一种基于局部约束稀疏表征的花卉类别辨识方法与流程
本发明涉及模式识别与人工智能技术领域,特别涉及一种基于局部约束稀疏表征的花卉类别辨识方法。
背景技术:
花卉类别辨识即指利用计算机对花卉的图像信息进行特征提取,计算机按照人的认识和思维方式加以种类归类和理解,进而可为用户提供一些科普性的花卉知识,其属于计算机自动对象识别的范畴,目前在花卉类别辨识方面专利比较少,在学术界有少量论文发表,如论文(YuningCHAI,VictorLEMPITSKY,AndrewZISSERMAN.BiCoS:ABi-levelCo-SegmentationMethodforImageClassification.ICCV,2011),其利用图像分割方法将图像分割成前景和背景,然后提取图像的颜色分布和超像素信息,并利用有效的推演算法来进行识别。论文(Nilsback,M-E.andZisserman,A.Automatedflowerclassificationoveralargenumberofclasses,ProceedingsoftheIndianConferenceonComputerVision,GraphicsandImageProcessing2008),其提取图像的颜色直方图,SIFT特征,HOG特征三种特征后,用SVM分类进行花卉类别的分类。论文(Nilsback,M-E.andZisserman,A,AVisualVocabularyforFlowerClassification,ProceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition2006),其利用BOW特征进行花卉图像的分类。
技术实现要素:
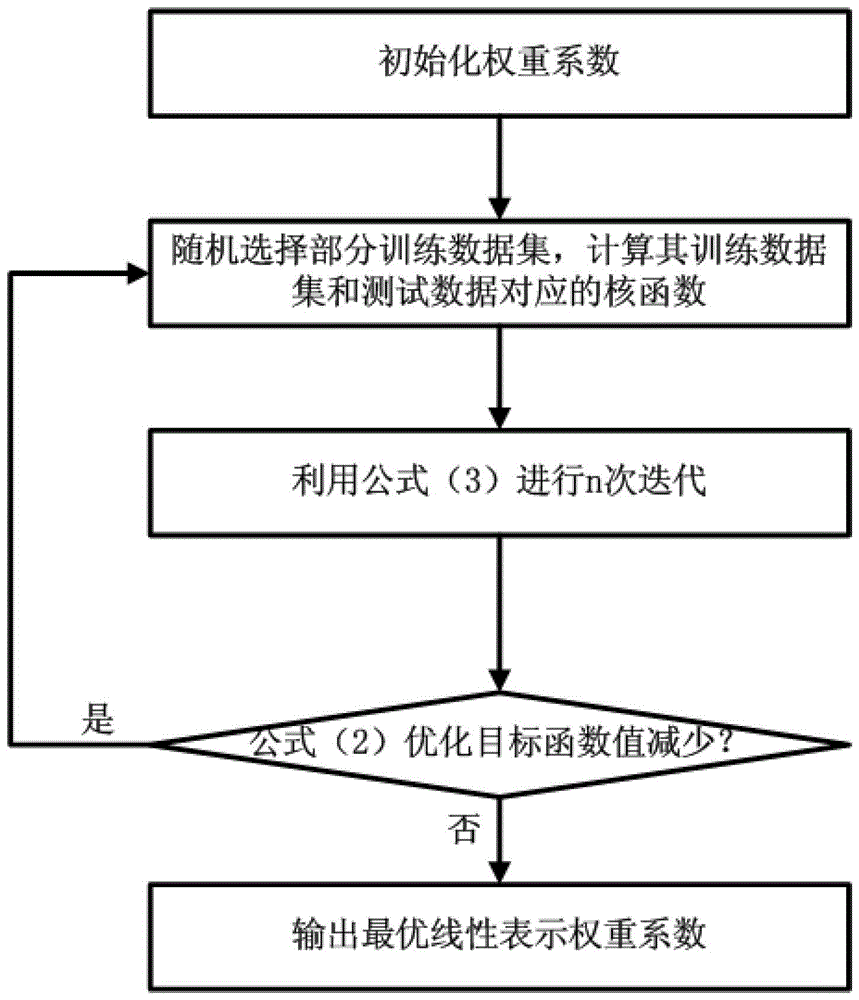
为了克服现有技术的上述缺点与不足,本发明的目的在于提供一种基于局部约束稀疏表征的花卉类别辨识方法,识别性能高。本发明的目的通过以下技术方案实现:一种基于局部约束稀疏表征的花卉类别辨识方法,包括以下步骤:(1)收集花卉图像数据库和建立花卉科普知识库:利用现有的植物花卉维基百科定义S个常用的花卉类别的名称,利用网络搜索引擎搜索各个花卉类别对应的花卉文字介绍和图片,将图片组成花卉图像数据库;将文字说明归入花卉科普知识库;(2)对步骤(1)得到的花卉图像数据库中的所有图片进行特征提取,每张图片提取的特征为m个;(3)花卉类别辨识学习过程:(3-1)从花卉图像数据库中挑选p张图片,将其特征作为测试数据集Y={yk},其中k=1...m分别代表每张图片提取的m个特征,p<N,N为花卉图像数据库中的图片数;花卉图像数据库中其余的N-p张图片的特征作为训练数据集其中j=1,2…S,表示花卉的类别;(3-2)将测试数据特征yk用训练数据特征线性表示为:其中是训练数据集表征测试数据集的权重系数,其值大于0;(3-3)为了训练数据集和测试数据集线性表示误差最小,同时增加测试数据特征和训练数据特征的局部性特征相似性结构的权重约束,建立下面的最优化学习准则:minWjk12Σk=1m||yk-Σj=1SXjkwjk||22+λΣj=1S||DjkΘwjk||2---(1)]]>其中Θ表示向量点乘;λ是约束项权重,是用来平衡线性表示误差与权重系数之间的常数变量;为测试数据特征yk与训练数据特征的欧式距离;(3-4)采用统计梯度下降法对进行迭代更新,更新方程为:wjk,t+1=wjk,t-η▿w▿w=-Xjkyk+XjkXjkwjt+λ||yk-Xjk||22·wjk,t---(2)]]>其中,t是SGD迭代过程的迭代次数,η是统计梯度下降迭代过程的学习率;(3-5)利用非线性函数φ将训练和测试数据的特征进行非线性映射到高维的再生核希尔伯特空间(reproducingkernelhilbertspace,简称RKHS),即φ(xi)Tφ(xj)=g(xi,xj),其中g(xixj)为χ2核函数,xi和xj是数据特征;公式(2)变换成:wjk,t+1=wjk,t-η▿w▿w=-hk+Gkwjk,t+λ(Pk-2hh+Gk)·wjk,t---(3)]]>其中是训练数据特征与测试数据特征yk的点乘核函数,是训练数据特征与自身的点乘核函数,Pk=φ(yk)φ(yk)是测试数据特征yk与自身的点乘核函数;经过公式(3)的多次迭代,得到最优的表征权重系数(4)辨识花卉:用户拍摄待辨识花卉的图像,对待识别的花卉图像提取特征Zk,其中k=1...m分别代表每张图片提取的m个特征;根据Zk,由花卉类别判决公式辨识花卉类别,并从花卉科普知识库中调出该花卉类别对应的文字说明;其中花卉类别判决公式为:其中j*表示利用某个j类别的训练数据的线性表示与测试数据的最小误差值,通过最小选择,j即为识别得到的花卉类别。