基于人工智能的人机交互方法及装置与流程
本申请涉及计算机领域,尤其涉及一种基于人工智能的人机交互方法及装置。
背景技术:
人工智能(Artificial Intelligence,简称AI)。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语音识别、图像识别、自然语言处理和专家系统等。
人机交互界面创建是以互联网为主要平台进行的,为达到一定交互目的以供用户参与的人机交互行为。随着互联网的发展,人机交互的应用也越来越广泛,例如,用户可以通过语音或文字与交互系统(聊天机器人、语音助手等)进行人机交互。
然而,在相关技术中,在人机交互过程中,对话内容单一且不能满足用户个性化、趣味性和知识性等多方面的需求。
技术实现要素:
本申请的目的旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本申请的第一个目的在于提出一种基于人工智能的人机交互方法,能够提高对话内容的丰富性,满足了用户个性化、趣味性和知识性的对话需求。
本申请的第二个目的在于提出了一种基于人工智能的人机交互装置。
本申请的第三个目的在于提出了另一种基于人工智能的人机交互装置。
本申请的第四个目的在于提出了一种非临时性计算机可读存储介质。
本申请的第五个目的在于提出了一种计算机程序产品。
为达上述目的,根据本申请第一方面实施例提出的一种基于人工智能的人机交互方法,包括以下步骤:根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;应用多个对话源的特征资源获取与所述解析结果对应的多个结果;根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
本申请实施例的基于人工智能的人机交互方法,首先根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成结构化的解析结果,然后应用多个对话源的特征资源获取与解析结果对应的多个结果,最后根据预设的筛选策略从多个结果中确定与多模输入信息对应的多模输出信息推送给用户。由此,能够提高对话内容的丰富性,满足了用户个性化、趣味性和知识性的需求。
为达上述目的,根据本申请的第三方面实施例提出的一种基于人工智能的人机交互装置,包括:生成模块,用于根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;获取模块,用于应用多个对话源的特征资源获取与所述解析结果对应的多个结果;确定模块,用于根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
本申请实施例的基于人工智能的人机交互装置,首先根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果,然后应用多个对话源的特征资源获取与解析结果对应的多个结果,最后根据预设的筛选策略从多个结果中确定与多模输入信息对应的多模输出信息推送给用户。由此,能够提高对话内容的丰富性,满足了用户个性化、趣味性和知识性的需求。
为达上述目的,根据本申请的第三方面实施例提出的一种基于人工智能的人机交互装置,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为:
根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
为达上述目的,根据本申请的第四方面实施例提出的一种非临时性计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器被执行时,使得移动终端能够执行一种基于人工智能的人机交互方法,所述方法包括:
根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
为达上述目的,根据本申请的第五方面实施例提出的一种计算机程序产品,当所述计算机程序产品中的指令处理器执行时,执行一种基于人工智能的人机交互方法,所述方法包括:
根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果;
