一种通过多级拟合得到标准化模型运动的方法及电子设备与流程
本发明涉及计算机技术领域,特别涉及一种通过多级拟合得到标准化模型运动的方法及电子设备。
背景技术:
在实时视频中的人脸识别和跟踪领域,现有技术通常使用单次拟合来获得模型的运动,这种方式往往是保证了稳定性就无法保证精度,而如果保证了精度稳定性就比较差,二者通常不可兼得。
技术实现要素:
为了解决上述问题,本发明提供一种通过多级拟合得到标准化模型运动的方法及电子设备。
所述技术方案如下:
第一方面,提供了一种通过多级拟合得到标准化模型运动的方法,所述方法包括:
获取人脸正面的特征点;
对所述特征点进行回归估计,得到第一结果;
对所述第一结果进行第一次线性拟合,得到第二结果;
对所述第二结果进行夸张,得到第三结果;
对所述第三结果进行第二次线性拟合,得到最终结果。
结合第一方面,在第一种可能的实现方式中,所述获取人脸正面的特征点包括:
通过摄像头实时采集人脸正面特征点。
结合第一方面,在第二种可能的实现方式中,所述对所述特征点进行回归估计,得到第一结果包括:
根据预设的公式和预设的人脸特征库对所述特征点进行岭回归估计;
根据所述岭回归估计得到的参数和所述人脸特征库输出所述第一结果。
结合第一方面,在第三种可能的实现方式中,所述对所述第一结果进行第一次线性拟合,得到第二结果包括:
根据预设的公式和预设的人脸特征库对所述第一结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述第二结果。
结合第一方面的第三种可能的实现方式,在第四种可能的实现方式中,所述人脸特征库是归一化后的人脸特征库。
结合第一方面的第四种可能的实现方式,在第五种可能的实现方式中,所述二次规划中的约束参数的取值范围为(0.001,1]。
结合第一方面,在第六种可能的实现方式中,所述对所述第二结果进行夸张,得到第三结果包括:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果。
结合第一方面的第六种可能的实现方式,在第七种可能的实现方式中,所述预设的表情模型为无表情模型。
结合第一方面的第六种可能的实现方式,在第八种可能的实现方式中,所述夸张系数的取值范围为[1,10]。
结合第一方面,在第九种可能的实现方式中,所述对所述第三结果进行第二次线性拟合,得到最终结果包括:
根据预设的公式和预设的人脸特征库对所述第三结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述最终结果。
结合第一方面的第九种可能的实现方式,在第十种可能的实现方式中,所述人脸特征库是归一化后的人脸特征库。
结合第一方面的第九种可能的实现方式,在第十一种可能的实现方式中,所述二次规划中的约束参数的取值范围为(0,0.001]。
结合第一方面的第二种至第一方面的第十一种任一项可能的实现方式,在第十二种可能的实现方式中,所述预设的人脸特征库中的人脸模型是3D模型。
结合第一方面的第十二种可能的实现方式,在第十三种可能的实现方式中,所述人脸模型与所述人脸正面的特征点的点数一样,面数一样,面序一样,点序一样。
第二方面,提供了一种电子设备,所述电子设备包括:
获取模块,用于获取人脸正面的特征点;
估计模块,用于对所述特征点进行回归估计,得到第一结果;
第一拟合模块,用于对所述第一结果进行第一次线性拟合,得到第二结果;
夸张模块,用于对所述第二结果进行夸张,得到第三结果;
第二拟合模块,用于对所述第三结果进行第二次线性拟合,得到最终结果。
结合第二方面,在第一种可能的实现方式中,所述获取模块通过摄像头实时采集人脸正面特征点。
结合第二方面,在第二种可能的实现方式中,所述估计模块具体用于:
根据预设的公式和预设的人脸特征库对所述特征点进行岭回归估计;
根据所述岭回归估计得到的参数和所述人脸特征库输出所述第一结果。
结合第二方面,在第三种可能的实现方式中,所述第一拟合模块具体用于:
根据预设的公式和预设的人脸特征库对所述第一结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述第二结果。
结合第二方面的第三种可能的实现方式,在第四种可能的实现方式中,所述人脸特征库是归一化后的人脸特征库。
