一种基于稀疏非线性子空间迁移的图像分类方法与流程
本发明属于一种图像分类方法,具体涉及一种基于稀疏非线性子空间迁移的图像分类方法。
背景技术:
:一般来说,在传感器没有发生漂移时采集到的数据称为源域,在使用一段时间后传感器发生漂移后获得的数据称为目标域。在图像领域,可以把物体的任意一种姿态称为源域,将受到外界条件改变(例如角度、光线强弱、背景色彩改变等)得到的另一种姿态称为目标域,图像分类的基本任务就是能够将这些处于不同状态下的同类物体寻找出来。为了描述简便,本发明规定:“S”表示源域,“T”表示目标域;源域训练数据记为目标域训练数据记为其中D代表维数,NS和NT是两个域中训练样本的数目;和表示目标域中少数标记的和大量未标记的数据;表示将源数据和目标数据的原始空间映射到潜在空间的带有维数d的基础变换;z表示Xs和XT之间的稀疏重建矩阵;1n表示长度为n的非零列向量;I表示单位矩阵;‖·‖0代表一个向量非零元素的数目;‖·‖1表示L1-范数;‖·‖F表示矩阵的Frobenius范数;[X]i表示X的第i列。在本发明中,矩阵采用大写黑体,向量为小写黑体,变量为斜体。M.Shao,D.Kit,andY.Fu,“GeneralizedTransferSubspaceLearningThroughLow-RankConstraint,”Int.J.Comput.Vis.,vol.109,pp.74-93,2014.(M.Shao,D.Kit和Y.Fu于2014年发表在《国际计算机视觉期刊》中的109卷第74-93页的论文《低秩约束条件下的广义转移子空间学习》),提供了一种基于低秩表示的子空间迁移方法(简称LTSL),LTSL方法的数据转换原理图如图1所示:源域训练数据XS和目标域训练数据XT经训练获得一个转换基W,源域数据和目标域数据经转换基W映射到子空间(子空间指的是通过投影,实现高维特征向低维空间的映射,尽量保证不丢失信息,这是一种常用的降维思想,在这个子空间训练数据时,可以有效防止过拟合),在子空间内,源数据WXS通过低秩Z可以使得和目标域数据WXT分布一致,即同类经过映射更靠近,从而实现分类。存在的子空间学习方法(例如,主成分分析(PCA),线性判别分析(LDA),局部保持投影(LPP)等),被用来学习子空间投影W,在子空间中,源数据WXS通过低秩表示(LRR)用来重建目标数据WXT(因目标数据WXT是存在的,WXS是通过低秩表示来逼近的)。LTSL解决子空间转移问题,是通过如下最小化目标函数实现的(即:找到一组W,Z,E的值,使得该式子的值达到最小):s.t.WTXT=WTXSZ+E,WTU2W=I式中,rank(.)表示矩阵的秩,‖E‖2,1表示l2,1-范数,并且λ1和λ2是正则化系数。表达式‖E‖2,1是用来激励E的误差列为0,因此噪声或异常源域在适应的过程中可以被删除。然而rank(Z)的最小值往往可以的用低等级结构找到一个重建系数矩阵。F(W,Xs)是一个广义的子空间学习函数,它可写成Tr(WTU1W),U1和U2是由子空间学习模式来选择的,学习模式如PCA或LDA等。W是一种子空间学习表示形式,学习模式有PCA或LDA;Z是低秩表示。当子空间学习模式选定时,W固定,采用非精确的增广拉格朗日乘子法求解上式以获得Z、E。该基于低秩表示方法,对知识适应性提供了一个较完整的理论和空间分析,但只在满足子空间独立并且具有充足数据的条件下,LTSL的性能表现良好。实际上,子空间独立和数据量充足是很难满足的,所以基于低秩表示的子空间迁移方法的准确度较低。另外,LTSL方法只适用于线性数据的转换,但对非线性的数据不能进行处理,而本方法发明正是针对于非线性数据。技术实现要素:本发明所要解决的技术问题就是提供一种基于稀疏非线性子空间迁移的图像分类方法,它能提高图像数据在子空间迁移的准确度,且能适用于非线性数据的转换。