盲式文字输入方法、盲式文字输入装置和计算装置与流程
本发明总体地涉及文字输入技术,更具体地涉及盲式(eye-free)文字输入技术。
背景技术:
智能电视、智能电话、个人数字助理等计算设备在日常生活中广泛使用。这样的计算设备的输入通常是通过在可触摸屏幕或者面板上显示键盘布局(后文中称之为软键盘,相对于传统的台式机的物理键盘而言),检测用户对键盘的点击来进行输入的。已有的文字输入(包括命令输入)通常需要用户眼睛盯着操作的软键盘。这在很多时候是不方便的。例如人们在走路、慢跑、聊天、看电视或者开车时,眼睛通常需要注意别处,盯着键盘可能是不方便或者危险的。
以智能电视为例,目前智能电视不再只具有简单的电视功能,而是还具有许多应用程序的功能,例如搜索、购物等等。但是,目前智能电视的文字输入非常不便,这是由于遥控器作为文字输入设备,尺寸非常小,缺少有效的文字输入手段,输入速度非常慢。
传统的盲式文本输入在物理键盘上进行的,诸如非专利文献1中所介绍的QWERTY和Braille输入。以多个手指输入,用户的输入速度可达60-100WPM(word per minute,每分钟单词数),如文献2和3所介绍的。
但是,传统技术在触摸屏上的盲式输入准确度很低,实验研究表明,当目标尺寸为1.25cm时,在可触摸移动电话上的绝对位置控制精度下降至85%,参见文献4。
传统的盲式文字输入方法有手势输入。用户可以做出单笔划手势以输入字符;Escape-Keyboard键盘允许用户以弹击手势输入字符;针对盲人的No-look Notes要求两个手指以及语音反馈,已报道的输入速度为1.67到14.7wpm,请参见文献5、6、7、8。
发明人研究分析发现,盲式文本输入算法面对的最大挑战在于来自各种因素的输入误差或噪声,例如设备、手指宽大、手姿态、软键盘大小等等。针对此的措施是利用语言模型,计算对于给定输入信号后验概率最大的单词。如文献9那样。不过,先前的研究大部分假定在各个按键点击动作纸件没有相关性,用户独立地进行每个按键点击。
在文献10中,提出了相对键盘输入技术,其中基于所有按键点击落点距离第一个点击落点的偏移来预测输入的单词。评估显示,如果噪声很小,对于仿真数据,输入的准确率较高;但是,对于从真实用户收集的数据,准确率降至0.456。
可见,存在对于输入速度较快、准确率较高的盲式文字输入技术的迫切需求。
文献:
1.Clawson,J.,Lyons,K.,Starner,T.,&Clarkson,E.(2005,October).The impacts of limited visual feedback on mobile text entry for the twiddler and mini-qwerty keyboards.In Wearable Computers,2005.Proceedings.Ninth IEEE International Symposium.
2.Findlater,L.,&Wobbrock,J.(2012,May).Personalized input:improving ten-finger touchscreen typing through automatic adaptation.In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems(pp.815-824).ACM.
3.Findlater,L.,Wobbrock,J.O.,&Wigdor,D.(2011,May).Typing on flat glass:examining ten-finger expert typing patterns on touch surfaces.InProceedings of the SIGCHI conference on Human factors in computing systems(pp.2453-2462).ACM.
4.Wang,Y.,Yu,C.,Liu,J.,&Shi,Y.(2013,August).Understanding performance of eyes-free,absolute position control on touchable mobile phones.In Proceedings of the 15th international conference on Human-computer interaction with mobile devices and services(pp.79-88).ACM.
5.Enns,N.,&MacKenzie,I.S.(1998).Touchpad-based remote control devices(pp.229-230).ACM.
6.Tinwala,H.,&MacKenzie,I.S.(2010,October).Eyes-free text entry with error correction on touchscreen mobile devices.In Proceedings of the 6th Nordic Conference on Human-Computer Interaction:Extending Boundaries(pp.511-520).ACM.
7.Banovic,N.,Yatani,K.,&Truong,K.N.(2013).Escape-keyboard:A sight-free one-handed text entry method for mobile touch-screen devices.International Journal of Mobile Human Computer Interaction(IJMHCI),5(3),42-61.
8.Bonner,M.N.,Brudvik,J.T.,Abowd,G.D.,&Edwards,W.K.(2010).No-look notes:accessible eyes-free multi-touch text entry.In Pervasive Computing(pp.409-426).Springer Berlin Heidelberg.
9.Corsten,C.,Cherek,C.,Karrer,T.,&Borchers,J.(2015,April).HaptiCase:Back-of-Device Tactile Landmarks for Eyes-Free Absolute Indirect Touch.InProceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems(pp.2171-2180).ACM.
10.Rashid,D.R.,&Smith,N.A.(2008,January).Relative keyboard input system.In Proceedings of the 13th international conference on Intelligent user interfaces(pp.397-400).ACM.