结合第二方面的第四种可能的实现方式,在第五种可能的实现方式中,所述二次规划中的约束参数的取值范围为(0.001,1]。
结合第二方面,在第六种可能的实现方式中,所述夸张模块具体用于:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果。
结合第二方面的第六种可能的实现方式,在第七种可能的实现方式中,所述预设的表情模型为无表情模型。
结合第二方面的第六种可能的实现方式,在第八种可能的实现方式中,所述夸张系数的取值范围为[1,10]。
结合第二方面,在第九种可能的实现方式中,所述第二拟合模块具体用于:
根据预设的公式和预设的人脸特征库对所述第三结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述最终结果。
结合第二方面的第九种可能的实现方式,在第十种可能的实现方式中,所述人脸特征库是归一化后的人脸特征库。
结合第二方面的第九种可能的实现方式,在第十一种可能的实现方式中,所述二次规划中的约束参数的取值范围为(0,0.001]。
结合第二方面的第二种至第二方面的第十一种任一项可能的实现方式,在第十二种可能的实现方式中,所述预设的人脸特征库中的人脸模型是3D模型。
结合第二方面的第十二种可能的实现方式,在第十三种可能的实现方式中,所述人脸模型与所述人脸正面的特征点的点数一样,面数一样,面序一样,点序一样。
第三方面,提供了一种电子设备,所述设备包括存储器,摄像头,以及与所述存储器,所述摄像头连接的处理器,其中,所述存储器用于存储一组程序代码,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
获取人脸正面的特征点;
对所述特征点进行回归估计,得到第一结果;
对所述第一结果进行第一次线性拟合,得到第二结果;
对所述第二结果进行夸张,得到第三结果;
对所述第三结果进行第二次线性拟合,得到最终结果。
结合第三方面,在第一种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
通过摄像头实时采集人脸正面特征点。
结合第三方面,在第二种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据预设的公式和预设的人脸特征库对所述特征点进行岭回归估计;
根据所述岭回归估计得到的参数和所述人脸特征库输出所述第一结果。
结合第三方面,在第三种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据预设的公式和预设的人脸特征库对所述第一结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述第二结果。
结合第三方面的第三种可能的实现方式,在第四种可能的实现方式中,所述人脸特征库是归一化后的人脸特征库。
结合第三方面的第四种可能的实现方式,在第五种可能的实现方式中,所述二次规划中的约束参数的取值范围为(0.001,1]。
结合第三方面,在第六种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果。
结合第三方面的第六种可能的实现方式,在第七种可能的实现方式中,所述预设的表情模型为无表情模型。
结合第三方面的第六种可能的实现方式,在第八种可能的实现方式中,所述夸张系数的取值范围为[1,10]。
结合第三方面,在第九种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据预设的公式和预设的人脸特征库对所述第三结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述最终结果。
结合第三方面的第九种可能的实现方式,在第十种可能的实现方式中,所述人脸特征库是归一化后的人脸特征库。
结合第三方面的第九种可能的实现方式,在第十一种可能的实现方式中,所述二次规划中的约束参数的取值范围为(0,0.001]。
结合第三方面的第二种至第一方面的第十一种任一项可能的实现方式,在第十二种可能的实现方式中,所述预设的人脸特征库中的人脸模型是3D模型。
