一种文件仓库存储的智能排重方法及系统与流程
本发明涉及文件仓库管理领域,特别是涉及一种文件仓库存储的智能排重方法及系统。
背景技术:
目前,随着企事业的单位电子信息化越来越充分,互联网应用用户群体越来越大,现代计算机系统中,需要存储的电子文件也越来越多,存储需求陆续从GB、TB的规模,逐步向PB、EB迈进。虽然电子硬件的发展使得提供更多的存储容量成为可能,但基于节约成本的考虑,如何进一步充分、有效地利用这些存储,在任何时候,都是一件可带来可观社会效益和经济效益的活动。
当今时代,个人计算机中总是存储了相当数量的电子文件,而且正在越来越多。但是,无论是在单位内部,还是整个社会中,都有一个明显的事实是,不同的个体有相当大的可能持有大量相同的电子文档,比如在单位中,多人存有相同的工作文档;互联网中,多人可能存有相同的照片、音视频文件。在当前云存储时代,每个人可能因为免费存储或者主动备份的考虑,会选择将大量文件上传到同个系统中;某些单位可能处于无形资产安全管理的角度,要求员工主动上传或者使用软件强制搜集工作文件到某个系统中。
对于此类系统而言,如何应对大量使用者持有相当数量的相同文件时,如何有效使用存储的问题。简单地为每个人的每一个文件做存储拷贝,不考虑文件内容的异同,显然是一种极大的浪费,特别是对于文件大小较大的视频文件、压缩文件,不消除冗余重复存储,对于企业而言,可能带来巨大的成本压力。
应用MD5值来指代一个文件,以此分辨多个文件是否实质上是同一个文件,不失为一种可选方案,其运行效率较高,实施起来对系统运行造成的性能开销较小(最准确的方法是将文件传输到存储系统中,和已有文件逐个字节比对,但如此性能耗费巨大)。
现有方案通常是通过MD5摘要算法计算一个待进入系统存储文件的MD5哈希值,进而和已经在系统中已经存储的其他文件的MD5值进行比对,一旦相同就认为是同个文件,从而省略将其存到文件仓库系统的动作,以节省文件仓库存储空间。相当一部分网盘的文件秒传技术通常也是用类似的技术来大幅度提升传输体验。
虽然通过MD5哈希值对比来判断文件的异同,运行效率是比较理想的,但是通常使用的MD5是一个32个字节(256位位长)的字符串,其状态取值空间非常庞大,但是仍然是有限取值状态空间的。在2004年8月17日的美国加州圣巴巴拉召开的国际密码学会议(Crypto’2004)上来自山东大学的王小云教授做了破译MD5、HAVAL-128、MD4和RIPEMD算法的报告。MD5和SHA-1都属于散列算法,从设计原理来讲,就有产生碰撞的可能。这意味着不同的文件可能拥有相同的MD5值,虽然概率非常非常低。
当不同的文件拥有相同MD5值,使用现有技术可能误将一个实质内容和存储系统中任一文件不相同的文件误判为存储系统中已经存在的文件,从而导致误判为无需存储,数据文件丢失,概率极低,但有些重要文件的丢失仍然难以承受。
有鉴于此,本发明人专门设计了一种文件仓库存储的智能排重方法及系统,本案由此产生。
技术实现要素:
本发明的目的在于提供一种文件仓库存储的智能排重方法及系统,以进一步降低存储文件排重的误判率。
为了实现上述目的,本发明采用的技术方案如下:
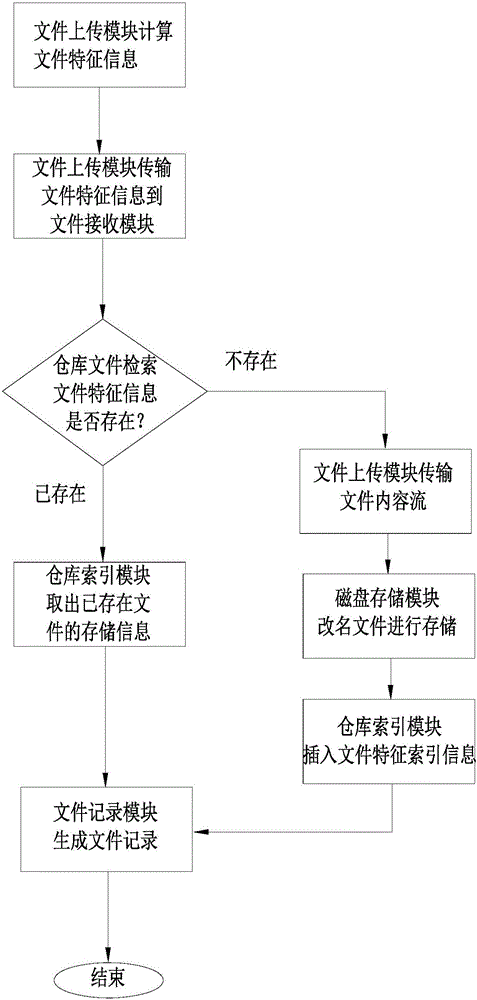
一种文件仓库存储的智能排重方法,包括以下步骤:
S01:计算待存储文件的MD5值以及该待存储文件的分段MD5值;
S02:将该待存储文件的MD5值、大小以及分段MD5值同时进行上传;
S03:接收到上述三部分信息后进行索引检索,判断相同的文件是否存在,若不存在则进入步骤S04,若存在则进入步骤S05;
S04:返回文件不存在的应达信息,并将该待存储文件的内容流上传,在接收到完整的文件后对其进行存储,并插入新的索引记录,进入步骤S06;
S05:返回文件存在的应达信息,并取出该待存储文件的文件名;
S06:插入文件记录,将该待存储文件的原始文件信息和存储时对应的文件名进行关联,以供后续调取原始文件。
