一种基于深度强化学习的多智能体避障导航控制方法
本发明专利属于多智能体系统和强化学习领域,是一种基于深度强化学习的多智能体避障导航控制方法,涉及到随机障碍物环境建模、强化学习要素设计、基于注意力机制的网络模型设计以及算法训练流程设计等一系列方法。
背景技术:
1、多智能体协同避障导航问题是无人机、无人车等多智能体系统的重要研究分支,目前的避障导航控制算法缺乏智能体间的协同决策能力,容易导致智能体间避障路径的冲突,极大降低了系统整体的避障效率,并且控制方法应对随机障碍物环境以及智能体数量动态变化的鲁棒性与灵活性也有待提高。
2、强化学习是一种通过试错和延迟回报机制进行学习的机器学习方法,智能体根据环境的回报反馈信息对行为决策的优劣进行评估,并以最大化累积回报为目标学习和优化智能体策略,深度强化学习算法展现出强大的学习能力并在各种复杂问题上取得了显著成果。随机障碍物环境中的多智能体协同避障导航控制任务可被建模为分布式的部分可观察马尔可夫决策过程,并使用多智能体深度强化学习算法对智能体策略进行求解。智能体通过加载强化学习算法训练得到的最优避障运动控制策略,即可根据智能体间的有限通信交互以及对环境的观测信息进行协同动作决策,成功运动至各自的目标点位置并避免发生碰撞。
3、注意力机制是深度学习领域中一种能够自适应选择输入数据的不同部分并加权的方法,从而将网络模型聚焦于对结果贡献最大的部分数据以提高网络性能。与传统的全连接神经网络相比,注意力机制具有局部化、灵活和解释性强等特点,有助于减少模型参数和计算复杂度,提高模型效率。目前,注意力机制已经在自然语言处理、计算机视觉、推荐系统等领域得到广泛应用并取得了显著的成果。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于深度强化学习的多智能体避障导航控制方法,实现安全且鲁棒的多智能体协同避障导航控制,有效提高多智能体集群对障碍物场景以及智能体数量动态变化的适应能力,算法具有分布式执行的灵活性优势。
2、本发明的目的是通过以下技术方案来实现的:
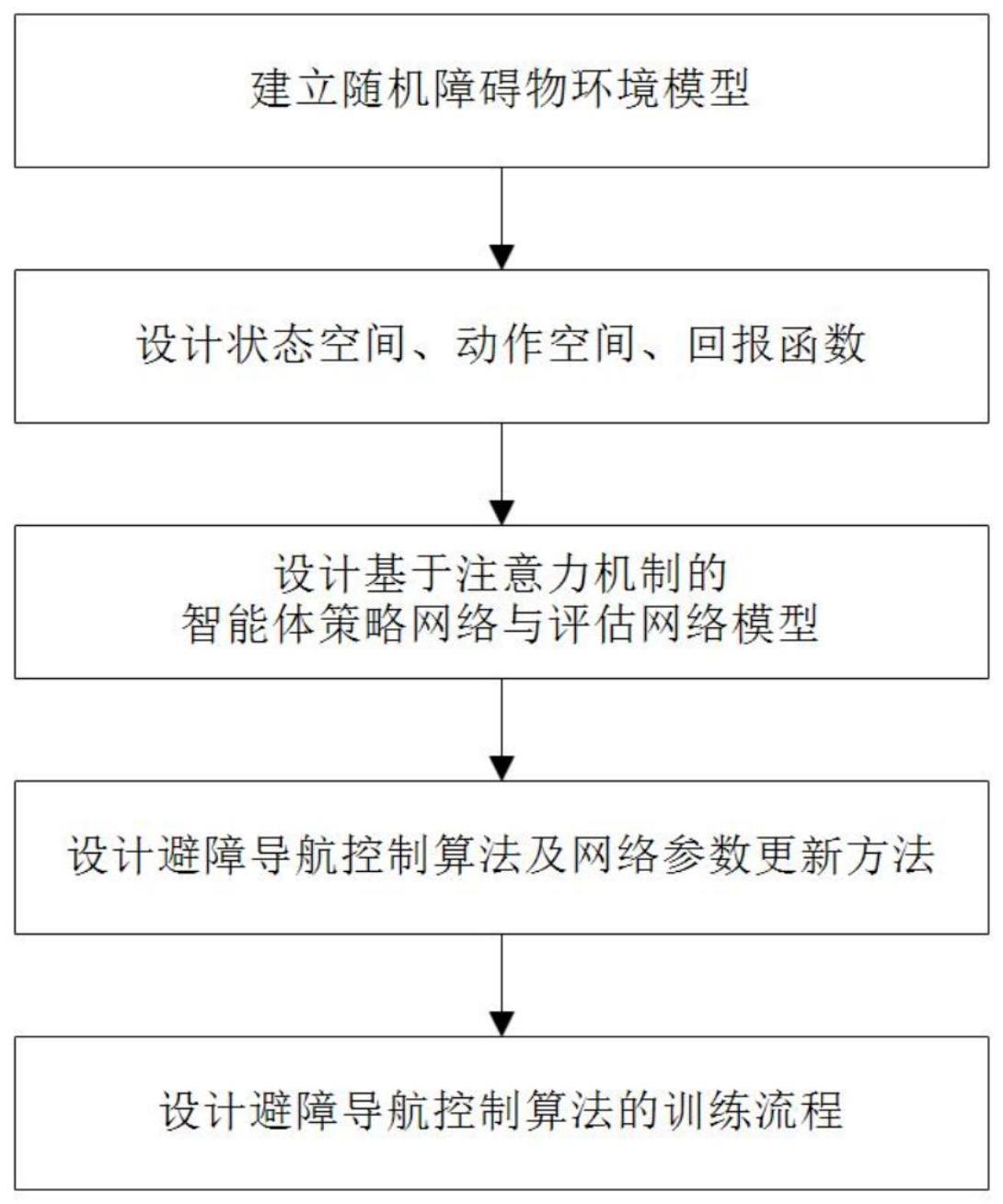
3、一种基于深度强化学习的多智能体避障导航控制方法,包括以下步骤:
4、步骤s1、建立随机障碍物环境模型,包括智能体运动、随机通信概率和障碍物探测模型,为多智能体避障导航控制算法的离线训练提供仿真环境;
5、步骤s2、状态空间设计:基于所述步骤s1中的随机障碍物环境模型,利用智能体运动状态及障碍物位置信息构造智能体i的局部观测oi,通过拼接所有智能体的局部观测构造环境全局状态s;
6、动作空间设计:将控制智能体运动的加速度定义为智能体的动作,智能体具有连续动作空间;
7、回报函数设计:以智能体运动至目标位置为目标,对到达目标点进行奖励,以智能体、障碍物间的避障为约束,对发生碰撞进行惩罚,并通过构造辅助奖励解决回报的稀疏性问题;
8、步骤s3、分别将所述步骤s2中的全局状态s和观测状态oi作为评估网络和策略网络的输入,基于注意力机制设计智能体的策略网络与评估网络模型结构;
9、步骤s4、设计基于深度强化学习的多智能体避障导航算法框架,并给出所述步骤s3中的策略网络与评估网络的参数更新方法;
10、步骤s5、设计避障导航控制算法的训练流程,智能体与所述步骤s1中的障碍物环境不断交互产生经验信息,利用所述步骤s4中的参数更新方法优化所述步骤s3中的网络参数,智能体通过加载训练完成得到的策略网络模型即可实现分布式的协同避障导航。