应用多个对话源的特征资源获取与所述解析结果对应的多个结果;
根据预设的筛选策略从所述多个结果中确定与所述多模输入信息对应的多模输出信息推送给所述用户。
本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
图1是根据本申请一个实施例的基于人工智能的人机交互方法的流程图;
图2是根据本申请一个实施例的人机交互的示意图;
图3是根据本申请另一个实施例的基于人工智能的人机交互方法的流程图;
图4是根据本申请一个实施例的基于人工智能的人机交互装置的结构示意图;
图5是根据本申请另一个实施例的基于人工智能的人机交互装置的结构示意图
图6是根据本申请又一个实施例的基于人工智能的人机交互装置的结构示意图;
图7是根据本申请再一个实施例的基于人工智能的人机交互装置的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。
下面参考附图描述本申请实施例的基于人工智能的人机交互方法及装置。
具体地,本申请实施例的基于人工智能的人机交互方法适用于很多种不同的应用场景,可以根据实际应用需要选择设置。举例说明如下:
场景一:虚拟化任务即用电子的方式来承载的虚拟化任务,例如虚拟歌手、虚拟动漫人物等。
场景二:智能硬件设备,例如智能交互玩具。
场景三:电子商务,例如智能客服。
场景四:生活服务。例如语音导航、酒店接待和智能讲解员等。
通常,在上述任一场景中,用户可以通过语音、文本、表情、图片、实时图像等与交互系统(例如语音助手)进行人机交互。随着互联网的发展,人机交互的应用也越来越广泛,用户对于在人机交互过程中的对话需求也越来越多。
然而,在目前的人机交互过程中,对话内容比较单一且不能满足用户个性化、趣味性和知识性等多方面的需求。
为了解决上述问题,本发明提出了一种基于人工智能的人机交互方法,通过应用多个对话源的特征资源获取多个结果,并通过筛选的方式从多个结果中确定与多模输入信息对应的多模输出信息推送给用户,从而提高对话内容的丰富性,满足用户个性化、趣味性和知识性的对话需求。具体如下:
图1是根据本申请一个实施例的基于人工智能的人机交互方法的流程图。
如图1所示,本申请实施例的基于人工智能的人机交互方法包括以下步骤:
步骤110,根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果。
具体地,在人机交互的过程中,用户可以通过键盘、语音、图片和视频等方式输入多模输入信息,其形式可以是语音、文本、表情、图片、实时图像等。并且,在多模输入信息后会推送给用户多模输出信息。多模输入信息和多模输出信息构成历史交互信息。
具体地,为了保证当前的多模输入信息对应的多模输出信息是满足用户各方面需求的。首先根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果。
需要说明的是,预设解析策略的有很多种,例如包括:语义句法解析策略、用户行为解析策略和场景解析策略等中的一种或者多种。
进一步地,选择不同的预设解析策略获取到的解析结果不同。举例说明如下:
第一种示例,预设解析策略包括语义句法解析策略。
具体地,根据语义句法解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成上下文解析结果。
其中,上下文解析结果可以有很多种,例如包括:语句的语法结构、语句的中心词、语句的会话行为类型、语句的意图、多轮对话的主题、上下文对话指代消解和补全等中的一种或者多种。
为了本领域人员更加清楚了解上述上下文解析结果,下面结合图2具体描述说明。
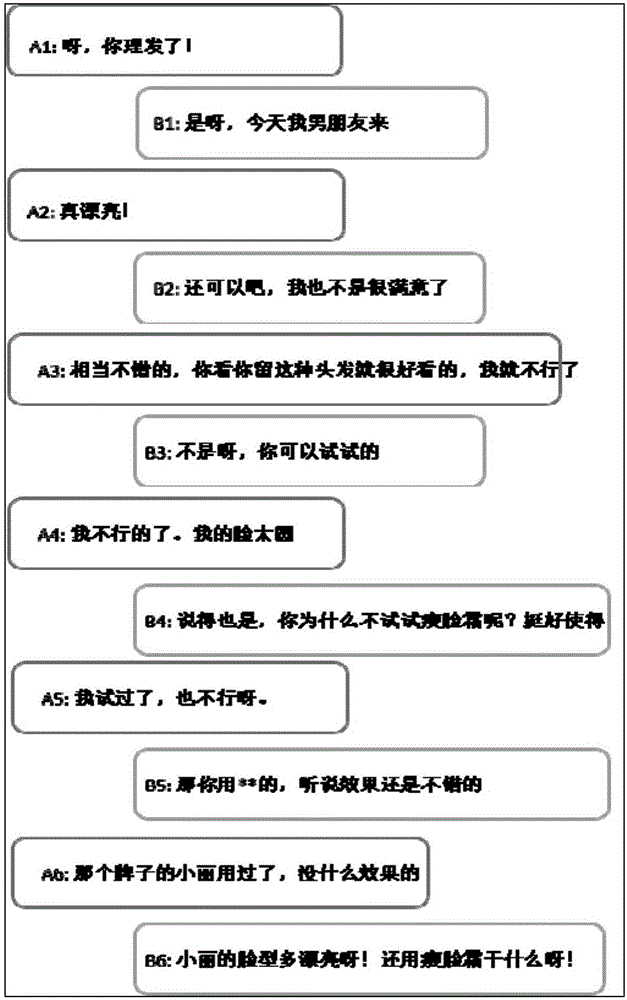
图2是根据本申请一个实施例的人机交互的示意图。
如图2所示,在人机交互过程中具有(A1,B1)至(A6,B6)六个对话,结合这六个对话具体描述语句的语法结构、语句的中心词、语句的会话行为类型、语句的意图、多轮对话的主题、上下文对话指代消解和补全。
具体地,语句的语法结构可以理解为将一个完整的句子,解析成实体、谓语和实体的语法结构。以图2中的A6“那个牌子的小丽用过了”为例说明,解析成实体为“小丽”、谓语为“用过了”和实体“那个牌子”。