技术实现要素:
鉴于此,做出了本发明。
根据本发明的一个方面,提供了一种借助真实软键盘或虚拟软键盘的盲式文字输入方法,包括:检测用户手指在软键盘上的点击动作,获得按时间顺序排列的点击点数据序列;基于语言模型、基于点击模型以及至少部分基于相邻点击点之间的相对位置数据,对于各个候选单词,计算该点击点数据序列对应于该候选单词的概率,其中,点击模型存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布;以及
基于计算得到的概率,将所述点击点数据序列识别为相应单词。
在一个示例中,将识别出的单词显示于单词输入域。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述相邻点击点之间的相对位置数据为相邻点击点之间的位移向量。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述点击模型存储了任意两个字母按键之间点击位移向量的概率密度分布参数。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述概率密度分布为高斯分布,参数为:高斯分布中的均值和标准偏差。
在一个示例中,根据本发明实施例的盲式文字输入方法,其中,所述点击模型针对各个用户,存储所述概率密度分布参数,不同用户相关联的概率密度分布参数是不同的,以及所述计算该点击点数据序列对应于该候选单词的概率包括:确定做出点击操作的用户标识信息;基于用户标识信息,从点击模型中获得该用户相关联的概率密度分布参数;以及基于所述相关联的概率密度分布参数,来计算该点击点数据序列对应于该候选单词的概率。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述计算该点击点数据序列对应于该候选单词的概率包括:基于点击模型、基于相邻点击点之间的相对位置数据、基于时间上彼此间隔一个或多个点击的点击点之间的相对位置数据,计算该点击点数据序列对应于该候选单词的概率,其中点击模型中存储了为了计算相邻点击点之间、以及彼此间隔一个或多个点击的点击点之间表现出具体相对位置的概率而言所必需的数据信息。
在一个示例中,根据本发明实施例的盲式文字输入方法,用户输入模式为双手输入模式,所述键盘为分开的左手键盘和右手键盘,所述点击点数据序列包括已经被区分开的左手点击点数据序列和右手点击点数据序列,计算概率中,将候选单词拆成左手字母序列和右手字母序列,然后分别针对左手字母序列,来计算左手点击点数据序列对应于该左手字母序列的概率作为左手概率;以及针对右手字母序列,来计算右手点击点数据序列对应于该右手字母序列的概率作为右手概率,进而基于左手概率和右手概率,来计算所述点击点数据序列对应于该候选单词的概率;点击模型中存储了用户在用左手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,以及用右手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,
在一个示例中,根据本发明实施例的盲式文字输入方法,用户输入模式为双手输入模式,计算概率中,根据标准指法规则将候选单词拆成左手字母 序列和右手字母序列,并根据点击点和字母之间的对齐关系,将点击点序列分为左手点击点数据序列和右手点击点数据序列;然后分别针对左手字母序列,来计算左手点击点数据序列对应于该左手字母序列的概率作为左手概率;以及针对右手字母序列,来计算右手点击点数据序列对应于该右手字母序列的概率作为右手概率,进而基于左手概率和右手概率,来计算所述点击点数据序列对应于该候选单词的概率;点击模型中存储了用户在用左手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,以及用右手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入方法,如果系统能够判断输入点序列中的各点与左右手之间的对应关系,则在和候选单词做匹配时,只考虑点击点序列中各点的左右手对应关系与候选单词中各字母的左右手对应关系完全一致的候选词。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述键盘为26键全键盘或9键键盘。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述盲式文字输入装置与VR眼镜结合使用。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述相邻点击点之间的相对位置数据为相邻点击点之间的位移向量,时间上彼此间隔一个或多个点击的点击点之间的相对位置数据为所述点击点之间的位移向量,其中所述点击模型存储了为了计算相邻点击点之间、以及彼此间隔一个或多个点击的点击点之间表现出具体位移向量的概率而言所的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述计算该点击点数据序列对应于该候选单词的概率包括:基于点击模型、基于首个点击的位置数据、基于相邻点击点之间的相对位置数据,计算该点击点数据序列对应于该候选单词的概率,其中,点击模型中存储了为了计算首个点击的位置数据出现在具体位置以及相邻点击点之间表现出具体相对位置的概率而言所需的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入方法,点击点序列对应于单词w的概率p(w|I)通过下式来表征,