本发明所要解决的技术问题是通过这样的技术方案实现的,它包括有以下步骤:步骤1、输入源域样本和目标域样本计算原始数据XS1是源域的第一个样本、是源域的第NS个样本、XT1是目标域的第一个样本、是目标域的第NT个样本;步骤2,计算KT和K由式和分别求解出KT和K;是原始数据X投影到希尔伯特空间的数据;步骤3,求出K的特征值分解由式K=VSVT求解出K的特征值分解;V为特征向量构成的矩阵,S的对角线上元素为特征向量所对应的特征值;步骤4,初始化特征向量Φ由式Φ:=V(:,v)取V的前d个最大特征值所对应的特征向量,式中v为V的前d个最大特征值所对应的特征向量;步骤5,更新Z将Φ固定,使用ADMM方法,更新以下式(8)中的Z:minZ||Z||1+λ1||ΦTKT-ΦTKZ||F2---(8)]]>s.t.1NS+NTTZ=1NTT]]>式(8)中,Z为稀疏矩阵,λ1表示权衡参数,表示长度为NS+NT的非零列向量,表示长度为NT的非零列向量;步骤6,更新Φ将Z固定,使用特征值分解的方法,更新以下式(13)中的Φ:minΦλ1||ΦTKT-ΦTKZ||F2+λ2Tr((I-ΦΦTK)TK(I-ΦΦTK))---(13)]]>s.t.ΦTKΦ=I步骤7,检查收敛性情况若仍然不收敛,则重复步骤5和步骤6;若收敛,则输出Φ和Z的值;步骤8,由得映射P*,计算源域数据XS映射到预设子空间的值MS,步骤9,利用映射P*,计算标记的目标训练数据XTl映射到预设子空间的值MTl,表示非线性XS,投影到希尔伯特空间即为然后通过稀疏矩阵Z向目标域转换;步骤10,计算未被标记的目标测试数据XTu映射到预设子空间的值MTu,步骤11,基于标记的训练数据[MS,MTl]和它们对应的标记,利用二范数正则最小二乘方法训练一个分类器W;步骤12,通过计算判决函数对未被标记的目标测试数据进行类别判别。本发明的技术效果是:提高了图像数据在预设子空间迁移的准确度;由于本发明首先通过核方法把数据从原始空间映射到再生的核希尔伯特空间,因此能适用于非线性数据的转换。附图说明本发明的附图说明如下:图1为
背景技术:
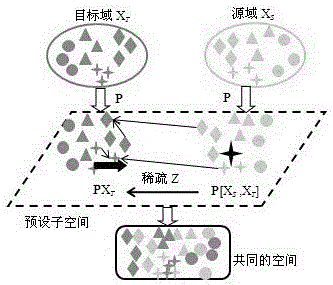
的LTSL的数据转换原理图;图2为本发明的数据转换原理图;图3为数据验证的源域和目标域的三维分布图;图4为图3的数据经本发明转换后的二维预设子空间分布图;图5为一个受试者的样本图像;图6为本发明应用于对图5中微笑表情上的姿态调整结果图。具体实施方式下面结合附图和实施例对本发明作进一步说明:本发明首先通过核方法把数据从原始空间映射到再生的核希尔伯特空间(RKHS),再通过如图2所示的转换,在核希尔伯特空间,由一个预先定义的基础转换P,将目标域训练数据XT通过基础转换P映射到预设子空间得到目标数据PXT,将源域训练数据XS通过基础转换P映射到预设子空间得到PXS,由于本发明通过源域和目标域数据P[XS,XT]来对目标数据进行重建,因此把P[XS,XT]又统一称为源域数据,然后利用源域数据P[XS,XT]通过稀疏矩阵Z进行转换,与PXT在预设子空间内共享分布。本发明的原理是:LSDT(线性)转换与NLSDT(非线性)转换的区别在于:由于在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,有可能变为线性可分的,但是高维空间又会导致维数灾难,因此采用核的方法,先将原始数据投影到希尔伯特空间上,降低维数就可避免维数灾难,即X投影到(X是原始数据,是X投影到希尔伯特空间后的数据)。首先定义核矩阵并且其中κ是核函数,采用高斯核函数,xi、xj为原始数据,分别为原始数据xi、xj投影到希尔伯特空间的数据。