步骤(3-4)中,η随着迭代次数t的增加而减小,步骤(3-5)所述χ2核函数的表达式为exp(-χ2(x,x)/μ),其中χ2为对称式的卡方(Chi-squared)距离,μ是当前训练数据集的χ2距离的均值。步骤(1)所述利用现有的植物花卉维基百科定义S个常用的花卉类别的名称,利用网络搜索引擎搜索各个花卉类别对应的花卉文字介绍和图片,具体为:利用现有的植物花卉维基百科定义313个常用的草本花卉类别的名称,利用网络搜索引擎搜索各个花卉类别对应的花卉文字介绍和图片,每个花卉类别下载100张图片。每张图片提取的特征包括颜色直方图、SIFT特征(Scale-invariantfeaturetransform,尺度不变特征转换特征)、HOG特征(Histogramoforientedgradients,方向梯度直方图特征)、BOW特征(Bagofword,字典包特征)、SSIM特征(StructuralSimilarity,结构相似性特征)、GB特征(StructuralSimilarity,结构相似性特征)。与现有技术相比,本发明具有以下优点和有益效果:(1)花卉类别辨识学习过程中,最优化学习准则不仅考虑了当前线性表示误差最小原理,而且还将图像基于局部的相似特征结构建模到学习准则的约束项,从而图像在线性表示时,系统优选选择最相似的图像特征进行线性表示,再保证线性系数稀疏性的同时,又提高了系统的辨识性能。(2)本发明框架结构可以无缝地融入更多的图像特征,为后续系统升级提供便利,并且更多有辨识度的图像特征也能进一步提高系统的辨识性能。(3)本发明的辨识法能很好地应用到实际的花卉科普系统中,由于本发明的辨识建模方法识别性能高,从而保证花卉科普系统的鲁棒性和稳定性。附图说明图1为本实施例的基于局部约束稀疏表征的花卉类别辨识方法的流程图。图2为本实施例的统计梯度下降方法主要流程图。具体实施方式下面结合实施例,对本发明作进一步地详细说明,但本发明的实施方式不限于此。实施例如图1所示,本实施例的基于局部约束稀疏表征的花卉类别辨识方法,包括以下步骤:(1)收集花卉图像数据库和建立花卉科普知识库:利用现有的植物花卉维基百科定义313个常用的草本花卉类别的名称,利用google和百度等网络搜索引擎搜索各个花卉类别对应的花卉文字介绍和图片,每个花卉类别下载100张图片。将图片组成花卉图像数据库;将文字说明归入花卉科普知识库。(2)对步骤(1)得到的花卉图像数据库中的所有图片进行特征提取,每张图片提取的特征为6个,包括颜色直方图、SIFT特征(实现细节参考Lowe,D.G.,DistinctiveImageFeaturesfromScale-InvariantKeypoints,InternationalJournalofComputerVision,60,2,pp.91-110,2004)、HOG特征(实现细节参考N.DalalandB.Triggs.Histogramoforientedgradientsforhumandetection.InComputerVisionandPatternRecognition,pp.887–893.IEEE,2005)、BOW特征(实现细节参考S.Lazebnik,C.Schmid,andJ.Ponce.Beyondbagoffeatures:Spatialpyramidmatchingforrecognizingnaturalscenecategories.InComputerVisionandPatternRecognition,pp.2169–2178.IEEE,2006)、SSIM特征(实现细节参考E.ShechtmanandM.Irani.,Matchinglocalself-similaritiesacrossimagesandvideos.InProc.CVPR,2007)、GB特征(实现细节参考A.C.Berg,T.L.Berg,andJ.Malik.,Shapematchingandobjectrecognitionusinglowdistortioncorrespondences.InProc.CVPR,2005)。