其中,p(w)表示单词w的先验概率,从语言模型数据库中获得, 用户实际输入I为长度为n的点击序列,表示单词w的m个字符的理想点击位置,ΔXi=Xi-Xi-1;ΔYi=Yi-Yi-1表示相邻理想点击点之间的向量,Δxi=xi-xi-1;Δyi=yi-yi-1表示相邻实际输入点之间的向量,其中点击模型中还存储了用户在用手指点击一个按键时点击点位置的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入方法,其中, 以及 表示高斯分布,其中分别表示ΔXk的均值和方差,以及 分别表示ΔYk的均值和方差。
在一个示例中,根据本发明实施例的盲式文字输入方法,其中,针对每个用户,来存储相关联的和以及所述计算该点击点数据序列对应于该候选单词的概率包括:确定做出点击操作的用户标识信息;基于用户标识信息,从点击模型中获得该用户相关联的和以及基于该用户相关联的和来计算p(Δxk|ΔXk)、p(Δyk|ΔYk)。
在一个示例中,根据本发明实施例的盲式文字输入方法,其中,对于每两个按键,基于统计的这两个按键之间的向量的平均值和方差来得到这两个按键相关联的和
在一个示例中,根据本发明实施例的盲式文字输入方法,其中基于先验数据,拟合出所述软键盘,基于拟合的软键盘中的拟合得到的两个按键之间的平均值和方差来得到这两个按键相关联的和
在一个示例中,根据本发明实施例的盲式文字输入方法,所述相邻点击点之间的相对位置数据为相邻点击点之间的时间间隔,其中所述点击模型存储了为了计算相邻点击点之间表现出具体时间间隔的概率所必需的数据信息。
在一个示例中,根据本发明实施例的盲式文字输入方法,所述基于计算得到的概率,将所述点击点数据序列识别为相应单词包括:基于计算得到的点击点数据属于确定单词的概率,显示多个单词候选;响应于用户对多个单词候选做出的选择动作,选择对应的单词候选作为单词输入。
根据本发明的另一方面,提供了一种盲式文字输入装置,包括:可触摸屏幕或面板,其上布置有真实或虚拟的软键盘;检测单元,配置为检测用户手指在软键盘上的点击动作,获得按时间顺序排列的点击点数据序列;点击模型,存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布;识别单元,配置为基于语言模型、基于点击模型以及至少部分基于相邻点击点之间的相对位置数据,对于各个候选单词,计算该点击点数据序列对应于该候选单词的概率,以及基于计算得到的概率,将所述点击点数据序列识别为相应单词。
在一个示例中,根据本发明实施例的盲式文字输入装置,还可以包括:显示单元,配置为将识别的单词显示于单词输入域。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述显示单元为VR眼镜。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述盲式文字输入装置与电视机结合使用,所述电视机的显示屏作为所述显示单元。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述用户单手操作盲式文字输入装置,以大拇指或食指来操作盲式文字输入装置;或者所述用户双手操作盲式文字输入装置,输入方式为下列之一:双手大拇指输入、双手食指输入、双手十指输入。
在一个示例中,根据本发明实施例的盲式文字输入装置,用户输入方式为双手输入模式,所述键盘为分开的左手键盘和右手键盘,所述点击点数据序列包括已经被区分开的左手点击点数据序列和右手点击点数据序列,计算概率中,将候选单词拆成左手字母序列和右手字母序列,然后分别针对左手字母序列,来计算左手点击点数据序列对应于该左手字母序列的概率作为左手概率;以及针对右手字母序列,来计算右手点击点数据序列对应于该右手字母序列的概率作为右手概率,进而基于左手概率和右手概率,来计算所述点击点数据序列对应于该候选单词的概率;点击模型中存储了用户在用左手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,以及用右手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
22、根据权利要求20的盲式文字输入装置,用户输入模式为双手输入模式,键盘不是分开的左手键盘和右手键盘,
计算概率中,根据标准指法规则将候选单词拆成左手字母序列和右手字母序列,并根据点击点和字母之间的对齐关系,将点击点序列分为左手点击点数据序列和右手点击点数据序列;然后分别针对左手字母序列,来计算左手点击点数据序列对应于该左手字母序列的概率作为左手概率;以及针对右手字母序列,来计算右手点击点数据序列对应于该右手字母序列的概率作为右手概率,进而基于左手概率和右手概率,来计算所述点击点数据序列对应于该候选单词的概率;点击模型中存储了用户在用左手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,以及用右手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入装置,如果系统能够判断输入点序列中的各点与左右手之间的对应关系,则在和候选单词做匹配时,只考虑点击点序列中各点的左右手对应关系与候选单词中各字母的左右手对应关系完全一致的候选词。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述键盘为26键全键盘或9键键盘。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述相邻点击点之间的相对位置数据包括相邻点击点之间的位移向量。
