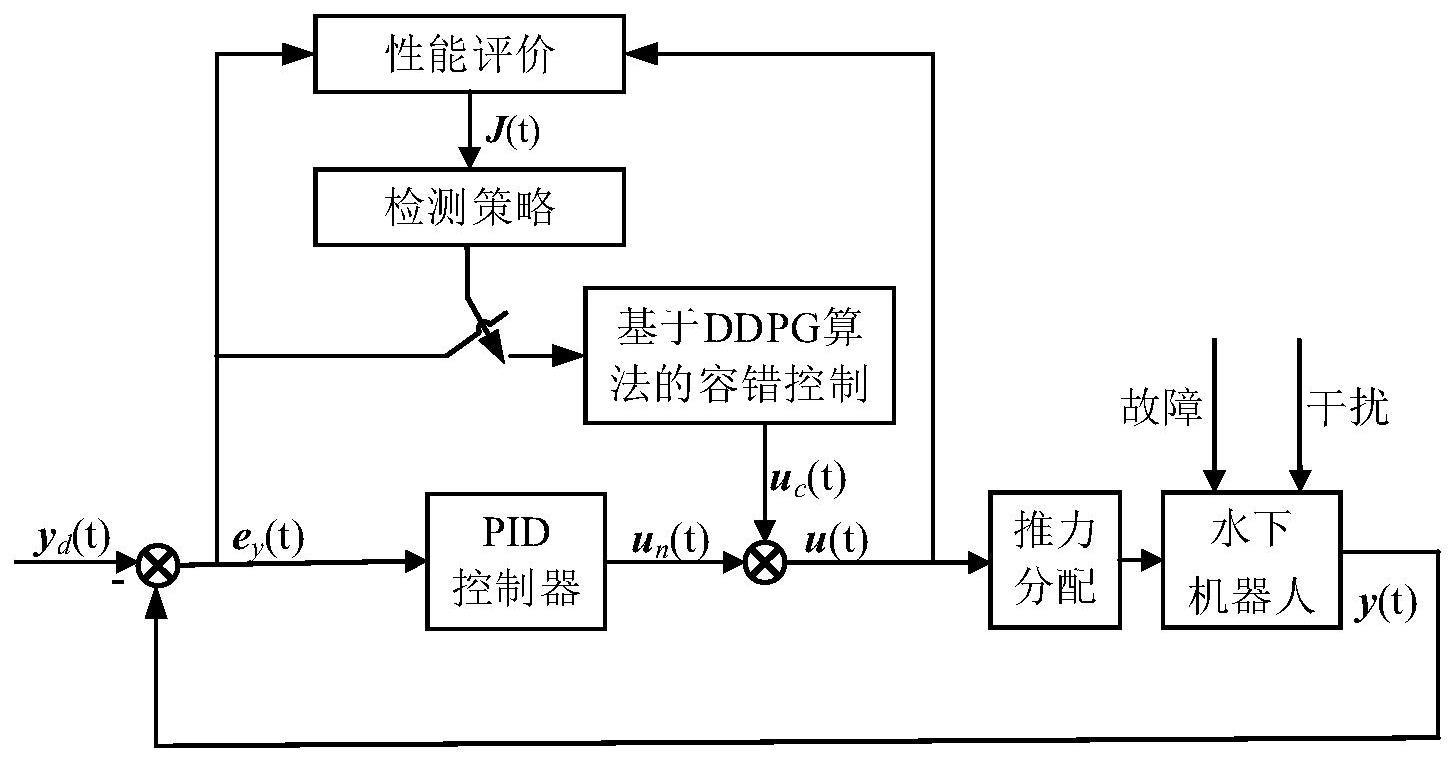
本发明属于水下机器人容错控制,具体涉及一种基于ddpg算法的水下机器人推进器故障容错控制方法。
背景技术:
1、作为人类探索海洋的得力助手,水下机器人是多种现代高科技技术集成的产物,通过远程遥控和特定的功能模块可完成资源探测、水下作业和特种作战等任务,对于未来海洋科学技术的发展具有特殊意义。推进器是水下机器人必备的动力部件,与其它部件相比,推进器要在高压、高盐环境下长时间高负荷运转,是水下机器人负荷最重的部件。推进器故障时性能明显低于正常水平,难以完成预期的作业任务,甚至会对水下机器人的安全构成威胁。潜深越大,承载的静水压力也越大,推进器出现故障的概率也成倍增加。因此,如果能在故障发生时及时采取容错控制策略,将大幅提高水下机器人的安全性。
2、容错控制的基本思想是在故障发生时使用系统的冗余资源来保持原始性能,或者在牺牲一定性能的情况下确保系统能够在指定的时间内安全地完成计划任务。目前,水下机器人多通过集成故障诊断单元提供推进器故障信息来实现容错控制,然而深海环境的复杂和水下机器人自身的非线性、强耦合和模型的不确定性使其故障诊断成为了难点,另外由于故障发生初期无法提供足够多的有效数据,因此对于数据驱动的容错控制方法也同样具有挑战性。因此需要建立一种有效的不依赖于故障诊断单元的水下机器人容错控制方法。
3、强化学习的快速发展在处理模型的不确定性方面具有巨大的优势,为容错控制问题的解决提供了新的思路。考虑到深度确定性策略梯度(deep deterministic policygradient,ddpg)算法在连续动作空间中能够有效学习的优点,本发明将其应用到水下机器人容错控制领域,不需要故障诊断单元提供故障的精确估计信息,可以有效提高水下机器人轨迹跟踪控制系统的可靠性。
技术实现思路
1、针对含有模型不确定性、推进器饱和、未知外部干扰和推进器故障等问题的水下机器人非线性系统,本发明提出了一种基于深度确定性策略梯度算法的水下机器人推进器容错控制方法,首先考虑系统正常运行的情况设计了比例-积分-微分控制器(proportionintegration differentiation,pid控制器),并利用二次型指标对系统性能进行实时检测。当水下机器人性能下降超过设定阈值时,判定为推进器发生了故障,由基于深度确定性策略梯度算法设计的容错控制算法生成控制补偿信号,补偿推进器故障对水下机器人造成的影响,从而实现容错控制。本发明所提方法增强了水下机器人在推进器故障情况下的轨迹跟踪控制性能,同时具有自学习能力,适用于复杂的海洋环境。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种基于ddpg算法的水下机器人推进器故障容错控制方法,包括以下步骤:
4、步骤1:同时考虑模型不确定性、推进器饱和、未知外部干扰和推进器故障,构建水下机器人非线性模型;
5、步骤2:考虑系统正常运行时的情况,通过期望轨迹与水下机器人非线性模型的输出信息得到水下机器人轨迹跟踪误差,设计比例-积分-微分控制器实现水下机器人的轨迹跟踪控制;
6、步骤3:基于步骤2得到的轨迹跟踪误差及控制器的输出信号,构建二次型性能指标实时检测系统性能,并给出检测策略用于判断系统是否发生推进器故障;
7、步骤4:基于步骤3给出的检测策略,当判定系统发生故障时,设计ddpg算法的奖励函数,基于水下机器人的输出对ddpg算法中的策略网络和评价网络进行训练,得到控制器补偿信号,从而实现水下机器人的容错控制。
8、进一步地,步骤1的具体过程如下:
9、步骤1.1:所述水下机器人非线性模型包括运动学模型和动力学模型,在不考虑故障时分别如式(1)和式(2)所示:
10、
11、
12、式中,为水下机器人的位置向量,其中ηx,ηy,ηz为水下机器人在惯性坐标系中的位置坐标,ηθ,ηψ分别为水下机器人的横倾角、纵倾角、艏向角;为η的一阶导数;v=[vu,vv,vw,vp,vq,vr]t为水下机器人的速度向量,其中vu,vv,vw分别为水下机器人线速度矢量在载体坐标系中的3个分量,vp,vq,vr分别为水下机器人角速度矢量在载体坐标系中的3个分量;为v的一阶导数;mrb是刚体惯量矩阵,ma表示水下机器人在加速过程中所受到的来自周围液体惯性作用的水动力矩阵,c(v)是科氏力与向心力矩阵,d(|v|)是与航行器航行速度有函数关系的阻尼力矩阵,g(η)表示回复力;τrb为水下机器人推进器产生的力和力矩向量,τenv表示因环境产生的未知干扰;jc(η)为坐标变换矩阵,其表达式为:
13、
14、式中,03表示大小为“3×3”的零矩阵,
15、
16、
17、由于水下机器人具有较强的非线性和耦合特性,基于动态建模技术获得的模型具有较大的不确定性,表示如下:
18、
19、
20、式中,分别为刚体惯量矩阵、水动力惯量矩阵、科氏力与向心力矩阵、水阻尼矩阵的标称值,δmrb,δma,δc(v),δd(|v|)分别表示相对应矩阵的不确定性;
21、步骤1.2:考虑bt为推力分配矩阵,trb为推进器产生的推力矢量,则有τrb=bttrb;推进器的输出受到其输出能力的限制,考虑推进器输出的上限和下限分别为tmax和tmin,则推进器饱和由下式表示:
22、sat(trb)=trb+λ
23、式中,
24、
25、考虑水下机器人发生推进器故障,此时推进器真实输出为trb,f,则有:
26、trb,f=trb-tf
