代码的崩溃定位方法及装置与流程
本发明涉及计算机技术领域,特别涉及一种代码的崩溃定位方法及装置。
背景技术:
随着应用程序的复杂性的提高,在应用程序的运行过程中,经常会存在应用程序崩溃的问题。当应用程序崩溃时,开发人员需要及时对导致崩溃的代码进行定位,以及时修复这部分代码。
目前,应用程序在崩溃后向服务器上传异常堆栈信息,该异常堆栈信息至少包括应用程序崩溃时的代码调用关系,开发人员人为地对异常堆栈信息中的代码调用关系进行分析,确定出导致崩溃的代码,再到应用程序的代码中定位该代码的位置。
由于开发人员需要先人为分析出导致崩溃的代码,再到代码中定位该代码的位置,在代码的代码内容较多时,开发人员无法快速定位出代码的位置,从而导致代码的崩溃定位的效率较低。
技术实现要素:
为了解决代码内容较多而导致代码的崩溃定位效率较低的问题,本发明实施例提供了一种代码的崩溃定位方法及装置。所述技术方案如下:
第一方面,提供了一种代码的崩溃定位方法,所述方法包括:
获取异常堆栈信息,所述异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象,所述崩溃对象是所述代码中引起崩溃的对象;
获取对所述项目的代码进行扫描得到的第一异常代码信息,所述第一异常代码信息用于指示所述项目的代码中存在编码错误的各个异常对象;
根据所述异常堆栈信息和所述第一异常代码信息,确定每个崩溃对象所关联的异常对象;
定位每个崩溃对象所关联的异常对象在所述代码中的位置。
第二方面,提供了一种代码的崩溃定位装置,所述装置包括:
堆栈信息获取模块,用于获取异常堆栈信息,所述异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象,所述崩溃对象是所述代码中引起崩溃的对象;
第一信息获取模块,用于获取对所述项目的代码进行扫描得到的第一异常代码信息,所述第一异常代码信息用于指示所述项目的代码中存在编码错误的各个异常对象;
异常对象确定模块,用于根据所述堆栈信息获取模块获取的所述异常堆栈信息和所述第一信息获取模块获取的所述第一异常代码信息,确定每个崩溃对象所关联的异常对象;
异常对象定位模块,用于定位每个崩溃对象所关联的所述异常对象确定模块确定的异常对象在所述代码中的位置。
本发明实施例提供的技术方案的有益效果是:
通过获取异常堆栈信息,该异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象;获取对项目的代码进行扫描得到的第一异常代码信息,该第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;根据异常堆栈信息和第一异常代码信息,定位每个崩溃对象所关联的异常对象在代码中的位置,这样,将崩溃对象与异常对象相关联,确定了与崩溃对象相关联的异常对象在代码中的位置,解决了代码内容较多而导致代码的崩溃定位效率较低的问题,达到了提高代码的崩溃定位效率的效果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一个实施例提供的代码的崩溃定位方法的方法流程图;
图2是本发明另一实施例提供的代码的崩溃定位方法的方法流程图;
图3是本发明一个实施例提供的代码信息获取的方法流程图;
图4是本发明一个实施例提供的项目信息配置界面;
图5是本发明一个实施例提供的异常对象确定的方法流程图;
图6是本发明一个实施例提供的服务器交互的示意图;
图7是本发明一个实施例提供的一种崩溃对象与异常对象关联的界面示意图;
图8是本发明一个实施例提供的代码的崩溃定位装置的结构框图;