具体地,语句的中心词可以理解为当前对话的实体或者主体。继续以图2中的A6“那个牌子的小丽用过了,听说效果不错”为例说明,这语句的中心词为“那个牌子的”。
具体地,语句的会话行为类型可以理解为根据语用的关系和对话的结构,将对话中的每个语句,附上一个结构的具体类别。以图2中的(A1,B1)为例说明,A1“呀,你理发了”为陈述;B1“是啊”为确认,“今天我男朋友来”为陈述。
具体地,语句的意图可以理解为对话中每个语句的目的。以图2中的B4“说的也是,你为什么不试试瘦脸霜呢”为例说明,这语句的意图为“推荐瘦脸霜”。
具体地,多轮对话的主题以图2中的A1至B3为例说明,多轮对话的主题为B的“头发”或者“发型”。
具体地,在对话的过程中,关于人称或者实物,经常会出现省略或指代的情况。上下文对话指代消解和补全可以理解为对于上述情况,进行正确的实体填充,使得语句的表达意思完整。以以图2中的A6“那个牌子的小丽用过了”为例说明,这语句中“那个牌子”需要上下文对话指代消解和补全。改写为“**牌子的瘦脸霜”。
第二种示例,预设解析策略包括语义句法解析策略和用户行为解析策略。
具体地,根据语义句法解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成上下文解析结果。和根据用户行为解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成用户的属性特征和偏好特征。
需要说明的是,生成上下文解析结果的具体过程请参见上述第一种示例的具体描述,在此不再赘述。
可以理解的是,在人机交互的过程中,可以了解到用户的属性特征和偏好特征。需要说明的是,机器的属性特征和偏好特征一般通过系统预先设置。
其中,属性特征可以包括姓名、性别、年龄和职业等。由此,属性特征在一段时间内比较稳定,不会轻易改变。
其中,偏好特征可以理解为一个具体的类别(比如体育、音乐等),或者是一个情境或者事件的概念(比如夜跑爱好者、喜马拉雅山北坡攀登等),还可以是一类用户的标签(比如90后、吊丝等)。由此,偏好特征可以描述的维度很多,一般通过短语和标签来进行描述,不稳定会随着时间变化。
第三种示例,预设解析策略包括语义句法解析策略、用户行为解析策略和场景解析策略。
具体地,根据语义句法解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成上下文解析结果。和根据用户行为解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成用户的属性特征和偏好特征。和根据场景解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成环境特征。
需要说明的是,生成上下文解析结果和生成用户的属性特征和偏好特征的具体过程请参见上述第一种示例和第二种示例的具体描述,在此不再赘述。
其中,在人机交互的过程中,用户所处的环境特征例如时间、地点和天气等可以根据场景解析策略解析与用户之间的历史交互信息和当前的多模输入信息获取。
步骤120,应用多个对话源的特征资源获取与解析结果对应的多个结果。
具体地,应用多个对话源的特征资源有很多种,例如包括:多个对话源对应的不同多媒体属性的资源、多个对话源对应的不同语言风格的资源、多个对话源对应的不同人物风格的资源、多个对话源对应的不同知识库的资源和多个对话源对应的不同服务功能的资源等中的一种或者多种。
需要说明的是,应用不同多个对话源的特征资源获取与解析结果对应的多个结果不同。
具体地,多媒体属性的资源可以是语音、文本、表情、图片、实时图像等。
需要说明的是,不同的对话源,可以以异构(对话的双方使用的多媒体属性的资源不一致,比如一方是文本,另一方是图片)的方式来进行对话。
举例而言,用户贴出自己的照片,某种对话源对照片进行颜值打分,或者用户贴出一个景点照片,某种对话源识别该景点,并给出识别的地点名称,或者是用户发出一个表情类图片,某种对话源返回另一个语义比较丰富的图片。
具体地,语言风格的资源可以是性别带来的风格(男性比较豪爽大气,女性比较体贴细致)、性格带来的风格(萌萌哒,娇羞腼腆,活泼开朗,鲁莽凶恶等)、人口属性带来的风格(机器人的金属类的嗓音,以及机器人特有的金属类外壳)和方言特征(不同方言表达同一个意思时的文字选择和语音语调)等。
