基于人工智能的查询信息处理方法和装置与流程
本发明涉及信息处理技术领域,尤其涉及一种基于人工智能的查询信息处理方法和装置。
背景技术:
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语音识别、图像识别、自然语言处理和专家系统等。其中,人工智能最重要的方面就是语音识别技术。
随着各种智能交互产品的出现,在检索场景下,用户输入的查询语句越来越多元化,越来越随性,在检索时,输入的查询语句中包含一些与检索意图无关的检索词。比如,用户通常会在输入查询语句时,加入个人口语化的表述等。
然而,相关技术中,检索系统基于输入的检索词进行检索,因而检索结果容易受到查询语句中,与检索意图无关的检索词的影响,而导致检索结果不准确。
技术实现要素:
本发明的目的旨在至少在一定程度上解决上述的技术问题之一。
为此,本发明的第一个目的在于提出一种基于人工智能的查询信息处理方法,该方法提高了检索结果和用户查询意图的相关性,提高了检索性能。
本发明的第二个目的在于提出一种基于人工智能的查询信息处理装置。
为了实现上述目的,本发明第一方面实施例提出了一种基于人工智能的查询信息处理方法,包括以下步骤:
分析用户输入的查询语句提取主干信息;
根据高频信息对所述主干信息进行同义信息变换处理生成检索信息;
反馈与所述检索信息对应的检索结果。
本发明实施例的基于人工智能的查询信息处理方法,分析用户输入的查询语句提取主干信息,并根据高频信息对主干信息进行同义信息变换处理生成检索信息,进而反馈与检索信息对应的检索结果。由此,提高了检索结果和用户查询意图的相关性,提高了检索性能。
另外,本发明实施例的基于人工智能的查询信息处理方法,还具有如下附加的技术特征:
在本发明的一个实施例中,所述分析用户输入的查询语句提取主干信息,包括:
对所述查询语句进行切词处理;
对切词结果进行词性标注以及词法分析,对所述查询语句进行子句切分;
删除子句切分结果中的无用片段;
提取剩余子句中正确的主干信息;
对所述正确的主干信息之间的紧密度进行分析,确定所述查询语句的主干信息。
在本发明的一个实施例中,所述删除子句切分结果中的无用片段,包括:
根据预设的口语表达模板检测所述子句切分结果中是否存在口语表达片段,如果存在,则删除所述口语表达片段;和/或,
根据预设的情绪表达特性检测所述子句切分结果中是否存在情绪表达片段,如果存在,则删除所述情绪表达片段;和/或,
根据预设的重复表达类型检测所述子句切分结果中是否存在重复表达片段,如果存在,则删除所述重复表达片段。
在本发明的一个实施例中,所述提取剩余子句中正确的主干信息,包括:
识别所述剩余子句中的实体词;
通过语句结构获取与所述实体词关联的关系词;
根据预设的语言模型删除与上下文无关的实体词和/或关系词,获取剩余子句中正确的主干信息。
在本发明的一个实施例中,所述根据高频信息对所述主干信息进行同义信息变换处理生成检索信息,包括:
根据预设的使用户满意点击的高频查询集合对所述主干信息进行同义检索匹配;
如果具有与所述主干信息同义匹配的相似度满足预设阈值的高频查询语句,则根据所述高频查询语句对所述主干信息进行同义信息变换处理生成检索信息。
在本发明的一个实施例中,还包括:
如果不具有与所述主干信息同义匹配的相似度满足预设阈值的高频查询语句,根据历史点击的查询及对应的主题结果信息和预设阈值,获取同义查询语句簇;
对所述同义查询语句簇中的每个查询语句进行结构分析并进行实体泛化;
