一种搜索结果的生成方法和装置与流程
一种搜索结果的生成方法和装置【技术领域】本发明涉及互联网应用技术领域,特别涉及一种搜索结果的生成方法和装置。
背景技术:
随着信息和网络技术的不断发展,搜索引擎已经成为人们获取信息的重要途径。用户通过在搜索引擎中输入搜索词(query),获取搜索引擎针对该搜索词返回的搜索结果。搜索结果通常是根据一系列的评分策略和排序算法而得到的。其中,影响搜索结果排名除了相关性因素以外,主要还有站点(网站)的权威性因素。现有的权威性主要考虑网页的超链接关系、互联网用户的访问程度、站点本身的权威性等级等客观因素。这种采用超链接等关系来衡量网站/网址权威性的方式通常体现的是知名度,一般只能反映网页在整个互联网上的流行程度,但对于一些小型的网站来说,其自身资源有限,在权威性上落后。例如,用户的一些寻址搜索请求,目的是能够找到相应的官方网站,然而一些小型的官方网站,和具有类似内容的门户网站相比,权威性相差很多,而且在相关性上也并不占优,因此在排名上会受到挤压。使用户较难找到想要的结果,这样必然增加了用户与系统的交互次数,对服务器造成较大压力。
技术实现要素:
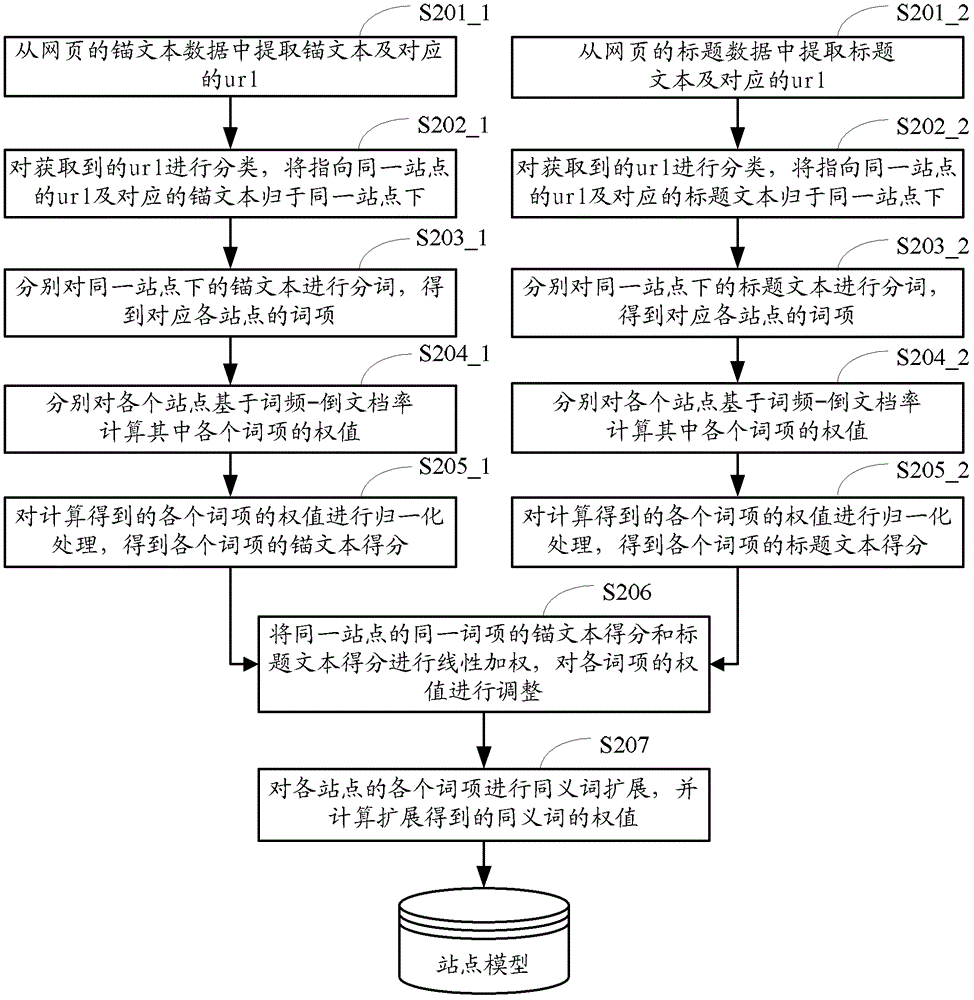
为解决上述,本发明提供了一种搜索结果的生成方法和装置,能够更好地适应用户的寻址需求,方便用户更快地找到感兴趣的网站,同时提高了用户和系统的效率,减少交互次数,减轻服务器的压力。具体技术方案如下:一种搜索结果的生成方法,该方法包括:S1、预先利用网页的锚文本或标题文本,得到各站点的词项及各词项的权值,建立各站点的站点模型;S2、获取用户的搜索词,通过检索得到与所述搜索词相匹配的各匹配网页;S3、利用所述搜索词与步骤S101建立的站点模型,通过相关性计算,得到所述搜索词与各匹配网页所对应站点模型的匹配度;S4、根据所述搜索词与各匹配网页所对应站点模型的匹配度,对所述各匹配网页进行排序,生成搜索结果。根据本发明一优选实施例,所述步骤S1具体包括以下步骤:步骤S1_1、从网页的锚文本数据中提取锚文本及对应的url,或从网页的标题文本数据中提取标题文本及对应的url;步骤S1_2、对获取到的url进行分类,将指向同一站点的url及对应的锚文本或标题文本归于同一站点下;步骤S1_3、分别对同一站点下的锚文本或标题文本进行分词,得到对应各站点的词项;步骤S1_4、分别对各个站点基于词频-倒文档率计算其中各个词项的权值,得到各站点的站点模型。根据本发明一优选实施例,还包括:对所述步骤S1_4计算得到的各个词项的权值进行归一化处理,得到各个词项的锚文本得分或标题文本得分。根据本发明一优选实施例,在进行所述归一化处理之后,还包括:将同一站点的同一词项的所述锚文本得分和所述标题文本得分进行线性加权,对各词项的权值进行调整。根据本发明一优选实施例,还包括对所述站点模型中的各个词项进行同义词扩展,并计算扩展得到的同义词的权值。根据本发明一优选实施例,所述同义词的权值Ws=W×Ratio,其中,W是站点中词项的权值,Ratio是所述同义词根据同义词级别确定的系数。根据本发明一优选实施例,所述步骤S2中在获取用户的搜索词之后,还包括:对获取的搜索词进行分词得到搜索词的词项,计算各个词项的权值,得到搜索词向量;所述步骤S3中利用所述搜索词向量与步骤S1建立的站点模型进行所述相关性计算。根据本发明一优选实施例,所述步骤S2中基于词项的倒文档率计算各个词项的权值。根据本发明一优选实施例,还包括:对所述步骤S2中,在通过检索得到与所述搜索词相匹配的各匹配网页之前,还包括:对用户的搜索词进行寻址需求识别,保留具有寻址需求的结果;在通过检索得到与所述搜索词相匹配的各匹配网页之后,还包括:对匹配网页进行主页识别,保留具有主页特征的结果。根据本发明一优选实施例,所述步骤S4具体包括:根据所述匹配度与各匹配网页对应站点的基础相关性值,计算得到各匹配网页对应站点的修正相关性值;根据各匹配网页对应的站点的修正相关性值对所述各匹配网页进行排序,将满足预设要求的匹配网页生成搜索结果显示给用户。