源域数据P[XS,XT]通过稀疏矩阵Z进行转换,从而与目标域数据PXT在预设子空间内共享分布,那么稀疏非线性子空间迁移优化的数学模型为式(1)中,T0是稀疏水平;为预设子空间的目标数据,为预设子空间的源域数据;Z为使预设子空间内源域和目标域数据共享分布的稀疏矩阵。因为基于L0范数的优化是非凸问题,因此本发明模型使用了该规范的凸逼近,即L1范数。为了使获得的P能够确保投影不使数据发生扭曲,并且可以保持很多有用信息,那么有如下表达式,将式(1)与式(2)式结合,最后可以表达为:式(3)中,P的行必须是正交的,并且必须归一化,使得PPT=I,I是单位矩阵,以此避免退化。此外,假定(表示长度为NS+NT的非零列向量,表示长度为NT的非零列向量),使得源域数据和目标域数据在联合的仿射预设子空间,而非线性预设子空间(仿射预设子空间和线性预设子空间的区别在于是否有选定的原点。仿射预设子空间中的任何两点的地位等价,而线性预设子空间的原点是个特殊的点),λ1和λ2则表示权衡参数(即
背景技术:
的正则化系数λ1和λ2,表示了每项的权重)。为了简化,令那么目标函数(3)可以写为:目标函数(3)或(4)中,P的解有很多,即解不唯一。基础变换P的一种求解方法如下:存在一个最优解P*,它可以直观地表示为在情况下,原始数据和目标数据的线性组合,表示形式如下:式(5)中,φ为特征向量,,φT、分别为φ和的转置矩阵。结合式(4)与式(5),目标函数可以表示为:令那么前述式(3)可以表示如下:minZ,Φ||z||1+λ1||ΦTKT-ΦTKZ||F2+λ2Tr((I-ΦΦTK)TK(I-ΦΦTK))---(7)]]>s.t.ΦTKΦ=I,1NS+NTTZ=1NTT]]>从式(7)可以看出:式中涉及两个变量Z和Φ。为了得到式(7)的最小解,可以采用固定一个变量,而改变另一个变量来解决这个问题。因此,包括以下2个主要步骤:第一、更新稀疏矩阵(Z)为了得到Z,可以固定Φ,那么式(7)可以表示为:minZ||Z||1+λ1||ΦTKT-ΦTKZ||F2s.t.1NS+NTTZ=1NTT---(8)]]>这是一个典型的稀疏套索(Lasso)优化问题,可以采用交替方向乘子法(ADMM)有效地解决。引入辅助变量L,式(8)可以改写为:minZ,L||Z||1+λ1||ΦTKT-ΦTKL||F2s.t.L=Z,1NS+NTTL=1NTT---(9)]]>式(9)的增强拉格朗日函数可以表示为:J(Z,L)=||Z||1+μ12||ΦTKT-ΦTKL||F2+<YA,L-Z>+<YB,1NS+NTTL-1NTT>+μ12(||L-Z||F2+||1NS+NTTL-1NTT||22)---(10)]]>式(10)中,YA和YB分别表示拉格朗日乘子,λ1=μ1/2;λ1和μ1均为系数变量,可以随意选择,取λ1=μ1/2只是为了求导得到(11)式的时候方便(二范数求导刚好有2与1/2刚好约掉);μ2是用增广拉格朗日乘子法求解时的系数。为了解式(9)的L,现固定Z,并且使式(10)的偏导为0,可以获得L的表达式如下:L=(μ1KTΦΦTK+μ2I+μ21NS+NT1NS+NTT)-1(μ1KTΦΦTKT-YA-1NS+NTYB+μ2Z+μ21NS+NT1NTT)---(11)]]>固定L,那么Z可以通过以下式子求解:minZ||Z||1+μ22||L-Z||F2+<YA,L-Z>∝minZ||Z||1+μ22(||L-Z||F2+μ22<YA,L-Z>)∝minZ||Z||1+μ22||Z-(L+YAμ2)||F2---(12)]]>因此,采用ADMM方法,依据式(8)求解Z的步骤如下:步骤1),初始化参数令Z,YA,YB均为0,μ2为λ1,ρ=1.1和maxμ=106;其中YA和YB分别表示拉格朗日乘子,λ1和λ2则表示权衡参数;步骤2),更新L当不收敛的时候固定Z,通过利用下式对L进行求解:L=(μKTΦΦTK+μ2I+μ21NS+NT1NS+NTT)-1(μKTΦΦTKT-YA-1