基于双端读数insertsize统计特征的scaffolding方法与流程
本发明涉及生物信息学领域,特别是一种基于双端读数insertsize统计特征的scaffolding方法。
背景技术:
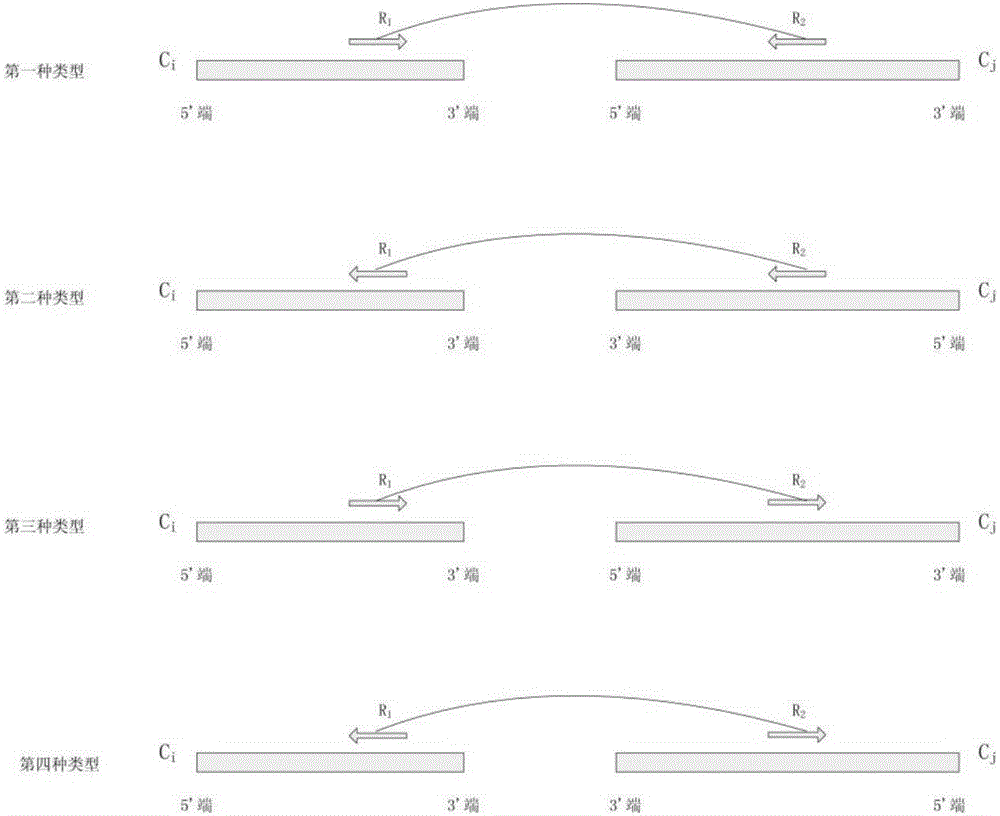
:基因组一般是指全部编码和非编码的脱氧核糖核酸(DNA)序列,它是由四种碱基:腺嘌呤(A)、胸腺嘧啶(T)、胞嘧啶(C)与鸟嘌呤(G)组成的序列,即基因组序列是一个字符串,这个字符串中只包含四个字符A,T,G,C。在实际基因组序列中也包含另一个字符N,代表该位置的碱基无法确定。通过基因组测序,可以获得大量基因组序列上短片段碱基序列(读数或read)。由基因组测序得到的读数集合,一般读数的长度比较短。序列拼接方法就是利用这些短读数还原完整的原始基因组序列。随着高通量测序技术的快速发展,基因组测序成本越来越低,并且速度越来越快,已经出现了许多拼接方法。但是,由于基因组序列中存在大量的重复区,拼接方法一般首先利用读数构建一些长的序列片段(contig),每条contig一般都是由A,T,G,C组成的比读数要长的字符串。然后采用名为scaffolding的方法确定这些contig的方向,以及它们在基因组序列上的先后顺序。通过scaffolding可以产生一些超长序列片段(scaffold),每条scaffold包含一些排好先后顺序并确定方向和距离的contig,contig之间的空白区域用‘N’来填充。目前普遍采用的测序技术得到的读数长度比较短,在200碱基对(bp)左右。这种短读数可以分为两种类型:单个读数(singleread)和双端读数(pairedread)。单个读数是在测序的时候复制一个比较短的基因组序列片段,然后对该片段进行测序得到一个读数。另外一种是在测序时,首先复制一个比较长的基因组序列片段,然后对基因组片段的左端和右端一段短区域进行测序,得到一对短读数即双端读数。双端读数中每对读数之间的间距称为insertsize,即首先复制的基因组序列片段长度,一般假设insertsize大小服从正态分布。由于双端读数的insertsize一般比读数本身的长度长,可以跨过一些重复区,因此双端读数可以克服部分长度小于insertsize的简单重复区。因此,现有的scaffolding方法往往利用双端短读数确定contig的方向和先后顺序关系。对于大部分scaffolding方法,在使用之前,用户首先采用某个拼接方法产生contig,并利用某个比对工具把双端读数比对到这些contig上,获得每个读数比对到contig上的位置信息,这些位置信息以bam或者sam文件格式保存。scaffolding方法以contig文件和比对结果文件作为输入数据。大部分scaffolding方法往往会首先构建一个scaffold图,每个节点代表一个contig,两个节点之间的边表示它们可能在基因组序列上相邻。这些scaffolding方法最主要的区别是:(1)、在构建scaffold图时,如何确定正确的边;(2)、采用什么策略从scaffold图中确定contig的方向和先后顺序。SOPRA方法首先删除了平均读数覆盖度高的contig,如果contig某个区域的读数覆盖度也很高,则比对到这个区域的读数也被移除。SOPRA设计了一些优化目标和约束条件,并在scaffold图上确定scaffold。Bambus2方法设计了一种贪婪的启发式算法确定contig的方向和先后顺序。MIP方法把scaffold图分解成一些小的scaffold图,并基于混合整数规划分配给每个contig一个方向和位置。OPERA方法首先对scaffold图进行压缩,并利用组合算法寻找最优的scaffold。SSPACE采用一种贪婪的策略,两个contig之间比对上的双端读数越多,则它们紧邻的可能性越大。SCARPA方法首先侦测scaffold图中存在的contig方向冲突,并利用线性规划框架确定contig之间的顺序。BESST方法利用双端读数的统计信息,优化scaffold图的边。在scaffold图中选择具有最多匹配上的双端读数的路径作为scaffold。ScaffoldMatch方法则基于scaffold图把scaffolding方法转化为最大权重的无环二分匹配问题。