根据本发明一优选实施例,所述满足预设要求包括:对于修正相关性值最高的网站,若该网站原排名在第N位之外,则将该网站的排名提升至第N位之内,其中N为预设正整数;一种搜索结果的生成装置,该装置包括:站点模型建立模块,用于预先利用网页的锚文本或标题文本,得到各站点的词项及各词项的权值,建立各站点的站点模型;搜索词获取模块,用于获取用户的搜索词,通过检索得到与所述搜索词相匹配的各匹配网页;匹配度计算模块,用于计算所述搜索词与所述站点模型建立模块建立的站点模型,通过相关性计算,得到所述搜索词与各匹配网页所对应站点模型的匹配度;搜索结果生成模块,用于根据所述搜索词与各匹配网页所对应站点模型的匹配度,对所述各匹配网页进行排序,生成搜索结果。根据本发明一优选实施例,所述站点模型建立模块具体包括:文本获取单元,用于从网页的锚文本数据中提取锚文本及对应的url,或从网页的标题文本数据中提取标题文本及对应的url;分类单元,用于对获取到的url进行分类,将指向同一站点的url及对应的锚文本或标题文本归于同一站点下;分词单元,用于分别对同一站点下的锚文本或标题文本进行分词,得到对应各站点的词项;赋值单元,用于分别对各个站点基于词频-倒文档率计算其中各个词项的权值,得到各站点的站点模型。根据本发明一优选实施例,所述站点模型建立模块还包括归一化单元,用于对所述赋值单元计算得到的各个词项的权值进行归一化处理,得到各个词项的锚文本得分或标题文本得分。根据本发明一优选实施例,所述站点模型建立模块还包括合并单元,用于将所述归一化单元得到的同一站点的同一词项的所述锚文本得分和所述标题文本得分进行线性加权,对各词项的权值进行调整。根据本发明一优选实施例,所述站点模型建立模块还包括同义词扩展单元,用于对所述站点模型中的各个词项进行同义词扩展,并计算扩展得到的同义词的权值。根据本发明一优选实施例,所述同义词的权值Ws=W×Ratio,其中,W是站点中词项的权值,Ratio是所述同义词根据同义词级别确定的系数。根据本发明一优选实施例,所述搜索词获取模块包括搜索词分词单元和搜索词赋值单元,所述搜索词分词单元,用于对获取的搜索词进行分词得到搜索词的词项;所述搜索词赋值单元,用于计算所述搜索词分词单元得到的各个词项的权值,得到搜索词向量,供给所述匹配度计算模块进行所述相关性计算。根据本发明一优选实施例,所述搜索词获取模块基于词项的倒文档率计算各个词项的权值。根据本发明一优选实施例,所述搜索词获取模块还包括:寻址需求识别单元,用于在通过检索得到与所述搜索词相匹配的各匹配网页之前,对用户的搜索词进行寻址需求识别,保留具有寻址需求的结果;主页识别单元,用于在通过检索得到与所述搜索词相匹配的各匹配网页之后,对匹配网页进行主页识别,保留具有主页特征的结果。根据本发明一优选实施例,所述搜索结果生成模块包括相关性值确定单元和搜索结果排序单元,所述相关性值确定单元,用于根据所述匹配度与各匹配网页对应站点的基础相关性值,计算得到各匹配网页对应站点的修正相关性值;所述搜索结果排序单元,用于根据各匹配网页对应的站点的修正相关性值对所述各匹配网页进行排序,将满足预设要求的匹配网页生成搜索结果显示给用户。根据本发明一优选实施例,所述满足预设要求包括:对于修正相关性值最高的网站,若该网站原排名在第N位之外,则将该网站的排名提升至第N位之内,其中N为预设正整数。由以上技术方案可以看出,本发明提供的搜索结果的生成方法和装置,利用锚文本和用户标题文本建立站点模型,由于站点模型同时考虑到了站点内所包含的所有网页的内容,从而能够使得官网、个人首页等网站的相关性值能够得到提升,提升这些网站的排名,方便搜索用户迅速找到感兴趣的搜索结果,更适应用户的寻址搜索需求,同时提高了用户和系统的效率,减少交互次数,减轻服务器的压力。【附图说明】图1为本发明实施例一提供的搜索结果的生成方法流程图;图2为本发明实施例一提供的建立站点模型的方法流程图;图3为本发明实施例二提供的搜索结果的生成装置结构图;图4为本发明实施例二提供的站点模型建立模块的结构图。【具体实施方式】为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。实施例一、图1是本实施例提供的搜索结果的生成方法流程图,如图1所示,该方法包括:步骤S101、预先利用网页的锚文本或标题文本,得到各站点的词项及各词项的权值,建立各站点的站点模型。一个站点通常包括多个网页,一个网页内包括多个锚文本。所述锚文本(超链接文本,anchortext),用以指引注释其对应的超链接(url,统一资源定位符)。从抓取到的网络资源中,获取各网页内的锚文本及其对应的url,作为锚文本数据。另一方面,一个站点通常包括首页和内页,都会有标题文本(titletext)来描述,用以概括页面的主页内容和出处等。