一种基于强化学习的室内仓储差分机器人局部避障方法
本发明涉及局部避障,尤其涉及一种基于强化学习的室内仓储差分机器人局部避障方法。
背景技术:
1、在室内仓储环境中,局部避障是差分机器人智能控制中的重要任务之一。差分式机器人的局部避障可以定义为:机器人根据实时感知信息以及全局路径信息,规划一个合理的路径来避开未知的障碍物,并且这个路径不会偏离全局的路径规划。
2、目前局部避障算法有dwa滑动窗口法、人工势场法、teb算法等,这些算法在已知环境中,当遇到未知静态障碍物时,表现得效果能够令人满意;但当遇到动态障碍物时,它们的表现效果远不如静态场景下的效果,如当仓库中有较多的机器人和工作人员时,机器人容易发生震荡和紧急停止现象,机器人的工作效率低下,且搬运的货物可能会掉下来,造成财产损失并具有一定的危险性。
技术实现思路
1、为克服现有技术的不足,本发明提出一种基于强化学习的室内仓储差分机器人局部避障方法。
2、本发明的技术方案是这样实现的:
3、一种基于强化学习的室内仓储差分机器人局部避障方法,包括步骤:
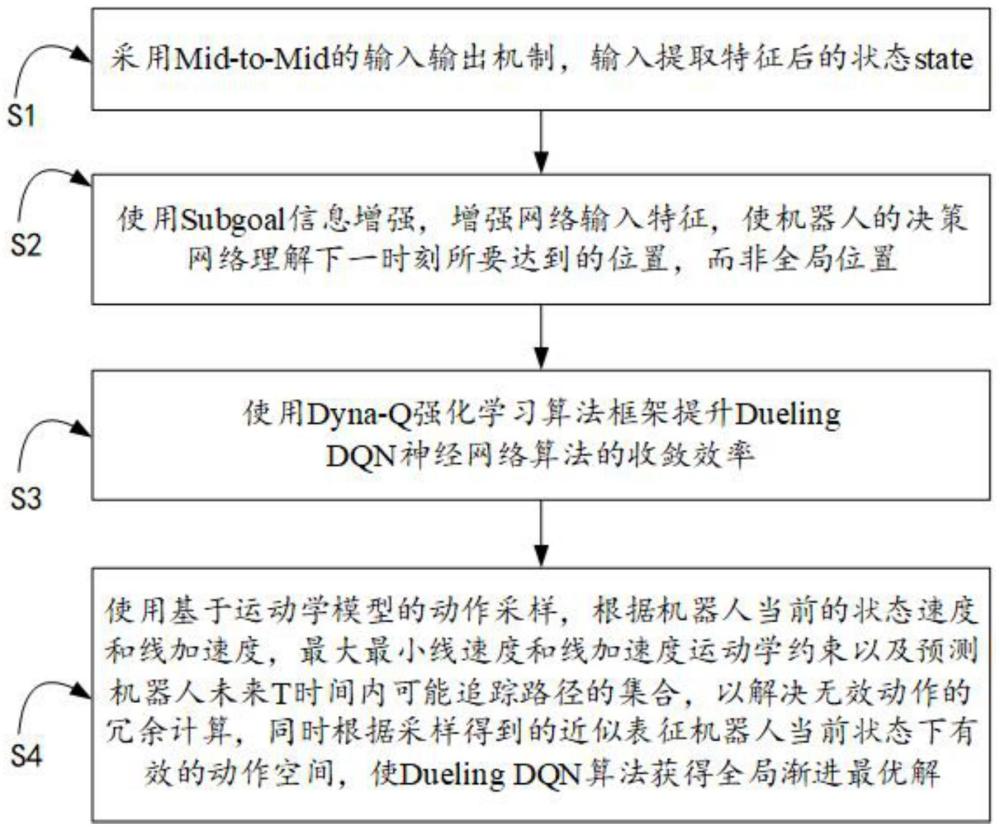
4、s1:采用mid-to-mid的输入输出机制,输入提取特征后的状态state,所述状态state包括机器人已知地图位置和姿态(robotx,roboty,robotyaw,)、经过极坐标转换后的机器人与目标点的相对位姿(l,theta)、滤波后的激光雷达数据以及机器人的固定动作集合(v,w),其中,l代表机器人与目标点的距离,theta代表机器人的位置与目标点,在全局地图上的矢量夹角,l和theta公式为:
5、
6、
7、s2:使用subgoal信息增强,增强网络输入特征,使机器人的决策网络理解下一时刻所要达到的位置,而非全局位置;
8、s3:使用dyna-q强化学习算法框架提升dueling dqn神经网络算法的收敛效率,所述dyna-q强化学习算法包括步骤:
9、s31:初始化状态s和其动作a的集合以及所对应的价值q(s,a)和模型model(s,a);
10、s32:循环迭代训练,对于每一代训练时,更新状态s,并通过∈-greedy算法选择并执行动作a,得到奖励值r以及下一时刻的状态s’,根据这四个状态更新q值;
11、s33:与真实环境交互后,更新model(s,a);
12、s34:重复n次模拟真实环境,每次随机选择存在内存中的状态s,并随机选择a.通过模型计算出s’和r,再通过q值更新公式进行更新;
13、s4:使用基于运动学模型的动作采样,根据机器人当前的状态速度和线加速度,最大最小线速度和线加速度运动学约束以及预测机器人未来t时间内可能追踪路径的集合,以解决无效动作的冗余计算,同时根据采样得到的近似表征机器人当前状态下有效的动作空间,使dueling dqn算法获得全局渐进最优解。
14、进一步地,所述s1包括步骤:若激光雷达的点云数据存在异常点,采用均值滤波的方式来清理激光雷达的数据。
15、进一步地,所述s2包括步骤:a*在已知地图下根据机器人的实时位置和目标点所规划的全局路径的一个特殊的点,所述特殊点根据机器人追踪全局路径取一个固定阈值的位置。