目前,虽然这些scaffolding方法已经取得了不错的结果,但是,仍然有以下几个问题需要进一步解决:(1)现有的方法往往利用比对到两个contig上的双端读数个数作为scaffold图上边的权重。而在低覆盖度区域,比对上的读数本身就很少,所以这种权重设置的方法往往会遗漏一些低覆盖度区域的contig之间的联系。对于一些复杂重复区,也不能简单的通过比对上的双端读数个数进行解决。(2)在发现scaffold图中的方向冲突和顺序冲突时,现有的方法一般通过一个整体的优化目标和约束条件,发现并移除造成冲突的边。这种策略把高可信度和低可信度的边一起考虑,而忽略了高可信度边对其它边的限制作用,也容易造成移除一些高可信度的边。(3)在遍历scaffold图,抽取路径并产生scaffold时,往往以整条路径上匹配上的双端读数个数最大化为优化目标,而忽略了长节点和短节点的一些特性。比如,一个长节点不能跨过一个长节点去和其它长节点相关联,而每个节点都可以同时和多个短节点相关联,所以,不能以从scaffold图中抽取路径为目标。这些问题的存在,限制了现有的scaffolding方法取得更令人满意的结果。技术实现要素:本发明所要解决的技术问题是,针对上述现有技术的不足,提供一种基于双端读数insertsize统计特征的scaffolding方法,简单易用,准确性高。为解决上述技术问题,本发明所采用的技术方案是:一种基于双端读数insertsize统计特征的scaffolding方法,包括以下步骤:1)首先将双端读数数据集合比对到contig上,得到比对结果;对比对结果进行预处理:1.1)对于双端读数中的每个读数,保留比对得分值最高的位置信息,删除其它位置信息;1.2)计算contig上每个碱基位置的单个读数覆盖度,如果该覆盖度大于该contig上所有碱基位置的平均读数覆盖度的k倍,则删除比对到该碱基位置的所有双端读数信息;其中2≤k≤4;1.3)删除不符合insertsize统计特征的双端读数的比对信息;insertsize统计特征是指insertsize服从正态分布N(μis,σis),其中μis为均值,σis为标准差;比对到同一条contig上的双端读数的insertsize需要在[μis-3*σis,μis+3*σis]这一区间,否则删除该双端读数的比对信息;2)根据保留下来的比对结果,构建带权重的scaffold图,图中每个节点代表一个contig;并利用insertsize分布估计两个节点之间比对上双端读数的期望值;再根据两个节点之间比对上双端读数的实际个数和期望值,确定两个节点之间是否存在边及边的权重;3)确定scaffold图中的冲突,并移除造成冲突的边:根据双端读数比对到两个节点上的位置和方向,确定两个节点之间的距离,及两个节点是否在同一个方向上,也就是说,在scaffold图中每条边约束了两个节点之间的距离,以及两个节点是否方向一致;移除部分边来保证scaffold图中不存在距离和方向冲突,以移除边的权重之和最小为优化目标,进行冲突发现和移除;4)生成scaffold集合;根据节点的长度,把scaffold图中的节点分为长节点和短节点;首先,抽取出只包含长节点的简单路径集合,将这些简单路径集合作为初始的scaffold集合;一个scaffold即一个节点序列;其次,如果一个短节点和scaffold中两个相邻的长节点都存在边,则把该短节点插入到两个长节点中间,形成新的scaffold;如果在两个相邻的长节点中,存在多个短节点和它们相连,则先根据短节点和长节点的距离由小到大对短节点进行排序,再按顺序把短节点插入到长节点之间,形成新的scaffold;最后,选择一个scaffold从其末端节点出发,基于scaffold图进行广度优先遍历,并把遍历的节点合并到当前scaffold,对scaffold进行扩展;当遇到另一个scaffold的末端时,合并这两个scaffold;当没有其它节点可以扩展时,则停止该scaffold的遍历;输出scaffold集合。