基于向量回归机和遗传算法的地震属性优选方法与流程
本发明涉及油田勘探开发技术领域,特别是涉及到一种基于向量回归机和遗传算法的地震属性优选方法。
背景技术:
在进行地震储层预测时,通常引入与储层预测有关的各种地震属性。地震属性的引入通常要经过一个从少到多,又从多到少的过程。所谓从少到多,是指在设计预测方案的初期阶段应该尽量多的列举出各种可能与储层预测有关的属性。这样可以充分利用各种有用的信息,吸收各方面专家的经验,改善储层预测的效果。但是,属性的无限增加对于储层预测也会带来不利的影响,因为:
(1)有些地震属性可能与目的层本身无关,而反映了浅层干扰的变化,若对输入属性不加鉴别,有些属性只会引起混乱;
(2)增加属性会给计算带来困难,因为过多的数据占用大量的存储空间和计算时间;
(3)大量的属性中肯定会包含着许多彼此相关的因素,造成信息的重复和浪费;
(4)属性数是与训练样本数有关的。就模式识别而言,当样本数固定时,属性数过多会造成分类效果的恶化。
因此,针对具体问题,必须从众多的地震属性中挑选一些最好的地震属性或属性组合。
常用的属性优选方法有属性比较法、顺序前进法、顺序后退法、遗传算法等。
遗传算法(ga)是一种解组合最优问题的全局搜索算法。引入遗传算法可以找到组合优化问题的全局或近似最优解,即找出储层预测中的最优或次优地震属性组合。该算法是一种基于生物界自然选择和自然遗传机制解组合优化问题的全局搜索算法,但又区别于普通的搜索算法。普通的搜索算法一般只是从一个解出发改进到另一个较好的解而遗传算法则是从原问题的一组解出发改进到另一组较好的解。
遗传算法主要由以下几个问题组成:
(1)编码问题
遗传算法不能直接处理问题空间的参数,必须把它们转换成遗传空间内按一定结构且由基因组成的染色体或个体。这一转换操作称为编码,也可以称作问题的表示。通常由问题空间向ga空间的映射称作编码,而由ga空间向问题空间的映射称作“译码”。评估编码水平常采用三个方面的指标,即完备性问题(空间中的所有候选解都能表示为ga空间的染色体)、健全性(ga空间中的染色体能对应所有问题空间中的候选解)和非冗余性(染色体和候选解一一对应)。
(2)群体设定
遗传操作是对众多个体同时进行的,这些众多个体组成了群体。在遗传算法处理流程编码设计之后的任务是初始群体的设定,并以此为起点一代一代地进化,直到满足某种进化停止准则而结束进化过程,此时得到最后一代或群体。在遗传算法中初始群体的设定可采取如下策略:①根据问题固有知识,设法把握最优解所占空间在整个问题空间中的分布范围,并在此范围内设定初始群体;②随机生成一定数目的个体,并从中挑出最好的个体加人到初始群体中。这种过程不断迭代,直到初始群体中个数达到预先确定的规模。
(3)遗传操作
遗传操作是模拟生物基因遗传的操作。在遗传算法通过编码组成初始群体后,遗传操作的任务就是对群体中的个体,按照它们对环境的适应程度适应度评估完成一定的操作,从而实现优胜劣汰的进化过程。从优化搜索的角度而言,遗传操作可使问题的解逐代优化,并逼近最优解。遗传操作包括选择、交叉和变异三个基本遗传算子,它们具有操作的随机化特点,其效果与三个遗传算子所取得的操作概率、编码方法、群体大小、初始群体以及适应度函数的设定密切相关。
遗传算法有一个非常关键的问题:群体中个体适应度的评价。2002年,王永刚教授发表《地震属性的ga-bp优化方法》,将遗传算法与神经网络算法相结合,发挥两种算法的优势,寻找全局最优,但是神经网络算法本身容易陷于局部最优,而且样本数据需要量大。2006年,韦振中老师发表《基于支 持向量机和遗传算法的特征选择》,在适应度评价时,使用支持向量分类机,实现对属性的定性分类,没有上升到定量评价的高度。2012年,张长开老师发表《基于支持向量机的属性优选和储层预测》,介绍支持向量回归机可以建立储层特征参数与优选属性之间的最优化定量计算关系,可以对属性优选实现定量化评价。为此我们发明了一种新的基于向量回归机和遗传算法的地震属性优选方法,解决了以上技术问题。
技术实现要素:
本发明的目的是提供一种把支持向量回归机引入到遗传算法当中,通过对优选属性的定量化评价,来提高属性优选的准确率的基于向量回归机和遗传算法的地震属性优选方法。