所述步骤S01中,对待存储文件进行N等份,N为正整数,且N≥2,对于大小不足N的倍数的待存储文件,将大小补足为N的倍数再进行N等份,待N等份后,文件尾部的某些片段数据不足的按实际数据进行计算,最终得到N个分段MD5值。
所述步骤S03中,索引检索用自定义的哈希检索或平衡查找树的方式实现。
所述步骤S04中,待存储文件进行存储时,将文件名修改为[file_md5]_m的形式,m代表[file_md5]这个MD5串下对应编号为m的文件。
一种文件仓库存储的智能排重方法的智能排重系统,包括:
一文件上传模块,用于计算待存储文件的各种MD5值,并执行待存储文件到服务端的传输;
一文件接收模块,用于接收文件上传模块上传的文件内容以及文件上传模块事先计算的各种MD5值,保存文件记录,并执行文件智能排重判断;
一仓库索引模块,用于记录各个不相同文件的复数个MD5特征信息,以供文件接收模块检索携带指定MD5特征信息的文件和判断该文件在文件仓库中是否已经存在,引用计数是多少;
一文件记录模块,用于记录上传文件的原始记录信息,同时关联记录文件最终在磁盘存储模块总存储的文件目录和名称;
一磁盘存储模块,用于文件内容的最终实际存储;
所述文件上传模块连接文件接收模块,所述文件接收模块分别连接仓库索引模块、文件记录模块和磁盘存储模块。
采用上述方案后,本发明具有以下几个优点:
一、本发明巧妙地应用了文件分片计算MD5和完整文件MD5串,共同构成文件的唯一性特征,更好地利用了MD5的抗修改特性,使不同文件在存储时因MD5碰撞造成丢失文件的概率降到最低,仅仅成为理论上的可能,在实际应用中应不可能发生;
二、本发明在磁盘存储模块的基础上,提供了一个仓库索引模块,用于提升相同文件判断的性能,并且可对同一份文件附件类似引用计数一类扩展属性信息;
三、本发明的磁盘存储模块应用文件名分割字符串,该计算方法简单而直接,对大量文件的存储形成目录嵌套,以限制单个目录下的文件数量,有效地保障了文件定位打开的性能要求。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明原理图;
图2是本发明流程简要示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1和图2所示,本发明提供一种文件仓库存储的智能排重方法,包括以下步骤:
S01:计算待存储文件的MD5值以及该待存储文件的分段MD5值;
S02:将该待存储文件的MD5值、大小以及分段MD5值同时进行上传;
S03:接收到上述三部分信息后进行索引检索,判断相同的文件是否存在,若不存在则进入步骤S04,若存在则进入步骤S05;
S04:返回文件不存在的应达信息,并将该待存储文件的内容流上传,在接收到完整的文件后对其进行存储,并插入新的索引记录,进入步骤S06;
S05:返回文件存在的应达信息,并取出该待存储文件的文件名;
S06:插入文件记录,将该待存储文件的原始文件信息和存储时对应的文件名进行关联,以供后续调取原始文件。
特殊情况下,两个文件的MD5值会有极低的可能发生碰撞,但根据MD5算法的抗修改性(对原数据进行任何改动,哪怕只修改1个字节,所得到的MD5值都有很大区别),本发明认为,如果两个文件内容确实有部分不相同,则虽然整个文件的MD5偶尔发生碰撞,但必定在两个文件中可以找到一段相同的位置区域(数据开始和结束的文件偏移地址相同),对该区域的数据进行MD5计算的结果是不同的。
为了便于实施,本发明将考虑对文件进行N等份(N为正整数,且N≥2),对于大小不足N的倍数的待存储文件,将大小补足为N的倍数再进行N等份,待N等份后,文件尾部的某些片段数据不足的按实际数据进行计算(特别的是某些片段的数据量为0,就按0长度字节流进行MD5计算),最终得到N个分段MD5值。
在本实施例中,当文件仅有1个字节时,N等份的结果是,第一个片段仅有1个字节,后续N-1个片段都是空片段,但是0个字节的文件实际上也可以计算得到一个特定的MD5值。因此,不影响各片段的MD5计算。