所述步骤2)具体为:2.1)根据双端读数比对到两个节点上的方向,把比对上的双端读数分为四种类型:(正向,反向),(反向,正向),(正向,正向)和(反向,反向);针对任意两个节点Ci和Cj,统计比对上的双端读数的类型,选择比对上的双端读数个数最多的类型,将属于该类型的双端读数作为最终比对上的双端读数,进行后续分析;2.2)如果最终比对上的双端读数个数n小于阀值m1,则这两个节点之间不添加边,并删除这两个节点之间比对上的双端读数信息;其中2≤m1≤4;2.3)如果最终比对上的双端读数个数n大于或者等于阀值m,则利用insertsize分布估计两个节点之间比对上的双端读数的期望值;设比对到Ci和Cj之间的第t个双端读数为(Rt1,Rt2),且Rt1比对到Ci的p1位置,Rt2比对到Cj的p2位置,由此得到两个距离:Dt1=leni-p1和Dt2=p2+r;其中leni为Ci的长度,r为双端读数的长度;估计Ci和Cj之间的距离为Gt=μis-Dt1-Dt2;根据所有比对到Ci和Cj之间的双端读数,计算Ci和Cj之间距离的估计值Gij:Gij=1nΣt=1nGt;]]>2.4)对于一个读数Rt,如果它能够比对到Ci的pt位置,并且比对方向和Rt1比对到Ci上的比对方向一致,则它的另一端读数Rs能够比对到Cj的概率即为Rt和Rs之间的距离在区间[Dt+Gij+r,Dt+Gij+lenj]的概率,通过以下公式进行计算该概率:Pt=∫Dt+Gij+lenjDt+Gij+rf(x)dx]]>其中,Dt=leni-pt,f(x)为正态分布的概率密度函数,lenj为Cj的长度;因为在实际中,insertsize一般都小于μis+3*σis,所以,本方法只选择比对到Ci的[max(μis+3*σis-Gij-r,0),leni]区间上的读数计算比对上的双端读数期望值。由于测序错误的存在,一些应该比对上的读数而没有比对上,所以该概率值再乘以测序错误率e。针对所有比对到Ci上的读数都可以计算其另一端读数比对到Cj的概率。最终通过以下公式计算Ci和Cj之间比对上的双端读数的期望值:Eij=e*Σt=1sPt]]>其中,s为比对到Ci的[max(μis+3*σis-Gij-r,0),leni]区间上的读数个数,并且这些比对上的读数的比对方向和Rt1比对到Ci上的比对方向一致;e为测序错误率,根据步骤1.3)中保留下来的比对上的单个读数个数估计得到,测序错误率e等于比对上的单个读数个数与所有读数个数的比值;2.5)计算Ci和Cj相邻的可能性ρij:ρij=1-|1-Eijn|]]>期望值Eij和实际比对上的双端读数之间的比值,如果这两个值越接近,则表示Ci和Cj相邻的可能性ρij越大;2.6)同理,根据步骤2.4)和2.5),利用比对到Cj上的读数计算它们另一端读数比对到Ci上的期望,最终得到ρji;2.7)如果ρij和ρji中有一个小于阀值m2,则Ci和Cj之间不添加边,否则,在Ci的3’端和Cj的5’端之间添加一条边,权重为ρij和ρji的平均值;如果Ci的一端(3’端或者5’端)只和Cj的一端存在比对上的双端读数,而Cj的该端也只和Ci的该端存在比对上的双端读数,即使计算出的ρij或者ρji小于阀值m2,也在Ci和Cj之间添加一条边,该边权重设为m2;其中0.2≤m2≤0.4。所述步骤2.1)中,m1=3;所述步骤2.7)中,m2=0.3。所述步骤3)具体包括以下步骤:3.1)移除造成长节点冲突的边:将scaffold图中节点长度大于等于μis+3*σis的节点称为长节点,剩余的节点称为短节点;在同一个方向上,如果一个长节点和其它多个长节点存在边,则只保留这些边中权重最大的边;3.2)移除造成方向冲突的边:利用迭代和整数线性规划方法发现造成方向冲突的边,并删除掉造成方向冲突的边,使scaffold图中不包含方向冲突;①设置初始化权重阈值θ=0.9;②设置以下方向约束条件和优化目标函数:即给每个节点分配一个方向,使符合约束的所有边的权重之和最大;选择scaffold图中所有权重大于θ的边,建立集合V;并建立一个边的空集合Ω1;如果Ci和Cj之间的边属于集合V,且没有在集合Ω1中,并且根据该边的约束,Ci和Cj在不同的方向上,则建立方向约束条件为:Oi+Oj≤2-ηij-Oi-Oj≤-ηij]]>如果Ci和Cj之间的边属于集合V,且没有在集合Ω1中,并且根据该边的约束,Ci和Cj在同一个方向上,则建立方向约束条件为:Oi-Oj≤1-ηij-Oi+Oj≤1-ηij]]>其中,Oi,Oj∈{0,1},分别表示给节点Ci和Cj分配的方向,0代表正向,1代表反向;ηij是一个松弛变量,ηij∈{0,1};如果Ci和Cj之间的边属于集合V,且在集合Ω1中,并且根据该边的约束,Ci和Cj在不同的方向上,则方向约束条件为:-Oi!