16、进一步地,所述s3包括步骤:采用基于模型的强化学习算法框架dyna-q,在训练初期使用其他模型所生成的样本进行预训练,加速网络快速收敛到局部最优解,再通过不断迭代探索使算法收敛于全局渐进最优解。
17、进一步地,所述s4包括步骤:
18、s41:数据采集时,随机选择起始点和目标点的位置姿态,dwa算法结合a*算法进行路径追踪和避障,与此同时进行数据采集,并使用dueling dqn同样的奖励函数r计算每一个决策动作,具体奖励函数的如下所示
19、
20、其中gdpre表示机器人在未执行决策动作前离目标点的距离,gdnow表示机器人在执行决策动作后离目标点的距离;
21、s42:存储到replay buffer中,进而学习dwa算法的策略。
22、本发明的有益效果在于,与现有技术相比,本发明基于模型学习的dyna-q算法框架,学习dwa算法的避障策略,进行模型预训练,并通过对网络输入的特征提取,增加subgoal信息,并基于模型采样动作等手段,加速局部避障算法收敛速度并有效提高算法的上限。
技术特征:
1.一种基于强化学习的室内仓储差分机器人局部避障方法,其特征在于,包括步骤:
2.如权利要求1所述的基于强化学习的室内仓储差分机器人局部避障方法,其特征在于,所述s1包括步骤:若激光雷达的点云数据存在异常点,采用均值滤波的方式来清理激光雷达的数据。
3.如权利要求1所述的基于强化学习的室内仓储差分机器人局部避障方法,其特征在于,所述s2包括步骤:a*在已知地图下根据机器人的实时位置和目标点所规划的全局路径的一个特殊的点,所述特殊点根据机器人追踪全局路径取一个固定阈值的位置。
4.如权利要求1所述的基于强化学习的室内仓储差分机器人局部避障方法,其特征在于,所述s3包括步骤:采用基于模型的强化学习算法框架dyna-q,在训练初期使用其他模型所生成的样本进行预训练,加速网络快速收敛到局部最优解,再通过不断迭代探索使算法收敛于全局渐进最优解。
5.如权利要求1所述的基于强化学习的室内仓储差分机器人局部避障方法,其特征在于,所述s4包括步骤:
技术总结
本发明公开了一种基于强化学习的室内仓储差分机器人局部避障方法,包括步骤:采用Mid‑to‑Mid的输入输出机制,输入提取特征后的状态state;使用Subgoal信息增强,增强网络输入特征,使机器人的决策网络理解下一时刻所要达到的位置,而非全局位置;使用Dyna‑Q强化学习算法框架提升Dueling DQN神经网络算法的收敛效率;使用基于运动学模型的动作采样,解决无效动作的冗余计算,同时根据采样得到的近似表征机器人当前状态下有效的动作空间,使Dueling DQN算法获得全局渐进最优解。本发明基于模型学习的dyna‑q算法框架,学习dwa算法的避障策略,进行模型预训练,并通过对网络输入的特征提取,增加subgoal信息,并基于模型采样动作等手段,加速局部避障算法收敛速度并有效提高算法的上限。
技术研发人员:张懿,袁越,吴新玲,杨文欢
受保护的技术使用者:广东外语外贸大学南国商学院
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!