一种应用哈希Hash划分桶快速获得邻域的方法与流程
本发明属于信息处理领域,尤其涉及一种以二范数距离为度量,采用哈希(Hash)划分桶缩小邻域信息粒子搜索空间的快速获得邻域的方法。
背景技术:
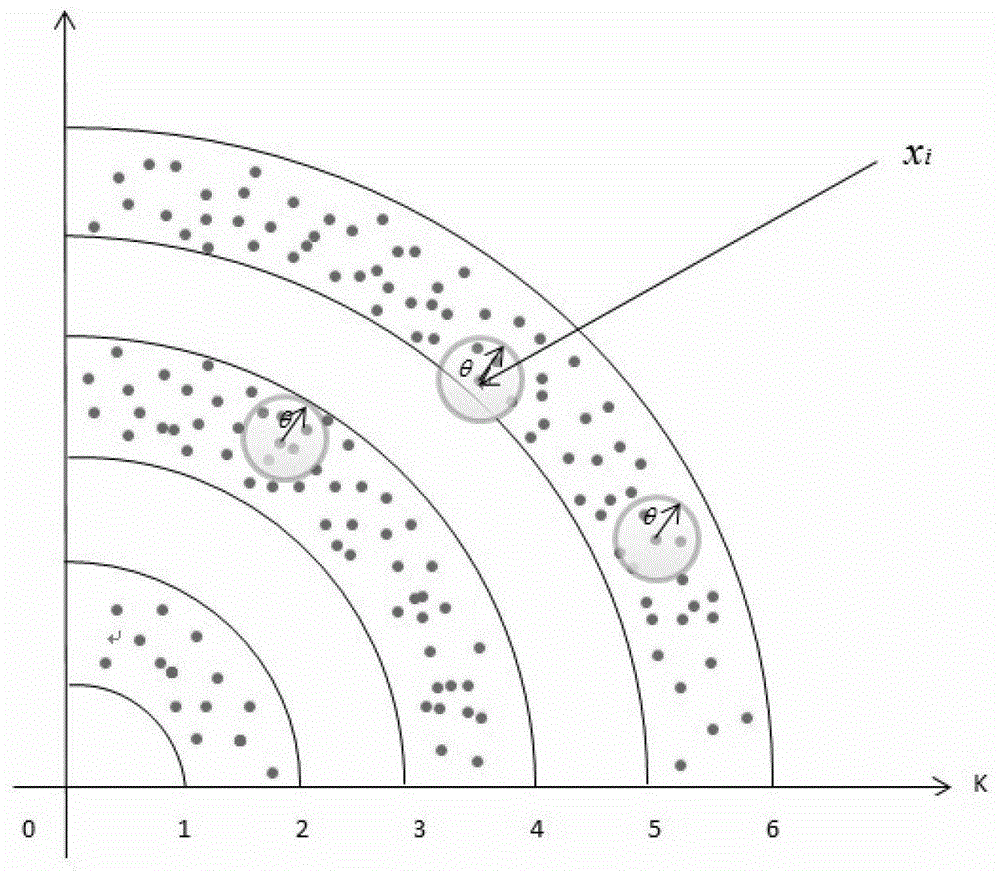
随着信息技术的迅速发展以及数据库管理系统的广泛应用,人们记录的数据越来越多。激增的数据背后隐藏着许多重要的信息,人们希望能够对其进行更高层次的分析,以便更好地利用这些数据。T.Y.Lin于1988年提出了邻域模型的概念,他通过使用空间邻域实现对论域的粒化,并将空间邻域理解为基本的信息粒子,而后利用这些基本信息粒子来描述论域中的其他概念。在1998年,姚一豫教授以及在2002年吴伟志教授对邻域算子和邻域系统的基本系统性质分别进行了深入的研究。Yao讨论了粒计算与粗糙集、商空间等数据挖掘工具之间的关系,并且通过采用逻辑决策语言来描述粒度,构建粒度世界的逻辑框架。Skowron在文献中也描述了粒语言,他将信息表上定义的逻辑公式的意义集看做信息粒,并讨论了这种信息粒的语法和语义。在这些研究的基础上,胡清华将邻域模型引入到粗糙集中,对邻域粗糙集模型进行了详细的定义,并设计可以同时约简名义型、数值型、混合型数据的约简算法。随着数据的爆炸式增加,在运用邻域模型处理大数据时,时间效率就成为了首要考虑的因素。如何减少搜索和计算邻域信息粒子的时间,是一个值得考虑的问题。邻域有两种定义方法:一种是由邻域内所含对象的数量而定,如经典的k-近邻方法;另一种是根据在某一度量上邻域中心点到边界的最大距离进行定义。本发明所涉及的邻域为第2种方法。实数空间上的非空有限集合U={x1,x2,x3,…,xn},对于U上的任意对象xi,其θ邻域为θ(xi)={x∈U,Δ(x,xi)≤θ},其中,θ≥0,θ(xi)称为由xi生成的θ邻域信息粒子,简称xi的邻域粒子,就二维实数空间而言,基于1范 数、2范数和无穷范数的邻域如图3所示,分别为菱形、圆形和正方形区域。度量的性质有:(1)因为xi∈θ(xi);(2)xj∈θ(xi)→xi∈θ(xj);(3)邻域信息粒子族{θ(xi)|i=1,2,…n}构成U的一个覆盖。邻域信息粒子族引导出论域空间U上的一个邻域关系N,该关系可由一个关系矩阵来表示M(N)=(rij)n×n,如果xj∈θ(xi),则rij=1否则rij=0。
技术实现要素:
本发明的目的在于一种应用哈希Hash划分桶快速获得邻域的方法,以减少搜索和计算邻域信息粒子的时间,实现运用邻域模型处理大数据的快速性。为此,本发明采用以下技术方案:本发明方法的具体步骤如下:一种应用哈希Hash划分桶快速获得邻域的方法,其特征在于它包括如下步骤:步骤一,求分桶坐标系的坐标原点x0,根据给定的邻域系统NRS=<U,N,θ>,U是全部样本记录构成的集合,N表示邻域关系,θ为邻域半径;步骤二,求样本的距离,对于求样本间的距离||xi-x0||;步骤三,根据步骤二中的样本距离,用Hash方法建立搜索桶:对于计算k是非负整数。以k作为hashKey建立hash表。建立hash表在空间内的球面模型:将hashKey作为球面的半径,hash表在空间内就是一系列相互嵌套的球;某一hashKey下的样本,处于以hashKey为半径的球面与hashKey-1为半径的球面之间的空间内,相邻球面间的空间称为所述桶,B1,B2,…,Bb,为由b个hashKey值作为半径所得 的b个桶。步骤四,获得邻域:桶Bk-1,Bk,Bk+1内的记录,获得样本x的邻域。在采用上述技术方案的基础上,本发明还可采用以下进一步的技术方案:x0取原点或者是在N中最小值组成的一个特征向量。