=Oj如果Ci和Cj之间的边属于集合V,且在集合Ω1中,并且根据该边的约束,Ci和Cj在同一个方向上,则方向约束条件为:Oi=Oj优化目标函数为:MAX(∑wij·ηij)其中,wij表示节点Ci和Cj之间的边的权重;MAX(∑wij·ηij)表示求使得函数值最大的ηij取值;③求解优化目标函数,对于所有没有在集合Ω1中的边,如果ηij等于1,则节点Ci和Cj之间的边添加到集合Ω1中;④令θ=θ-0.1,返回步骤②;直到θ=0,结束迭代;⑤当结束迭代后,每个节点都被分配了一个方向,并且没有在集合Ω1中的边确定为造成方向冲突的边,进行删除,形成一个新的scafold图;3.3)移除造成顺序冲突的边:ⅰ设置初始化权重阈值θ=0.9;建立一个边的空集合Ω2;ⅱ设置以下顺序约束条件和优化目标函数:即通过分配给每个contig一个起始位置,使满足距离约束的所有边的权重之和最大;选择scaffold图中所有权重大于θ的边,建立集合V;如果Ci和Cj之间的边属于集合V,且没有在集合Ω2中,则建立顺序约束条件为:Xj-Xi-leni-Gij≤C(1-Φij)Xi-Xj+leni+Gij≤C(1-Φij)]]>如果Ci和Cj之间的边属于集合V,且已经在集合Ω2中,则建立顺序约束条件为:Xi-Xj-leni<=μis+3*σisXi-Xj-leni>0]]>优化目标函数为:MAX(∑wij·Φij)其中,Xi,Xj∈[0,C],分别表示给节点Ci和Cj分配的在正向上的起始位置坐标,Xi,Xj为整数,且Xj≥Xi;C是所有节点长度之和的两倍;Φij∈[0,1],是一个松弛变量,用来反映相应边约束的Ci和Cj之间的距离和通过分配位置坐标得到的距离之间的差距;leni为Ci的长度,Gij为根据相应边约束得到的Ci和Cj之间距离;ⅲ求解优化目标函数,对于所有没有在集合Ω2中的边,通过分配给相应节点的起始位置可以计算得到一个新的节点之间的距离,如果这个距离和上边步骤中通过比对上的双端读数计算的到的距离之差不大于3*σis,则相应的边添加到集合Ω2中;即若Ci和Cj之间的边没有在集合Ω2中,且:|Xj-Xi-leni-Gij|≤3*σis则Ci和Cj之间的边添加到集合Ω2中。ⅳ令θ=θ-0.1,返回步骤ⅱ;直到θ=0,结束迭代;ⅴ当结束迭代后,每个节点都被分配了一个起始位置坐标,并且没有在集合Ω2中的边确定为造成顺序冲突的边,进行删除。进一步地,如果步骤1)中以多个双端读数数据集合作为输入数据,则首先从insertsize比较小的双端读数数据集合开始scaffolding,并以步骤4)中输出的scaffold作为下一个双端读数数据集合的contig进行scaffolding。所述步骤1.2)中,k=3。与现有技术相比,本发明所具有的有益效果为:本发明是一种基于双端读数insertsize统计特征的scaffolding方法,scaffolding是序列拼接算法中一个重要的步骤,它以contig集合和读数比对到contig上的位置信息为输入数据,并以scaffold集合为输出结果。每个scaffold是由确定了方向和顺序的contig组成。本方法基于insertsize分布对比对到两个contig上的双端读数进行评价,构建加权的scaffold图,该方法能够有效的克服测序不均衡问题以及部分重复区问题。基于加权的scaffold图,本方法采用迭代和整数线性规划方法发现和移除方向和顺序冲突。迭代策略可逐步确定高可信的边,并以高可信的边为框架进行后续的冲突发现。最终本发明采用一种启发式方法确定scaffold图中节点的先后顺序,构建scaffold集合。本发明充分利用双端读数之间的insertsize分布,构建更准确的scaffold图,并利用迭代策略有效的发现scaffold图中的方向和顺序冲突。本发明简单有效,并在四组真实数据上和其它多种目前流行的scaffolding方法进行比较。实验结果表明,本发明所提供的方法能够更准确的确定contig的方向以及它们之间的顺序。