(3)花卉类别辨识学习过程:(3-1)从花卉图像数据库中挑选30张图片,将其特征作为测试数据集Y={yk},其中k=1...6分别代表图像的6种特征:颜色直方图、SIFT特征、HOG特征、BOW特征、SSIM特征和GB特征;花卉图像数据库中的剩下的31270张图片的特征作为训练数据集其中j=1...313,表示花卉的类别;(3-2)将测试数据特征yk用训练数据特征线性表示为:其中是训练数据集表征测试数据集的权重系数,其值大于0;(3-3)为了训练数据集和测试数据集线性表示误差最小,同时增加测试数据特征和训练数据特征的局部性特征相似性结构的权重约束,建立下面的最优化学习准则:minWjk12Σk=1m||yk-Σj=1SXjkwjk||22+λΣj=1S||DjkΘwjk||2---(1)]]>其中Θ表示向量点乘;λ是约束项权重,是用来平衡线性表示误差与权重系数之间的常数变量(本实施例中设定为0。01);表示测试数据特征yk和其相似的训练数据特征的局部性描述,具体定义是为测试数据特征yk与训练数据特征的欧式距离;在最优化学习准则下,能够保证相似的测试特征会选择相似的训练特征进行线性表示;为了能够使得最终的线性表示系数能够稀疏,一般会将其中权重系数低于一定阈值(本实施例0.005)设为0。(3-4)采用统计梯度下降法(StochasticgradientdescentMethod,简称SGD)对进行迭代更新,更新方程为:wjk,t+1=wjk,t-η▿w▿w=-Xjkyk+XjkXjkwjt+λ||yk-Xjk||22·wjk,t---(2)]]>其中,t是SGD迭代过程的迭代次数,η是统计梯度下降迭代过程的学习率;为了保证学习准则能够有效收敛,本实施例设定学习率η随着迭代次数t的增加而减小,η=11+100t;]]>统计梯度下降方法主要流程过程如图2所示,首先是初始化权重系数然后随机选择部分训练数据集计算其训练数据集和测试数据对应的核函数和接着让i=1,...,n,利用公式(3)进行权重系数n次迭代,迭代完后,计算公式(2)优化目标函数值,如果其比上次迭代过程时值小,重新随机化训练数据集进行下一次迭代循环,或者表明迭代已寻找到最佳权重系数,迭代结束,输出最优线性表示权重系数;(3-5)利用非线性函数φ将训练和测试数据的特征进行非线性映射到高维的再生核希尔伯特空间(reproducingkernelhilbertspace,简称RKHS),即φ(xi)Tφ(xj)=g(xi,xj),其中g(xi,xj)为χ2核函数,xi和xj是数据特征;χ2核函数的表达式为exp(-χ2(x,x)/μ,其中χ2为对称式的卡方(Chi-squared)距离,μ是当前训练数据集的χ2距离的均值。公式(2)变换成:wjk,t+1=wjk,t-η▿w▿w=-Xjkyk+XjkXjkwjt+λ||yk-Xjk||22·wjk,t---(2)]]>其中是训练数据特征与测试数据特征yk的点乘核函数,是训练数据特征与自身的点乘核函数,Pk=φ(yk)φ(yk)是测试数据特征yk与自身的点乘核函数;经过公式(3)的多次迭代,得到最优的表征权重系数(4)辨识花卉:用户拍摄待辨识花卉的图像,对待识别的花卉图像提取特征Zk,其中k=1...6分别代表颜色直方图、SIFT特征、HOG特征、BOW特征、SSIM特征、GB特征;根据Zk,由花卉类别判决公式辨识花卉类别,并从花卉科普知识库中调出该花卉类别对应的文字说明;其中花卉类别判决公式为:其中j*表示利用某个j类别的训练数据的线性表示与测试数据的最小误差值,通过最小选择,j即为识别得到的花卉类别。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1