基于深度强化学习的无人机编队保持控制方法与流程
本发明涉及智能控制和无人机技术的交叉领域,特别是指一种基于深度强化学习的无人机编队保持控制方法。
背景技术:
1、针对无人机编队保持航迹指令生成的传统方法,如pid(比例积分微分)算法,参数往往需要手动整定,且鲁棒性较差,其控制性能在面对复杂环境或剧烈扰动时往往会急剧下降甚至失效;模型预测控制等方法一般需要被控对象和扰动等环境要素的精确模型来进行控制律和制导律的设计,但是这些模型通常是非线性且极为复杂的,基于此,建立一个精准的控制模型往往较为困难,而且模型的鲁棒性也难以得到保证。在这种背景下,善于处理复杂随机性的深度强化学习方法受到了多方关注。
2、深度强化学习是机器学习领域的重要组成部分,是处理序贯决策问题的有力手段,目前被广泛应用于机器人、游戏、金融、交通等领域。使用深度强化学习训练往往需要建立其马尔科夫决策过程,其目标是使智能体在与训练场景的互动过程中,在累计奖励函数值的指导下,训练得到一种最佳策略,该策略使智能体具备根据状态空间变化合理选取动作的能力。在使用该算法进行训练时,能够主动在环境模型中设计较强的随机性,可以解决复杂随机环境中的决策控制问题,适用于无人机编队航迹指令生成问题的解决。
技术实现思路
1、本发明要解决的技术问题是提供一种基于深度强化学习的无人机编队保持控制方法,以提高无人机编队队形保持控制的智能性、鲁棒性、准确性。
2、为解决上述技术问题,本发明提供技术方案如下:
3、一种基于深度强化学习的无人机编队保持控制方法,包括:
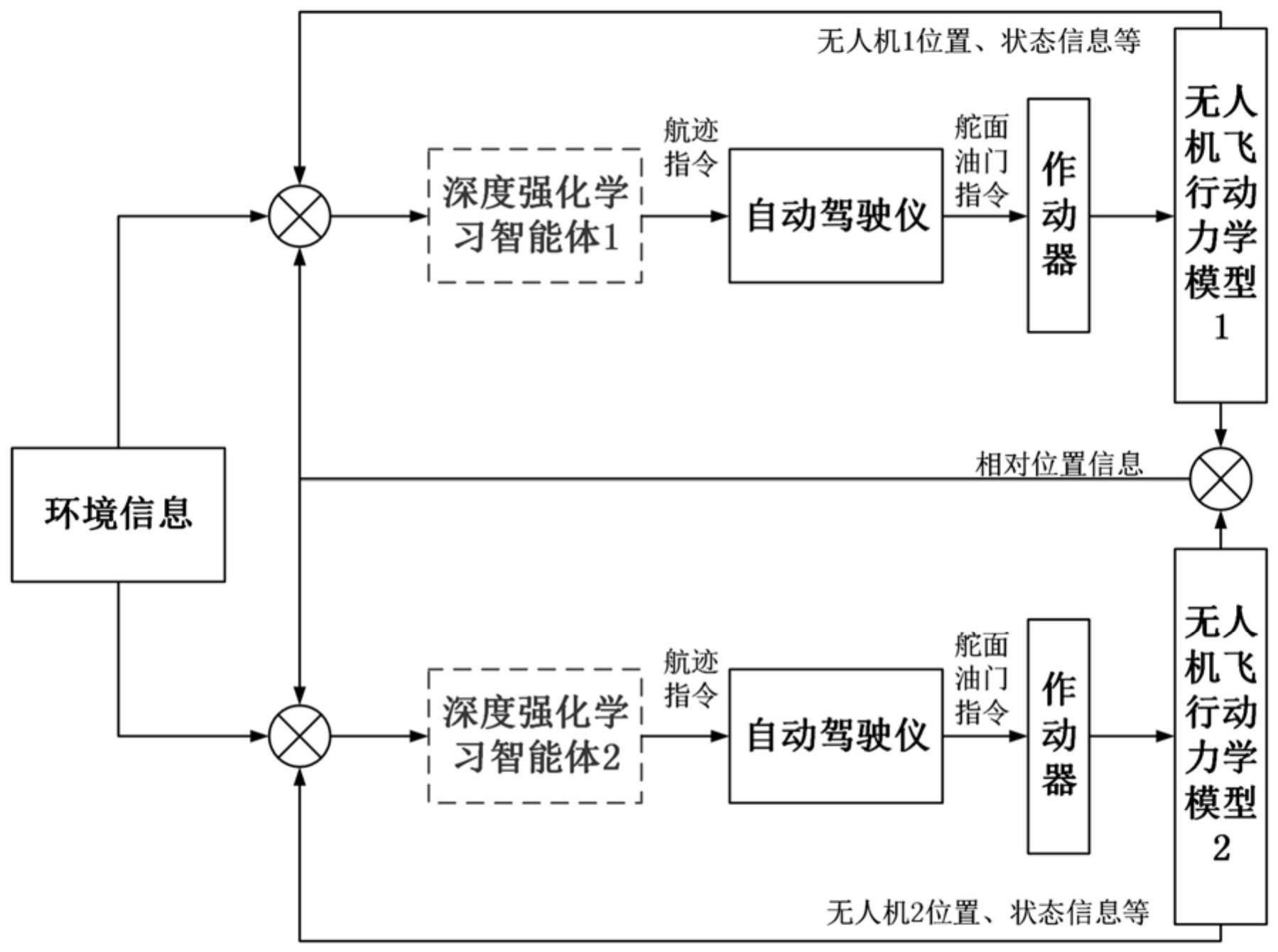
4、步骤1:根据飞行力学原理,建立无人机飞行动力学模型和运动学模型,并根据虚拟长机拓扑结构,设计无人机相对运动模型;
5、步骤2:根据pid控制原理,设计无人机的增稳-姿态-航迹的pid串级控制器;
6、步骤3:设计每一个无人机的mappo智能体的马尔科夫决策过程,包括状态空间、动作空间、奖励函数和终止条件;
7、步骤4:设计适用于符合该马尔可夫决策模型的神经网络结构;
8、步骤5:对设计的mappo智能体进行训练,智能体的输入为状态空间,输出为无人机控制指令,pid串级控制器接收该控制指令进而操控无人机完成编队保持。
9、本发明具有以下有益效果:
10、本发明的基于深度强化学习的无人机编队保持控制方法,是将独立学习范式与近端策略优化算法相结合,进而处理多机编队(多智能体)问题。首先,根据飞行力学原理建立无人机单机的运动学和动力学方程并基于虚拟长机结构建立无人机编队相对运动模型;进一步,设计各无人机的pid串级控制器,使无人机能准确快速地跟踪指令;然后,根据mappo算法设计编队队形保持过程的马尔科夫决策模型、神经网络结构和算法流程,使多无人机可以在风扰等复杂环境中保持编队,同时,将俯仰角速度等无人机关键状态量加入状态空间,使该方法的控制精度获得了极大的提高。本发明利用深度强化学习算法建立复杂环境与无人机指令之间的映射关系,提高了无人机编队队形保持控制的智能性、鲁棒性、准确性。