附图说明图1为本发明方法流程图;图2为本发明一实施例pairedread比对到contig的四种类型;图3为本发明一实施例pairedread比对到contig的第一种类型的距离信息;图4为本发明一实施例提取scaffold图中scaffold;具体实施方式如图1所示,本发明具体实现过程如下:一、预处理在本方法中,假设双端读数中,左右读数不在同一个方向上,并且相对于左读数的5’端到3’端的方向,右读数在左读数的右边。以contig文件和比对结果文件为输入数据。在比对结果文件中,由于重复区和测序错误,往往会造成某条读数有多个比对位置信息。对于每个读数,本方法只保留比对得分值最高的比对位置信息,剩下的非最优比对位置信息全部去除。根据所有读数的比对位置信息,可以得到每个contig上每个位置的读数覆盖度,即某个碱基位置有多少个比对上的读数覆盖该位置。同时,计算每个contig平均读数覆盖度,即该contig上所有比对上的读数的碱基数除以contig的长度。接着计算contig每个位置的读数覆盖度除以contig的平均覆盖度,如果该值大于一定阀值,则认为该位置为重复区,会对后续的计算造成影响,所以去除掉所有比对到高覆盖度区域的读数位置信息。比对到同一条contig上的双端读数之间的距离需要在[μis-3*σis,μis+3*σis]这一区间,否则移除该双端读数的比对信息。然后利用所有仍然保留下来的比对上的读数个数除以所有读数的个数,得到一个估计的测序错误率e。二、构建带权重的scaffold图对于两个contig:Ci和Cj,和一个比对上的双端读数:(R1,R2),其中R1比对到Ci,R2比对到Cj。根据R1和R2是否正向比对到Ci和Cj上,把比对上的双端读数分为四种类型:(1)R1正向比对到Ci,R2反向比对到Cj,意味着Ci的3’端和Cj的5’端有关联。(2)R1反向比对到Ci,R2正向比对到Cj,意味着Ci的5’端和Cj的3’端有关联。(3)R1正向比对到Ci,R2正向比对到Cj,意味着Ci的3’端和Cj的3’端有关联。(4)R1反向比对到Ci,R2反向比对到Cj,意味着Ci的5’端和Cj的5’端有关联。图2为本发明双端读数比对到contig的四种类型示意图。由于R1和R2不在同一个方向上,所以(1)和(2)两种类型,意味着Ci和Cj在同一个方向上,而(3)和(4)两种类型,意味着Ci和Cj不在同一个方向上。首先,对于每一个contig,建立一个节点代表该contig。针对任何两个contig,统计比对上的双端读数类型,并选择比对上的双端读数个数最多的类型进行后续分析,其它类型比对上双端读数不予考虑。如果比对上的双端读数个数小于阀值m,则这两个contig之间不会添加边。如果该值大于或者等于阀值m,则利用insertsize分布对这些比对上的双端读数进行打分。假设比对到Ci和Cj的第t个双端读数为(Rt1,Rt2),Rt1比对到Ci的p1位置,R2比对到Cj的p2位置。可以得到两个距离,Dt1=leni–p1和Dt2=p2+r。其中leni为Ci的长度,lenj为Cj的长度,r为读数的长度。可以估计Ci和Cj之间的距离为Gt=μis-Dt1-Dt2。根据所有比对到Ci和Cj上的双端读数,可以得到Ci和Cj之间距离的最终估计值Gij为:Gij=1nΣt=1nGt]]>其中,n为比对到Ci和Cj的双端读数个数。对于一个读数Rt,如果它能够比对到Ci的pt,并且比对方向和Rt1比对到Ci上的比对方向一致,则它的另一端读数Rs能够比对到Cj的概率即为Rt和Rs之间的距离insertsize在区间[Dt+Gij+r,Dt+Gij+lenj]的概率,Dt=leni–pt,假设insertsize符合正态分布,则该概率可以利用下边公式进行计算:Pt=∫Dt+Gij+lenjDt+Gij+rf(x)dx]]>其中f(x)为正态分布的概率密度函数。而在实际中,insertsize一般都小于μis+3*σis,所以,本方法只选择比对到Ci的[max(μis+3*σis-Gij-r,0),leni]区间上的读数计算双端读数期望值。由于测序错误的存在,一些应该比对上的读数而没有比对上,所以该概率值再乘以测序错误率e。针对所有比对到Ci上的读数都可以计算其另一端读数比对到Cj的概率。最终计算得到一个值,即Ci和Cj之间比对上的双端读数的期望值,利用下边公式进行计算:Eij=e*Σt=1sPt]]>s为比对到Ci的[max(μis+3*σis-Gij-r,0),leni]区间上的读数个数,并且比对上读数的比对方向和Rt1比对到Ci的比对方向一致。