图9是本发明再一实施例提供的代码的崩溃定位装置的结构框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
请参考图1,其示出了本发明一个实施例提供的代码的崩溃定位方法的方法流程图。该代码的崩溃定位方法可以应用于服务器中,该代码的崩溃定位方法包括:
步骤101,获取异常堆栈信息,异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象,崩溃对象是代码中引起崩溃的对象。
步骤102,获取对项目的代码进行扫描得到的第一异常代码信息,第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象。
步骤103,根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象。
步骤104,定位每个崩溃对象所关联的异常对象在代码中的位置。
综上所述,本发明实施例提供的代码的崩溃定位方法,通过获取异常堆栈信息,该异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象;获取对项目的代码进行扫描得到的第一异常代码信息,该第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象;定位每个崩溃对象所关联的异常对象在代码中的位置,这样,将崩溃对象与异常对象相关联,确定了与崩溃对象相关联的异常对象在代码中的位置,解决了代码内容较多而导致代码的崩溃定位效率较低的问题,达到了提高代码的崩溃定位效率的效果。
请参考图2,其示出了本发明另一实施例提供的代码的崩溃定位方法的方法流程图。该代码的崩溃定位方法可以应用于服务器中,该代码的崩溃定位方法包括:
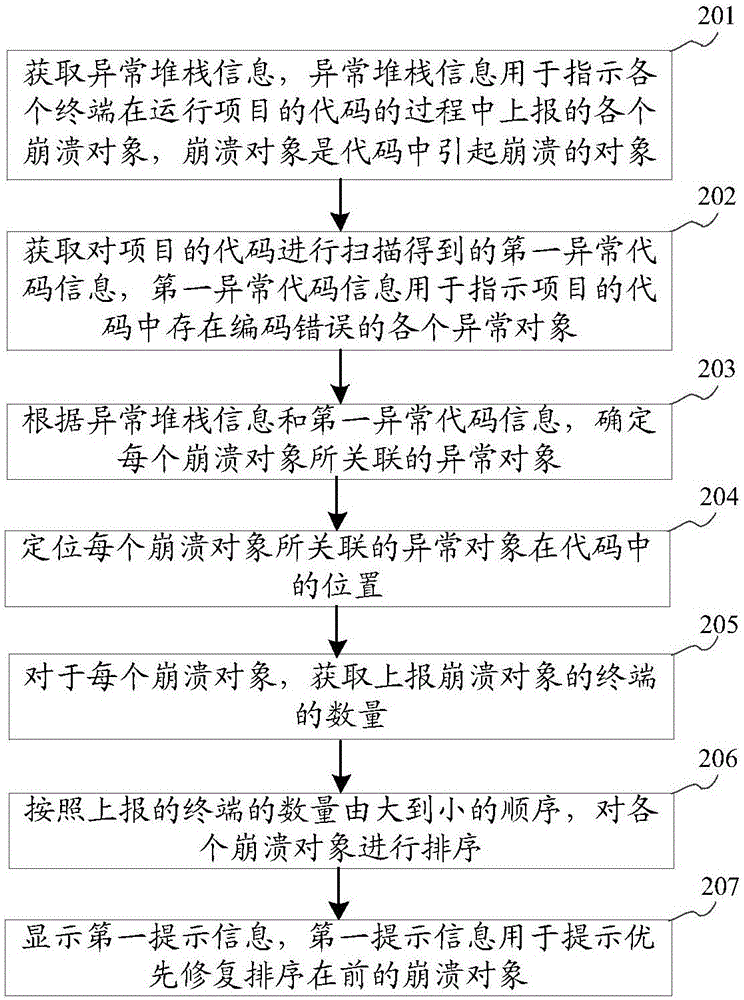
步骤201,获取异常堆栈信息,异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象,崩溃对象是代码中引起崩溃的对象。
本实施例中,项目是由代码构成的应用程序。例如,项目可以为游戏、聊天工具、购物网站等应用程序。终端可以从服务器下载项目,并在终端中运行项目的代码,从而向终端的用户提供功能。
由于项目的代码可能存在编码错误,因此,在终端运行项目的代码的过程中可能会出现崩溃的现象,本实施例中将代码中引起崩溃的对象称为崩溃对象。例如,当项目的代码中某个指针并未指向有意义的内存时,终端在通过某个函数调用该指针读取数据时会无法确定从哪里读取数据,从而引起崩溃,本实施例将该函数称为崩溃对象。
为了能使开发人员快速查找到崩溃对象,以对崩溃对象进行修复,终端还可以在代码出现崩溃现象时,记录崩溃位置处的对象以及调用该对象的对象,将这些对象的信息记录成堆栈信息,将堆栈信息上报给服务器。本实施例中,将多个终端对一个项目上报的堆栈信息称为异常堆栈信息。其中,对象可以是文件或函数,也可以是文件和函数中的至少一种和函数参数。其中,文件可以是libNativeRQD.so,函数可以是OnMoveNext(),函数参数可以是k。
在一个实例中,堆栈信息可以如下:
#00pc 00007807/data/app-lib/com.tencent.rqd.rqdtest-1/libNativeRQD.so(doACrash+55)
#01pc 0000787b/data/app-lib/com.tencent.rqd.rqdtest-1/libNativeRQD.so(Java_com_tencent_feedback_eup_jni_NativeExceptionUpload_doNativeCrashForTe st+59)
