基于改进ORAR算法的关联规则推荐系统的制作方法
本发明涉及一套基于改进orar算法的关联规则推荐系统,是一种基于关系代数理论,利用关系矩阵及相关运算寻找出关联规则的推荐系统。该系统在实现orar算法的过程中,将支持度及对应的偏好标签存储在一个名字空间矩阵内,同时通过置信度求解函数求解出相应的置信度从而求解出关联规则。属于数据挖掘领域。
背景技术:
随着“啤酒、尿布”案例在营销届的成功运用,人们对不断收集的数据中关联规则的挖掘原来越感兴趣,关联规则的应用范围也逐渐从超市营销扩展到更多的领域。当前的关联规则挖掘算法主要有apriori和orar等,apriori算法会产生大量的候选集,需要重复扫描数据库,效率低下。orar算法利用关系矩阵进行计算,只需扫描一遍数据库,效率较高。但是仍然存在一系列的问题。例如,不易查找频繁项集对应的支持度,求不出强规则等。
技术实现要素:
本发明的目的是克服现有技术中存在的不足,提供一种基于改进orar算法的关联规则推荐系统,本发明扩充了orar关联规则算法,将大于支持度阈值的频繁项集的各个偏好标签与其对应的支持度存储在一个名字空间矩阵内。能够快速的找出支持度从而求解出置信度。在利用orar只需扫描一遍数据库的优点之上解决了orar无法求出置信度的缺点,从而为企业、商家提供更为高效、方便的关联规则挖掘业务,具有较大实用价值。
本发明提出的基于改进orar算法的关联规则挖掘系统,包括数据预处理模块、、1大项集生成模块、2大项集生成模块、k大项集生成模块和关联规则生成模块。所述数据预处理模块与数据库交互,负责将数据库的文本转换为适合运算的关系矩阵。所述1大项集生成模块、2大项集生成模块、k大项集生成模块共同构成orar算法的具体实现,负责频繁项集的生成和支持度的计算;所述关联规则生成模块与支持度求解模块交互,负责根据支持度求解模块生成的支持度求出置信度从而转化为具体的关联规则。
本法明的优点在于:将大于支持度阈值的频繁项集的各个偏好标签与其对应的支持度存储在一个名字空间矩阵内。在求解关联规则的置信度时,编写求解函数。根据偏好标签查找名字空间矩阵,再找出与偏好标签相匹配的支持度,代入置信度公式求解。在充分利用orar算法只需扫描一遍数据库的优点,解决了orar算法存在的不易查找频繁项集对应的支持度,求不出强规则等问题。提高了关联规则挖掘的效率。
附图说明
图1为本发明的结构框图。
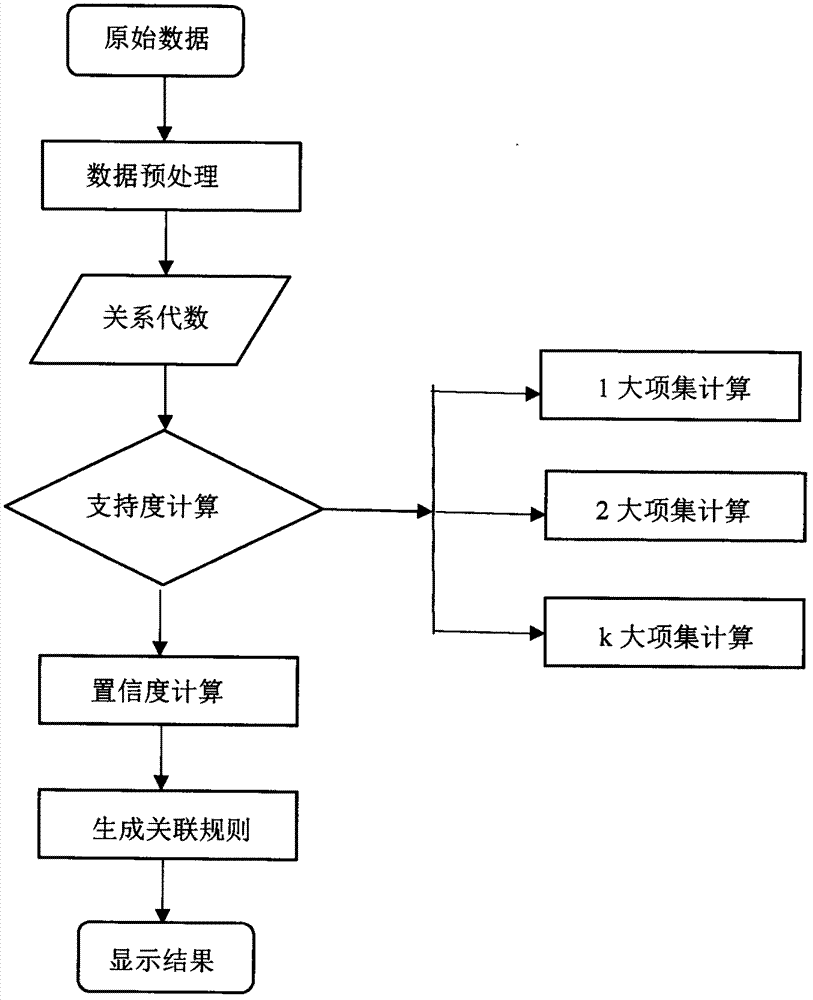
图2为本发明的工作流程图。
具体实施方式
下面结合具体附图和实施例对本发明作进一步说明。
本发明提出的基于改进orar算法的关联规则挖掘系统,包括数据预处理模块、1大项集生成模块、2大项集生成模块、k大项集生成模块和关联规则生成模块。所述数据预处理模块与数据库交互,负责将数据库的文本转换为适合运算的关系矩阵。所述1大项集生成模块、2大项集生成模块、k大项集生成模块共同构成orar算法的具体实现,负责频繁项集的生成和支持度的计算;所述关联规则生成模块与支持度求解模块交互,负责根据支持度求解模块生成的支持度求出置信度从而转化为具体的关联规则。