从抓取到的网络资源中,获取各网页的标题文本及其对应的url,作为标题文本数据。利用这些锚文本数据或标题文本数据建立各站点模型。下面结合图2对站点模型的建立做进一步详细说明。图2是本实施例提供的建立站点模型的方法流程图,如图2所示,其中,分支S201_1至S205_1为利用锚文本建立站点模型的方法,可以包括以下步骤:步骤S201_1、从网页的锚文本数据中提取锚文本及对应的url。利用搜索引擎抓取整个网络资源上的锚文本数据,包括各个站点内的锚文本及其对应的url。从这些锚文本数据中提取锚文本及对应的url。例如,以获取网页“www.sunanchn.cn”站点首页为例,得到的锚文本如表1所示(未全部列出):表1锚文本锚文本对应的url南京尚安数码科技有限公司http://www.sunanchn.cn/尚安科技http://www.sunanchn.cn/南京尚安数码http://www.sunanchn.cn/南京尚安数码科技有限公司http://www.sunanchn.cn/Main南京尚安数码科技有限公司http://www.sunanchn.cn/Main/index.aspx南京尚安数码http://www.sunanchn.cn/Main/index.aspx............步骤S202_1、对获取到的url进行分类,将指向同一站点的url及对应的锚文本归于同一站点下。在判断url是否指向同一个站点时,可以但不限于以“/”作为分隔符,以模板“http://……/”进行判断,即将网络协议“http://”后至第一个“/”之前内容一样的url作为同一个站点的url。例如,url1为“http://www.xxx.com”,其对应锚文本1。url2为“http://www.xxx.com/1.htm”,其对应锚文本2。由于url1和url2中“http://……/”之间的内容相同,因而,url1和url2都是属于“www.xxx.com”这个站点下面的url,其对应的锚文本1和锚文本2都是“www.xxx.com”这个站点的锚文本。同理,对“www.sunanchn.cn”站点的锚文本和url进行归类,得到的结果如表2所示:表2步骤S203_1、分别对同一站点下的锚文本进行分词,得到对应各站点的词项。采用现有的分词方法,例如可以采用正向最大匹配法进行大粒度分词,同时采用正向最小匹配法进行小粒度分词,得到词项。以“南京尚安数码”为例,分词结果得到词项,包括:“南京”、“尚”、“安”、“尚安”、“数码”。采用现有过滤方法,过滤掉标点符号及停用词,得到词项“南京”、“尚”、“安”、“尚安”和“数码”。对属于站点“www.sunanchn.cn”下的各个锚文本进行分词,得到该站点“www.sunanchn.cn”的词项。步骤S204_1、分别对各个站点基于词频-倒文档率计算其中各个词项的权值。统计各个词项在同一站点的锚文本中的出现次数(TF),并与各个词项的倒文档率(IDF)计算各个词项的权值Wt,即Wt=TF*IDF。其中,词项的倒文档率为固定的值,可以通过现有的词典获得,表示词项的表意能力,IDF值越大,表意能力越强。例如,统计词项“尚安”在站点“www.sunanchn.cn”的锚文本中出现次数为1000,“尚安”的IDF值假设为0.02,则词项“尚安”的权值是20。步骤S205_1、对步骤S204_1计算得到的各个词项的权值进行归一化处理,得到各个词项的锚文本得分。各个站点所获得的锚文本数量各异,经过分词得到的词项数量或多或少。如果一个词项在两个不同站点的锚文本中出现次数相同,那么根据步骤S204_1计算得到的该词项的权值也就相同,然而该词项对于两个不同站点而言,其重要程度可能是不相同的。为了使各个站点中词项的权值可以体现词项对于站点的重要程度,有必要对词项的权值进行归一化至[0,1],采用统一的形式表示。在本步骤中,采用归一化公式:Score_Anchor=Wt/Wt_max(1)其中,Wt是计算得到的词项的权值,Wt_max是针对同一站点中的各词项计算出的Wt的最大值。值得一提的是,Wt_max也可以是一个固定的预估值,根据经验能够预估到各词项的权值不会超过某个数值,可以将该数值作为Wt_max。经过归一化处理,得到各个词项在[0,1]内的锚文本得分Score_Anchor。