#02pc 0007bb9f/system/lib/libdvm.so(dvmPlatformInvoke+79)
#03pc 000056af<unknown>
#04pc 000d9eac/system/lib/libdvm.so(dvmCallJNIMethod(unsigned int const*,JValue*,Method const*,Thread*)+412)
#05pc 00212eb9/system/lib/libdvm.so
#06pc 00008c9f<unknown>
#07pc 00091219/system/lib/libdvm.so(dvmInterpret(Thread*,Method const*,JValue*)+201)
本实施例中,在服务器获取到异常堆栈信息后,需要对异常堆栈信息进行分析,从而确定崩溃对象。在一种实现方式中,服务器对异常堆栈信息中的所有堆栈信息进行分析,以确定崩溃对象。
由于有些崩溃是由代码中的异常对象引起的,有些崩溃不是由异常对象引起的,而只有由异常对象引起的崩溃才能由开发人员修改代码来修复,因此,为了避免对不能通过修复异常对象来修复的崩溃对象进行分析所浪费的资源,在另一种实现方式中,服务器在对异常堆栈信息进行分析之前,还可以过滤掉不是由异常对象引起的崩溃的堆栈信息。其中,异常对象是项目的代码中存在编码错误的对象。例如,当项目的代码中某个指针并未指向有意义的内存时,服务器确定调用该指针的函数编写错误,本实施例将该函数称为异常对象。
通常,由异常对象引起的崩溃有固定类型,服务器可以从异常堆栈信息中读取所有堆栈信息的崩溃类型,对崩溃类型为第一类型的堆栈信息进行保留,对崩溃类型为非第一类型的堆栈信息进行删除,得到异常堆栈信息。即,获取异常堆栈信息,包括:获取崩溃类型为第一类型的异常堆栈信息,第一类型为由异常对象引起的崩溃的类型。
其中,第一类型可以包括SIGSEGV和SIGBUS。SIGSEGV是代码中引用无效的地址时引起的崩溃的崩溃类型,SIGBUS是代码中引用非法地址时引起的崩溃的类型。
步骤202,获取对项目的代码进行扫描得到的第一异常代码信息,第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象。
本实施例中,服务器采用预设的代码扫描工具对项目的代码进行扫描,将扫描结果作为第一异常代码信息。其中,服务器可以先扫描代码,对得到的第一异常代码信息进行缓存,在获取到异常堆栈信息时再读取第一异常代码信息;也可以先获取异常堆栈信息,再扫描代码得到第一异常代码信息;还可以在扫描代码得到第一异常代码信息时获取异常堆栈信息,本实施例不作限定。
本实施例中,异常堆栈信息对应的代码和第一异常代码信息对应的代码需要相同,因此,请参考图3,获取对项目的代码进行扫描得到的第一异常代码信息,还包括:
步骤2021,读取异常堆栈信息对应的项目标识。
项目标识用于在代码扫描过程中标识项目,项目标识可以是服务器创建项目时分配的,也可以是服务器在发布项目时分配的,本实施例不作限定。其中,项目标识可以是app_id。
步骤2022,在第一关联关系中确定与项目标识对应的项目键值,第一关联关系用于记录不同的项目标识与不同的项目键值之间的对应关系。
项目键值用于在崩溃上报过程中标识项目,项目键值可以是服务器在创建项目时分配的,也可以是服务器在接收到终端上报的崩溃对象时分配的,本实施例不作限定。其中,项目键值可以是项目key。
本实施例中,用户还需要为项目标识和项目键值建立第一关联关系,以关联异常堆栈信息和第一异常代码信息。因此,在第一关联关系中确定与项目标识对应的项目键值之前,还包括:接收用户在查看项目的第一异常代码信息时触发的配置操作;显示包括项目的项目键值的配置界面;接收用户在配置界面中输入的项目标识;将项目键值和项目标识对应添加到第一关联关系中。
