一种基于深度强化学习的SCARA机器人近似约束鲁棒控制方法
本发明涉及scara机器人控制,特别涉及一种基于深度强化学习的scara机器人近似约束鲁棒控制方法。
背景技术:
1、scara机械人的轨迹跟踪控制主要是使各关节或末端执行器能够快速稳定地跟踪期望的轨迹。然而,scara机器人系统是具有多个输入和输出的复杂控制系统,具有时变和强耦合的动态特性。此外,内部参数偏差和未知扰动导致系统中的不确定性。传统的控制器需要人工的不断调参才能达到较好的控制效果,但是其依赖于预先的特定环境,无法根据不同的环境不同的工作任务动态调节控制参数。
技术实现思路
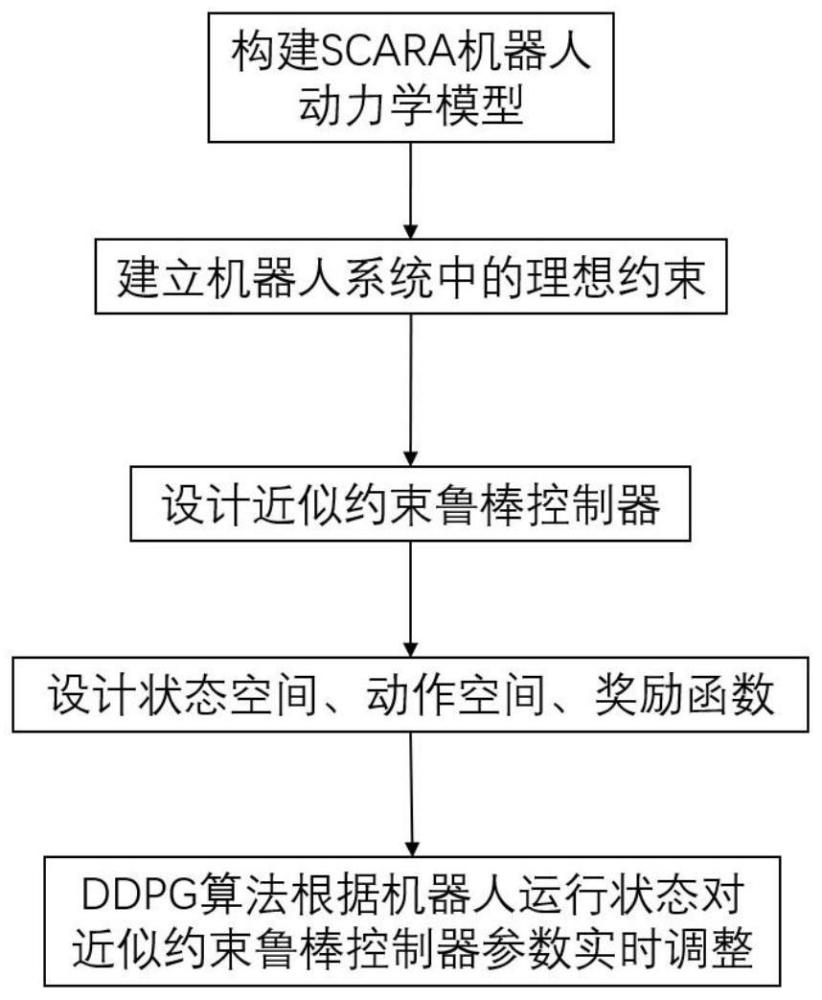
1、本发明公开了一种基于深度强化学习的scara机器人近似约束鲁棒控制方法,所述scara机器人包括四个自由度,第一自由度为整体升降,第二自由度为大臂转动,第三自由度为小臂转动,第四自由度为末端旋转;针对第二自由度和第三自由度,构建近似约束鲁棒控制方法,具体方法如下:
2、构建scara机器人动力学模型;
3、确定理想约束条件;
4、设计近似约束鲁棒控制器;
5、以ddpg算法对近似约束鲁棒控制器的控制参数进行优化;
6、以优化后的近似约束鲁棒控制器控制scara机器人。
7、进一步地,构建scara机器人动力学模型,具体如下:
8、
9、其中,q为转动角度,为转动速度,为转动加速度,σ为不确定干扰,m为惯性力矩、c为科式与离心力矩,f为摩擦力矩和外部干扰力矩。
10、进一步地,理想约束条件,具体如下:
11、将无不确定性无约束系统的运动方程改写为
12、
13、其中,jc∈σ即为约束力;
14、约束力的表达式:
15、
16、其中,表示(·)的标称部分,表示为moore-penrose广义逆。
17、进一步地,设计近似约束鲁棒控制器,具体如下:
18、
19、其中,
20、
21、
22、
23、其中,k>0,
24、
25、
26、其中,
27、进一步地,以ddpg算法对近似约束鲁棒控制器的p、k和∈参数进行优化,具体方法如下:
28、获取scara机器人的基本动力学参数、库伦摩擦系数和粘性摩擦系数;
29、初始化scara机器人初始状态、期望关节运动轨迹、主网络和目标网络权重参数,引入随机噪声;
30、获取第t时刻网络输入状态st=(qi,ei,∫qidt)
31、对动态信息st进行观察,根据策略μ来选择鲁棒控制器的参数at,at=(p,k,∈),为鲁棒控制器p,k,∈参数的动作向量,在动作选择的同时加入噪声n,可避免智能体在选择动作时陷入局部最优解,第t时刻动作表示如下:
32、
33、其中,表示主网络中策略网络权重参数,n表示为噪声;μ(·)为主网络中的策略函数,根据输入的状态输出动作,用于和环境交互,迭代更新网络权重函数;
34、将状态转换过程(st,at,rt,st+1)存储在经验池中,其中,rt为鲁棒控制器执行动作at后所获得的奖励,st+1为第t+1时刻网络输入状态;
35、从经验池中随机选取m个状态转换过程(st,at,rt,st+1)作为一个训练集,获得累计奖励qtarget
36、qtarget=rj+γq′(sj+1,μ′(si+1|θμ′)|θq′)
37、其中,θμ′和θq′分别为目标网络中的策略网络和价值网络的权重系数,γ为折扣因子。q'(·)为目标网络中的价值网络,用于基于经验池计算目标网络的评价值,提供主网络;μ'(·)为目标网络中的策略网络,用于基于经验池中的数据计算目标网络的动作;
38、当前价值网络通过最小化损失函数的方式,采用梯度下降法对价值网络中的权重参数θq进行更新,其中,l(θq)为价值网络损失函数:
39、
40、当前策略网络通过最小化损失函数的方式,采用确定性策略梯度的方法对策略网络中的权重参数θμ进行更新,其中为策略网络损失函数:
41、
42、通过最小化损失函数l(θq)、j(θμ)更新主网络中价值网络和策略网络中的权重参数θq、θμ;
43、更新价值网络和策略网络的目标网络权重参数θμ′、θq′,若sj+1为终止状态,则结束本轮次的迭代;目标价值网络和目标策略网络通过更新速率为的软更新方式进行网络更新如下:
44、θj+1q′←ρθq+(1-ρ)θjq′
45、θj+1μ′←ρθμ+(1-ρ)θjμ′。
46、进一步地,鲁棒控制器p、k和∈参数选取达到最优时,满足以下公式:
47、
48、其中,为期望的关节角度,qi为实际的关节角度,p为scara机器人物理参数。
49、进一步地,设计奖励函数r公式如下:
50、r=r1+r2
51、
52、
53、其中,ψ为设置的关节角度临界值。
54、由于采用以上技术方案,本发明具有以下有益效果:
55、1、本发明利用ddpg算法采集scara机械人的工作状态,实时调整鲁棒控制系统的参数,使系统始终保持稳定的轨迹跟踪性能。
56、2、通过基于u-k方程的鲁棒控制对scara机械人非线性动力学模型的不确定性进行补偿,在scara机械人结构参数摄动和具有时变外部干扰以及摩擦阻力等因素下,能够降低动力学模型的不确定性对控制器的影响,从而维持控制系统的稳定,进一步提高scara机械人的轨迹跟踪性能。
技术特征:
1.一种基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,所述scara机器人包括四个自由度,第一自由度为整体升降,第二自由度为大臂转动,第三自由度为小臂转动,第四自由度为末端旋转;针对第二自由度和第三自由度,构建近似约束鲁棒控制方法,具体方法如下:
2.如权利要求1所述的基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,构建scara机器人动力学模型,具体如下:
3.如权利要求2所述的基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,理想约束条件,具体如下:
4.如权利要求3所述的基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,设计近似约束鲁棒控制器,具体如下:
5.如权利要求4所述的基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,以ddpg算法对近似约束鲁棒控制器的p、k和∈参数进行优化,具体方法如下:
6.如权利要求5所述的基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,鲁棒控制器p、k和∈参数选取达到最优时,满足以下公式:
7.如权利要求5所述的基于深度强化学习的scara机器人近似约束鲁棒控制方法,其特征在于,设计奖励函数r公式如下:
技术总结
一种基于深度强化学习的SCARA机器人近似约束鲁棒控制方法,基于拉格朗日方程建立SCARA机器人动力学模型,基于U‑K方程建立机器人系统中的理想约束,根据动力学模型和理想约束,设计SCARA机器人的鲁棒近似约束跟随控制器,建立深度确定性策略梯度算法,设计状态空间、动作空间、奖励函数,根据SCARA机器人的轨迹跟踪状态,对鲁棒控制器的控制参数进行实时调整,最终学习到最优的鲁棒控制参数。本发明利用DDPG算法采集SCARA机械人的工作状态,实时调整鲁棒控制系统的参数,使系统始终保持稳定的轨迹跟踪性能。
技术研发人员:程虎,甄圣超,郑红梅
受保护的技术使用者:合肥工业大学
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!