对实体泛化后的等价结构的频次与预设阈值进行比较,大于预设阈值的等价结构确定为同义结构;
对所述主干信息进行结构分析及实体泛化,根据所述同义架构匹配与所述主干信息相似的同义查询语句;
根据所述同义查询语句对所述主干信息进行同义信息变换处理生成检索信息。
为了实现上述目的,本发明第二方面实施例提出了一种基于人工智能的车讯信息处理装置,包括:
分析模块,用于分析用户输入的查询语句提取主干信息;
生成模块,用于根据高频信息对所述主干信息进行同义信息变换处理生成检索信息;
反馈模块,用于反馈与所述检索信息对应的检索结果。
本发明实施例的基于人工智能的查询信息处理装置,分析用户输入的查询语句提取主干信息,并根据高频信息对主干信息进行同义信息变换处理生成检索信息,进而反馈与检索信息对应的检索结果。由此,提高了检索结果和用户查询意图的相关性,提高了检索性能。
另外,本发明实施例的基于人工智能的车讯信息处理装置,还具有如下附加的技术特征:
在本发明的一个实施例中,所述分析模块包括:
第一处理单元,用于对所述查询语句进行切词处理;
切分单元,用于对切词结果进行词性标注以及词法分析,对所述查询语句进行子句切分;
删除单元,用于删除子句切分结果中的无用片段;
提取单元,用于提取剩余子句中正确的主干信息;
第一确定单元,用于对所述正确的主干信息之间的紧密度进行分析,确定所述查询语句的主干信息。
在本发明的一个实施例中,所述删除单元用于:根据预设的口语表达模板检测所述子句切分结果中是否存在口语表达片段,如果存在,则删除所述口语表达片段;和/或,
根据预设的情绪表达特性检测所述子句切分结果中是否存在情绪表达片段,如果存在,则删除所述情绪表达片段;和/或,
根据预设的重复表达类型检测所述子句切分结果中是否存在重复表达片段,如果存在,则删除所述重复表达片段。
在本发明的一个实施例中,所述提取单元包括:
识别子单元,用于识别所述剩余子句中的实体词;
第一获取子单元,用于通过语句结构获取与所述实体词关联的关系词;
第二获取子单元,用于根据预设的语言模型删除与上下文无关的实体词和/或关系词,获取剩余子句中正确的主干信息。
在本发明的一个实施例中,所述生成模块包括:
匹配单元,用于根据预设的使用户满意点击的高频查询集合对所述主干信息进行同义检索匹配;
第一生成单元,用于在具有与所述主干信息同义匹配的相似度满足预设阈值的高频查询语句时,根据所述高频查询语句对所述主干信息进行同义信息变换处理生成检索信息。
在本发明的一个实施例中,所述生成模块还包括:
获取单元,用于在不具有与所述主干信息同义匹配的相似度满足预设阈值的高频查询语句时,根据历史点击的查询及对应的主题结果信息和预设阈值,获取同义查询语句簇;
第二处理单元,用于对所述同义查询语句簇中的每个查询语句进行结构分析并进行实体泛化;
第二确定单元,用于对实体泛化后的等价结构的频次与预设阈值进行比较,大于预设阈值的等价结构确定为同义结构;
所述匹配单元,还用于对所述主干信息进行结构分析及实体泛化,根据所述同义架构匹配与所述主干信息相似的同义查询语句;
第二生成单元,用于根据所述同义查询语句对所述主干信息进行同义信息变换处理生成检索信息。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1是根据本发明一个实施例的基于人工智能的查询信息处理方法的流程图;
图2是根据本发明第二个实施例的基于人工智能的查询信息处理方法的流程图;
图3是根据本发明一个实施例的根据语句结构提取剩余子句中正确的主干信息的场景示意图;