11、上述技术方案中,所述步骤s1包括:
12、建立智能体运动模型,将每个智能体视为具有半径ra的圆形实体,使用二阶微分系统描述智能体i的圆心运动状态:
13、
14、s.t.||vi||≤vmax
15、||ui||≤umax
16、其中,pi、vi、ui分别表示智能体i的位置、速度和加速度向量,与分别表示pi与vi的微分,n表示集群中智能体的数目,由于智能体需要满足实际运动学约束,因此最大速度和加速度分别限制为vmax和umax;
17、建立随机通信概率模型,智能体间成功通信的概率随着距离的增加而呈指数级降低:
18、
19、其中,表示智能体i与智能体j成功进行通信的概率,rc表示确定性通信半径,在此范围内智能体间能够进行稳定的通信,rmax表示智能体的最大通信半径,ca为非负常数,用于调整成功通信概率的衰减程度,将与智能体i成功通信的邻居智能体集合记为
20、建立基于单线激光雷达的障碍物探测模型,定义半径为rtr的圆形可信区域,将单线激光雷达探测得到的障碍物点位置集合记为为排除距离较远且对当前智能体影响较小的障碍物,障碍物探测模型只考虑信任区域内的障碍物数据,智能体i根据障碍物探测模型得到的障碍物点集合表示如下:
21、
22、其中,表示障碍物点云j相对智能体i的位置向量。
23、上述技术方案中,所述步骤s2包括:
24、设计状态空间:智能体在导航避障任务中需运动至各自的目标位置,智能体i在时刻t的观测应当包含目标点的相对位置以及自身速度信息:
25、
26、其中,表示智能体i的目标点位置,为智能体i与目标点γi之间的归一化相对位置;
27、为智能体i的归一化速度;上式上标t表示在第t时刻的物理量,同理,后续上标t亦具有相同含义。
28、运动过程中为避免与其它智能体、障碍物发生碰撞,智能体观测应同时包含邻居智能体以及探测到的障碍物的相对位置信息:
29、
30、
31、其中,表示邻居智能体j相对智能体i的归一化位置,表示智能体i探测到的障碍物点云j的位置,表示障碍物点云j与智能体i之间的归一化相对位置;
32、为更好的辅助智能体间的协同决策以形成提前避让的行为,在智能体观测中加入邻居智能体的速度信息:
33、
34、其中,表示智能体i与邻居智能体j之间的归一化相对速度;
35、定义智能体i在t时刻的观测为表示如下:
36、
37、其中,k表示智能体i邻居智能体的个数,满足m表示智能体i探测到的障碍物点云个数,满足
38、在所有智能体的观测基础之上构建t时刻的全局环境状态st:
39、
40、设计动作空间:根据所述步骤s1中的智能体运动模型,只需提供加速度即可实现对智能体的连续运动控制,因此将智能体i的动作定义为加速度控制量:
41、ui=ai
42、设计回报函数:回报函数应对智能体到达目标点进行奖励,在智能体到达目标点之前使用智能体与目标点之间的距离变化量作为中间回报值,设计回报函数中的目标点奖励项:
43、
44、其中,c1为正的比例常数,ε表示允许的目标距离误差,在此误差范围内认为智能体已经成功到达该目标点,rgoal表示智能体到达目标点后获得的奖励值,分别表示在前一时刻t-1与当前时刻t智能体i与目标规划点γ之间的距离,定义为
45、为使智能体策略学习到智能体与智能体、障碍物之间的自主避障行为,在回报函数中加入对碰撞的惩罚,记智能体的避障缓冲区半径为do,设计避障惩罚项如下:
46、
47、其中,c2为正的比例常数,dmin,i表示智能体i与其它智能体、障碍物间的最小距离,计算方法如下:
48、
49、其中,当集合与均为空集时,此时智能体的避障范围内没有其它智能体或障碍物,避障惩罚项直接取rβ(st)=0,,min()表示取最小值操作;
50、为使智能体尽可能快地运动至目标点,在回报函数中添加对智能体频繁改变运动方向的惩罚,即加速度变化惩罚项:其中c3为正的比例系数,该惩罚项对智能体的加速度突变进行了抑制,更符合机器人的运动学约束;
51、智能体i在时刻t获得的回报ri(st)可由目标点奖励项、避障惩罚项、加速度变化惩罚项组合构成:
52、ri(st)=rγ(st)+rβ(st)+ru(st)。
53、上述技术方案中,所述步骤s3包括:
54、设计特征提取网络模型:策略网络将所述步骤s2中的观测状态oi作为输入,并使用注意力模块自适应地提取邻居智能体和障碍物的重要特征信息,记聚合障碍物位置特征信息的注意力模块为attenβ,其包含三个参数矩阵,将提取邻居智能体运动特征信息的注意力模块记为attenα,包含三个参数矩阵,分别用于将输入信息映射为查询与键值对,如下所示:
55、
56、
57、其中,dh,dv为特征向量维度,智能体i的速度与目标点相对位置拼接向量xγ,m个障碍物相对位置拼接向量xβ,k个邻居智能体的相对位置、速度拼接向量xα,分别定义如下:
58、
59、注意力模块使用缩放点积注意力计算注意力系数,定义聚合后的障碍物位置特征为hβ,邻居智能体运动特征向量为hα,特征聚合过程如下:
60、
61、设计基于注意力机制的策略网络模型:在注意力模块之前,首先使用多层感知机(mlp)将输入的智能体观测映射至高维空间,同时选取leakyrelu作为mlp的激活函数,其次将注意力模块输出的特征向量hβ、hα与表示智能体速度和目标位置信息的特征向量进行拼接,作为特征提取网络的输出,最后进一步使用mlp得到智能体策略输出;训练过程中在注意力模块内加入dropout层,以一定概率将部分节点的权重系数设置为0;
62、设计基于距离注意力的评估网络模型:评估网络以所述步骤s2中的全局环境状态st以及由所有智能体的动作构成的联合动作at作为输入,首先利用所述特征提取网络提取环境状态特征,其次考虑到距离较远的智能体一般对当前智能体的影响较小,为减小神经网络的参数量并降低训练难度,设计距离注意力模块对环境状态特征向量进一步聚合和降维:
63、
64、其中,ho,i表示特征提取网络输出的智能体i的观测特征向量,αi,j表示智能体i对智能体j的距离注意力系数,计算方法如下:
65、
66、
67、其中,cα为非负系数,用于调整不同距离的邻居智能体对当前智能体的影响程度;
68、评估网络模型首先使用mlp将输入中的智能体动作组合向量映射至高维空间,其次将特征提取网络聚合后的特征向量与动作特征向量进行向量化拼接,最后使用mlp输出全局评估q值,选取leakyrelu作为评估网络模型中mlp的激活函数。
69、上述技术方案中,所述步骤s4包括:
70、设计避障导航控制算法以及网络参数更新方法:在多智能体协同避障导航任务中,智能体的状态空间、行为空间属性完全相同,因此在基于深度强化学习的避障导航控制算法中,所有智能体等价并共享相同的评估网络、策略网络和经验池数据,将策略网络记为πφ,将两个独立的评估网络记为qθ,1、qθ,2,将对应的目标评估网络记为