接着,计算该期望值和实际比对上的双端读数之间的比值,如果这两个值越接近,则表示Ci和Cj相邻的可能性ρij越大:ρij=1-|1-Eijn|]]>同理,可以利用比对到Cj的读数计算它们另一端读数比对到Ci上的期望,最终得到ρji,如果ρij和ρji有一个小于一定阀值0.3,则Ci和Cj之间不会添加边,否则,在Ci的3’端和Cj的5’端之间添加一条边,权重为这两个值的平均值。如果Ci的一端(3’端或者5’端)只和Cj的一端存在双端读数,而Cj的该端也只和Ci的该端存在双端读数,即使计算出的ρij或者ρji小于阀值,则Ci和Cj之间也添加一条边,该边权重设为0.3。当处理完所有的contig后,则构建了一个带权重的scaffold图。三、发现并移除方向和顺序冲突3.1长节点冲突首先对于scaffold图中节点长度大于等于μis+3*σis的节点称为长节点,剩余的节点为短节点。由于一个双端读数跨过长度大于μis+3*σis的区间的概率非常小,所以一个长节点的5’端只能和一个其它长节点相连接。如果一个长节点的5’端边中有多个边都指向其它长节点,则只保留权重最大的边,剩余的指向长节点的边删除。3’端做同样的处理。3.2方向冲突在scaffold图中遍历路径时,当从一个节点的5’端进入该节点时,必须从该节点的3’端出来访问下一个节点。设定Oi∈{0,1},代表Ci的方向,0代表正向,1代表反向。在scaffold图中,如果一条边是从一个contig的5’端到另一个contig的3’端,或者从一个contig的3’端到另一个contig的5’端,则该边约束两个contig具有相同的方向。否则,该边约束两个contig具有相反的方向。当一个节点的方向确定了,则基于scaffold图中的路径,其他节点的方向也能确定。但是,scaffold图中往往存在一些方向冲突,即某一节点通过不同的路径往往推导得到不同的方向。本方法利用整数线性规划发现方向冲突,并通过删除掉一些边使scaffold图中不包含方向冲突。本方法采用迭代的策略发现方向冲突。在每次迭代时,只考虑权重大于θ的边。初始设置θ=0.9,并且构建一个边集合Ω1,并设置为空。首先选择scaffold图中所有大于θ的边。每条边都代表两个节点之间方向的约束条件。如果Ci和Cj之间的边不存在于集合Ω,并且Ci和Cj在不同的方向上,则约束条件为:Oi+Oj≤2-ηij-Oi-Oj≤-ηij]]>如果Ci和Cj在同一个方向上,则约束条件为:Oi-Oj≤1-ηij-Oi+Oj≤1-ηij]]>其中,ηij是一个松弛变量,ηij∈{0,1};如果Oi和Oj违反了该边的约束,则ηij肯定等于0;如果Ci和Cj之间的边已经在集合Ω1中,则它们之间方向约束是不能违反的,即如果Ci和Cj在不同的方向上,则:-Oi!=Oj如果Ci和Cj在同一个方向上,则:Oi=Oj优化目标函数为:MAX(∑wij·ηij)其中,wij表示Ci和Cj之间的边的权重;MAX(∑wij·ηij)表示求使得函数值最大的ηij取值;该目标函数中只考虑没有存在于集合Ω1中的边,该目标函数能够保证如果Oi和Oj符合对应边规定的约束,ηij等于1。在该次迭代完成后,如果ηij等于1,则对应的边添加到集合Ω1中。θ从0.9到0.1,每次迭代时θ=θ-0.1。当结束迭代后,每个节点都被分配了一个方向,而不存在于集合Ω1中的边被认为是造成方向冲突的边,并删除。3.3顺序冲突在scaffold图中,每条边也规定了两个contig之间的距离。本方法通过给每个contig分配起始位置,使分配的起始位置尽量符合每条边规定的contig之间的距离。在最终的起始位置分配方案中,两个contig之间的距离,有两个值,一个是通过分配给contig的起始位置计算得到的距离,和对应边规定的距离。如果这两个距离相差太大,则认为该边造成顺序冲突,删除掉该边。本方法在解决contig顺序冲突也采用和解决方向冲突相同的迭代方式。在每次迭代时,只考虑权重大于θ的边。Xi∈[0,C],代表Ci在正向上的起始位置坐标。由于在上一步解决方向冲突时,已经计算得到每个contig的方向,对于方向为0的contig,该起始位置就是5’端的位置,对于方向为1的contig,该起始位置就是3’端的位置。