图4(a)-图4(b)是根据本发明一个实施例的根据同义架构匹配与主干信息相似的同义查询语句的场景示意图;
图5(a)-图5(b)是根据本发明一个实施例的基于人工智能的查询信息处理方法实施例的检索情况示意图;
图6(a)-图6(b)是根据本发明另一个实施例的基于人工智能的查询信息处理方法实施例的检索情况示意图;
图7是根据本发明第一个实施例的基于人工智能的车讯信息处理装置的结构示意图;
图8是根据本发明第二个实施例的基于人工智能的车讯信息处理装置的结构示意图;
图9是根据本发明第三个实施例的基于人工智能的车讯信息处理装置的结构示意图;以及
图10是根据本发明第四个实施例的基于人工智能的车讯信息处理装置的结构示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参考附图描述本发明实施例的基于人工智能的查询信息处理方法和装置。
图1是根据本发明一个实施例的基于人工智能的查询信息处理方法的流程图。
如图1所示,该基于人工智能的查询信息处理方法可包括:
S101,分析用户输入的查询语句提取主干信息。
通常,相关检索系统根据用户输入的检索词进行检索,并向用户提供检索结果。然而,在实际应用中,用户在输入检索词的时候,尤其是语音输入检索词的时候,通常会加入一些细节性描述、个人主管情绪上的描述、个人口语化描述等。
比如,用户可能输入查询语句“我是上个月23号做的那个手术血一直没干导致近两年来特多我很害怕帮我搜一下帮我问问”,来获取相关检索结果。
然而,当前检索系统是针对输入的检索词进行检索,因而检索结果容易受到查询语句中,与检索意图无关的检索词的影响,而导致检索结果不准确。且相关检索系统针对文本搜索进行建模处理的,当上述用户输入查询语句的方式是语音输入时,其对语音长语句的识别性能不高。
为了解决上述问题,本发明提出了一种基于人工智能的查询信息处理方法,该方法提高检索结果和用户查询意图的相关性,提高了检索性能。
具体地,在实际执行过程中,分析用户输入的查询语句,去除一些无用、重复、情绪化、口语的语句片段,提取出表达用户检索需求的主干信息。
需要说明的是,根据具体应用需求的不同,可采用多种方式分析用户输入的查询语句提取主干信息:
第一种示例,可基于查询语句的词法和语法等与语言属性相关的特性,分析用户输入的查询语句提取主干信息,比如基于查询语句中的词性提取出查询语句中与本次检索意图相关的检索词,比如识别出查询语句中的实体词(比如人、地、机构、生物、物品、虚拟作品等),并将该与本次检索意图相关的检索词作为本次查询语句的主干信息。
第二种示例,可预先根据大量的实验结果,存储不同的查询语句与主干信息的匹配关系,从而分析用户输入的查询语句与预存储的查询语句的相似度,如果用户输入的查询语句与某个预存储的查询语句相似度较高时,则查询上述匹配关系,获取对应的主干信息。
S102,根据高频信息对主干信息进行同义信息变换处理生成检索信息。
S103,反馈与检索信息对应的检索结果。
可以理解,由于不同的语境中,同样的主干信息表达的语义不同,如果仅仅根据提取的主干信息进行检索,则可能会造成检索结果与用户的检索意图不符。
比如,针对用户输入的查询语句“我在长春我要卖玉米非转基因的”,提取的主干信息“长春”、“卖”、“玉米”、“非转基因”,则直接根据该主干信息进行检索得到的检索结果,集中于为用户提供卖转基因玉米的信息,比如,为用户提供一号店、淘宝、京东、天猫等卖玉米的网上店铺,而用户的Titus是在长春卖非转基因玉米。