请参考图4,在代码扫描工具得到第一异常代码信息后,服务器显示配置与第一异常代码信息相关联的异常堆栈信息的配置界面,此时,配置界面中包括该第一异常代码信息对应的项目键值,配置界面中还包括项目标识的输入框,当用户在该输入框中输入项目标识,并触发关联控件时,服务器建立项目键值和项目标识的第一关联关系。
可选的,配置界面中还包括项目名称、语言类型、版本号、是否定时关联等信息,其中,项目名称用于描述项目,语言类型用于描述项目的代码的语言,版本号用于描述项目的版本,是否定式关联用于描述是否定时关联第一异常代码信息和异常堆栈信息。
步骤2023,确定项目键值所指示的项目的代码。
步骤2024,获取对项目的代码进行扫描得到的第一异常代码信息。
代码扫描工具对项目的代码进行扫描后,得到的每条扫描结果对应一个异常对象,且一条扫描结果包括异常对象、错误类型、行号等等。
本实施例中,在服务器获取到第一异常代码信息后,需要对第一异常代码信息进行分析,从而确定异常对象。在一种实现方式中,服务器对第一异常代码信息中的所有扫描结果进行分析,以确定异常对象。
由于有些异常对象并不会引起崩溃,且只有由异常对象引起的崩溃才能由开发人员修改代码来修复,因此,为了避免对不能引起崩溃的异常对象进行分析所浪费的资源,在另一种实现方式中,服务器在对第一异常代码进行分析之前,还可以过滤掉不会引起崩溃的异常对象的扫描结果。
通常,能够引起崩溃的异常对象有固定类型,服务器可以从第一异常代码信息中读取所有扫描结果中的错误类型,对错误类型为第二类型的扫描结果进行保留,对错误类型非第二类型的扫描结果进行删除,得到异常堆栈信息。即,获取对项目的代码进行扫描得到的第一异常代码信息,包括:对项目的代码进行扫描,从扫描结果中获取错误类型为第二类型的第一异常代码信息,第二类型是引起崩溃的异常对象的类型。
其中,第二类型与代码的编码语言相关。当编码语言是C++时,第二类型可以包括空指针和越界。空指针是指代码中指针并未指向有意义的内存,越界是指代码中就没有为该指针分配内存空间。当编码语言是C#时,第二类型可以包括溢出异常、索引范围异常和空引用异常。溢出异常是指代码中选中的上下文中所进行的算术运算、类型转换或转换操作导致溢出,索引范围异常是指代码中通过索引访问数据时,索引超出了设定的索引范围,空引用是指代码中引用的内容为空。
步骤203,根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象。
请参考图5,根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象,包括:
步骤2031,从异常堆栈信息中提取每个崩溃对象的第一标识。
第一标识用于指示崩溃对象。比如,当崩溃对象是文件中的函数时,第一标识可以是文件名和函数名,也可以是根据文件名计算出的第一哈希值和根据函数名计算出的第二哈希值,本实施例不作限定。
具体地,从异常堆栈信息中提取每个崩溃对象的第一标识,包括:读取异常堆栈信息中的每条堆栈信息,每条堆栈信息包括对应的一个堆栈中记录的n层信息,且堆栈中记录的第0层信息是崩溃位置处对象的信息,堆栈中记录的第i+1层信息是调用第i层对象的对象的信息,0≤i≤n;对于每条堆栈信息,检测堆栈信息中第j层信息中的对象是否是崩溃对象,当第j层信息中的对象是崩溃对象时,读取第j层信息中的对象的第一标识;当第j层信息中的对象不是崩溃对象时,将j更新为j+1,继续执行检测堆栈信息中第j层信息中的对象是否是崩溃对象的步骤,0≤j≤n。