具体地、所述数据预处理模块需要扫描数据库,设d是事务数据库,t={t1,t2,…,tm}和i={i1,i2,…,in}分别为数据库中的交易集和项集,得到互相关矩阵
其中i=1,2,…,m,j=1,2,…,n。r为从t到i的二元关系矩阵,i就是使用频率,t就是采样次数。
设某特征子集对应的集合为一个关系数据库的子集dbi,若dbi中有m条记录和n个项,则通过扫描一次数据库,构造互相关矩阵
其中i=1,2,…,m,j=1,2,…,n。rij的值为1或0,分别表示第i个事务中包含或未包含第j个项。
所述1大项集生成模块、2大项集生成模块、k大项集生成模块主要针对现有的orar算法进行了改进,目前的orar算法只能在给出最小支持度阈值基础上求解频繁项集,通过判定支持度是否大于最小支持度来确定该频繁项集的保留与丢弃,但并没有将该频繁项集与其对应的支持度存储在同一名字空间内。因此难以查找各频繁项集对应的支持度,无法求解各关联规则对应的置信度及强规则。
针对以上不足,对orar算法进行了如下改进:
将大于支持度阈值的频繁项集的各个偏好标签与其对应的支持度存储在一个名字空间矩阵内。
在求解关联规则的置信度时,编写求解函数。根据偏好标签查找名字空间矩阵,再找出与偏好标签相匹配的支持度,代入置信度公式求解。
具体的计算步骤如下:
一、求解1-项集的支持度。对于大于支持度阈值的项目集,将偏好标签与其对应的支持度存入矩阵aorar1=(aij)p×q(p=x,q=2)中,其中x为筛选结果行数。
二、根据求解的1-项集,将1-项集中的偏好标签两两组合(排除重复),求解2-项集的支持度。对于大于支持度阈值的项集,将组合偏好标签与其对应的支持度存入aorar2=(aij)p×q(p=y,q=3),其中y为筛选结果行数。
三、在求解k-项集时,根据求解的1-项集和(k-1)-项集进行k阶组合,排除两种重复:项目集内部的偏好标签重复和项目集间的组合重复。对于大于支持度阈值的项目集,将组合偏好标签与其对应的支持度存入aorark=(aij)p×q(p=z,q=k+1),其中z为筛选结果行数。
所述关联规则生成模块主要是用来根据所述支持度求解模块的结果求解出置信度从而生成相应的关联规则。具体的工作过程如下:
在置信度求解函数中,对形如
如图1所示,本系统分数据预处理模块、支持度求解模块和关联规则生成模块。其中所述数据预处理模块安装在操作系统之上,与mysql数据库直接交互。所述关联规则生成模块与具体应用程序或命令行界面交互,输出具体关联规则。
具体地,所述数据预处理模块安装在ubuntu操作系统之上,通过jdbc与mysq1数据库连接。所述关联规则生成模块为java接口,通过java静态函数实现,可以在任何java程序中调用,生成的关联规则保存在list中,system.out输出。具体系统工作流程如图2所示。
本发明扩充了orar关联规则算法,将大于支持度阈值的频繁项集的各个偏好标签与其对应的支持度存储在一个名字空间矩阵内。能够快速的找出支持度从而求解出置信度。在利用orar只需扫描一遍数据库的优点之上解决了orar无法求出置信度的缺点,从而为企业、商家提供更为高效、方便的关联规则挖掘业务,具有较大实用价值。
- 还没有人留言评论。精彩留言会获得点赞!