一种基于Kinect的手部动作捕捉方法与流程
本发明涉及虚拟现实解析技术领域,尤其是一种基于Kinect的手部动作捕捉方法。
背景技术:
在传统的手部动作捕捉方法中,系统的设计者自行设计手势的开始动作来划分手部的动作过程的开始、稳定、结束三个阶段,比如做L型的直线等。但这些方法的缺陷在于要求用户在每个手势前都要做一个附加动作使动作捕捉变得繁琐且不友好。
技术实现要素:
本发明提出的一种基于Kinect的手部动作捕捉方法,大大提高动作捕捉的正确率及速度,满足实时捕捉的要求。
本发明的技术方案是这样实现的:
一种基于Kinect的手部动作捕捉方法,手部的动作过程分为开始、稳定、结束三个阶段,当处于稳定阶段时手是保持不变的,而在开始和结束阶段都有手的运动,具体捕捉过程包括以下步骤:
步骤1:打开Kinect的彩色和深度视频流,对彩色视频流做帧差,对得到的差分图做连通域分析,参照对应的深度图,选出这些连通域中平均深度值最小的区域minROI,并记录该区域所在的位置和平均深度;
步骤2:当连续三帧检测到的minROI,其平均深度值变化不大,而位置在水平方向有明显的平移运动时就认为此时用户在做水平方向的快速移动,即开启了识别系统,令star t=1并把此时minROI的平均深度值deepTH作为分割阈值,在深度图中分割出手部区域,完成本次手势的精确分割;
步骤3:将分割出的手部区域中的肤色像素建立肤色模型,并将deepTH扩大一定的距离后得到segTH,(0,segTH)的深度区间就是下次手势出现的候选区域;
步骤4:当检测到start=1且gesture=-1时,对深度图中(0,segTH)范围内的像素值建立深度直方图,对于驱动小块噪声后的直方图,安装深度值从小到大的顺序扫描,把第一次出现高度锐减的直方块所在的深度值作为分隔阈值来分割深度图形,选取其中最大的面积区域作为感兴趣区域ROI,对ROI内的每个像素,判断是否为肤色,若属于辐射的像素个数大于某一阈值时确定此时分隔出的前景为用户手势,令gesture=-1,否则认为此帧中没有用户手势,重置start=0,gesture=0,继续循环步骤4。
本发明通过提供的基于Kinect的手部动作捕捉方法,其有益效果在于:利用深度直方图,自动确定分割阈值,把彩色图像中的颜色信息作为判断分割出的区域是否为手势的辅助手段,降低分割错误的概率,利用实时视频中前后两次手势直接的联系,把每次的分割深度限定在某一范围内,分割深度范围之外的背景对分割效果就不产生任何影响,对复杂的背景有更大的适应性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
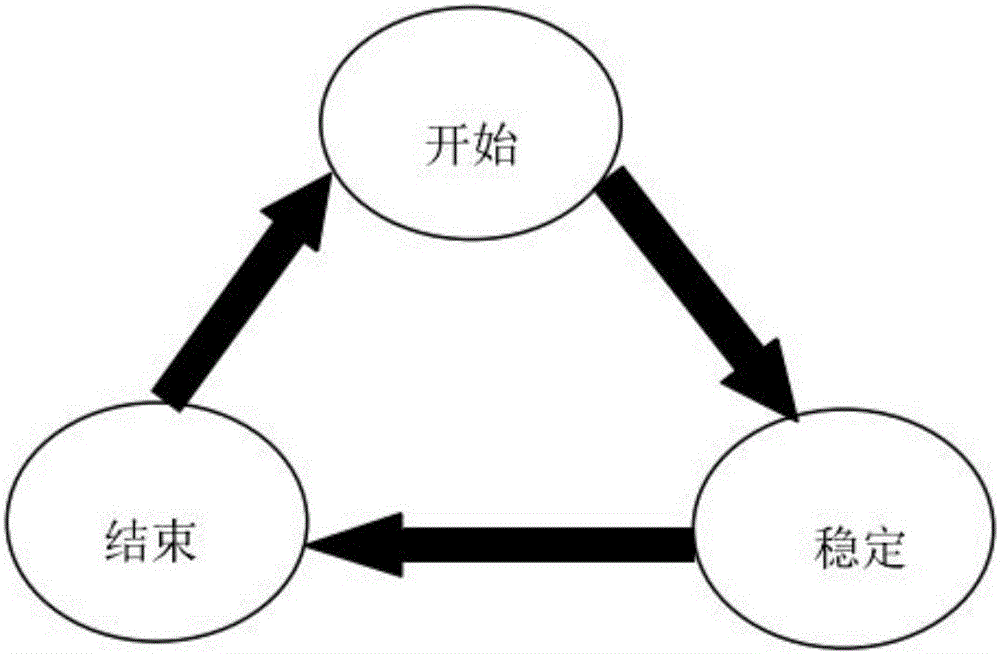
图1为手部动作的三个阶段转换图;
图2为手部动作捕捉流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人 员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例的基于Kinect的手部动作捕捉方法,在实施时需要基于以下两点要求:1、要求用户做手势时,手要在身体之前,并且要与身体有一定的间隔;2、要求手与Kinect之间不能有其他物体遮挡,且距离在1~2米之间为最佳。在实际应用中,这两点要求是合理的并且易于实现。