其中,上述步骤S03中,索引检索所使用的索引信息,主要包含:文件完整MD5值[file_md5]、文件大小[file_size]、文件N等份后各分段MD5值[seg1_md5]、[seg2_md5]、[segN_md5]。此索引检索可用自定义的哈希检索或平衡查找树的方式实现,一个简单的实现方式是,基于关系数据库实现,将上述文件特征信息(file_md5,file_size,seg1_md5,seg2_md5,......segN_md5)定义为一个数据表的多个列,并基于这些列创建联合索引,即可通过select语句执行快速检索。
进一步地,所述步骤S04中,待存储文件进行存储时,将文件名修改为[file_md5]_m的形式,m代表[file_md5]这个MD5串下对应编号为m的文件。文件名[file_md5]_m中的m的生成规则是:索引检索时的文件md5同样为[file_md5]的文件已经存在的个数,在此基础上增加1,得到m值。
当存储形如[file_md5]_m这样文件名的文件时,可依次将前8个字符中的每两个字符,作为一层目录的名称创建子目录(最终依次创建4层子目录),以避免因单个目录中存储过多的文件而降低磁盘定位、打开文件的性能。
待完成存储后,在插入新的索引记录(file_md5,file_size,seg1_md5,seg2_md5,....segN_md5,[file_md5]_m,refcount),将最终存储的文件名和文件特征索引信息相关联,并随同生成文件的索引计数refcount。
文件的索引计数refcount,代表欲上传的refcount个原始文件,实际上对应磁盘存储系统中的同一个文件。索引计数,通常可用于删除的场景。
本发明基于MD5这一公知技术,创造性地应用文件等分计算分片MD5的方法,有效利用了MD5算法的抗修改特性,能更大程度地分辨文件的不同。这一点相比仅适用MD5和文件大小描述文件的唯一性特征,更加可靠,更能抵抗MD5的碰撞问题。同时,由于只采用MD5算法,因此,有利于在文件内容流逐步读入内存缓存的过程中,一次性计算整个文件和各个分片数据段的MD5。
本发明还提供一种文件仓库存储的智能排重方法的智能排重系统,包括:
一文件上传模块,用于计算待存储文件的各种MD5值,并执行待存储文件到服务端的传输;
一文件接收模块,用于接收文件上传模块上传的文件内容以及文件上传模块事先计算的各种MD5值,保存文件记录,并执行文件智能排重判断;
一仓库索引模块,用于记录各个不相同文件的复数个MD5特征信息,以供文件接收模块检索携带指定MD5特征信息的文件和判断该文件在文件仓库中是否已经存在以及引用计数是多少;
一文件记录模块,用于记录上传文件的原始记录信息,如上传文件的原始文件名和文件所有人,同时关联记录文件最终在磁盘存储模块中如何存放的信息-----简单指文件最终在磁盘存储模块总存储的文件目录和名称;
一磁盘存储模块,用于文件内容的最终实际存储,原始文件在最终存入时,文件名将被转换,统一为文件MD5值结合当前同一个MD5值下自1开始逐个递增的数字编号形成的字符串,形如
“1a2b3c4d5e6f77889911223344556677_1”;
所述文件上传模块连接文件接收模块,所述文件接收模块分别连接仓库索引模块、文件记录模块和磁盘存储模块。
本发明具有以下几个优点:
一、本发明巧妙地应用了文件分片计算MD5和完整文件MD5串,共同构成文件的唯一性特征,更好地利用了MD5的抗修改特性,使不同文件在存储时因MD5碰撞造成丢失文件的概率降到最低,仅仅成为理论上的可能,在实际应用中应不可能发生;
二、本发明在磁盘存储模块的基础上,提供了一个仓库索引模块,用于提升相同文件判断的性能,并且可对同一份文件附件类似引用计数一类扩展属性信息;
三、本发明的磁盘存储模块应用文件名分割字符串,该计算方法简单而直接,对大量文件的存储形成目录嵌套,以限制单个目录下的文件数量,有效地保障了文件定位打开的性能要求。
上述说明示出并描述了本发明的优选实施例,如前所述,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!