在一个示例中,根据本发明实施例的盲式文字输入装置,对于任意两个字母,所述点击模型存储了相邻点击点之间的位移向量的概率密度分布参数。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述概率密度分布为高斯分布,参数为:高斯分布中的均值和标准偏差。
在一个示例中,根据本发明实施例的盲式文字输入装置,其中,所述点击模型针对各个用户,存储所述概率密度分布参数,不同用户相关联的概率密度分布参数是不同的,以及所述计算该点击点数据序列对应于该候选单词的概率包括:确定做出点击操作的用户标识信息;基于用户标识信息,从点击模型中获得该用户相关联的概率密度分布参数;以及基于所述相关联的概率密度分布参数,来计算该点击点数据序列对应于该候选单词的概率。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述计算该点击点数据序列对应于该候选单词的概率包括:基于点击模型、基于相邻点击点之间的相对位置数据、基于时间上彼此间隔一个或多个点击的点击点之间的相对位置数据,计算该点击点数据序列对应于该候选单词的概率,其中点 击模型中存储了为了计算相邻点击点之间、以及彼此间隔一个或多个点击的点击点之间表现出具体相对位置的概率而言所必需的数据信息。
30、根据权利要求29的盲式文字输入装置,所述相邻点击点之间的相对位置数据为相邻点击点之间的位移向量,时间上彼此间隔一个或多个点击的点击点之间的相对位置数据为所述点击点之间的位移向量,其中所述点击模型存储了为了计算相邻点击点之间、以及彼此间隔一个或多个点击的点击点之间表现出具体位移向量的概率而言所的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述计算该点击点数据序列对应于该候选单词的概率包括:基于点击模型、基于首个点击的位置数据、基于相邻点击点之间的相对位置数据,计算该点击点数据序列对应于该候选单词的概率,其中,点击模型中存储了为了计算首个点击的位置数据出现在具体位置以及相邻点击点之间表现出具体相对位置的概率而言所需的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入装置,点击点序列对应于单词w的概率p(w|I)通过下式来表征,
其中,p(w)表示单词w的先验概率,从语言模型数据库中获得, 用户实际输入I为长度为n的点击序列,表示单词w的m个字符的理想点击位置,ΔXi=Xi-Xi-1;ΔYi=Yi-Yi-1表示相邻理想点击点之间的向量,Δxi=xi-xi-1;Δyi=yi-yi-1表示相邻实际输入点之间的向量,其中点击模型中还存储了用户在用手指点击一个按键时点击点位置的概率密度分布。
在一个示例中,根据本发明实施例的盲式文字输入装置,其中, 以及 表示高斯分布,其中分别表示ΔXk的均值和方差,以及 分别表示ΔYk的均值和方差。
在一个示例中,根据本发明实施例的盲式文字输入装置,其中,针对每个用户,来存储相关联的和以及所述计算该点击点数据序列对应于该候选单词的概率包括:确定做出点击操作的用户标识信息;基于用户标识信息,从点击模型中获得该用户相关联的和 以及基于该用户相关联的和来计算p(Δxk|ΔXk)、p(Δyk|ΔYk)。
在一个示例中,根据本发明实施例的盲式文字输入装置,其中,对于每两个按键,基于统计的这两个按键之间的向量的平均值和方差来得到这两个按键相关联的和
在一个示例中,根据本发明实施例的盲式文字输入装置,其中基于先验数据,拟合出所述软键盘,基于拟合的软键盘中的拟合得到的两个按键之间的平均值和方差来得到这两个按键相关联的和
在一个示例中,根据本发明实施例的盲式文字输入装置,所述相邻点击点之间的相对位置数据为相邻点击点之间的时间间隔,其中所述点击模型存储了为了计算相邻点击点之间表现出具体时间间隔的概率所必需的数据信息。
在一个示例中,根据本发明实施例的盲式文字输入装置,所述基于计算得到的概率,将所述点击点数据序列识别为相应单词包括:基于计算得到的点击点数据属于确定单词的概率,显示多个单词候选;响应于用户对多个单词候选做出的选择动作,选择对应的单词候选作为单词输入。
根据本发明的另一方面,提供了一种适于进行盲式文字输入的计算装置,包括可触摸屏幕或面板、存储器和处理器,可触摸屏幕或面板上布置有真实或虚拟的软键盘;存储器上存储有计算机可执行代码;当计算机可执行代码由所述处理器执行时,执行下述方法:检测用户手指在软键盘上的点击动作,获得按时间顺序排列的点击点数据序列;基于语言模型、基于点击模型以及至少部分基于相邻点击点之间的相对位置数据,对于各个候选单词,计算该点击点数据序列对应于该候选单词的概率,其中,点击模型存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布;以及基于计算得到的概率,将所述点击点数据序列识别为相应单词
本公开的盲式文字输入技术考虑相邻点击相对位置,相比于基于点击绝对位置的技术,显著提高了文字输入速度和准确率。
附图说明
从下面结合附图对本发明实施例的详细描述中,本发明的这些和/或其它方面和优点将变得更加清楚并更容易理解,其中:
图1示出了根据本发明实施例的借助真实软键盘或虚拟软键盘的盲式文字输入设备100的结构框图。
图2示出了根据本发明实施例的由盲式文字输入设备100执行的盲式文字输入方法200的总体流程图。
图3示出了绝对位置算法AGK和本发明实施例的相对位置算法RGK在输入单词预测准确度方面的实验结果比较表格。