本实施例的基本思想是:根据手和背景通Kinect的距离不同,利用深度直方图来分割出手势,同时利用颜色信息来确定分割出的前景是否为手势,依次来确保分割的正确率。在实时虚拟现实系统中,为了精确分割出第一个手势以便于我们用在这次手势所包含的信息来建立更具有鲁棒性的手势识别,这里我们认为的规定识别启动方式为:用户收在水平方向的快速移动。
在实际情况中,用户手部的动作过程分为开始、稳定、结束三个阶段,开始,即抬起手部到维持某种手势的过程;稳定,即维持某种静态手势的阶段;结束,即手势完成放下手部的过程。三个阶段的转换如图1所示。
本实施例中,采用标识start、gesture来区分这三个阶段,start,标识手势的开始,避免对同一次手势多次重复采集和识别;gesture,标识手势的稳定,只有在这个阶段采集到的手势才是准确的手势。
在自然状态下,当处于稳定阶段时手是保持不变的,而在开始和结束阶段都有手的运动,故将手部动作划分这三个阶段:当前后两帧帧差图中有运动物体时则令start=1;当start=1且又检测到帧差图没有运动物体时令gesture=-1,此时可能为手势的稳定阶段也可能只是背景中其他的运动物体引发了此状态,只有当此帧分割出的前景区域中,肤色像素个数大于某阈值时,才确定此帧为手势稳定的关键帧并令gesture=1,否则用此帧来更新背景,并重置start=0,gesture=0,继续检测视频流。
如图2所示,具体捕捉过程包括以下步骤:
步骤1:打开Kinect的彩色和深度视频流,对彩色视频流做帧差,对得到的差分图做连通域分析,参照对应的深度图,选出这些连通域中平均深度值最小的区域minROI,并记录该区域所在的位置和平均深度;
步骤2:当连续三帧检测到的minROI,其平均深度值变化不大,而位置在水平方向有明显的平移运动时就认为此时用户在做水平方向的快速移动,即开启了识别系统,令star t=1并把此时minROI的平均深度值deepTH作为分割阈值,在深度图中分割出手部区域,完成本次手势的精确分割;
步骤3:将分割出的手部区域中的肤色像素建立肤色模型,并将deepTH扩大一定的距离后得到segTH,(0,segTH)的深度区间就是下次手势出现的候选区域;
步骤4:当检测到start=1且gesture=-1时,对深度图中(0,segTH)范围内的像素值建立深度直方图,对于驱动小块噪声后的直方图,安装深度值从小到大的顺序扫描,把第一次出现高度锐减的直方块所在的深度值作为分隔阈值来分割深度图形,选取其中最大的面积区域作为感兴趣区域ROI,对ROI内的每个像素,判断是否为肤色,若属于辐射的像素个数大于某一阈值时确定此时分隔出的前景为用户手势,令gesture=-1,否则认为此帧中没有用户手势,重置start=0,gesture=0,继续循环步骤4。
本实施例的基于Kinect的手部动作捕捉方法,利用深度直方图,自动确定分割阈值,把彩色图像中的颜色信息作为判断分割出的区域是否为手势的辅助手段,降低分割错误的概率,利用实时视频中前后两次手势直接的联系,把每次的分割深度限定在某一范围内,分割深度范围之外的背景对分割效果就不产生任何影响,对复杂的背景有更大的适应性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!