因此,为了避免上述问题,本发明实施例的基于人工智能的查询信息处理方法中,为了更好的理解用户的检索意图,对用户的检索意图进行表达上的理解,而不仅仅是字面上的理解。
具体而言,由于检索系统通常是基于用户点击数据进行排序,低频、长尾等检索词因为没有点击数据或点击数据较低,基于低频、长尾等检索词进行检索的效果较差。
从而,在本示例中,根据高频信息对主干信息进行同义信息变换处理生成检索信息,并根据该检索信息进行检索,在获取与检索信息对应的检索结果后,向用户反馈与检索信息对应的检索结果。
综上所述,本发明实施例的基于人工智能的查询信息处理方法,分析用户输入的查询语句提取主干信息,并根据高频信息对主干信息进行同义信息变换处理生成检索信息,进而反馈与检索信息对应的检索结果。由此,提高了检索结果和用户查询意图的相关性,提高了检索性能。
基于以上实施例,进一步地,为了更加清楚的描述如何分析用户输入的查询语句提取主干信息,下面以根据查询语句的词法和语法提取主干信息为例,具体说明本发明实施例的基于人工智能的查询信息处理方法,说明如下:
图2是根据本发明第二个实施例的基于人工智能的查询信息处理方法的流程图,如图2所示,该方法包括:
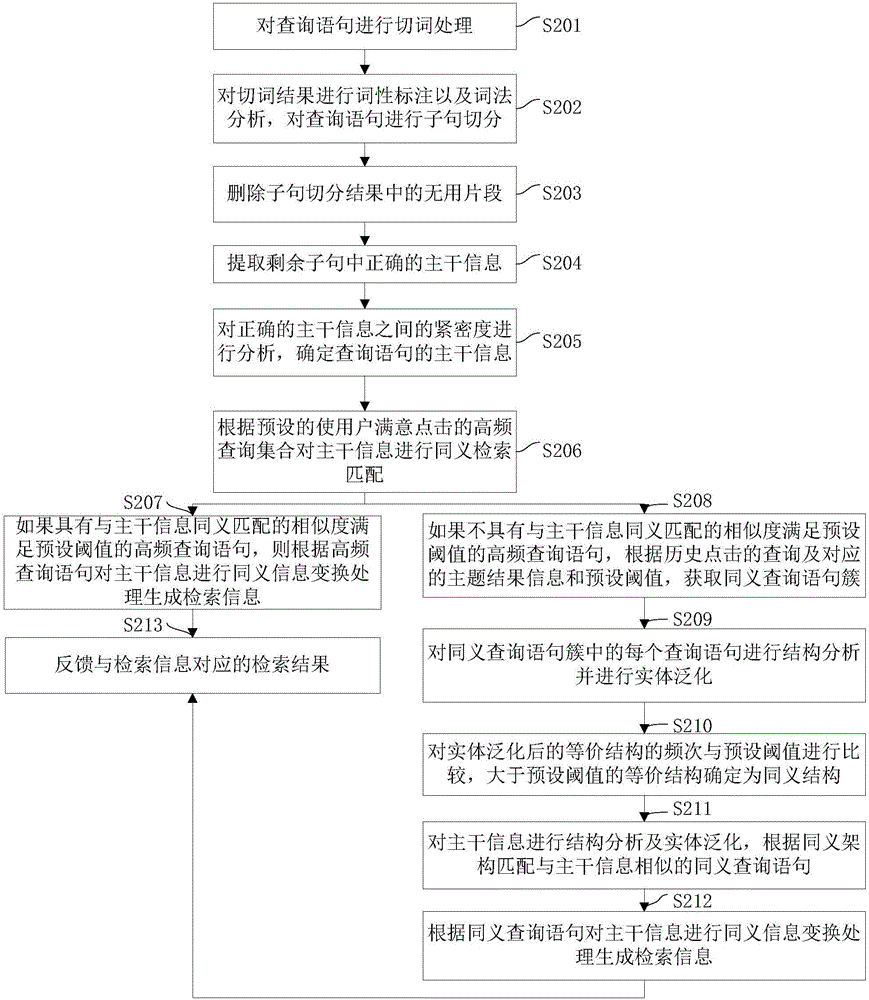
S201,对查询语句进行切词处理。
S202,对切词结果进行词性标注以及词法分析,对查询语句进行子句切分。
具体地,由于用户输入尤其是语音输入的查询语句,通常是长语句,因而需要对查询语句进行切词处理,以及对切词结果进行词性标注以及词法分析,对查询语句进行子句切分。
举例而言,如果用户输入的查询语句是“我是上个月23号我去做那个手术吗那个血一直没干致两年来的特别多我特别的害怕想问一下帮我下”,则对该查询语句进行切词处理,得到的切词处理结果为“我/是/上个月/23号/我/去/做/那个/手术/吗/那个/血/一直/没/干/致/两年/来/的/特别/多/我/特别/的/害怕/想/问/一/下/帮/我/下/”。进一步地,对切词处理结果进行词性标注以及词法分析得到的结果为“我/r是/v上个月/t23号/m我/r去/v做/v那个/r手术/n吗/y那个/r血/n一直/d没/d干/v致/v两年/t来/v的/u特别/d多/a我/r特别/d的/u害怕/a想/v问/v一/m下/q帮/v我/r下/q”。
其中,r标识代词,v标识动词,t标识时间词,m标识数词,n标识名词,d标识副词,a标识形容词,u标识助词,q标识量词。
更进一步地,对查询语句进行子句切分,将一个较长的查询句切分为若干子句。
在本发明的一个实施例中,可采用CRF序列标注模型,通过训练大量语料,其中,训练语料可来自豆瓣、网页正文等已分句的句子,获取大量句子的特征词和词性及其组合特征。
从而,可根据CRF序列标注模型,通过分析查询语句中的词性和词法,对查询语句进行子句切分,将一个较长的查询句切分为若干子句。
举例而言,对于查询语句为“我是上个月23号我去做那个手术吗那个血一直没干致两年来的特别多我特别的害怕想问一下帮我下”的子句切分结果为“我是上个月23号,我去做那个手术吗,那个血一直没干,致两年来的特别多,我特别的害怕,想问一下,帮我下”(在该示例中,为了便于描述,以逗号隔开表示分句在此分开,在实际操作过程中该都好可以不存在,也可以是任意符号,在此不做限制)。
S203,删除子句切分结果中的无用片段。
具体地,由于查询语句中包括口语化表达片段、主观情绪表达片段、重复片段等,而这些片段在人之间表达一种客气的请求等,但是针对搜索系统或者机器人等,这些口语片段则没有必要存在,因而需要删除子句切分结果中的无用片段。