以步骤201中的堆栈信息为例,#00记录的是第0层信息,#01记录的是第1层信息,依次类推,#07记录的是第7层信息。其中,示例中,一层信息可以包括终端类型、内存地址、文件以及函数在文件中的偏移量。当然,每层信息还可以包括函数、函数参数等其他信息,本实施例不作限定。
堆栈信息中记录的第i+1层对象与第i层对象之间存在调用关系,即,第i+1层信息是调用第i层对象的对象的信息。
例如,堆栈信息记录了4层信息,分别为第0层信息、第1层信息、第2层信息和第3层信息。第1层信息是调用了第0层对象的对象的信息,第2层信息是调用了第1层对象的对象的信息,第3层信息是调用了第2层对象的对象的信息。
在服务器对堆栈信息进行分析时,先检测第0层信息中的对象是否为崩溃对象,若第0层信息中的对象是崩溃对象,则读取该崩溃对象的第一标识,结束分析流程;若第0层信息中的对象不是崩溃对象,则检测第1层信息中的对象是否为崩溃对象,若第1层信息中的对象是崩溃对象,则读取该崩溃对象的第一标识,结束分析流程;若第1层信息中的对象不是崩溃对象,则检测第2层信息中的对象是否为崩溃对象,依此类推,直到检测到崩溃对象为止。
其中,在检测对象是否是崩溃对象时,服务器可以检测对象是否是能获取到具体代码的对象;当对象是能够获取到具体代码的对象时,确定该对象是崩溃对象;当对象不是能获取到具体代码的函数,例如,对象是函数库中的函数时,确定该对象不是崩溃对象。
在实际实现过程中,由于i的数值越大,第i层对象调用的对象越多,此时,分析第i层对象崩溃的原因越复杂,因此,通常,服务器只分析第0层对象和第1层对象。
步骤2032,从第一异常代码信息中提取每个异常对象的第二标识。
第二标识用于指示异常对象。比如,当异常对象是文件中的函数时,第二标识可以是文件名和函数名,也可以是根据文件名计算出的第一哈希值和根据函数名计算出的第二哈希值,本实施例不作限定。
步骤2033,当存在相匹配的第一标识和第二标识时,将第二标识所指示的异常对象确定为第一标识所指示的崩溃对象所关联的异常对象。
第一标识与第二标识匹配是指第一标识与第二标识相同,或者,第一标识的哈希值与第二标识的哈希值相同。例如,第一标识是OnMoveNext(),第二标识是OnMoveNext(),则服务器确定第一标识和第二标识相匹配。
本实施例以第一标识和第二标识均包括文件名和函数名对匹配第一标识和第二标识的过程进行说明,服务器可以先检测第一标识和第二标识中的文件名是否相同,在文件名相同时,再检测第一标识和第二标识中的函数名是否相同,在函数名相同时,确定第一标识和第二标识相匹配。
步骤204,定位每个崩溃对象所关联的异常对象在代码中的位置。
由于异常对象在代码中的行号是确定的,因此,在确定出崩溃对象所关联的异常对象后,开发人员可以直接定位到该行号所指示的代码,对该代码进行修改,以修复崩溃对象。
由于服务器可能定位出多个崩溃对象所关联的异常对象在代码中的位置,且服务器可能是按照定位顺序提示开发人员修复崩溃对象的,此时,开发人员依次对崩溃对象进行修复。由于有些崩溃对象影响的用户数多,有些崩溃对象影响的用户数少,因此,服务器还可以根据崩溃对象所影响的用户数对崩溃对象进行排序,以提示开发人员优先修复影响用户数多的崩溃对象,以保证大多数用户能正常使用项目,此时执行步骤205。
步骤205,对于每个崩溃对象,获取上报崩溃对象的终端的数量。
其中,上报崩溃对象的终端的数量即为崩溃对象影响的用户数。
步骤206,按照上报的终端的数量由大到小的顺序,对各个崩溃对象进行排序。
步骤207,显示第一提示信息,第一提示信息用于提示优先修复排序在前的崩溃对象。
在一种实现方式中,服务器可以从排序的数量中选择排序在前n位的数量,并生成用于指示每种数量对应的崩溃对象的第一提示信息。其中,n为正整数,例如,n为10、50、100等等。