分支S201_1至S205_1为利用标题文本建立站点模型的方法,可以包括以下步骤:步骤S201_2、从标题数据中提取标题文本及对应的url。例如,利用网络爬虫下载网页内容后,提取的网页标题文本及其对应的url如表3所示:表3步骤S202_2、对获取到的url进行分类,将指向同一站点的url及对应的标题文本归于同一站点下。本步骤与步骤S202_1相类似,在判断url是否指向同一个站点时,可以但不限于以“/”作为分隔符,以模板“http://……/”进行判断,即将网络协议“http://”后至第一个“/”之前内容一样的url作为同一个站点的url。对表3的内容进行分类,得到结果如表4:表4步骤S203_2、分别对同一站点下的标题文本进行分词,得到对应各站点的词项。与步骤S203_1类似,采用现有的分词方法,例如可以采用正向最大匹配法进行大粒度分词,同时采用正向最小匹配法进行小粒度分词,得到词项。以“尚安安防系统超市”为例,分词结果得到词项,包括:“尚安”、“尚”、“安”、“安防”、“系统”和“超市”。采用现有过滤方法,过滤掉标点符号及停用词,得到词项“尚安”、“尚”、“安”、“安防”、“系统”和“超市”。步骤S204_2、分别对各个站点基于词频-倒文档率(TF-IDF)计算其中各个词项的权值。与步骤S204_1相类似,统计各个词项在指向同一站点的标题文本中的出现次数(TF),并与各个词项的倒文档率(IDF)计算各个词项的权值Wt,即Wt=TF*IDF。步骤S205_2、对步骤S204_2计算得到的各个词项的权值进行归一化处理,得到各个词项的标题文本得分。与步骤S205_1相类似,采用归一化公式:Score_Title=Wt/Wt_max(2)其中,Wt是计算得到的词项的权值,Wt_max是针对同一站点中的各词项计算出的Wt的最大值。同样地,Wt_max也可以是一个固定的预估值,根据经验能够预估到各词项的权值不会超过某个数值,可以将该数值作为Wt_max。经过归一化处理,得到各个词项在[0,1]内的标题文本得分Score_Title。步骤S206-S207是利用锚文本得分和标题文本得分建立站点模型的方法,具体如下步骤S206、将同一站点的同一词项的锚文本得分和标题文本得分进行线性加权,对各词项的权值进行调整。采用的线性加权公式为:W=Score_Anchor×a+Score_Title×(1-a)(3)其中,W是站点中词项的权值,a是预设的加权因子,0<a<1。根据实际应用场景的不同,可设置不同的a,分配词项的锚文本得分Score_Anchor和标题文本得分Score_Title的比例,对词项的权值进行调整。可以理解的是,根据本发明方案,可以使用锚文本或标题文本的其中一种数据来建立站点模型,因而,当仅使用一种数据建立站点模型时,可以不必进行本步骤的线性加权操作。步骤S207、对各站点的各个词项进行同义词扩展,并计算扩展得到的同义词的权值。在本发明的一种优选实施方式中,还可以进一步利用同义词词表,对各个词项进行同义词扩展。例如,针对“尚安”可以通过同义词词表扩展得到“sunanchn”,“科技”可以扩展得到“科学技术”、“科学和技术”、“科学与技术”等等。利用站点中各个词项的权值以及通过该些词项扩展得到的同义词所在的同义词级别,来计算同义词的权值Ws,其计算公式为:Ws=W×Ratio(4)其中,W是站点中词项的权值,Ratio是所述同义词根据同义词级别确定的系数,其值大小处于[0,1]之间。根据同义词级别确定的系数Ratio可以采用词项与扩展的同义词之间的相关性来确定,从而计算得到同义词的权值。例如,某站点的词项包括词A,扩展的同义词包括词B,则计算词B的权值可以但不限于采用以下计算公式:WB=WA×RAB(5)其中,WB为词B的权值,WA为词A的权值,RAB为词A和词B的相关性。例如,针对站点“www.sunanchn.cn”,经过步骤S206计算得到“科技”的权值为0.1531,“科技”和“科学技术”之间的相关性为0.8,则可以得到“科学技术”的权值为0.12248。计算词A与词B之间的相关性RAB的具体过程包括如下:分别针对词A和词B确定特征向量,该特征向量的确定过程为:先将单个词(如,词A)作为搜索词到搜索引擎中进行搜索,得到搜索结果,选取前X个页面的搜索结果,并对每个页面的内容进行分词并计算分词的TF-IDF作为各个分词的权值,再选取权重值排在前Y个的分词作为词A的特征向量。