具体而言,在本发明的一个实施例中,可根据预设的口语表达模板检测子句切分结果中是否存在口语表达片段,如果存在,则删除口语表达片段
在本实施例中,举例而言,可根据预设的口语表达模板检测子句切分结果中是否存在“我想搜索一下XXX”、“你知道XXX吗”、“帮我找一下XXX”等口语表达片段,如果存在,则删除该片段。
在本发明的一个实施例中,可根据预设的情绪表达特性检测子句切分结果中是否存在情绪表达片段,如果存在,则删除情绪表达片段。
在本实施例中,可针对人称代词和情绪词的搭配来识别情绪表达片段,其中人称代词属于闭集合,可人工收集,主观情绪词是传统情感分析中的词典词语,可直接依赖情感分析的结果。
在本发明的一个实施例中,可根据预设的重复表达类型检测子句切分结果中是否存在重复表达片段,如果存在,则删除重复表达片段。
在本示例中,重复表达片段可能是用户因为强调其检索需求重复的表述,比如,针对某个子句切分结果:“我想知道张裕酒厂的位置,具体在什么地方呢”,其中,“位置”跟“具体在什么地方”属于重复表达片段,从而可删除其中一个片段。
在本示例中,重复表达片段也可能是用户针对同类需求的多种表述,比如,针对某个子句切分结果:“我要看樱桃小丸子我看要樱桃小丸子给我找”,其中,“我要看樱桃小丸子”重复了两遍,可以删除其中一个片段。
又比如,针对某个子句切分结果:“我要看拯救地球中文版不是英文的”,其中,“不是英文的”通过否定强调要的是“中文版”,从而可将“不是英文的”删除。
另外,在本发明的另一个实施例中,如果针对某个子句切分结果包含多个在同类需求,则可识别同类多需求的表达,并基于其中一个需求进行满足。
比如,针对“我要看蜘蛛侠,我要看奥特曼,我还要看光头强”的子句切分结果,可仅能满足对“我要看蜘蛛侠”检索需求。
S204,提取剩余子句中正确的主干信息。
具体地,在本发明的一个实施例中,可识别剩余子句中的实体词,并根据语句结构获取与实体词相关联的关系词,进而根据预设的语言模型删除与上下文无关的实体词和/或关系词,以获取剩余子句中正确的主干信息。
举例而言,对于剩余子句“给我找配国语的韩剧继承者们”,识别的实体词为“继承者们”,语句结构分析如图3所示,通过结语句构分析结果,得到与实体词搭配的关系词“配”以及通过关系词得到的另一个关联实体“国语”等,都是正确的主干信息。
基于以上描述,应当理解的是,在提取剩余子句中正确的主干信息的过程中,还可包括对错误的主干信息的识别。
具体而言,可识别音转字/词的过程中引入的错别字或者与上下文完全不搭对的词条,因而可基于语言模型的错误或不搭对主干信息的识别,若当前主干信息会引起整个语言模型分数大幅降低,则会认为该主干信息是与上下文无关的,应该删除。
比如,针对剩余子句:“第一次拔智齿的时候是血黑色的非常多还带有血块王侯妻妾怎么回事”,其中“王侯妻妾”就属于完全不搭对的词语,跟上下文都无关,因而可将“王侯妻妾”确认为是错误的主干信息进行删除。
S205,对正确的主干信息之间的紧密度进行分析,确定查询语句的主干信息。
可以理解,对于同样的主干信息,在不同的子句中的重要程度不同,因而需要针对不同的子句,对得到的正确的主干信息进行选择。
具体地,为了生成针对多个子句的最终检索信息,针对正确的主干信息之间的紧密的进行分析,将紧密度较高的主干信息处理并合,确定查询语句的主干信息。