例如,上报崩溃对象1的终端的数量为500,上报崩溃对象2的终端的数量为1500,上报崩溃对象3的终端的数量为2500,上报崩溃对象4的终端的数量为2000,且n为2,则服务器生成用于指示崩溃对象3和崩溃对象4的第一提示信息。
本实施例中,服务器还可以根据崩溃对象所关联的异常对象,对项目中可能存在的崩溃对象进行预测,以减少崩溃的发生概率,提高代码质量。此时,在定位每个崩溃对象所关联的异常对象在代码中的位置之后,还包括:获取对其他项目的代码进行扫描得到的第二异常代码信息,第二异常代码信息用于指示其他项目的代码中存在编码错误的各个异常对象;根据项目中确定的崩溃对象与异常对象的第二关联关系,预测各个异常对象中将导致崩溃的异常对象;显示第二提示信息,第二提示信息用于提示修复预测得到的异常对象。
例如,项目1中崩溃对象1与异常对象1关联,此时,第二关联关系中包括崩溃对象1与异常对象1的关联关系,则在项目2中确定出异常对象1后,服务器可以根据第二关联关系预测出异常对象1可能会引起崩溃,且崩溃的对象可能是崩溃对象1,此时,服务器提示开发人员对崩溃对象1进行修复。
当然,服务器还可以提取引起崩溃的各个异常对象之间的共性,当从其他项目中扫描出具有共性的异常对象时,再预测该具有共性的异常对象关联的崩溃对象,以提高预测的准确性。
本实施例中,请参考图6,服务器可以包括bugly服务器,TSC匹配服务器,TSC扫描服务器、TSC网页服务器,且TSC匹配服务器分别与bugly服务器、TSC扫描服务器、TSC网页服务器相连。其中,bugly服务器是bugly平台的后台服务器,bugly平台是接收终端上报的异常堆栈信息的平台,TSC扫描服务器是TSC扫描平台的后台服务器,TSC扫描平台是采用TscanCode(代码扫描工具)对项目的代码进行扫描得到第一异常代码信息的平台,TSC匹配服务器是对异常对象信息和第一异常代码信息进行匹配的服务器,TSC网页服务器是用于展示崩溃对象和异常对象的关联的服务器。
请参考图7,其示出了崩溃对象与异常对象关联的一种示意图,其中,区域701内显示的是崩溃对象,区域702内显示的是崩溃对象关联的异常对象。
综上所述,本发明实施例提供的代码的崩溃定位方法,通过获取异常堆栈信息,该异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象;获取对项目的代码进行扫描得到的第一异常代码信息,该第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象;定位每个崩溃对象所关联的异常对象在代码中的位置,这样,将崩溃对象与异常对象相关联,确定了与崩溃对象相关联的异常对象在代码中的位置,解决了代码内容较多而导致代码的崩溃定位效率较低的问题,达到了提高代码的崩溃定位效率的效果。
通过获取上报崩溃对象的终端的数量;按照上报的终端的数量由大到小的顺序,对各个崩溃对象进行排序;显示第一提示信息,第一提示信息用于提示优先修复排序在前的崩溃对象,可以提示开发人员优先修复上报的终端数量大的崩溃对象,以保证大多数用户能正常使用项目。
通过获取对其他项目的代码进行扫描得到的第二异常代码信息;根据项目中确定的崩溃对象与异常对象的第二关联关系,预测各个异常对象中将导致崩溃的异常对象;显示第二提示信息,第二提示信息用于提示修复预测得到的异常对象,这样,可以根据扫描出的异常对象预测可能会存在的崩溃对象,以提示开发人员提前修复该崩溃对象,避免了崩溃的发生,以提高代码质量。
请参考图8,其示出了本发明一个实施例提供的代码的崩溃定位装置的结构框图。该代码的崩溃定位装置可以应用于服务器中,该代码的崩溃定位装置,包括:
堆栈信息获取模块810,用于获取异常堆栈信息,异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象,崩溃对象是代码中引起崩溃的对象;
第一信息获取模块820,用于获取对项目的代码进行扫描得到的第一异常代码信息,第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;
异常对象确定模块830,用于根据堆栈信息获取模块810获取的异常堆栈信息和第一信息获取模块820获取的第一异常代码信息,确定每个崩溃对象所关联的异常对象;
异常对象定位模块840,用于定位每个崩溃对象所关联的异常对象确定模块830确定的异常对象在代码中的位置。
综上所述,本发明实施例提供的代码的崩溃定位装置,通过获取异常堆栈信息,该异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象;获取对项目的代码进行扫描得到的第一异常代码信息,该第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象;定位每个崩溃对象所关联的异常对象在代码中的位置,这样,将崩溃对象与异常对象相关联,确定了与崩溃对象相关联的异常对象在代码中的位置,解决了代码内容较多而导致代码的崩溃定位效率较低的问题,达到了提高代码的崩溃定位效率的效果。
请参考图9,其示出了本发明再一实施例提供的代码的崩溃定位装置的结构框图。该代码的崩溃定位装置可以应用于服务器中,该代码的崩溃定位装置,包括:
堆栈信息获取模块910,用于获取异常堆栈信息,异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象,崩溃对象是代码中引起崩溃的对象;
第一信息获取模块920,用于获取对项目的代码进行扫描得到的第一异常代码信息,第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;
异常对象确定模块930,用于根据堆栈信息获取模块910获取的异常堆栈信息和第一信息获取模块920获取的第一异常代码信息,确定每个崩溃对象所关联的异常对象;
异常对象定位模块940,用于定位每个崩溃对象所关联的异常对象确定模块确定的异常对象在代码中的位置。
可选的,异常对象确定模块930,包括:
第一标识提取单元931,用于从异常堆栈信息中提取每个崩溃对象的第一标识;
第二标识提取单元932,用于从第一异常代码信息中提取每个异常对象的第二标识;
异常对象确定单元933,用于当存在相匹配的第一标识提取单元931提取的第一标识和第二标识提取单元932提取的第二标识时,将第二标识所指示的异常对象确定为第一标识所指示的崩溃对象所关联的异常对象。
可选的,第一标识提取单元931,还用于:
读取异常堆栈信息中的每条堆栈信息,每条堆栈信息包括对应的一个堆栈中记录的n层信息,且堆栈中记录的第0层信息是崩溃位置处对象的信息,堆栈中记录的第i+1层信息是调用第i层对象的对象的信息,0≤i≤n;
对于每条堆栈信息,检测堆栈信息中第j层信息中的对象是否是崩溃对象,当第j层信息中的对象是崩溃对象时,读取第j层信息中的对象的第一标识;当第j层信息中的对象不是崩溃对象时,将j更新为j+1,继续执行检测堆栈信息中第j层信息中的对象是否是崩溃对象的步骤,0≤j≤n。
可选的,堆栈信息获取模块910,还用于获取崩溃类型为第一类型的异常堆栈信息,第一类型为由异常对象引起的崩溃的类型;
第一信息获取模块920,还用于对项目的代码进行扫描,从扫描结果中获取错误类型为第二类型的第一异常代码信息,第二类型是引起崩溃的异常对象的类型。