本发明的目的可通过如下技术措施来实现:基于向量回归机和遗传算法的地震属性优选方法,该基于向量回归机和遗传算法的地震属性优选方法包括:步骤1,对测井数据和地震属性进行预处理;步骤2,提取样本,并在时间域上将样本集分组;步骤3,进行地震属性优选,得到优选的地震属性子集与储层非线性的支持向量回归机模型;步骤4,利用测试数据对建立的支持向量回归机模型进行检验,在误差满足要求时,得到最优属性组合;步骤5,输出最优属性组合。
本发明的目的还可通过如下技术措施来实现:
在步骤1中,对测井数据进行重采样,使其采样率与地震数据相同;在井位置处提取角度域共成像点道集的各种叠前属性和叠后属性,叠前属性包括截距和梯度属性,然后对叠前叠后属性进行标准化处理。
在步骤2中,将预处理后的测井数据和井位置处的地震属性组成一一对应的样本集,在时间域上将样本集分成两组:训练数据和测试数据,训练数据用于优选属性和建立支持向量回归机模型,测试数据用于对得到的支持向量回归机模型进行检验。
在步骤3中,利用向量回归机和遗传算法相结合,对训练数据进行优选,得到优选的地震属性子集与储层非线性的向量回归机模型,通过向量回归机算法实现属性优选的定量化评价,提高了属性优选的准确率。
在步骤3中,对地震属性进行二进制编码,并且随机形成初始群体,即,对属性集{att1,att2,…,attn}进行二进制编码,编码串h=h1h2…hn表示对属性集 所做的一次选择,其中hi=1表示第i个属性被选择,其中hi=0表示第i个属性未被选择,每一个二进制编码串所选择的属性的组合是一个初始群体中的个体。
在步骤3中,利用支持向量回归机和遗传算法进行交叉验证,对群体中个体的适应度进行检测和评估,从而优选属性,交叉验证是以步骤2中的训练数据为基础,将支持向量回归机模型的交叉检验均方差作为遗传算法的适应度评价标准;将训练数据的个体从时间域上分成m份,每次用其中的1份建模,其余m-1份测试,根据那1份数据利用;支持向量回归机得到测井曲线与属性之间的最优化的定量计算关系,然后计算其余m-1份数据的均方根预测误差ermsj;重复m次建模、测试之后得到每次测试的均方根预测误差,然后计算m次均方根预测误差的平均值,即得到支持向量回归机模型的交叉检验均方差;其中,交叉检验均方差rmsecv的计算公式如下:
公式1中,rmsecv表示支持向量回归机模型的交叉检验均方差,m表示训练数据个体在时间域上分了多少份,ermsj表示每份测试数据的均方根预测误差;公式2是ermsj的具体表达式,其中,n为样本数,yi为实际值,
在步骤3中,根据公式1所得结果,剔除适应度差的一半个体,对适应度好的一半个体进行繁殖,在繁殖时进行基因的交叉和变异。
在步骤3中,判断利用训练数据得来的优选属性是否满足误差要求或者达到最大繁殖的代数,如果误差比设定误差大且未达到最大繁殖代数,则继 续进行个体的繁殖和进化;如果误差小于设定误差或者达到最大繁殖代数,则进入步骤4。
在步骤4中,误差计算公式如下:
式中,e表示测试数据的误差值,yi为实际值,
在误差不满足要求时,返回到步骤3,重新进行地震属性优选与建模。
在步骤5中,保存最优属性组合及基于向量回归机模型参数,便于预测井点处甚至整个工区范围的测井数据分布。
本发明中的基于向量回归机和遗传算法的地震属性优选方法,将遗传算法与支持向量回归机相结合,融合两种技术的优点。遗传算法的优点是可以从一组属性优选出另一组属性,而不是从一个属性优选出另一个属性,而且可以全局寻找最优解;支持向量回归机的优点是具有小样本的学习能力,泛化能力强,而且可以实现对属性的定量化评价,提高属性优选的准确率。基于svr-ga的地震属性优选方法将以上优点融合,从而针对特定的储层特征参数,寻找到最能反映储层特征的敏感属性组合。
附图说明
图1为本发明的基于向量回归机和遗传算法的地震属性优选方法的一具体实施例的流程图;
图2为本发明的一具体实施例中利用svr-ga方法针对训练数据计算出来的gr预测曲线与实际曲线的对比图;
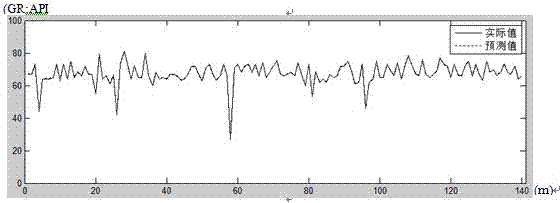
图3为本发明的一具体实施例中用测试数据对建立的svr模型进行检验,得出的gr预测曲线与实际曲线的对比图。
具体实施方式
为使本发明的上述和其他目的、特征和优点能更明显易懂,下文特举出较佳实施例,并配合附图所示,作详细说明如下。