具体地,人物风格的资源主要指的是人机交互中机器的一方,代表某个具体的人物(包括现实中的人物和虚拟人物)。现实中的人物比如娱体明星(胡歌,刘翔),政治人物(奥巴马,),文化名人(高晓松);虚拟人物,比如漫画中的人物(葫芦娃,擎天柱,阿童木),小说中的人物(诸葛亮,鲁智深,罗密欧),电影电视中的人物(梅长苏,李云龙,Sheldon Cooper)。
举例而言,上文:“我最近每天工作好忙,感觉没意思啊”,某种对话源(拟人化-高晓松):“生活不只眼前的苟且,还有诗和远方的田野”;上文:“你如何评价你的一生?”,某种对话源(拟人化-诸葛亮)“鞠躬尽瘁,死而后已”。
具体地,知识库的资源主要指的是富含知识,并且能否基于知识进行联想和推理。其中,知识库的资源有很多种,举例说明如下:
第一种示例,能够根据一个实体确定一个知识点,对该知识点进行横向和纵向的拓展和联想。其中,纵向是对一个知识点的具体属性进行深度的挖掘(比如,姚明:身高,荣誉),横向是对不同知识点进行联系(比如,姚明:叶莉关系为夫妻)。
举例而言,上文:“我喜欢姚明”,某种对话源:“是吗?你知道姚明身高2.26m吗?”。
第二种示例,能够基于知识进行推理,对对话中一些违反常识的内容能够检测和纠正(比如,知识库的内容是“天空是蓝色的“,如果输入信息为“天空是黑色的”,能够基于知识库的内容检测出与常识有矛盾,并且用一定的方式进行纠正)。
举例而言,上文:“我家养的小鸡有4条腿”,某种对话源:“根据我已有的知识,鸡只有2条腿”。
第三种示例,能够基于知识库进行回答(比如,输入信息为“姚明的妻子是谁“,能够基于知识库中“姚明-叶莉-关系:夫妻,进行推理和回答,给出正确的回复”姚明的妻子是叶莉“)。
具体地,服务功能的资源主要指的是可以满足某个具体的需求。比如,查某个地方的天气,接龙类游戏(成语接龙,数羊),播报类(新闻,笑话,段子,广播,音乐),问答类游戏(人物问答,猜灯谜),推荐类服务(今晚看什么电影,今天吃什么美食,好听的音乐),提醒类服务(日程跟踪提醒)。
步骤130,根据预设的筛选策略从多个结果中确定与多模输入信息对应的多模输出信息推送给用户。
具体地,在根据实际应用需要选择合适的多个对话源的特征资源获取与解析结果对应的多个结果后,需要根据预设的筛选策略选择一个合适的结果作为多模输入信息对应的多模输出信息推送给用户。其中,根据预设的筛选策略有很多种,可以根据需要选择,举例说明如下:
第一种示例,可以根据预设的筛选指标和对应的权重信息对多个结果进行评分的方式,并选择合适评分结果对应的结果作为多模输入信息对应的多模输出信息。
第二种示例,可以直接从多个结果选取符合筛选指标的结果随机作为多模输入信息对应的多模输出信息。
需要说明的是,筛选指标可以根据实际应用需要进行选择设置。
本申请实施例的基于人工智能的人机交互方法,首先根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果,然后应用多个对话源的特征资源获取与解析结果对应的多个结果,最后根据预设的筛选策略从多个结果中确定与多模输入信息对应的多模输出信息推送给用户。由此,能够提高对话内容的丰富性,满足了用户个性化、趣味性和知识性的需求。
图3是根据本申请另一个实施例的基于人工智能的人机交互方法的流程图。
如图3所示,本申请实施例的基于人工智能的人机交互方法包括以下步骤:
步骤210,根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果。
步骤220,应用多个对话源的特征资源获取与解析结果对应的多个结果。
需要说明的是,步骤S210-S220的描述与上述步骤S110-S120相对应,因此对的步骤S210-S220的描述参考上述步骤S110-S120的描述,在此不再赘述。
步骤230,根据预设的筛选指标和对应的权重信息对多个结果进行评分。
步骤240,根据与多个结果对应的评分结果确定与多模输入信息对应的多模输出信息。
具体地,预设的筛选指标可以包括但不限于个性化、上下文相关性、主题维持、主动性、或、对话质量中的一种或者多种。