27、式中tf=fktrb+fb,fk=diag(k1,k2,k3,k4,k5,k6)和fb=diag(b1,b2,b3,b4,b5,b6)是未知的推进器故障系数矩阵,满足06≤fk≤i6,06≤fb≤i6,k1,k2,k3,k4,k5,k6分别表示对应推进器的乘性故障系数,b1,b2,b3,b4,b5,b6分别表示对应推进器的加性故障系数,其中06表示大小为“6×6”的零矩阵,i6表示大小为“6×6”的单位矩阵;
28、步骤1.3:选取状态变量x1(t)=η(t),x2(t)=v(t),测量变量为y(t)=x1(t)=η(t),控制变量u(t)=trb(t),则(1)、(2)式所示的水下机器人系统在考虑发生推进器故障的情况时描述成如下状态空间方程的形式:
29、
30、式中,
31、h(x2(t))=-(mrb+ma)-1(c(x2(t))+d(x2(t)|))≤0
32、bu=(mrb+ma)-1bt,bd=(mrb+ma)-1,d(t)=τenv(t),f(t)=tf(t)。
33、进一步地,步骤2中,考虑系统在正常运行时沿着期望轨迹yd(t)做轨迹跟踪运动,因此有轨迹跟踪误差ey(t)=y(t)-yd(t);设计比例-积分-微分控制器如下式所示:
34、
35、式中,上标代表矩阵bu的伪逆矩阵,kp,ki,kd分别是对轨迹跟踪误差ey(t)及其积分、微分量的加权。
36、进一步地,步骤3中,给出如(4)式所示的二次型性能指标:
37、
38、式中p1和p2是性能指标的权值矩阵,tn是时间窗长度;在系统稳定的情况下,给出基于性能的检测阈值jth(t)如(5)式所示:
39、
40、式中ε是人为给定的足够小的常数,由此得到如下检测策略:
41、
42、由此可知,系统正常运行时j(t)小于等于阈值jth(t),补偿算法不启动,即u(t)=un(t),un(t)为步骤2所设计的比例-积分-微分控制器产生的控制信号;而当j(t)大于阈值jth(t)时,视为推进器故障引起的系统性能下降,触发后续容错控制算法。
43、进一步地,步骤4的具体过程如下:
44、步骤4.1:选取补偿控制信号uc(t)作为ddpg算法中的动作向量a(t),作为ddpg算法中的观测状态向量s(t),考虑如(6)式所示的奖励函数:
45、
46、式中||·||2表示2-范数,c表示当训练得到的ddpg算法代理接近理想条件时人为给予的恒定奖励,由奖励函数得长期累积奖励如下式所示:
47、
48、式中γ∈(0,1)表示折扣系数,它使累积奖励随着迭代次数的增加而保持不变;r(τ)表示τ时刻的奖励值;
49、由此水下机器人推进器容错控制问题就转化成了让水下机器人学习在发生推进器故障之后如何调整补偿控制信号uc(t),从而获得最大的累积奖励值r(t),为:
50、
51、步骤4.2:构建ddpg算法中的4个神经网络,其中当前策略网络负责学习策略函数μ,权值为θμ,而当前评价网络负责学习逼近值函数q,权值为θq,目标策略网络μ′权值为θμ′,目标评价网络q′权值为θq′,两个目标网络的网络结构与各自对应的当前网络完全相同;