结合第三方面的第十二种可能的实现方式,在第十三种可能的实现方式中,所述人脸模型与所述人脸正面的特征点的点数一样,面数一样,面序一样,点序一样。
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,通过两次二次规划使得得到的结果既保持稳定又具有较高的精度,其中第一次二次规划通过采用较大的约束参数使得得到的结果保持稳定,第二次二次规划通过采用较小的约束参数使得得到的结果具有较高的精度,从而有效地解决了稳定性和精度不可兼得的问题。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种通过多级拟合得到标准化模型运动的方法流程图;
图2是本发明实施例提供的一种通过多级拟合得到标准化模型运动的方法流程图;
图3是本发明实施例提供的一种通过多级拟合得到标准化模型运动的方法流程图;
图4是本发明实施例提供的一种电子设备的结构示意图;
图5是本发明实施例提供的一种电子设备的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,该方法既可以用于实时视频中的人脸识别与跟踪,也可以用于静态图像中的人脸视频与跟踪,该方法可以是通过运行电子设备上的应用程序实现的,该电子设备可以是智能手机、平板电脑和其他电子设备中的任意一个,本发明实施例对具体的电子设备不加以限定。
实施例一
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,参照图1所示,方法流程包括:
101、获取人脸正面的特征点。
具体的,该过程可以包括:
摄像头实时采集视频帧数据;
从所述视频帧中识别出人脸部分;
提取所述人脸部分的正面特征点。
102、对所述特征点进行回归估计,得到第一结果。
具体的,根据所述特征点和预设的人脸特征库进行岭回归估计,得到第一结果。
103、对所述第一结果进行第一次线性拟合,得到第二结果。
具体的,根据所述第一结果和预设的人脸特征库进行二次规划,得到第二结果。
104、对所述第二结果进行夸张,得到第三结果。
具体的,该过程可以包括:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果。
105、对所述第三结果进行第二次线性拟合,得到最终结果。
具体的,根据所述第三结果和预设的人脸特征库进行二次规划,得到第二最终结果。
其中,步骤103中二次规划的约束参数取值较大,步骤105中二次规划中的约束参数取值较小。
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,通过两次二次规划使得得到的结果既保持稳定又具有较高的精度,其中第一次二次规划通过采用较大的约束参数使得得到的结果保持稳定,第二次二次规划通过采用较小的约束参数使得得到的结果具有较高的精度,从而有效地解决了稳定性和精度不可兼得的问题。
实施例二
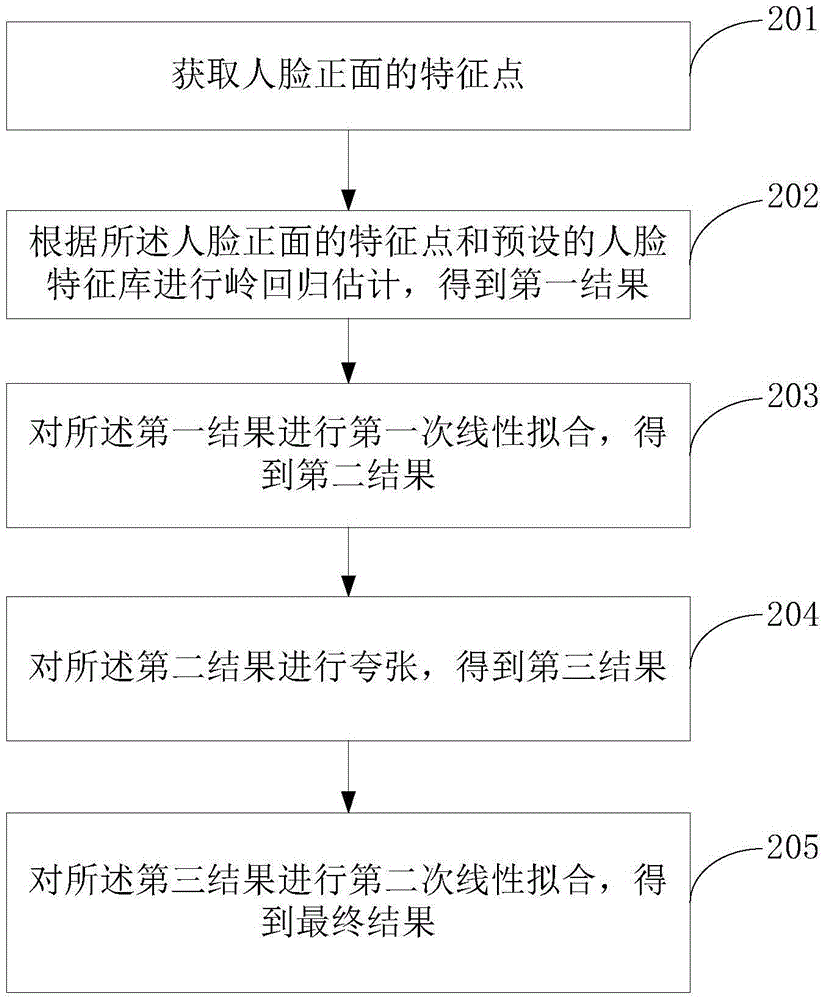
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,参照图2所示,方法流程包括:
201、获取人脸正面的特征点。
具体的,该过程可以包括:
摄像头实时采集视频帧数据;
从所述视频帧中识别出人脸部分;
提取所述人脸部分的特征点;
将所述特征点映射为人脸正面的特征点。
202、根据所述人脸正面的特征点和预设的人脸特征库进行岭回归估计,得到第一结果。
具体的,以所述人脸正面的特征点为因变量Y,以所述预设的人脸特征库中的人脸模型为自变量X的线性回归的公式为:
Y=aX+b (1)
其中,a和b是线性回归的参数。
根据公式(1)可以推导出公式(2):
Y-bXT=aXXT (2)
根据公式(2)和岭回归算法,可以推导出公式(3):
a=Y-bXT×XXT+λI-1 (3)
其中,I为单位矩阵,λ为岭回归参数。
根据所述人脸正面的特征点和人脸特征库以及公式(3)可以计算出a和b的估算值a'和b',根据a'和b'以及所述人脸特征库X可计算得到Y'=a'X+b',其中Y'即为所述第一结果,Y'是对Y的估计。