举例而言,针对查询语句“那个女的我想想美元是什么样的过早一百个图片给我瞅瞅”的子句切分处理结果为:“那个女的,我想想美元是什么样的,过早一百个图片给我瞅瞅”。
进而,提取的各个子句的重要主干信息分别为“女的”“美元什么样”“一百个图片”,由于“女”与“美元”的紧密度很低,“美元”与“图片”的紧密度较高,所以得到“我想想美元是什么样的”“过早一百个图片给我瞅瞅”两个子句,从而确定该查询语句的主干信息为“美元什么样一百个图片”。
S206,根据预设的使用户满意点击的高频查询集合对主干信息进行同义检索匹配。
可以理解,在得到查询语句的主干信息后,对主干信息的表达进行理解,以准确理解用户的检索需求。
具体而言,根据预设的高频查询集合对主干信息进行同义检索,其中,上述高频查询集合包括用户满意点击的高频查询语句。
S207,如果具有与主干信息同义匹配的相似度满足预设阈值的高频查询语句,则根据高频查询语句对主干信息进行同义信息变换处理生成检索信息。
具体地,如果高频查询集合中具有与主干信息同义匹配的相似度满足预设阈值的高频查询语句,则表明当前主干信息和该高频查询语句同义,因而为了取得更好的检索效果,根据高频查询语句对主干信息进行同义变换处理,以生成检索信息。
S208,如果不具有与主干信息同义匹配的相似度满足预设阈值的高频查询语句,根据历史点击的查询及对应的主题结果信息和预设阈值,获取同义查询语句簇。
具体地,如果高频查询集合中不具有与主干信息同义匹配的相似度满足预设阈值的高频查询语句,则根据历史点击的查询及对应的主题结果信息和预设阈值,获取同义查询语簇。
比如,根据历史点击的查询及对应的主题结果信息和预设阈值,获取到同义查询语簇“哪里收鹿茸”、“谁买鹿茸”、“去哪卖鹿茸”等。
S209,对同义查询语句簇中的每个查询语句进行结构分析并进行实体泛化。
S210,对实体泛化后的等价结构的频次与预设阈值进行比较,大于预设阈值的等价结构确定为同义结构。
具体地,通过对同义查询语句簇中的每个查询语句进行结构分析并进行实体泛化,将查询语句泛化为一个较为常用的查询语句,对实体泛化后的等价结构的频次与预设阈值进行比较,大于预设阈值的等价结构确定为同义结构,以将查询语句泛化为一个较为常用的同义结构,增加检索结果与用户检索意图的相关性。
举例而言,对同义查询语簇“哪里收鹿茸”、“谁买鹿茸”、“去哪卖鹿茸”等进行结构分析,可以得到三元组“哪里,收,鹿茸”、“谁,买,鹿茸”、“,卖,鹿茸”(该三元组中主语确实,表示用户)。
进而,对“鹿茸”进行结构泛化,泛化到中药、药材、物品等。
从而,实体泛化后的等价结构为(地方疑问,收,中药)=(人物疑问,买,中药)=(用户,卖,中药)、(地方疑问,收,药材)=(人物疑问,买,药材)=(用户,卖,药材)、(地方疑问,收,物品)=(人物疑问,买,物品)=(用户,卖,物品)等,通过每一个等价的结构间,在大量的查询语句中预先对等价结构的频次进行设定,对实体泛化后的等价结构的频次与预设阈值进行比较,大于预设阈值的等价结构确定为同义结构。
S211,对主干信息进行结构分析及实体泛化,根据同义架构匹配与主干信息相似的同义查询语句。
具体地,在确定同义结构后,对主干信息进行结构分析即实体泛化,并根据同义架构匹配与主干信息相似的同义查询语句,以将主干信息转换为与用户检索意图相符的同义查询语句。
举例而言,如图4(a)所示,对主干信息“我要卖玉米非转基因的”进行结构分析后得到的结果是“我,卖,玉米”,实体泛化后的得到(我,卖,农作物)及(我,卖,商品),进而,通过相似度计算,以及根据同义架构“地方疑问,收,玉米”匹配与主干信息相似的同义查询语句,为如图4(b)所示的“哪里收购玉米”。
