基于变分推断和张量神经网络的知识库补全方法与流程
技术特征:
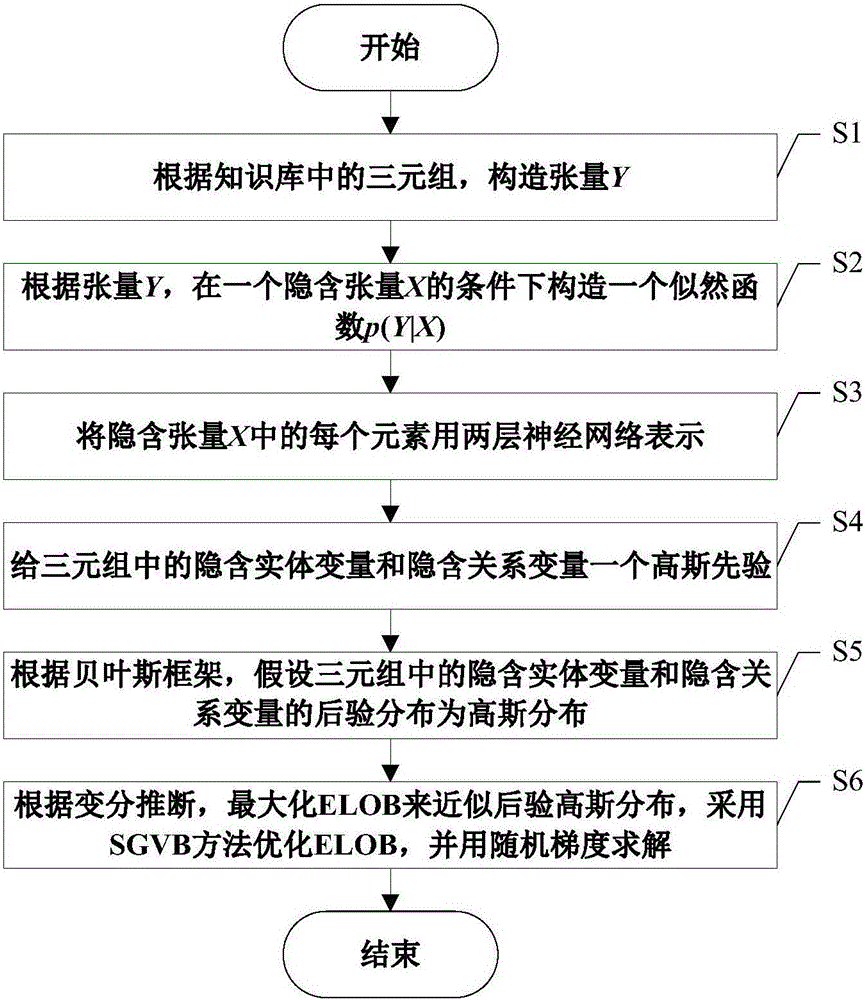
1.基于变分推断和张量神经网络的知识库补全方法,其特征在于,包括以下步骤:
S1、根据知识库中的三元组(ei,ej,rk),构造张量Y;
S2、根据张量Y,在一个隐含张量X的条件下构造一个似然函数p(Y|X);
S3、将隐含张量X中的每个元素xijk用两层神经网络表示;
S4、给三元组(ei,ej,rk)中的隐含实体变量和隐含关系变量一个高斯先验;
S5、根据贝叶斯框架,假设三元组(ei,ej,rk)中的隐含实体变量和隐含关系变量的后验分布为高斯分布;
S6、根据变分推断,最大化ELOB来近似后验高斯分布,采用SGVB方法优化ELOB,并用随机梯度求解。
2.根据权利要求1所述的基于变分推断和张量神经网络的知识库补全方法,其特征在于,所述步骤S1具体为:
假设知识库中的实体个数为N,关系个数为M,构造的张量Y∈RN×N×M,RN×N×M为维数是N×N×M的三维实数空间;若知识库中三元组(ei,ej,rk)存在,则张量Y的各维度上的下标对应的元素yijk为1,否则yijk为0。
3.根据权利要求2所述的基于变分推断和张量神经网络的知识库补全方法,其特征在于,所述步骤S2具体为:
根据张量Y,在一个隐含张量X的条件下构造一个似然函数p(Y|X):
其中Ber(yijk|σ(xijk;α))是伯努利分布,它的均值是σ(xijk;α),而σ(xijk;α)是sigmoid函数,具体形式为Iijk是一个指示变量,三元组(ei,ej,rk)在训练数据中存在的话,Iijk值为1,否则Iijk值为0。
4.根据权利要求3所述的基于变分推断和张量神经网络的知识库补全方法,其特征在于,所述步骤S3具体为:
将隐含张量X中的每个元素xijk用两层神经网络表示,具体表示为:
xijk=wThijk+b0 (2)
其中w为权重向量,b0表示一个线性偏差;ei,ej,rk∈Rd×1,b∈RK×1,w∈RK×d,W1,W2,W3∈RK×d,K为关系用向量表示之后的维度,d为实体用向量表示之后的维度;
是神经网络表示中的权重和偏差;f(·)是激活函数。
5.根据权利要求4所述的基于变分推断和张量神经网络的知识库补全方法,其特征在于,所述步骤S4具体为:
三元组(ei,ej,rk)中每个隐含实体变量和每个隐含关系变量都有先验知识,假设隐含实体变量和隐含关系变量均为高斯分布,具体形式如下:
其中,p(·)为先验的概率密度函数,N(·)为高斯分布的概率密度函数;μi,λi分别表示ei的先验概率密度函数的参数,其值分别为μE,μk,λk分别表示rk的先验概率密度函数的参数,其值分别为μR,
分别表示高斯分布的协方差矩阵。
6.根据权利要求5所述的基于变分推断和张量神经网络的知识库补全方法,其特征在于,所述步骤S5具体为:
根据贝叶斯框架,三元组(ei,ej,rk)中每个隐含实体变量和每个隐含关系变量的后验分布服从高斯分布,具体形式如下:
其中,q(·)为后验的概率密度函数,N(·)为高斯分布的概率密度函数;分别表示ei的后验概率密度函数的参数,
分别表示rk的后验概率密度函数的参数;
分别表示高斯分布的协方差矩阵。
7.根据权利要求6所述的基于变分推断和张量神经网络的知识库补全方法,其特征在于,所述步骤S6具体为:
根据变分推断,近似后验高斯分布的时候需要最大化下界ELOB,表示为:
logp(xi|θ)≥L(q(z|xi,φ),θ) (7)
其中xi代表的是第i个数据,L(·)代表的是最大化下界ELOB函数,θ为ELOB的参数,z表示隐含变量,φ为z后验概率密度函数的参数;
采用SGVB方法将ELOB第二项期望项进行简化,引入一个可微的转换和噪声ε,形式如下:z=gφ(ε),ε~p(ε),则公式(8)可重新表示为:
其中z(i,l)=gφ(ε),ε~p(ε);假设z=gφ(ε)=μ+diag(λ-1/2)ε,下界ELOB形式变为:
其中分别表示ej的后验概率密度函数的参数,
μE,μR值为0,λE,λR设定为I;
采用随机梯度上升算法求解,不断更新参数Θ,Φ,直到收敛停止。
- 还没有人留言评论。精彩留言会获得点赞!