图4示出了绝对位置算法和相对位置算法在输入速度、字符级别校正的错误率、预测错误率方面的比较结果表格。
图5示出了本发明人基于实验数据描绘的12个用户脑海中的键盘相对于标准键盘所处的位置和大小的示意图。
图6(a)到图6(f)示意性地示出了根据本发明实施例的盲式文字输入技术的应用场景图。
具体实施方式
为了使本领域技术人员更好地理解本发明,下面结合附图和具体实施方式对本发明作进一步详细说明。
下面说明一下本文中使用的术语的含义。
语言模型:统计式的语言模型是借由一个概率分布,而指派概率给字词
所组成的字串:p(w1,…,wm)。
点击模型:点击模型存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布数据。
绝对模型:基于用户输入单词时各个点击之间是独立的假设建立的模型。
相对模型:基于用户输入单词时各个点击之间是存在相互关系的假设建立的模型。
软键盘:本文中的软键盘指屏幕上或者面板上存在的键盘,并非传统的台式机或者笔记本电脑上的带有物理突出按键的键盘。另外,可显示为用户看到的键盘称之为“真实软键盘”,不显示出来的、用户不可见的键盘称之为“虚拟软键盘”。软键盘的例子有智能移动电话的触摸屏上显示的键盘,智能电视遥控器的屏幕上可显示的键盘,或者预期的可触摸面板上(可见或不不可见)的键盘。
在具体描述根据本发明实施例的盲式文字输入方法和设备之前,需要说 明的是,本发明的发明人设计并进行了大量实验,通过统计数据分析盲式输入的可行性,以及实验数据是否支持相对模型和绝对模型。正是基于这些实验结果,发明人提出了本公开的盲式文字输入方法和设备,并且将本公开的盲式文字输入技术与现有的输入方法进行了比较实验,分析了输入速度和准确率,最后实验结果也证实在输入速度和准确率方便,本公开的盲式文字输入技术都显示出突出的优越性。
为后面描述方便,下面定义一些符号,假定用户需要从预定义的词汇表(V)中输入单词(w)。一个单词可以表示为字符的序列,w=c1…cn。标准键盘上的字符ci的键中心的坐标是(Xi,Yi)。
一个单词w的理想输入表示为下式(1):
其中,m表示单词w包含的字符的个数。
实际输入I是用户在触摸板(touchpad)上进行的n个触摸点的序列。每个触摸点可以表示为触摸板上的坐标(xi,yi)。这样,单词的实际输入表示为下式(2):
考虑相对模式,相邻理想点击点之间的向量和相邻实际输入点击点之间的向量表示为式(3)和(4):
ΔXi=Xi-Xi-1;ΔYi=Yi-Yi-1 (3)
Δxi=xi-xi-1;Δyi=yi-yi-1 (4)
需要说明的是,本发明的发明人设计并进行了大量实验,通过统计数据分析盲式输入的可行性,以及相对模型和绝对模型的优劣。例如,发明人考察了用户脑海中的键盘形状、键盘位置和键盘大小与标准物理键盘之间的关系。为此,发明人招募参与者,收集了9664个单词的输入点击序列,其中涉及到40509次字母输入,考察了用户头脑中的键盘形状、键盘大小和键盘位置,还考察了用户点击坐标x与理想X之间的关系,以及Δx与ΔX之间的关系。
图5示出了本发明人基于实验数据描绘的12个用户脑海中的键盘相对于标准键盘所处的位置和大小的示意图,其中12个规则的矩形指示完全一样的12个标准物理键盘KB1-KB12,每个标准物理键盘KBi内的黑点为用户i的点击分布,这些点击分布的其外接矩形(虚线框)指示用户i的脑海中的键 盘。实验发现:
(1)绝对模型和相对模型得出的键盘形状都比较接近于标准物理键盘的形状,而且相比于基于绝对模型得到的用户脑海中的键盘形状,基于相对模型假设得到的用户脑海中的键盘形状更接近于标准物理键盘的键盘形状(相对模型考察x与X之间的关系,相对模型考察Δx与ΔX之间的关系),这一方面表明盲式输入是可行的(用户有能力将可视的物理键盘转化成脑海中的键盘);另一方面为相对模型提供了支持;
(2)在盲式输入的相邻点击之间存在某种依赖关系。具体地,一个分析过程如下:将每个点击视为一个变量,假设两者不存在相关性,同时假设每个点击的分布符合高斯分布,则基于如下统计学定理:两个具有相同标准变差的独立的高斯变量之和或者之差应该具有的标准偏差,通过实验统计得到向量Δx的标准偏差SD(Δx)和向量x的标准偏差SD(x),以及得到向量Δy的标准偏差SD(Δy)和向量y的标准偏差SD(y),并求得SD(Δx)/SD(x)和SD(Δy)/SD(y),发现与相差较大,因此这个实验结果支持相邻点击之间存在相关性的假设。
(3)不同用户的脑海中键盘位置和大小差异较大(参见图5)。
下面结合图1描述根据本发明实施例的盲式文字输入设备。
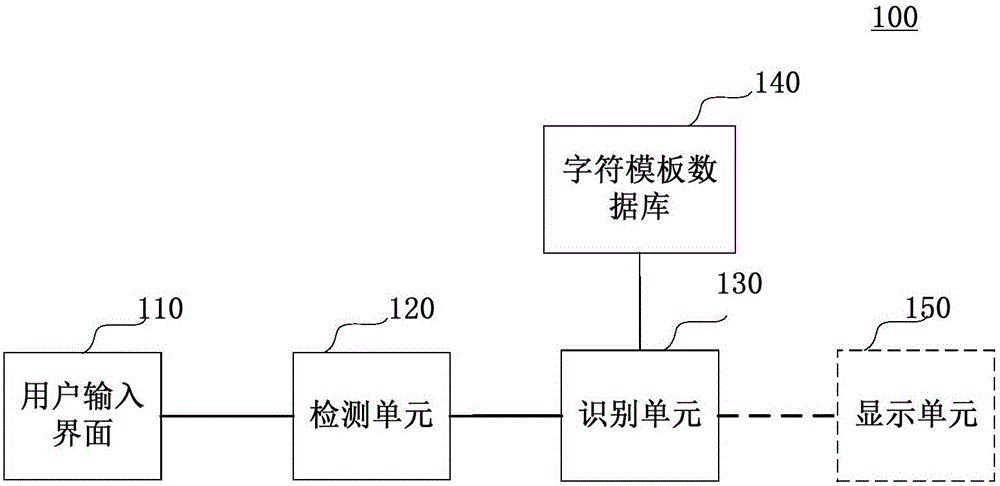
图1示出了根据本发明实施例的借助真实软键盘或虚拟软键盘的盲式文字输入设备100的结构框图。
如图1所示,盲式文字输入设备100可以包括:可触摸屏幕或面板110、检测单元120、语言模型数据库和点击模型数据库130、识别单元140。可选地,盲式文字输入设备100还可以包括显示单元150。
作为盲式文字输入设备实现环境的现实设备的示例,例如,可以为智能电视的遥控器、智能移动电话、智能眼镜、个人数字助理等等。
可触摸屏幕或面板110例如为智能移动电话的触摸屏,或者例如不具有显示功能但是能够感测用户的触摸或点击的面板。
检测单元120配置为检测用户手指在可触摸屏幕或面板上做出的点击动作。检测单元120例如包括压力传感器和模数转换器的器件,用于将用户的点击动作转换为计算设备能够处理的信号,
语言模型数据库和点击模型数据库130配置为存储语言模型数据和点击 模型数据,其中点击模型存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