S212,根据同义查询语句对主干信息进行同义信息变换处理生成检索信息。
S213,反馈与检索信息对应的检索结果。
具体地,在得到同义查询语句后,根据同义查询语句对主干信息进行同义信息变换处理,生成相应的检索信息进行检索,并反馈与检索信息对应的检索结果。
下面集合具体的应用场景,对执行本发明实施例的基于人工智能的查询信息处理方法实施例的检索情况进行举例:
在本发明的一个实施例中,如图5(a)所示,当输入的查询语句是“皇帝的新衣里皇帝听到议论后会有怎样的反应请你补充发挥”,经过相应的处理,得到的子句中的正确的主干信息为:“皇帝的新衣里皇帝听到议论后会有怎样的反应”。
进而,对主干信息“皇帝的新衣里皇帝听到议论后会有怎样的反应”进行相应的处理,以生成对应的如图5(b)所示检索信息,根据该检索信息进行检索。
在本发明的一个实施例中,如图6(a)所示,当输入的查询语句是“乌篷船儿轻轻摇春雨用蓝花草你知道蓝花草在绍兴有什么特殊的含义吗”(图中没有显示完全),经过相应的处理,得到的子句中的正确的主干信息为:“蓝花草在绍兴有什么特殊的含义”。
进而,对主干信息“蓝花草在绍兴有什么特殊的含义”进行相应的处理,以生成对应的如图6(b)所示检索信息,根据该检索信息进行检索。
综上所述,本发明实施例的基于人工智能的查询信息处理方法,对查询语句进行切词处理,对切词结果进行词性标注以及词法分析,以及对查询语句进行子句切分,进而删除子句切分结果中的无用片段,并提取剩余子句中正确的主干信息,以对正确的主干信息之间的紧密度进行分析,确定查询语句的主干信息。由此,提高了主干信息提取的正确性,保证了检索结果和用户查询意图的相关性,提高了检索性能。
为了实现上述目的,本发明还提出了一种基于人工智能的车讯信息处理装置,图7是根据本发明第一个实施例的基于人工智能的车讯信息处理装置的结构示意图,如图7所示,该基于人工智能的车讯信息处理装置可包括:分析模块100、生成模块200和反馈模块300。
其中,分析模块100,用于分析用户输入的查询语句提取主干信息。
生成模块200,用于根据高频信息对主干信息进行同义信息变换处理生成检索信息。
反馈模块300,用于反馈与检索信息对应的检索结果。
在本发明的实施例中,生成模块200根据高频信息对主干信息进行同义信息变换处理生成检索信息,并根据该检索信息进行检索,在获取与检索信息对应的检索结果后,反馈模块300向用户反馈与检索信息对应的检索结果
需要说明的是,前述对基于人工智能的车讯信息处理方法的解释说明,也适用本发明实施例的基于人工智能的车讯信息处理装置实施例,其原理类似,在此不再赘述。
综上所述,本发明实施例的基于人工智能的查询信息处理装置,分析用户输入的查询语句提取主干信息,并根据高频信息对主干信息进行同义信息变换处理生成检索信息,进而反馈与检索信息对应的检索结果。由此,提高了检索结果和用户查询意图的相关性,提高了检索性能。
基于以上实施例,进一步地,为了更加清楚的描述如何分析用户输入的查询语句提取主干信息,下面以根据查询语句的词法和语法提取主干信息为例,具体说明本发明实施例的基于人工智能的查询信息处理装置,说明如下:
图8是根据本发明第二个实施例的基于人工智能的车讯信息处理装置的结构示意图,如图8所示,在如图7所示的基础上,分析模块100包括第一处理单元110、切分单元120、删除单元130、提取单元140和第一确定单元150。