Xi是一个整数。C是所有节点长度之和的两倍。初始设置θ=0.9,并且构建一个边集合Ω2,并设置为空。选出所有权值大于等于θ的边,如果Ci和Cj之间的边权值大于θ,并且该边不存在集合Ω2中,则建立顺序约束条件为:Xj-Xi-leni-Gij≤C(1-Φij)Xi-Xj+leni+Gij≤C(1-Φij)]]>如果Ci和Cj之间的边已经存在集合Ω2中,则建立顺序约束条件为:Xi-Xj-leni<=μis+3*σisXi-Xj-leni>0]]>优化目标函数为:MAX(∑wij·Φij)其中,Xi,Xj∈[0,C],分别表示给节点Ci和Cj分配的在正向上的起始位置坐标,Xi,Xj为整数,且Xj≥Xi;C是所有节点长度之和的两倍;Φij∈[0,1],是一个松弛变量,用来反映相应边规定的Ci和Cj之间的距离和通过分配位置坐标得到的距离之间的差距。这种差距越小,则Φij的值越靠近1。当完成本次迭代后,若Ci和Cj之间的边没有在集合Ω2中,且:|Xj-Xi-leni-Gij|≤3*σis则Ci和Cj之间的边添加到集合Ω2中。θ从0.9到0.1,每次迭代时θ=θ-0.1。经过所有的迭代后,不存在于集合Ω2中的边被认为是造成位置冲突的边,并删除。四、生成scaffold虽然,在解决顺序冲突时,每个contig都被分配了一个位置,但是根据分配得到的起始位置,多个contig之间可能存在重叠区域。所以,本方法采用另外一种策略完成scaffold的构建,即线性化scaffold图中的节点。首先,本方法只考虑长节点和它们之间的边,并抽取出相应的简单路径作为初始的scaffold。其次,如果某一个短节点和一个scaffold中两个紧邻的长节点都存在边,则该短节点插入到该scaffold中。如果在两个长节点中,存在多个短节点和它们相连,则根据短节点和长节点的距离进行一个排序,然后把短节点插入到长节点之间。最后,本方法从scaffold的双端节点分别进行扩展。基于scaffold图,本方法采用深度优先算法进行扩展scaffold,如果不存在可扩展的节点或者遇到其它scaffold,则停止扩展,并合并遇到的其它scaffold。如果存在多个双端读数数据集合,则本方法首先从insertsize比较小的数据集合开始scaffolding,并以输出的scaffold作为下一个数据集合的contig进行scaffolding。如图4所示为本发明一实施例提取scaffold图中scaffold,其中(a)表示一个scaffold图,每个节点代表一个contig,其中深色的节点为长节点,其余节点为短节点。边上的数值为两个相连节点之间的距离。(b)表示首先抽取出长节点的简单路径。共有两个scaffold:ABC和DE。(c)把短节点插入到长节点中间。由于F,G两个节点都和长节点A,B相连,并且F离A更近,所以形成新的scaffold:AFGBC。(d)扩展scaffold:AFGBC,根据广度优先算法,首先选择距离起始节点最近的节点进行访问,当遇到其他scaffold时,两个scaffold合并。最终形成一个新的scaffold:AFGBCJHKIDE,每个节点是一个contig,并且每两个相邻节点之间的距离也已经确定,所以该scaffold就是一条更长的碱基序列,其中中间的空白区域用‘N’来代表。五、实验验证5.1数据集和评价指标为了验证本方法的有效性,本方法在四个物种的由Illumina技术得到的真实测序数据上进行了测试,并和目前流行的其它十一种scaffolding方法进行比较分析。这四种物种包括:金黄色酿脓葡萄球菌(S.aureus),红假单胞菌(R.sphaeroides),人类14号染色体(Human14)和恶性疟原虫(P.falciparum)。前两个数据集合只包含一个双端读数集合。后两个数据集合各包含两个双端读数集合,这两个集合具有不同的insertsize。contig是由拼接工具Velvet产生,这是由于Velvet产生的contig个数要多一些,这更有利于评价scaffolding方法。表1四组真实数据集为了评价scaffolding方法的准确性,本方法首先利用四个指标进行评价:(1)正确连接:两个contig被分配了正确的方向,并且它们之间的距离符合实际距离。