然后,计算词A的特征向量和词B的特征向量之间的相似度作为词A和词B的相关性,两个特征向量之间的相似度可以采用余弦相似度或者内积而得到。经过本步骤对各站点的词项进行扩展后,将扩展得到的同义词也作为各个站点的词项,使得站点模型中的词项更加全面、准确。当然,本步骤并不是必须的操作。针对站点“www.sunanchn.com”经过上述步骤S201_1/S201_2至步骤S207处理后,建立的站点模型如表5所示(未全部示出)。表5词项权值尚安0.1735sunanchn0.1588www.sunanchn.cn0.1588尚0.1533科技0.1531安0.1508数码0.1432南京0.1372公司0.1315科学与技术0.1225科学技术0.1225科学和技术0.1225尚安科技0.0999科技处0.0721............在站点模型中除了站点中的词项及其权值、扩展得到的同义词及其权值外,还可以包括站点名称以及词项总数量等信息。例如,站点“www.sunanchn.com”包括50个词项等等信息。值得一提的是,经过步骤S204_1或步骤S204_2计算得到各词项的权值后即可得到站点模型,站点模型包括站点的词项以及各词项的权值。后续的步骤S205_1、步骤S205_2、步骤S206以及步骤S207是对各词项的权值进行调整及优化处理,使得建立的站点模型更加准确。继续参见图1,步骤S102、获取用户的搜索词,通过检索得到与所述搜索词相匹配的各匹配网页。其中,所述获取用户的搜索词具体包括以下步骤:步骤S102a、对搜索词进行分词得到搜索词的词项。采用现有的分词方法,对扩展后的搜索词进行大粒度和小粒度分词。例如,采用正向最大匹配法进行大粒度分词,将搜索词“南京尚安数码”分词为“南京尚安”和“数码”。采用正向最小匹配法进行小粒度分词,将搜索词““南京尚安数码””分词为“南京”、“尚安”和“数码”。步骤S102b、计算步骤S102a得到的各词项的权值,构成搜索词向量。词项的权值计算方法可以但不限于采用基于词项的倒文档率(IDF)来计算搜索词各个词项的权值。IDF值是词项的表意能力,用以体现词项的重要性,IDF值越大,词项的权值越大。对于扩展的词项的权值可以利用扩展前的原有搜索词的词项的权值乘以扩展得到的搜索词与原有搜索词的相关度来计算,与上述计算公式(5)类似。在计算出各词项的权值后,利用搜索词的词项及各词项的权值构成搜索词向量。举个例子,对于搜索词“南京尚安”,经过分词等处理后,可以得到搜索词向量[南京,0.5尚安,0.9]。在本发明的一种优选实施方式中,在S102a之前,还可以用户的搜索词首先进行寻址需求识别。寻址query,主要指有搜索特定官网需求的,包括官网首页、官网频道、官网专题页、官网登陆页、web2.0个人首页等。query寻址需求识别,目的就是能识别这类query。在本发明中,对于用户的搜索可以首先进行寻址需求识别,然后针对具有寻址需求的搜索进一步执行后续步骤。其中,寻址需求识别可以采用现有技术,主要是结合用户点击行为和query文本的自然语言处理方法。当然,本发明对于寻址需求识别的具体实现方式并不需要进行限定。另外,在通过检索得到与所述搜索词相匹配的各匹配网页之后,还可以进一步利用主页识别技术对网页匹配结果进行过滤,保留具有主页特征的结果。主页,就是指官网首页、官网频道、官网专题页、官网登陆页、web2.0个人首页等,而这些页面具有唯一性和稳定性。在本发明中,通过主页识别技术对搜索结果进行过滤,可以更好地适应用户的寻址需求。其中,主页识别可以采用现有技术,例如是url形式识别、anchor文本分析识别等等。当然,本发明对于主页识别的具体实现方式并不需要进行限定。步骤S103、利用所述搜索词与步骤S101建立的站点模型,通过相关性计算,得到所述搜索词与各匹配网页所对应站点模型的匹配度。通过将搜索词向量和各站点模型做相似度计算,可以但不限于采用内积或余弦定理来计算相似度,得到搜索词与各站点的匹配度,该匹配度取值范围是[0,1]。例如,计算搜索词“南京尚安”与站点“www.sunanchn.com”的相关性,则将搜索词向量[南京,0.5尚安,0.9]与“www.sunanchn.com”的站点模型(如表5所示)进行内积计算,得到该搜索词“南京尚安”与站点“www.sunanchn.com”的匹配度=0.5×0.1372+0.9×0.1735=0.22475。