当搜索桶中样本记录获得邻域时,采用的是迭代方法,只需要搜索Bk,Bk+1桶内的记录来求获得样本x的邻域。本发明根据样本记录间的距离,利用Hash的方法将样本记录的集合划分成桶,集合中任意一个样本记录xi的邻域信息粒子的搜索空间将被缩小到相邻的三个桶Bk-1,Bk,Bk+1内。在此基础上,深入观察发现,当搜索样本记录的邻域空间采用的是迭代方法时,根据邻域系统的对称性原理,可以将邻域信息粒子的搜索空间进一步缩小到两个桶Bk,Ek+1的范围内。本发明的方法根据不同的邻域的大小θ可以得到不同的分桶效果。随着θ值变大,桶的数量将会减少,但是各个桶中所含的样本记录的数量会增加,当分桶是连续的情况下,计算邻域信息粒子时搜索的空间缩小的幅度将会减小,分桶所带来的效果将会减弱,而在所分的桶处于离散的时候,由于可能不存在相邻的桶,这时的搜索空间将会大幅度减小,分桶所带来的缩小邻域信息粒子搜索空间的效果增强。随着θ值变小,桶的数量将会变逐渐增加,桶中所含的样本数量将会减少,这样可能造成每个邻域信息粒子中所包含的信息量将会变少。据以上所述,根据邻域系统NRS=<U,N,θ>的不同情况,通过选择适合的θ值,来充分发挥分桶所带来的缩小邻域信息粒子搜索空间的效果,减少搜索和计算邻域信息粒子的时间。附图说明图1为本发明方法中的分桶为连续情况下的示意图。图2为本发明方法中的分桶为离散情况下的示意图。图3为二维实数空间内,基于1范数、2范数和无穷范数的邻域。具体实施方式为了更好的理解本发明的技术方案,以下结合附图和实施例作进一步描述。步骤一,求分桶坐标系的坐标原点x0:根据给定的邻域系统NRS=<U,N,θ>,求分桶坐标系的坐标原点x0。取N=CUD,则邻域系统NRS=<U,N,θ>成为邻域决策系统NRS=<U,C∪D,θ>,x0取每个属性的最小属性值组成一个特征向量。样本集合U={x1,x2,x3,…,xn},样本属性的集合C={a1,a2,…,am),样本的第i个属性ai,样本决策属性集合D,则基为x0=(min{xl(a1),x2(a1),…xn(a1)},min{x1(a2),x2(a2),…xn(a2)},…,min{x1(a1),x2(a1),…xn(a1)})步骤二,求样本的距离:对于求样本间的距离||xi-x0||;步骤三,根据步骤二中的距离,Hash方法建立桶:对于计算k是非负整数,以k作为hashKey建立hash表。将hashKey作为球面的半径,hash表在空间内就是一系列相互嵌套的球。某一hashKey下的样本,处于以hashKey为半径的球面与hashKey-1为半径的球面之间的空间内,相邻球面间的空间称为所述桶。 B1,B2,…,Bb为由b个hashKey值作为半径所得的b个桶。则U中的一部分记录在空间的分布如图1、图2所示,图1给出了一种较特殊的情况,即k是连续的;而实际上,对特定的数据而言,k可能是不连续的,即图2所示。步骤四,获得邻域:搜索桶Bk-1,Bk,Bk+1内的记录,求其邻域。当搜索桶中样本记录求解邻域时,采用的是迭代方法,由于邻域系统的对称性,只需要搜索Bk,Bk+1桶内的记录来求解其邻域。如图1中所示,对k=2的桶内的样本,在求解邻域的时候,可以只搜索k=2与k=3桶内的样本。如图2所示,在桶不连续的情况下,对于k=2桶中的样本,由于其相邻的k=3桶内为空,其桶内样本邻域的求解空间缩小了。应用hash建立桶的时间复杂度为O(n),n=|U|。样本属性集合C={a1,a2,…,am}中的样本属性的个数为m,建立的分桶的个数为b,在样本被均匀地分布到各个桶中的情况下,邻域计算的复杂度为在b趋近于|u|的情况下,邻域计算的复杂度将会趋近于O(m|U|)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1