52、步骤4.3:给定ddpg算法最大回合数ne,每回合最大迭代次数ns,折扣系数γ,目标网络更新率δ,初始化当前策略网络权值θμ,当前评价网络权值θq,并将参数复制到相对应的两个目标网络,初始化数据样本经验池;
53、步骤4.4:初始化噪声获取当前t时刻状态s(t);
54、步骤4.5:由当前策略网络计算动作a(t),为:
55、
56、在水下机器人系统中执行动作a(t),获得下一时刻状态s(t+1)和r(t),将产生的数据样本(s(t),a(t),s(t+1),r(t))存储到数据样本经验池中用于训练策略网络和评价网络;
57、步骤4.6:在数据样本经验池中随机选取n组数据(s(i),a(i),s(i+1),r(i)),(i=1,…,n),求解式(7):
58、λ(i)=r(i)+γq’(s(i+1),μ’(s(i+1)|θμ’)|θq’) (7)
59、构造评价网络的损失函数:
60、
61、求解令(8)式最小的权值θq,并更新当前评价网络;
62、当前策略网络采用梯度下降法进行更新,计算样本的策略梯度为:
63、
64、求解令(9)式最小的权值θμ,并更新当前策略网络;
65、根据步骤4.3中设定好的更新率δ对目标策略网络和目标评价网络的权值进行更新:
66、θμ’=δθμ+(1-δ)θμ’,θq’=δθq+(1-δ)θq’
67、步骤4.7:步骤4.5~4.6视为一次迭代过程,当经过ns次迭代后返回步骤4.4开始下一回合训练,当ne个回合训练结束后,策略网络产生最优策略μ*(s|θμ),将训练好的策略网络作为容错控制器用于生成控制补偿信号,为:
68、uc(t)=μ*(s(t)|θμ)
69、由前述步骤2可知,当j(t)大于阈值jth(t)时,视为推进器故障引起的系统性能下降,触发容错控制模块,此时ddpg算法利用实时信息产生控制补偿信号uc(t),有u(t)=un(t)+uc(t),进而实现水下机器人容错控制。
70、本发明所带来的有益技术效果:
71、本发明考虑了具有模型不确定性、推进器饱和、未知外部干扰和推进器故障的水下机器人非线性模型,采用二次型指标来实时检测系统的性能。当无故障时,采用比例-积分-微分控制器实现水下机器人的轨迹跟踪任务,当推进器故障导致的系统性能下降超过预设阈值时,容错控制器能够产生控制补偿信号补偿故障带来的影响。其中容错控制器的设计基于深度确定性策略梯度算法,通过最小化性能指标函数求解出轨迹跟踪的最优控制补偿信号,不需要先验故障信息,也不需要故障诊断单元提供精确的故障信息,同时深度确定性策略梯度算法具有自学习功能,因此可以适用于不同类型的推进器故障,更适用于复杂的海洋环境。本发明能够有效解决水下机器人在模型存在不确定性、推进器饱和、未知外部干扰及推进器故障情况下的轨迹跟踪容错控制问题。
- 还没有人留言评论。精彩留言会获得点赞!