步骤S104、根据所述搜索词与各匹配网页所对应站点模型的匹配度,对所述各匹配网页进行排序,生成搜索结果。优选地,可以将步骤S103计算得到的搜索词与各匹配网页对应的站点的匹配度加权到各站点基础相关性值上,得到各站点的修正相关性值。其中,加权公式可以采用:V=basic×e(6)其中,V是站点的修正相关性值,basic是站点基础相关性值,e是经过步骤S103计算得到的搜索词与站点的匹配度。例如,假设站点“www.sunanchn.com”基础相关性值=840,则经过加权后,得到的修正相关性值=840×(0.22475)=188.79。根据各匹配网页对应的站点的修正相关性值对所述各匹配网页进行排序,将满足预设要求的匹配网页生成搜索结果显示给用户。所述满足预设要求可以包括:选取与搜索词的修正相关性值最高的结果,按照一定的策略排到前N位,例如,将原先排名前10位之外的,提高到前10;将原先排名前3至10的,提高到前3;将原先排名前3的,提高至第1位。一般而言,官方网站会得到较高的修正相关性值,因此根据本发明的方案,可以让官方网站的排名得到有效提高。此外,也可以将基础相关性值与修正相关性值相加,根据相加的结果进行排序,这样同样能令修正相关性较高的网页获得比较大的排序提升。本发明提供的搜索结果的生成方法,从识别的网页集合中,将站点模型与搜索词匹配度较高的网页排序结果进行提升,由于站点模型同时考虑到了站点内所包含的所有网页的内容,使得官网、个人首页等网站的相关性值能够得到提升,从而可以让官网、个人首页等网站的排序提前,更好地满足用户的寻址需求。例如用户在搜索引擎中输入“北京青年假日酒店”,在原先的搜索结果排序中,官网的排名很靠后,首页的首页锚文本中很少命中“北京青年假日酒店”。而根据本发明方案建立站点模型后,能够从官方站点的内页锚文本数据和和标题文本数据中挖掘文本信息,将“假日”、“青年”、“酒店”等词条的匹配情况也得到加权,从而改善该官方站点的搜索结果排名。以上是对本发明所提供的方法进行的详细描述,下面对本发明提供的搜索结果的生成装置进行详细描述。实施例二、图3是本实施例提供的搜索结果的生成装置结构图,如图3所示,该装置包括:站点模型建立模块10,用于预先利用网页的锚文本或标题文本,得到各站点的词项及各词项的权值,建立各站点的站点模型。所述站点模型至少包括站点的词项以及各词项的权值。一个站点通常包括多个网页,一个网页内包括多个锚文本。所述锚文本用以指引注释其对应的url。从抓取到的网络资源中,获取各网页内的锚文本及其对应的url,作为锚文本数据。利用网络爬虫下载网页内容后,可以从中提取网页标题文本及其对应的标题文本作为网页的标题文本数据。站点模型建立模块10利用这些锚文本数据或网页的标题文本数据建立各站点模型,具体包括:文本获取单元101,用于从网页的锚文本数据中提取锚文本及对应的url,或从网页的标题文本数据中提取标题文本及对应的url。文本获取单元101利用搜索引擎抓取整个网络资源上的锚文本数据,包括各个站点内的锚文本及其对应的url。或者,从网络爬虫下载的网页内容中,提取的网页标题文本及其对应的url。分类单元102,用于对获取到的url进行分类,将指向同一站点的url及对应的锚文本或标题文本归于同一站点下。分类单元102在判断url是否指向同一个站点时,可以但不限于以“/”作为分隔符,以模板“http://……/”进行判断,即将网络协议“http://”后至第一个“/”之前内容一样的url作为同一个站点的url。分词单元103,用于分别对同一站点下的锚文本或标题文本进行分词,得到对应各站点的词项。采用现有的分词方法,例如可以采用正向最大匹配法进行大粒度分词,同时采用正向最小匹配法进行小粒度分词,得到词项。赋值单元104,用于分别对各个站点基于词频-倒文档率计算其中各个词项的权值,得到各站点的站点模型。统计各个词项在同一站点的锚文本或标题文本中的出现次数(TF),并与各个词项的倒文档率(IDF)计算各个词项的权值Wt,即Wt=TF*IDF。其中,词项的倒文档率为固定的值,可以通过现有的词典获得,表示词项的表意能力,IDF值越大,表意能力越强。归一化单元105,用于对赋值单元104计算得到的各个词项的权值进行归一化处理,得到各个词项的锚文本得分或标题文本得分。各个站点所获得的锚文本或标题文本数量各异,经过分词得到的词项数量或多或少。