示例性的,当所述人脸正面特征点的数量为66个,所述人脸特征库中有30个人脸模型时,Y,a和b是132维向量,X是132×30维的矩阵。
203、对所述第一结果进行第一次线性拟合,得到第二结果。
具体的,
对所述人脸特征库进行归一化,即对任意xi∈X,使得0≤xi≤1。
根据步骤202中的第一结果和归一化后的人脸特征库进行二次规划,得到第二结果。
以所述第一结果Y'为因变量,以所述归一化后的人脸特征库中的人脸模型为自变量X的线性回归的公式为:
Y'=aX+b (4)
其中,a和b是线性回归的参数,需要指出的是,公式(4)中的a和b与公式(1)中的a和b的取值可以不同。
根据公式(4)和二次规划算法得到公式:
s.t. aiXT≥bi, i∈I
其中X为归一化后的人脸特征库,G为对称矩阵,C为向量,ai为向量,bi为二次规划中的约束参数,其元素的取值范围为(0.001,1],I为约束参数的集合。
根据第一结果Y'以及不同的约束参数bi,可以求得不同的G和C,根据求的的G和C可以计算出a和b的估算值a'和b',根据a'和b'以及公式(4)可以计算出第二结果Y”=a'X+b',Y”是对Y'的估计。
优选的,bi中所有元素的取值都为0.008。
通过选取较大的约束参数,能够使得二次规划的结果保持稳定。
204、对所述第二结果进行夸张,得到第三结果。
具体的,该过程可以包括:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果,即:
Y”'=Y”-N×k+N
其中,Y”为所述第二结果,N为预设的表情模型,优选的,N为无表情模型,k为夸张系数,取值范围为[1,10],优选的,k=2.5。
通过获取所述第二结果与无表情模型的差值,保留了人脸表情的特征,再通过夸张系数进行放大,提高了所述人脸表情的特征的显著性,使得到的表情特征更加明显。
205、对所述第三结果进行第二次线性拟合,得到最终结果。
具体的,
根据步骤203中的归一化后的人脸特征库和步骤204中的第三结果进行二次规划,得到最终结果。
以所述第三结果Y”'为因变量,以所述归一化后的人脸特征库中的人脸模型为自变量X的线性回归的公式为:
Y”'=aX+b (5)
其中,a和b是线性回归的参数,需要指出的是,公式(5)中的a和b与公式(1)中的a和b以及公式(4)中的a和b的取值可以不同。
根据公式(5)和二次规划算法得到公式:
s.t. aiXT≥bi, i∈I
其中X为归一化后的人脸特征库,G为对称矩阵,C为向量,ai为向量,bi为二次规划中的约束参数,其元素的取值范围为(0,0.001],I为约束参数的集合。
根据第三结果Y”'以及不同的约束参数bi,可以求得不同的G和C,根据求的的G和C可以计算出a和b的估算值a'和b',根据a'和b'以及公式(5)可以计算出最终结果Y””=a'X+b',Y””是对Y”'的估计。
通过选取较小的约束参数,能够使得二次规划的结果保持较好的精度。
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,通过两次二次规划使得得到的结果既保持稳定又具有较高的精度,其中第一次二次规划通过采用较大的约束参数使得得到的结果保持稳定,第二次二次规划通过采用较小的约束参数使得得到的结果具有较高的精度,从而有效地解决了稳定性和精度不可兼得的问题,同时通过对表情特征进行夸张,使得获得的表情特征更加的明显。
实施例三
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,参照图3所示,方法流程包括:
301、获取人脸正面的特征点。
具体的,该过程可以包括:
摄像头实时采集视频帧数据;
从所述视频帧中识别出人脸部分;
提取所述人脸部分的特征点;
根据迭代算法将所述特征点映射为人脸正面的特征点。
302、根据所述人脸正面的特征点和预设的人脸特征库进行岭回归估计,得到第一结果。
根据所述人脸正面的特征点和人脸特征库以及公式(3)可以计算出a和b的估算值a'和b',根据a'和b'以及所述人脸特征库X可计算得到Y'=a'X+b',其中Y'即为所述第一结果,Y'是对Y的估计。