技术特征:
1.一种基于深度强化学习的无人机编队保持控制方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述步骤1包括:
3.根据权利要求1所述的方法,其特征在于,所述步骤2中,pid串级控制器包括依次连接的航迹pid控制器、姿态角pid控制器、操纵舵面和无人机扰动线化运动模型,其中:
4.根据权利要求1所述的方法,其特征在于,所述步骤3中,状态空间s的表达式为:
5.根据权利要求1所述的方法,其特征在于,所述步骤3中,动作空间包括离散的速度、航迹偏角和航迹倾角指令,表达式分别为:
6.根据权利要求1所述的方法,其特征在于,所述步骤3中,奖励函数的表达式为:
7.根据权利要求1所述的方法,其特征在于,所述步骤3中,第i个智能体单回合训练的终止条件为:
8.根据权利要求1所述的方法,其特征在于,所述步骤4中,神经网络结构采用actor-critic框架,其中,actor网络由3层全连接层构成,隐含节点数分别为128、128和27,前两层均使用relu激活函数,最后一层使用softmax激活函数,最终输出为动作库中各动作在当前策略下的概率分布;critic网络包含4层全连接层,前3层的隐含节点数分别为128、128和128,均使用relu激活函数,最后一层的网络节点数为1,输出值为当前状态的值函数。
9.根据权利要求1所述的方法,其特征在于,所述步骤5包括:
10.根据权利要求9所述的方法,其特征在于,所述步骤5还包括:
技术总结
本发明公开了一种基于深度强化学习的无人机编队保持控制方法,属于智能控制和无人机技术的交叉领域,所述方法包括:建立无人机飞行动力学模型和运动学模型,并根据虚拟长机拓扑结构,设计无人机相对运动模型;设计无人机的增稳‑姿态‑航迹的PID串级控制器;设计每一个无人机的MAPPO智能体的马尔科夫决策过程,包括状态空间、动作空间、奖励函数和终止条件;设计适用于符合该马尔可夫决策模型的神经网络结构;对设计的MAPPO智能体进行训练,智能体的输入为状态空间,输出为无人机控制指令,PID串级控制器接收该控制指令进而操控无人机完成编队保持。本发明提高了无人机编队队形保持控制的智能性、鲁棒性、准确性。
技术研发人员:焦瑞豪,王建岭,王永波,吴晗,郝铭慧
受保护的技术使用者:智洋创新科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!