如果一个词项在两个不同站点的锚文本或标题文本中出现次数相同,那么利用赋值单元104计算得到的该词项的权值也就相同,然而该词项对于两个不同站点而言,其重要程度可能是不相同的。为了使各个站点中词项的权值可以体现词项对于站点的重要程度,有必要对词项的权值进行归一化至[0,1],采用统一的形式表示。归一化单元105采用公式(1)得到各个词项的锚文本得分Score_Anchor和标题文本得分Score_Title。为了更清楚阐述站点模型建立模块10,下面结合图4作进一步详细说明。图4为本实施例提供的站点模型建立模块10的结构图,如图4所示,站点模型建立模块10包括:锚文本获取单元1011,用于从网页的锚文本数据中提取网页内的锚文本及对应的url。锚文本获取单元1011利用搜索引擎抓取整个网络资源上的锚文本数据,包括各个站点内的锚文本及其对应的url。从该些锚文本数据中提取锚文本及对应的url。例如,以获取网页“www.sunanchn.com”站点首页为例,得到的锚文本如表1所示。第一分类单元1021,用于对锚文本获取单元1011获取到的url进行分类,将指向同一站点的url及对应的锚文本归于同一站点下。第一分类单元1021在判断url是否指向同一个站点时,可以但不限于以“/”作为分隔符,以模板“http://……/”进行判断,即将网络协议“http://”后至第一个“/”之前内容一样的url作为同一个站点的url。例如,对表1中“www.sunanchn.com”站点的锚文本和url进行归类,得到的结果如表2所示。第一分词单元1031,用于分别对同一站点下的锚文本进行分词,得到对应各站点的词项。例如,对属于站点“www.sunanchn.com”下的各个锚文本进行分词,得到该站点“www.sunanchn.com”的词项。第一赋值单元1041,用于分别对各个站点基于词频-倒文档率计算其中各个词项的权值。统计各个词项在同一站点的锚文本中的出现次数(TF),并与各个词项的倒文档率(IDF)计算各个词项的权值Wt,即Wt=TF*IDF。第一归一化单元1051,用于对第一赋值单元1041计算得到的各个词项的权值进行归一化处理,得到各个词项的锚文本得分Score_Anchor。采用归一化公式:Score_Anchor=Wt/Wt_max其中,Wt是计算得到的词项的权值,Wt_max是针对同一站点中的各词项计算出的Wt的最大值。值得一提的是,Wt_max也可以是一个固定的预估值,根据经验能够预估到各词项的权值不会超过某个数值,可以将该数值作为Wt_max。经过归一化处理,得到各个词项在[0,1]内的锚文本得分Score_Anchor。标题文本获取单元1012,用于从网页的标题文本数据中提取标题文本及对应的url。标题文本获取单元1012从网络爬虫下载的网页内容中,提取的网页标题文本及其对应的url。所提取的网页标题文本及其对应的url如表3所示。第二分类单元1022,用于对标题文本获取单元1012获取到的url进行分类,将指向同一站点的url及对应的标题文本归于同一站点下。第二分类单元1022在判断url是否指向同一个站点时,可以但不限于以“/”作为分隔符,以模板“http://……/”进行判断,即将网络协议“http://”后至第一个“/”之前内容一样的url作为同一个站点的url。例如,对表3的内容进行分类,得到结果如表4。第二分词单元1032,用于分别对同一站点下的标题文本进行分词,得到对应各站点的词项。第二赋值单元1042,用于分别对各个站点基于词频-倒文档率(TF-IDF)计算其中各个词项的权值。第二归一化单元1052,用于对第二赋值单元1042计算得到的各个词项的权值进行归一化处理,得到各个词项的标题文本得分Score_Title。采用归一化公式:Score_Title=Wt/Wt_max其中,Wt是计算得到的词项的权值,Wt_max是针对同一站点中的各词项计算出的Wt的最大值。同样地,Wt_max也可以是一个固定的预估值,根据经验能够预估到各词项的权值不会超过某个数值,可以将该数值作为Wt_max。经过归一化处理,得到各个词项在[0,1]内的标题文本得分Score_Title。合并单元106,用于将第一归一化单元1051和第二归一化单元1052得到的同一站点的同一词项的所述锚文本得分和所述标题文本得分进行线性加权,对各词项的权值进行调整。