NS+NTYB+μ2Z+μ21NS+NT1NTT)]]>式中,L为辅助变量,λ1=μ1/2,μ2是用增广拉格朗日乘子法求解时的系数;步骤3),更新Z当不收敛的时候固定L,通过下式对Z进行求解:minZ||Z||1+μ22||Z-(L+YAμ2)||F2]]>步骤4),更新拉格朗日乘子根据步骤2)和步骤3)更新得到的L和Z,代入下式,YA=YA+μ2(L-Z),YB=YB+μ2(1TL-1T)得到更新后的乘法器;上述式(10)中,YA和YB分别表示拉格朗日乘子,由于这是一个典型的稀疏套索优化问题,因此采用交替方向乘子法(ADMM),因为式(10)有拉格朗日乘子,因此名称又叫做乘法器;步骤5),更新参数μ2μ2取μ2ρ和maxμ中的最小值(μ2ρ和maxμ是设定的值,步骤1中初始化参数部分已补充它们的设定值);步骤6),检查收敛情况若仍然不收敛,则重复步骤2)至步骤5);若收敛,则输出Z。第二、更新Φ为了解出Φ,通过固定Z,式(7)可以被写为:式(13)的目标函数被扩展如下:式(14)中,令ΦTKΦ=I,则ΦΦTKΦΦT=QKQT=ΦΦT=Q,那么目标函数可以简化为:Tr((λ1(K-1KT-Z)(K-1KT-Z)T-λ2I)KTQTK)(15)根据式子K=VSVT的特征值分解,其中V为特征向量,S对角线上元素为特征向量对应的特征值,得:KTQTK=VS12ΩΩTS12VT]]>式中,特征函数(15)化解为:Tr(ΩTS12VT(λ1(K-1KT-Z)(K-1KT-Z)T-λ2I)VS12Ω)=Tr(ΩTΘΩ)---(16)]]>式(16)中,并且ΩTΩ=ΦTVSVTΦ=ΦTKΦ=I最后,式(13)改写为:Ω*=argminΩTr(ΩTΘΩ),s.t.ΩTΩ=I---(17)]]>最优解Ω*是通过关于Θ的最小特征值的特征向量l来获得的。Ω*是通过和VVT=I所求得的,Φ*的最优能够被表示为:Φ*=VS-12Ω*---(18)]]>因此,依据式(13)求解Φ的步骤如下:步骤(1),求K的特征值分解由K=VSVT求出K的特征值分解;其中K=XTX,V为特征向量,S对角线上元素为特征向量对应的特征值;步骤(2),由下式求解出Θ:Θ=S12VT(λ1(K-1KT-Z)(K-1KT-Z)T-λ2I)VS12]]>步骤(3),求出Θ的特征值分解由式Θ=UΣUT求解出Θ的特征值分解,U是Θ的特征向量,Σ为一个对角阵,其对角上的元素为特征向量对应的特征值;步骤(4),求解Ω通过Ω=U(:,U)来求解Ω,该式是将Θ进行特征分解后,取U的前d个最小特征值对应的特征向量,式中U为U的前d个最小特征值所对应的特征向量;d的范围是1~U的所有特征值个数,以U中所有特征值依次循环,取实验效果好的那些值;步骤(5),求解Φ由式求解出Φ。综合上述内容,得本发明的基于稀疏非线性子空间迁移的图像分类方法,包括以下步骤:步骤1、输入源域样本和目标域样本计算XS1是源域的第一个样本、是源域的第NS个样本、XT1是目标域的第一个样本、是目标域的第NT个样本;步骤2,计算KT和K由式和分别求解出KT和K;是原始数据X投影到希尔伯特空间的数据;步骤3,求出K的特征值分解由式K=VSVT求解出K的特征值分解;V为特征向量所组成的矩阵,S对角线上元素为特征向量对应的特征值;步骤4,初始化Φ由式Φ:=V(:,v)取V的前d个最大特征值所对应的特征向量,式中v为V的前d个最大特征值所对应的特征向量;d的范围是1~(V的所有特征值个数),以V中所有特征值依次循环,取实验效果好的那些值;步骤5,更新Z将Φ固定,使用ADMM方法,更新以下式(8)中的Z:minZ||Z||1+λ1||ΦTKT-ΦTKZ||F2---(8)]]>s.t.1NS+NTTZ=1NTT]]>步骤6,更新Φ将Z固定,使用特征值分解的方法,更新以下式(13)中的Φ:minΦλ1||ΦTKT-ΦTKZ||F2+λ2Tr((I-ΦΦTK)TK(I-ΦΦTK))---(13)]]>s.t.