71、评估网络参数θi更新:智能体的评估网络将所有智能体的观测和动作组合作为输入,并通过最小化时序差分误差进行参数优化,定义评估网络的损失函数如下:
72、
73、其中,元组(st,at,rt,st+1,d)采样于经验回放池为n个智能体的动作组合,为回报组合,目标拟合值y定义如下:
74、
75、其中,λ为折扣因子,d为终止标志布尔值,取值为1时表示当前环境任务已完成,此时st+1为环境结束状态,取值为0时则相反,t+1时刻的动作组合由当前所有智能体的最新策略πθ根据观测st+1重新决策得到,α表示温度系数,用于调整智能体策略的探索与利用;
76、采用基于指数移动平均的软更新方法对目标评估网络参数进行更新:
77、
78、其中,τ为目标评估网络参数的软更新比例系数;
79、策略网络参数φ更新:智能体i的策略网络将观测状态oi作为输入,并以最大化期望回报与策略熵之和为优化目标,定义策略网络的损失函数为表示如下:
80、
81、其中,表示使用重参数化技巧从智能体的策略输出分布中采样得到的动作样本,采样过程如下:
82、
83、其中,分别表示随机策略πφ的输出,即正态分布的均值和标准差,ξ为服从标准正态分布的多维随机变量,tanh函数将动作限制在有限范围内,因此随机策略输出的概率分布发生了改变,策略的熵重新计算如下:
84、
85、其中,dim(a)表示动作空间a的维度;表示动作向量的第k个元素;
86、为了更好地平衡智能体的探索与利用过程,采用自适应学习方法动态地调整温度系数α,定义α的损失函数如下:
87、
88、其中,表示策略熵的期望值下限,即满足
89、上述技术方案中,所述步骤s5包括:
90、设计避障导航控制算法的训练流程,将训练总回合数记为m,回合最大步长记为tmax,参数更新间隔记为tupdate,训练过程包括以下步骤:
91、步骤7.1、初始化温度系数α,经验池策略网络参数φ、评估网络参数θ1,2、目
92、标评估网络参数评估网络、策略网络、温度系数的学习率λθ、λφ、λα,软更新比例τ等参数;
93、步骤7.2、遍历所有回合数episode=1→m,执行:
94、步骤7.2.1、初始化所有智能体及其目标点位置,获取初始状态;
95、步骤7.2.2、遍历回合步长t=1→tmax,执行:
96、步骤7.2.2.1、智能体策略根据观测选取动作
97、步骤7.2.2.2、执行at,状态转移至st+1,终止标志d,回报
98、步骤7.2.2.3、将交互数据加入经验池,
99、步骤7.2.2.4、若t为tupdate整倍数,执行:
100、步骤7.2.2.4.1、从中采样一批数据
101、步骤7.2.2.4.2、更新评估网络参数,
102、步骤7.2.2.4.3、更新策略网络参数,
103、步骤7.2.2.4.4、更新温度系数,
104、步骤7.2.2.4.5、更新目标网络参数,
105、步骤7.2.2.5、若所有智能体均已运动至目标点,则结束当前回合并执行步骤7.2.1,否则执行步骤7.2.2.1。
106、因为本发明采用上述技术方案,因此具备以下有益效果:
107、本发明利用深度强化学习技术实现未知障碍物环境中的多智能体避障导航控制,通过设计注意力机制自适应地提取邻近智能体及障碍物的重要特征信息,能够应对障碍物场景以及智能体数量的动态变化,具有分布式执行的灵活性优势。
- 还没有人留言评论。精彩留言会获得点赞!