识别单元140配置为基于语言模型、基于点击模型以及至少部分基于相邻点击点之间的相对位置数据,对于各个候选单词,计算该点击点数据序列对应于该候选单词的概率,以及基于计算得到的概率,将所述点击点数据序列识别为相应单词。
优选地,盲式文字输入设备100还包括显示单元150,可以用于显示识别出的单词,和/或在需要用户在多个候选中进行选择的情况下显示候选。
图2示出了根据本发明实施例的由盲式文字输入设备100执行的盲式文字输入方法200的总体流程图。
在步骤S210中,检测用户手指在软键盘上的点击动作,获得按时间顺序排列的点击点数据序列。
具体地,在用户输入模式下(可以通过某个开关或应用的开启而启动用户输入模式),检测用户手指的点击,然后可以通过检测单词输入的截止动作作为点击序列结束信号,所述截止动作可以为例如手指向右扫(swipe right)或者手指静止预定时间以上等等。
这里,用户手指应该做广义理解,涵盖代替用户手指的额外工具,例如点击笔、脚趾等。
用户可以单手操作盲式文字输入装置,以大拇指或食指来操作盲式文字输入装置。或者用户双手操作盲式文字输入装置,输入方式例如可以为下列之一:双手大拇指输入、双手食指输入、双手十指输入。
用户实际输入I为长度为n的点击序列,表示为在双手输入的情况下,针对每只手,得到各自的点击序列。
在步骤S220中,对于单词库中的每个单词,基于语言模型、基于点击模型以及至少部分基于相邻点击点之间的相对位置数据,对于各个候选单词,计算该点击点数据序列对应于该候选单词的概率,其中,点击模型存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
此步计算输入I对应于单词w的概率p(w|I),此步为本发明实施例的重点,后续将对此步进行具体描述。
在步骤S230中,基于计算得到的概率,将所述点击点数据序列识别为相 应单词,并显示于单词输入域。
这里,作为示例,可以简单地,将用户输入的点击序列识别为概率最高(即maxw∈V{p(w|I)},V表示单词库)的单词。替代地,可以显示概率最高的k个单词,作为用户输入单词的候选,供用户选择。
需要说明的是,在用户输入短语或句子的情况下,可以基于上下文情况来修正一个点击序列所对应单词的概率。
另外,在盲式文字输入技术应用于虚拟(VR)眼镜的情况下,可以将单词候选和/或输入的单词显示在VR眼镜上,即VR眼镜作为显示单元。
在盲式文字输入技术与电视机结合使用,所述电视机的显示屏作为所述显示单元。
下面结合示例详细说明图1所示步骤S220的实现,具体地,如何计算点击点数据序列对应于一单词w的概率,其中利用了相邻点击点之间的相对位置数据。下面首先对单手输入的情况加以说明。
如前所述,用户实际输入I为长度为n的点击序列,表示为
对于单词w,如前所述,其理想输入(或者说键盘字母坐标序列)为
基于用户输入I预测单词w可以表示为计算概率p(w|I),利用贝叶斯公式,得到式(5)
在本示例中,对实际输入I没有先验知识,或者即便有对于所有单词p(I)都是一样的,所以可以视为p(I)≡1,则上式(5)转变为下式(6),
p(w|I)=p(I|w)·p(w) (6)
对于m不等于n的单词w,可以直接丢弃掉,或者认为p(w|I)=0,同时基于前述式(1)和式(2),式(6)变为下式(7)
假定用户在X轴和Y轴上行为彼此独立,则上式(7)变为式(8)
根据本发明实施例的相对模型,认为至少相邻点击点之间存在相关性,因此上述概率计算会至少考虑相邻点击点之间的相对位置数据。在一个示例中,相邻点击点之间的相对位置数据为相邻点击点之间的位移向量,例如上文所述的(Δx,Δy)。不过,第一个点击点不具有相对位置数据,用绝对位置 数据来表示。在一个示例中,上式(8)可以表示为式(9)
上式中,p(w)可以从语言模型数据库中获得;p(x1|X1)和p(y1|Y1)基于点击模型数据库中存储的关于绝对点击位置的概率密度分布而获得,p(Δxk|ΔXk)和p(Δyk|ΔYk)可以基于点击模型数据库中存储的关于相对点击位置的概率密度分布信息计算得到。
在一个示例中,丢弃第一个点击点的绝对位置数据p(x1|X1)和p(y1|Y1),仅使用语言模型信息p(w)和相对点击位置概率p(Δxk|ΔXk)和p(Δyk|ΔYk)来计算p(w|I)也是可行的。
在一个示例中,认为相对点击位置的概率密度分布满足高斯分布,即如式(10)和(11)所示
关于高斯分布的参数,即均值和方差均值和方差存储于点击模型数据库中,可以由前述发明人对于众多用户盲式输入时的相邻点击的向量的统计得到。比如,可以在点击模型中存储:与连续点击的字母O和P相关联的统计得到的O对应点击和P对应点击之的均值间和方差 均值和方差与连续点击的K和I相关联的统计得到的K对应点击和I对应点击之间的均值和方差均值和方差与连续点击的字母M和O相关联的统计得到的M对应点击和O对应点击之间的均值和方差均值和方差等等。
综上,可以计算得到基于用户输入I预测单词w的概率p(w|I)。
相对比地,传统的绝对模型只使用绝对位置数据,上式(8)将变为式(12)。
传统地,假设用户对某个字母的点击的绝对位置也符合高斯分布,如式(13)和(14)所示。
同样,将高斯分布的参数,均值和方差存储在点击模型数据库中。
下面描述一下对于使用绝对位置来预测概率和使用相对位置来预测概率 的对比实验情况。
在该实验示例中,对于绝对位置算法(下文简称之为AGK):使用点击的绝对位置,使用的键盘为26键全键盘,