(2)错误连接:两个contig被分配了错误的方向,或者并它们之间的距离不符合实际距离,或者在不同的染色体上。(3)遗漏连接:两个contig被正确连接,但是它们中间遗漏了另一个contig。(4)丢失的contig:contig没有出现在最终的scaffolding结果中。这四个指标赋予了不同的权重,分别为1,1,2,0.5。根据以上四个指标,本方法利用F-score作为综合评价指标。定义PC为实际存在可以正确连接的个数。TPC是在scaffolding结果中存在的正确连接个数。FPC为错误连接,遗漏连接和丢失的contig个数三个指标乘以权重之和。TPR=TPCPC]]>PPV=TPCTPC+FPC]]>F-score=2*TPR*PPVTPR*PPV]]>5.2scaffolding方法之间的比较本方法和其它十一种比较流行的scaffolding方法进行了比较,这十一种scaffolding方法包括:Bambus2,MIP,OPERA,SCARPA,SOPRA,SSPACE,ABYSS,SOAP2,SGA,BESST,ScaffoldMatch。由于不同比对工具产生的比对结果有差异,所以本方法利用三种不同的比对工具bowtie,bowtie2和bwa,分别把双端读数比对到contig集合上。其中bowtie用两种不同的参数,一种是比对要求完全比对(使用-v0),另一种比对要求没有匹配上的碱基最多为3(使用-v3)。每种比对文件都产生一个scaffolding结果,只选择最优的结果作为最终结果。本方法命名为OPSS(OPtimizingScaffold图forScaffolding)。5.2.1、S.aureus的scaffolding结果S.aureus这个物种的基因组长度并不大,所以Velvet产生的contig数目并不多,只有170个contig。通过表2可以看出,本方法可以产生更多正确连接,并且可以接受的错误连接,并且本方法的F-score值是最高的。虽然SOAP2和ScaffoldMatch两种方法也得到了很多正确的连接,但是它们也产生了很多的错误连接。5.2.2、S.aureus的scaffolding结果R.sphaeroides这个物种的基因组长度已经达到4.6百万碱基,Velvet产生的contig数目达到577。通过表2可以看出,虽然本方法的F-score和正确连接数目都比其它方法高,但是本方法产生了比较多的错误连接。在本数据集上,SOAP2和ScaffoldMatch两种方法也得到了很多的正确的连接。5.2.3、P.falciparum的scaffolding结果P.falciparum的基因组长度比较长,并且Velvet产生的contig数目也比较多,达到9318。本方法首先分别对该物种的两个双端读数数据集合进行scaffolding,得到结果列在表3中。对于短insertsize的数据集合,本方法得到了最优的F-score值。对于长insertsize的数据集合,SOAP2得到了最优的F-score值,MIP得到了最多的正确连接。当两个数据集合一起进行scaffolding时,其结果列在表5中。本方法仍然得到了最优的F-score值。5.2.4、Human14的scaffolding结果Human14的基因组长度达到了8.8千万碱基,而且Velvet产生的contig数据也19936。由于Human14有两个数据集合,首先分别对两个数据集合进行scaffolding,结果列在表4中。对于短insertsize数据集,本方法仍然得到了最优的F-score,但是SOAP2也得到了很相似的F-score值。对于长insertsize数据集,所有的方法都没有得到令人满意的结果,其主要原因是该数据集的覆盖度太低。表5中也列出了两个数据集合同时scaffolding的结果。表2S.aureus和R.sphaeroides的scaffolding结果表3对P.falciparum两个数据集合分别scaffolding的结果表4对Human14两个数据集合分别scaffolding的结果表5P.falciparum两个数据集合一起scaffolding的结果和Human14两个数据集合一起scaffolding的结果当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1