示例性的,所述预设的人脸特征库为3D人脸特征库,其中的模型与所述人脸正面特征点的点数一样,面数一样,面序一样,点序一样,当所述人脸正面特征点的数量为33个,所述人脸特征库中有50张人脸时,Y,a和b是66维向量,X是66×50维的矩阵。
303、对所述第一结果进行第一次线性拟合,得到第二结果。
具体的,
对所述人脸特征库进行归一化,即对任意xi∈X,使得0≤xi≤1。
根据步骤302中的第一结果和归一化后的人脸特征库进行二次规划,得到第二结果。
以所述第一结果Y'为因变量,以所述归一化后的人脸特征库中的人脸模型为自变量X的线性回归的公式为:
Y'=aX+b (4)
其中,a和b是线性回归的参数,需要指出的是,公式(4)中的a和b与公式(1)中的a和b的取值可以不同。
根据公式(4)和二次规划算法得到公式:
s.t. aiXT≥bi, i∈I
其中X为归一化后的人脸特征库,G为对称矩阵,C为向量,ai为向量,bi为二次规划中的约束参数,其元素的取值范围为(0.001,1],I为约束参数的集合。
根据第一结果Y'以及不同的约束参数bi,可以求得不同的G和C,根据求的的G和C可以计算出a和b的估算值a'和b',根据a'和b'以及公式(4)可以计算出第二结果Y”=a'X+b',Y”是对Y'的估计。
优选的,bi中所有元素的取值都为0.01。
通过选取较大的约束参数,能够使得二次规划的结果保持稳定。
304、对所述第二结果进行夸张,得到第三结果。
具体的,该过程可以包括:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果,即:
Y”'=Y”-N×k+N
其中,Y”为所述第二结果,N为预设的表情模型,优选的,N为无表情模型,k为夸张系数,取值范围为[1,10],优选的,k=3。
通过获取所述第二结果与无表情模型的差值,保留了人脸表情的特征,再通过夸张系数进行放大,提高了所述人脸表情的特征的显著性,使得到的表情特征更加明显。
305、对所述第三结果进行第二次线性拟合,得到最终结果。
具体的,
根据步骤303中的归一化后的人脸特征库和步骤304中的第三结果进行二次规划,得到最终结果。
以所述第三结果Y”'为因变量,以所述归一化后的人脸特征库中的人脸模型为自变量X的线性回归的公式为:
Y”'=aX+b (5)
其中,a和b是线性回归的参数,需要指出的是,公式(5)中的a和b与公式(1)中的a和b以及公式(4)中的a和b的取值可以不同。
根据公式(5)和二次规划算法得到公式:
s.t. aiXT≥bi, i∈I
其中X为归一化后的人脸特征库,G为对称矩阵,C为向量,ai为向量,bi为二次规划中的约束参数,其元素的取值范围为(0,0.001],I为约束参数的集合。
根据第三结果Y”'以及不同的约束参数bi,可以求得不同的G和C,根据求的的G和C可以计算出a和b的估算值a'和b',根据a'和b'以及公式(5)可以计算出最终结果Y””=a'X+b',Y””是对Y”'的估计。
通过选取较小的约束参数,能够使得二次规划的结果保持较好的精度。
本发明实施例提供了一种通过多级拟合得到标准化模型运动的方法,通过两次二次规划使得得到的结果既保持稳定又具有较高的精度,其中第一次二次规划通过采用较大的约束参数使得得到的结果保持稳定,第二次二次规划通过采用较小的约束参数使得得到的结果具有较高的精度,从而有效地解决了稳定性和精度不可兼得的问题,同时通过对表情特征进行夸张,使得获得的表情特征更加的明显。
实施例四
本发明实施例提供了一种电子设备,参照图4所示,该电子设备包括:
获取模块401,用于获取人脸正面的特征点。
具体的,
获取模块401通过摄像头实时采集视频帧数据;
获取模块401从所述视频帧中识别出人脸部分;
获取模块401提取所述人脸部分的正面特征点。
估计模块402,用于对所述特征点进行回归估计,得到第一结果。
具体的,估计模块402根据所述特征点和预设的人脸特征库进行岭回归估计,得到第一结果。其具体估计过程与步骤202或步骤302中的过程一样,此处不再敷述。
第一拟合模块403,用于对所述第一结果进行第一次线性拟合,得到第二结果。
具体的,第一拟合模块403根据所述第一结果和预设的人脸特征库进行二次规划,得到第二结果。其具体规划过程与步骤203或步骤303中的过程一样,此处不再敷述。