如图1所示,图1为本发明的基于向量回归机和遗传算法的地震属性优选方法的流程图。
在步骤101中,对测井数据和地震属性进行预处理。对测井数据进行重采样,使其采样率与地震数据相同;在井位置处提取角度域共成像点道集的各种叠前属性(包括截距和梯度属性)和叠后属性,然后对叠前叠后属性进行标准化处理。
在步骤102中,进行样本提取。将整理后的测井数据和井位置处的地震属性组成一一对应的样本集,在时间域上将样本集分成两组:训练数据和测试数据,训练数据用于优选属性和建立svr模型,测试数据用于对得到的svr模型进行检验。
在步骤103中,进行地震属性优选与建模。利用ga与svr相结合,对训练数据进行优选,得到优选的地震属性子集与储层非线性svr模型。步骤103可以通过svr算法实现属性优选的定量化评价,提高了属性优选的准确率。
在一实施例中,对地震属性进行二进制编码,并且随机形成初始群体。即,对属性集{att1,att2,…,attn}进行二进制编码,编码串h=h1h2…hn表示对属性集所做的一次选择,其中hi=1表示第i个属性被选择,其中hi=0表示第i个属性未被选择,每一个二进制编码串所选择的属性的组合是一个初始群体中的个体。
利用支持向量回归机(svr)和遗传算法(ga)进行交叉验证,对群体中个体的适应度进行检测和评估,从而优选属性。这里所说的交叉验证是以步骤2所说的训练数据为基础,将svr模型的交叉检验均方差(rmsecv)(公式1)作为ga的适应度评价标准。将训练数据的个体从时间域上分成m份,每次用其中的1份建模,其余m-1份测试,根据那1份数据利用svr得到测井曲线与属性之间的最优化的定量计算关系,然后计算其余m-1份数据的均方根预测误差(ermsj)(公式2);重复m次建模、测试之后得到每次测试的均方根预测误差,然后计算m次均方根预测误差的平均值,即得到svr模型的交叉检验均方差(公式1)。
具体表达式如下:
公式1中,rmsecv表示svr模型的交叉检验均方差,m表示训练数据个体在时间域上分了多少份,ermsj表示每份测试数据的均方根预测误差;公式2是ermsj的具体表达式,其中,n为样本数,yi为实际值,
根据公式1所得结果,剔除适应度差的一半个体,对适应度好的一半个体进行繁殖,在繁殖时进行基因的交叉和变异。
判断利用训练数据得来的优选属性是否满足误差要求或者达到最大繁殖的代数,如果误差比设定误差大且未达到最大繁殖代数,则继续进行个体的繁殖和进化;如果误差小于设定误差或者达到最大繁殖代数,则进入步骤104。如图2所示,图2为本发明的一具体实施例中利用svr-ga方法针对训练数据计算出来的gr预测曲线与实际曲线的对比图。从图2可以看出,gr预测值与实际值比较吻合,交叉检验均方差只有0.9861。利用训练数据得来的优选属性满足了误差要求
在步骤104中,利用测试数据进行误差检验。如图3所示,本发明的一具体实施例中用测试数据对建立的svr模型进行检验,得出的gr预测曲线与实际曲线的对比图。从图3可以看出,在测试数据上,gr预测值与实际值差别较大,均方根预测误差是9.6243。用测试数据对步骤3得到的svr模型进行检验,与实际值对比,如果误差满足要求,得到最优属性组合,进入步骤5,如果误差不满足要求,进入步骤3,重新进行地震属性优选与建模。在步骤4中的误差计算公式如下:
式中,e表示测试数据的误差值,yi为实际值,
在步骤105中,输出最优属性组合。保存最优属性组合及svr模型参数,便于预测井点处甚至整个工区范围的测井数据分布。
表1最优属性组合表
在某工区针对gamma曲线进行属性优选的结果如上表1所示,图中叠前角度从1度到35度,属性从左到右依次为:瞬时相位、中心频率变化率、瞬时频率变化率、中心频率、瞬时频率、瞬时振幅、振幅平方。从表1可以看出,小、中、大各个角度都有属性被优选出来,而中心频率变化率、瞬时频率变化率、振幅平方这三种属性被优选出的较多,其它4种属性相对较少。流程结束。
本发明中的基于svr-ga的地震属性优选方法,融合svr和ga两种技术的优点,与以往方法相比,通过对属性的定量化评价,提高了属性优选的准确率。从而,针对特定的储层特征参数,能够寻找到最能反映储层特征的敏感属性组合。
- 还没有人留言评论。精彩留言会获得点赞!