ΦTKΦ=I步骤7,检查收敛性情况若仍然不收敛,则重复步骤5和步骤6;若收敛,则输出Φ和Z的值;步骤8,由得映射P*,计算源域数据XS映射到预设子空间的值MS,步骤9,利用映射P*,计算标记的目标训练数据XTl映射到预设子空间的值MTl,表示非线性XS,投影到希尔伯特空间即为经P后通过稀疏矩阵Z向目标域转换;步骤10,计算未被标记的目标测试数据XTu映射到预设子空间的值MTu,设置标记的目标训练数据XTl和未被标记的目标测试数据XTu,是因为要通过源域数据XS和标记的目标域数据XTl训练出一个分类器W,然后使用未被标记的目标域数据XTu进行测试,判断步骤11训练出的分类器W的好坏,以检验本发明的优劣;步骤11,基于标记的训练数据[MS,MTl]和它们对应的标记,利用二范数正则最小二乘方法训练一个分类器W;步骤12,通过计算判决函数对未被标记的目标测试数据进行类别判别。实验验证一、数据验证如图3所示,针对预设子空间阵列所产生的数据,通过不同方式的高斯分布和协方差矩阵,获得少数标记的目标数据和多数未标记的目标数据三维分布(目标数据是随机产生的满足高斯分布的数据),源域中有两类数据,每类数据包含50个样本,且容易在源域中找到两类数据的决策边界;在目标域中也有两类数据,每类有5个标记的样本和50个未标记的样本。从图3中可以清楚地看到:1、同一类的数据点在源域和目标域中有不同的分布;2、源域的分类超平面不适合目标域的决策边界(决策边界指将不同类数据分开的线或平面)。利用本发明的稀疏Z子空间迁移,经过投影和重建后,得二维预设子空间的源数据和目标数据,如图4所示,源数据和目标数据之间的空间错位率有所降低,并且这两类之间的决策边界清晰,很容易找到一种分类器实现分类,所以使用本方法发明进行数据分类是可行的、有效的。二、物体识别CMUMulti-PIE人脸数据集是一个公开数据集,共包含337个受试者的综合人脸数据集,其中的图像通过15个姿势,20种照明,6种表达,4个不同的阶段实现捕获。为了得到想要的结果,在实验中在阶段1和阶段2分别选择了前60名受试者,每个受试者的7种表情图像。如图5所示:阶段1为第一行,面部带有一般表情;阶段2为第二行,受试者还带有微笑。在这个实验中,四种实验设置如下:·设置1:每个受试者的红色矩形正面表情和蓝色矩形极端姿态(60°角)分别用来作为源域和目标域的训练数据,剩下的表情即被用作探针面。·设置2:参照设置1,进行相同配置。·设置1+2:将设置1和2中的两种正面表情和两种极端60°姿态表情作为训练数据,剩下的表情被用作探针面。·交叉设置:将设置1中每个受试者的一般表情作为源域,将设置2每个受试者的微笑表情作为目标域,以此适应表情的变化。由于三维旋转脸的高度非线性化,使得姿态对准极具挑战性。图6为本发明应用于阶段2的微笑表情上的姿态调整结果图,它将图5中正面表情作为源数据,后边极端姿态(60°角)用来作为目标数据。从图6我们可以看出:由于残留(噪声)的去除,目标人脸对准姿态良好。采用本非线性方法发明进行人脸识别,其识别准确率与LTSL相对比,其结果见表1。表1.针对人脸姿态识别的识别准确率比任务源域目标域LTSL-PCALTSL-LDA本发明设置1正面60度的角度55.756.063.7设置2正面60度的角度58.760.770.7设置1+2正面60度的角度57.860.767.5交叉设置设置1设置296.796.799.4本方法为非线性方法,由于原始数据非线性,将其投影到希尔伯特空间上再进行处理,从而大大地提高识别准确率。通过对比线性方法LTSL,由表1可以看出:本方法发明比线性方法LTSL的识别效果好。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1