在该实验示例中,对于相对位置算法(下文简称之为RGK):使用点击的相对位置,使用的键盘为26键全键盘,具体地相邻点击点之间的x向距离和y向距离。
实验招募了16个参与者,分别让其学习使用盲式绝对位置算法AGK和本发明实施例的相对位置算法RGK,然后输入预定的单词和短语,分别考察选取预测概率最高的前1名(称为top-1),前5名(称为top-5)和前25名(称为top-25)的候选单词是预测的准确率和输入速度。
图3示出了绝对位置算法AGK和本发明实施例的相对位置算法RGK在输入单词预测准确度方面的实验结果比较表格,其中RGK算法的Top-1、Top-5和Top-25的预测准确率分别为80.9%、95.9%和97.9%。AGK算法的Top-1、Top-5和Top-25的预测准确率分别为71.0%、91.7%和95.9%。可见,在Top-1、Top-5和Top-25三项预测上,本发明实施例的相对位置算法RGK的准确率明显高于绝对位置算法AGK,其中在Top-1预测准确率上,RGK比AGK高10%。
图4示出了绝对位置算法和相对位置算法在输入速度、字符级别校正的错误率、预测错误率方面的比较结果表格。
在输入速度上,根据本发明实施例的相对位置算法RGK显示出显著的优越性。如图4所示,绝对位置算法AGK的平均输入速度为17.23WPM(Word per Minute,每分钟字数),根据本发明实施例的相对位置算法RGK的平均输入速度为20.97WPM。可见,根据本发明实施例的相对位置算法RGK比绝对位置算法AGK快了21.7%。
在字符级别校正的错误率方面,发明人还设计和进行实验,比较了绝对位置算法AGK和相对位置算法RGK,AGK的纠正错误和未纠正错误率分别为6.11%和1.69%,RGK的纠正错误和未纠正错误率分别为5.13%和0.51%,可见相对位置算法RGK相比于绝对位置算法AGK产生的错误更少,具有更高的准确性。有关字符级别校正的错误率,可参见文献Wobbrock,J.O.,&Myers,B.A.(2006).Analyzing the input stream for character-level errors in unconstrained text entry evaluations.ACM Transactions on Computer-Human Interaction (TOCHI),13(4),458-489。
预测错误率指的是在top-k单词候选中,没有目标单词。如图4所示,可见ARG和RGK的预测错误率分别为4.09%和2.09%,可见相比于绝对位置算法ARG,RGK算法将预测错误率降低了一半。
另外,在学习使用效率和用户友好性上,参与者普遍表示因为已经熟悉智能手机的输入(QWERTY键盘),他(她)们很容易适应盲式文字输入算法,而且愿意在将来的智能电视上使用这样的盲式文字输入。
前面结合附图描述了根据本发明实施例的盲式文字输入装置和方法,此仅为示例,而非作为对本发明保护范围的限制。本领域技术人员可以根据需要对里边的具体结构、步骤、实现细节进行修改、变更、组合或替换。
在一个示例中,点击模型数据库针对各个用户来存储相邻点击的概率密度分布函数。例如,在概率密度分布函数是高斯分布的情况下,参数均值和方差是针对不同用户来分别获取和存储在点击模型数据库中的。这样在计算点击点数据序列对应于单词w的概率之前,应该确定用户的标识信息,以便后续从点击模型数据库中取得与该用户对应的、相邻点击点的概率密度分布,即与该用户对应的、各相邻点击点的距离矢量的均值和方差。然后,基于所述均值和方差参数,来计算该点击点数据序列对应于某单词的概率。例如,在点击模型数据库中:对于用户A,与连续点击的字母O和P相关联的统计得到的O对应点击和P对应点击之的均值间和方差均值和方差与连续点击的字母K和I相关联的统计得到的K对应点击和I对应点击之间的均值和方差均值和方差与连续点击的字母M和O相关联的统计得到的M对应点击和O对应点击之间的均值和方差 均值和方差等等;类似地,对于用户B,与连续点击的字母O和P相关联的统计得到的O对应点击和P对应点击之的均值间和方差 均值和方差与连续点击的字母K和I相关联的统计得到的K对应点击和I对应点击之间的均值和方差均值和方差与连续点击的字母M和O相关联的统计得到的M对应点击和O对应点击之间的均值和方差均值和方差等等;诸如此类,对于每个用户都存储了各个相邻点击的均值和方差均值和方差
在一个示例中,点击模型中的概率密度分布的参数是基于拟合出来的用户头脑中的键盘得到的。具体地,在区分用户来存储用户对应的参数的情况下,可以基于用户先前的大量点击行为,按照标准键盘的布局拟合出用户头脑中的键盘(如图5所示),此时拟合出的键盘是规则形状,与标准键盘形状相似。在拟合出键盘之后,两个字母之间点击向量的长度,由拟合的键盘上键之间的长度来表示;两个字母点击之间向量的方差,用拟合的键盘的方差来代替。例如:对于字母O和P,认为用户连续点击此两个字母时这两个相邻点击之间的向量是拟合出来的O键和拟合出来的P键之间的长度和方向。
在一个示例中,点击模型中各个字母点击之间向量的概率密度分布的参数是基于字母点击统计得到的,例如,某个字母的点击的绝对位置的均值和方差基于用户对该字母的点击来统计得到,此时形成的键盘形状是不规则的(按键之间的距离是不保证相等的),而两个字母的对应点击之间的向量(相对位置)的均值和方差基于用户对该两个字母之间的连续点击之间向量的统计得到的均值和方差来获得。