夸张模块404,用于对所述第二结果进行夸张,得到第三结果。
具体的,
夸张模块404获取所述第二结果与预设的表情模型的差值;
夸张模块404将所述差值乘以预设的夸张系数,得到夸张后的差值;
夸张模块404以所述预设表情模型与所述夸张后的差值的和作为所述第三结果,即:
Y”'=Y”-N×k+N
其中,Y”为所述第二结果,N为预设的表情模型,优选的,N为无表情模型,k为夸张系数,取值范围为[1,10],优选的,k=2.5。
第二拟合模块405,用于对所述第三结果进行第二次线性拟合,得到最终结果。
具体的,第二拟合模块405根据所述第三结果和预设的人脸特征库进行二次规划,得到第二最终结果。其具体规划过程与步骤205或步骤305中的过程一样,此处不再敷述。
本发明实施例提供了一种电子设备,通过两次二次规划使得得到的结果既保持稳定又具有较高的精度,其中第一次二次规划通过采用较大的约束参数使得得到的结果保持稳定,第二次二次规划通过采用较小的约束参数使得得到的结果具有较高的精度,从而有效地解决了稳定性和精度不可兼得的问题,同时通过对表情特征进行夸张,使得获得的表情特征更加的明显。
实施例五
本发明实施例提供了一种电子设备,参照图5所示,该电子设备包括存储器501、摄像头502、以及与存储器501、摄像头502连接的处理器503,其中,存储器501用于存储一组程序代码,处理器503调用存储器501所存储的程序代码用于执行以下操作:
获取人脸正面的特征点;
对所述特征点进行回归估计,得到第一结果;
对所述第一结果进行第一次线性拟合,得到第二结果;
对所述第二结果进行夸张,得到第三结果;
对所述第三结果进行第二次线性拟合,得到最终结果。
具体的,处理器503调用存储器501所存储的程序代码用于执行以下操作:
通过摄像头502实时采集人脸正面特征点。
具体的,处理器503调用存储器501所存储的程序代码用于执行以下操作:
根据预设的公式和预设的人脸特征库对所述特征点进行岭回归估计;
根据所述岭回归估计得到的参数和所述人脸特征库输出所述第一结果。
具体的,处理器503调用存储器501所存储的程序代码用于执行以下操作:
根据预设的公式和预设的人脸特征库对所述第一结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述第二结果。
优选的,所述人脸特征库是归一化后的人脸特征库。
优选的,所述二次规划中的约束参数的取值范围为(0.001,1]。
具体的,处理器503调用存储器501所存储的程序代码用于执行以下操作:
获取所述第二结果与预设的表情模型的差值;
将所述差值乘以预设的夸张系数,得到夸张后的差值;
以所述预设表情模型与所述夸张后的差值的和作为所述第三结果。
优选的,所述预设的表情模型为无表情模型。
优选的,所述夸张系数的取值范围为[1,10]。
具体的,处理器503调用存储器501所存储的程序代码用于执行以下操作:
根据预设的公式和预设的人脸特征库对所述第三结果进行二次规划;
根据所述二次规划得到的参数和所述人脸特征库输出所述最终结果。
优选的,所述人脸特征库是归一化后的人脸特征库。
优选的,所述二次规划中的约束参数的取值范围为(0,0.001]。
优选的,所述预设的人脸特征库中的人脸模型是3D模型。
优选的,所述人脸模型与所述人脸正面的特征点的点数一样,面数一样,面序一样,点序一样。
本发明实施例提供了一种电子设备,通过两次二次规划使得得到的结果既保持稳定又具有较高的精度,其中第一次二次规划通过采用较大的约束参数使得得到的结果保持稳定,第二次二次规划通过采用较小的约束参数使得得到的结果具有较高的精度,从而有效地解决了稳定性和精度不可兼得的问题,同时通过对表情特征进行夸张,使得获得的表情特征更加的明显。
以上仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭示如上,然而并非用以限定本发明,本领域普通技术人员在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容做出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!