可选的,装置还包括:
上报数量获取模块950,用于对于每个崩溃对象,获取上报崩溃对象的终端的数量;
崩溃对象排序模块960,用于按照上报数量获取模块获取的上报的终端的数量由大到小的顺序,对各个崩溃对象进行排序;
第一提示显示模块970,用于显示第一提示信息,第一提示信息用于提示优先修复排序在前的崩溃对象。
可选的,第一信息获取模块920,包括:
项目键值读取单元921,用于读取异常堆栈信息对应的项目键值;
项目标识确定单元922,用于在第一关联关系中确定与项目键值读取单元921读取的项目键值对应的项目标识,第一关联关系用于记录不同的项目键值与不同的项目标识之间的对应关系;
项目代码确定单元923,用于确定项目标识确定单元922确定的项目标识所指示的项目的代码;
第一信息获取单元924,用于获取对项目代码确定单元923确定的项目的代码进行扫描得到的第一异常代码信息。
可选的,第一信息获取模块920,还包括:
配置操作接收单元925,用于接收用户在查看项目的异常堆栈信息时触发的配置操作;
配置界面显示单元926,用于显示包括项目的项目键值的配置界面;
项目标识接收单元927,用于接收用户在配置界面中输入的项目标识;
关联关系添加单元928,用于将配置界面显示模块配置的项目键值和项目标识接收模块接收的项目标识对应添加到第一关联关系中。
可选的,装置还包括:
第二信息获取模块980,用于获取对其他项目的代码进行扫描得到的第二异常代码信息,第二异常代码信息用于指示其他项目的代码中存在编码错误的各个异常对象;
异常对象预测模块990,用于根据项目中确定的崩溃对象与异常对象的第二关联关系,预测各个异常对象中将导致崩溃的异常对象;
第二提示显示模块991,用于显示第二提示信息,第二提示信息用于提示修复预测得到的异常对象。
综上所述,本发明实施例提供的代码的崩溃定位装置,通过获取异常堆栈信息,该异常堆栈信息用于指示各个终端在运行项目的代码的过程中上报的各个崩溃对象;获取对项目的代码进行扫描得到的第一异常代码信息,该第一异常代码信息用于指示项目的代码中存在编码错误的各个异常对象;根据异常堆栈信息和第一异常代码信息,确定每个崩溃对象所关联的异常对象;定位每个崩溃对象所关联的异常对象在代码中的位置,这样,将崩溃对象与异常对象相关联,确定了与崩溃对象相关联的异常对象在代码中的位置,解决了代码内容较多而导致代码的崩溃定位效率较低的问题,达到了提高代码的崩溃定位效率的效果。
通过获取上报崩溃对象的终端的数量;按照上报的终端的数量由大到小的顺序,对各个崩溃对象进行排序;显示第一提示信息,第一提示信息用于提示优先修复排序在前的崩溃对象,可以提示开发人员优先修复上报的终端数量大的崩溃对象,以保证大多数用户能正常使用项目。
通过获取对其他项目的代码进行扫描得到的第二异常代码信息;根据项目中确定的崩溃对象与异常对象的第二关联关系,预测各个异常对象中将导致崩溃的异常对象;显示第二提示信息,第二提示信息用于提示修复预测得到的异常对象,这样,可以根据扫描出的异常对象预测可能会存在的崩溃对象,以提示开发人员提前修复该崩溃对象,避免了崩溃的发生,以提高代码质量。
需要说明的是:上述实施例提供的代码的崩溃定位装置在进行代码的崩溃定位时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将代码的崩溃定位装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的代码的崩溃定位装置与代码的崩溃定位方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!