采用的线性加权公式为公式(3),根据实际应用场景的不同,可设置不同的a,分配词项的锚文本得分Score_Anchor和标题文本得分Score_Title的比例,加权得到词项的权值W。同义词扩展单元107,用于对所述站点模型中的各个词项进行同义词扩展,并计算扩展得到的同义词的权值。同义词扩展单元107利用同义词词表,对各个词项进行同义词扩展。利用站点中各个词项的权值以及通过该些词项扩展得到的同义词所在的同义词级别,来计算同义词的权值Ws,其计算公式为:Ws=W×Ratio其中,W是站点中词项的权值,Ratio是所述同义词根据同义词级别确定的系数,其值大小处于[0,1]之间。根据同义词级别确定的系数Ratio可以采用词项与扩展的同义词之间的相关性来确定,从而计算得到同义词的权值。例如,某站点的词项包括词A,扩展的同义词包括词B,则计算词B的权值可以但不限于采用以下计算公式:WB=WA×RAB其中,WB为词B的权值,WA为词A的权值,RAB为词A和词B的相关性。计算词A与词B之间的相关性RAB的具体过程包括如下:分别针对词A和词B确定特征向量,该特征向量的确定过程为:先将单个词(如,词A)作为搜索词到搜索引擎中进行搜索,得到搜索结果,选取前X个页面的搜索结果,并对每个页面的内容进行分词并计算分词的TF-IDF作为各个分词的权值,再选取权重值排在前Y个的分词作为词A的特征向量。然后,计算词A的特征向量和词B的特征向量之间的相似度作为词A和词B的相关性,两个特征向量之间的相似度可以采用余弦相似度或者内积而得到。利用站点模型建立模块20建立站点“www.sunanchn.com”的站点模型如表5所示。继续参见图3,搜索词获取模块20,用于获取用户的搜索词,通过检索得到与所述搜索词相匹配的各匹配网页。搜索词获取模块20具体包括:搜索分词单元201,用于对搜索词进行分词得到搜索词的词项。采用现有的分词方法,对扩展后的搜索词进行大粒度和小粒度分词。搜索词赋值单元202,用于计算搜索词分词单元201得到的各词项的权值,构成搜索词向量,供给所述匹配度计算模块进行所述相关性计算。词项的权值计算方法可以但不限于采用基于词项的倒文档率(IDF)来计算搜索词各个词项的权值。IDF值是词项的表意能力,用以体现词项的重要性,IDF值越大,词项的权值越大。对于扩展的词项的权值,利用扩展前的原有搜索词的词项的权值乘以扩展得到的搜索词与原有搜索词的相关度来计算,与上述计算公式(5)类似。搜索词赋值单元202在计算出各词项的权值后,利用搜索词的词项及各词项的权值构成搜索词向量。进一步地,所述搜索词获取模块还可以包括:寻址需求识别单元200,用于在通过检索得到与所述搜索词相匹配的各匹配网页之前,对用户的搜索词进行寻址需求识别,保留具有寻址需求的结果;主页识别单元203,用于在通过检索得到与所述搜索词相匹配的各匹配网页之后,对匹配网页进行主页识别,保留具有主页特征的结果。匹配度计算模块30,用于计算所述搜索词与站点模型建立模块10建立的站点模型,通过相关性计算,得到所述搜索词与各匹配网页所对应站点模型的匹配度。通过将搜索词向量和各站点模型做相似度计算,可以但不限于采用内积或余弦定理来计算相似度,得到搜索词与各站点的匹配度,该匹配度取值范围是[0,1]。搜索结果生成模块40,用于根据所述搜索词与各匹配网页所对应站点模型的匹配度,对所述各匹配网页进行排序,生成搜索结果。搜索结果生成模块40包括相关性值确定单元401和搜索结果排序单元402。所述相关性值确定单元401,用于根据所述匹配度与各匹配网页对应站点的基础相关性值,计算得到各匹配网页对应站点的修正相关性值;所述搜索结果排序单元402,用于根据各匹配网页对应的站点的修正相关性值对所述各匹配网页进行排序,将满足预设要求的匹配网页生成搜索结果显示给用户。所述满足预设要求可以包括:对于修正相关性值最高的网站,若该网站原排名在第N位之外,则将该网站的排名提升至第N位之内,其中N为预设正整数。本发明提供的搜索结果的生成方法和装置,利用锚文本和用户标题文本建立站点模型,由于站点模型同时考虑到了站点内所包含的所有网页的内容,从而能够使得官网、个人首页等网站的相关性值能够得到提升,提升这些网站的排名,方便搜索用户迅速找到感兴趣的搜索结果,更符合用户需求,同时提高了用户和系统的效率,减少交互次数,减轻服务器的压力。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1