在前面示例中,计算该点击点数据序列对应于该候选单词的概率过程中仅考虑了相邻点击点之间的相对位置,不过本发明并不局限于此,而是可以不仅考虑相邻点击点之间的相对位置,还可以考虑次相邻的点击点(彼此之间间隔一个点击点)之间的相对位置,乃至彼此间隔更多点击点(如彼此间隔2个点击点、3个点击点等)的点击点之间的相对位置。点击数据库中存储了为了计算相邻点击点之间、以及彼此间隔一个或多个点击的点击点之间表现出具体相对位置关系的概率而言所必需的数据信息。具体地,例如,在点击数据库中存储了相邻点击点之间的矢量的概率密度分布,以及彼此间隔一个或多个点击的点击点之间的矢量的概率密度分布。以及,在计算点击点数据序列对应于某单词的概率之前,会计算点击点数据序列的,相邻点击点之间的矢量,以及彼此间隔一个或多个点击的点击点之间的矢量;然后基于语言模型,这些计算得到的矢量,以及基于点击数据库中的对应矢量的概率密度分布,来计算点击点数据序列对应于各个单词的概率。
在一个示例中,软键盘为分开的左手键盘和右手键盘,字母被分布在左手键盘和右手键盘,在检测单元检测用户手指点击时,检测用户手指在左手键盘上的点击动作,获得按时间顺序排列的点击点数据序列作为左手点击点数据序列,以及类似地检测用户手指在右手键盘上的点击动作,获得按时间顺序排列的点击点数据序列作为右手点击点数据序列。即,点击点数据序列包括已经被区分开的左手点击点数据序列和右手点击点数据序列。输入时用 户双手输入,左手在左手键盘上输入,右手在右手键盘上输入。在此情况下,根据本发明的一个实施例,在计算用户输入对应于某个单词的概率的过程中,将候选单词拆成左手字母序列和右手字母序列,然后分别针对左手字母序列,来计算左手点击点数据序列对应于该左手字母序列的概率作为左手概率;以及针对右手字母序列,来计算右手点击点数据序列对应于该右手字母序列的概率作为右手概率,进而基于左手概率和右手概率,来计算所述点击点数据序列对应于该候选单词的概率;点击模型中存储了用户在用左手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,以及用右手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
在一个示例中,键盘并非分开的左手键盘和右手键盘,不过目前输入模式为双手输入模式。在此情况下,根据本发明的一个实施例,在计算用户输入对应于某个单词的概率的过程中,根据标准指法规则将候选单词拆成左手字母序列和右手字母序列,并根据点击点和字母之间的对齐关系,将点击点序列分为左手点击点数据序列和右手点击点数据序列;然后分别针对左手字母序列,来计算左手点击点数据序列对应于该左手字母序列的概率作为左手概率;以及针对右手字母序列,来计算右手点击点数据序列对应于该右手字母序列的概率作为右手概率,进而基于左手概率和右手概率,来计算所述点击点数据序列对应于该候选单词的概率;点击模型中存储了用户在用左手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布,以及用右手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布。
在一个示例中,在双手输入模式的情况下,如果系统能够判断输入点序列中的各点与左右手之间的对应关系(比如,split keyboard),则在和候选单词做匹配时,可以只考虑点击点序列中各点的左右手对应关系与候选单词中各字母的左右手对应关系完全一致的候选词。
盲式文字输入装置上的软键盘可以为26键全键盘或9键键盘。
本发明实施例的盲式文字输入技术可以应用于各种场合。
图6(a)到图6(f)示意性地示出了根据本发明实施例的盲式文字输入技术的应用场景图,在这些场景中,输入是在无视觉反馈的情况下发生的。图6(a)示出了用户佩戴头盔显示器时,一手持握手机,用另一手的食指输入的场景; 图6(b)示出了在交互式桌面上,用户双手十指进行盲输入,用户关注交互内容而不是软键盘的场景;图6(c)示出了在走路情况下,用户单手持握手机拇指输入,目光注视前方路况的场景;图6(d)示出了用户佩戴头盔显示器时,单手持握手机拇指输入的场景;图6(e)示出了在远程屏幕上,用户双手空中输入;图6(f)示出了用户在观看电视时,双手持握手机双拇指输入,目光注视电视的场景。
在一个示例中,盲式文字输入装置可以与VR眼镜结合使用。例如,用户头戴着VR眼镜,同时用户在智能移动电话或者手柄的触摸板上进行盲式文字输入,此时用户输入的候选单词或者被识别确定的单词被显示在VR眼镜上。
在前面示例中,以相邻点击点之间的矢量来表示两者之间的相对位置关系。在一个示例中,还可以以相邻点击点之间间隔的时间来表示两者之间的相对位置关系,该时间间隔可以表征两个点击点之间的距离信息。
根据本发明的另一个实施例,提供了一种适于进行盲式文字输入的计算装置,包括可触摸屏幕或面板、存储器和处理器,可触摸屏幕或面板上布置有真实或虚拟的软键盘;存储器上存储有计算机可执行代码;当计算机可执行代码由所述处理器执行时,执行下述方法:检测用户手指在软键盘上的点击动作,获得按时间顺序排列的点击点数据序列;基于语言模型、基于点击模型以及至少部分基于相邻点击点之间的相对位置数据,对于各个候选单词,计算该点击点数据序列对应于该候选单词的概率,其中,点击模型存储了用户在用同一只手连续点击两个按键时后一个点击点相对于前一个点击点位置的概率密度分布;以及基于计算得到的概率,将所述点击点数据序列识别为相应单词,并显示于单词输入域。
本发明实施例的盲式文字输入方法和装置具有良好的广泛应用前景,可以应用于智能电视、智能手机、个人数字助理等等的文字输入,对于需要释放眼睛来进行其他事务的场合是非常有利的。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!