其中,第一处理单元110,用于对查询语句进行切词处理。
切分单元120,用于对切词结果进行词性标注以及词法分析,对查询语句进行子句切分。
具体地,由于用户输入尤其是语音输入的查询语句,通常是长语句,因而需要第一处理单元110和切分单元120分别对查询语句进行切词处理,以及对切词结果进行词性标注以及词法分析,对查询语句进行子句切分。
删除单元130,用于删除子句切分结果中的无用片段。
在本发明的一个实施例中,删除单元130根据预设的口语表达模板检测子句切分结果中是否存在口语表达片段,如果存在,则删除口语表达片段。
在本发明的一个实施例中,删除单元130根据预设的情绪表达特性检测子句切分结果中是否存在情绪表达片段,如果存在,则删除情绪表达片段。
在本发明的一个实施例中,删除单元130根据预设的重复表达类型检测子句切分结果中是否存在重复表达片段,如果存在,则删除重复表达片段。
提取单元140,用于提取剩余子句中正确的主干信息。
在本发明的一个实施例中,如图9所示,在如图8所示的基础上,该提取单元140包括识别子单元141、第一获取子单元142、第二获取子单元143。
其中,识别子单元141,用于识别剩余子句中的实体词。
第一获取子单元142,用于通过语句结构获取与实体词关联的关系词。
第二获取子单元143,用于根据预设的语言模型删除与上下文无关的实体词和/或关系词,获取剩余子句中正确的主干信息。
第一确定单元120,用于对正确的主干信息之间的紧密度进行分析,确定查询语句的主干信息。
进而,在本发明的一个实施例中,图10是根据本发明第四个实施例的基于人工智能的车讯信息处理装置的结构示意图,如图10所示,在如图7所示的基础上,生成模块200包括匹配单元210和第一生成单元220、获取单元230、第二处理单元240、第二确定单元250和第二生成单元260。
其中,匹配单元210,用于根据预设的使用户满意点击的高频查询集合对主干信息进行同义检索匹配。
第一生成单元220,用于在具有与主干信息同义匹配的相似度满足预设阈值的高频查询语句时,根据高频查询语句对主干信息进行同义信息变换处理生成检索信息。
获取单元230,用于在不具有与主干信息同义匹配的相似度满足预设阈值的高频查询语句时,根据历史点击的查询及对应的主题结果信息和预设阈值,获取同义查询语句簇。
第二处理单元240,用于对同义查询语句簇中的每个查询语句进行结构分析并进行实体泛化。
第二确定单元250,用于对实体泛化后的等价结构的频次与预设阈值进行比较,大于预设阈值的等价结构确定为同义结构。
在本发明的一个实施例中,匹配单元210还用于对主干信息进行结构分析及实体泛化,根据同义架构匹配与主干信息相似的同义查询语句。
第二生成单元260,用于根据同义查询语句对主干信息进行同义信息变换处理生成检索信息。
需要说明的是,前述对基于人工智能的车讯信息处理方法的解释说明,也适用本发明实施例的基于人工智能的车讯信息处理装置实施例,其原理类似,在此不再赘述。
综上所述,本发明实施例的基于人工智能的查询信息处理装置,对查询语句进行切词处理,对切词结果进行词性标注以及词法分析,以及对查询语句进行子句切分,进而删除子句切分结果中的无用片段,并提取剩余子句中正确的主干信息,以对正确的主干信息之间的紧密度进行分析,确定查询语句的主干信息。由此,提高了主干信息提取的正确性,保证了检索结果和用户查询意图的相关性,提高了检索性能。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!