由此,为了多模输出信息更符合用户需求,不同的筛选指标其对应的权重信息不同。
具体地,个性化是指不同的用户,会对对话源有不同的偏好。因此,可以利用用户的属性特征和偏好特征,以及历史交互信息中用户对于不同对话源的反馈信息,来选择用户比较喜欢和容易接受的对话源。比如,如果用户偏好富文本的内容,则赋予包含文本的多模输出信息比较大的权重信息;或者,如果用户偏好知识性强的内容,则赋予富含知识等输出信息比较大的权重信息。
具体地,上下文相关性指的是对话源的内容需要和历史交互信息和当前用户的多模输入信息存在相关性。上下文相关性主要包括两方面。
第一方面,对话的延续性即上下文之间逻辑比较顺畅,不存在语义的跳转和不相关语义的引入。举例而言,上文:“今天天气不错”,(相关性好):“是啊,天气很晴朗”。(相关性不好,语义跳跃性太强,或者包含不相关的语义):“我想骑自行车”。
第二方面,意图的满足情况即如果上文中包含明显的意图,内容源返回的结果应该直接进行意图的回应,而不是答非所问。举例而言,上文:“为什么不试试瘦脸霜呢?挺好使的”,(相关性好,明确响应上文的意图):“我试过了,也不行啊”,(相关性不好,没有明确响应上文的推荐意图):“瘦脸霜类型多种多样”。
具体地,主体维持主要是指在多轮的对话过程中,如果用户没有主动的转移话题,则人机交互系统一般不会主动的转移话题。以上述实施例图2中的对话(A1-B3),对话的主题一直是“头发”。在A4进行主题转移(主题由“头发”转移到“脸”和“瘦脸霜”)之前,B1-B3一直没有进行主动的话题转移。
具体地,主动性主要指在受控的情况下,主动进行话题转移。以上述实施例图2中的B4为例,“说的也是,你为什么不试试瘦脸霜呢?挺好使的”,将当前的话题,从“头发”主动引到“脸圆”到“瘦脸霜”上,该行为是主动且受控的,且转移的逻辑比较顺畅(发型到脸圆不合适到推荐瘦脸霜)。
具体地,对话质量综合考虑富文本的丰富程度,趣味性,知识性等因素。
进一步地,根据预设的筛选指标和对应的权重信息对多个结果进行评分,并将各个评分结果进行比较最终确定与多模输入信息对应的多模输出信息推荐给用户。其中,评分结果与预设的筛选指标和对应的权重信息有关,可以是最低分确定与多模输入信息对应的多模输出信息,也可以是最高分确定与多模输入信息对应的多模输出信息等。
步骤250,根据与用户之间的历史交互信息,进行与各语句对应的短期记忆并存储。
步骤260,根据与各语句对应的短期记忆转换成与多轮对话对应的长期记忆并存储。
具体地,短期记忆相对于长期记忆的时间较短,短期记忆包括一些短暂的,动态的事实类数据,也包括对话中特有的指代关系,具有变化快,作用范围窄(只对当前的对话理解有帮助,当时对于后续的对话没有帮助)。
以上述实施例图2中的对话(A1-B2)为例说明,动态类的事实类数据“B发型变化”,“B男朋友来“,以及上下文对话指代消解和补全B头发漂亮。
具体地,长期记忆包括一些用户的属性特征和偏好特征,需要根据与各语句对应的短期记忆转换成与多轮对话对应的长期记忆并存储,具有不易变化,作用范围宽(比如兴趣类的长时记忆会影响后续的对话)。
以上述实施例图2中的对话(A1-B2)为例说明,根据与各语句对应的短期记忆转换可以理解为需要进行进一步的抽象和推理。比如,B2短时记忆为“B男朋友来“,通过抽象和推理之后,可以得到两个长期记忆”B为女性”,B“有男朋友“。
本申请实施例的基于人工智能的人机交互方法,根据预设的筛选指标和对应的权重信息对多个结果进行评分,并根据与多个结果对应的评分结果确定与多模输入信息对应的多模输出信息推荐给用户,还根据与用户之间的历史交互信息,进行与各语句对应的短期记忆并存储,并根据与各语句对应的第一记忆转换成与多轮对话对应的长期记忆并存储。由此,进一步满足用户个性化、趣味性和知识性的对话需求。
为了实现上述实施例,本申请还提出了一种基于人工智能的人机交互装置。
图4是根据本申请一个实施例的基于人工智能的人机交互装置的结构示意图。
如图4所示,该基于人工智能的人机交互装置包括:生成模块41、获取模块42和确定模块43。
其中,生成模块41用于根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果。
获取模块42用于应用多个对话源的特征资源获取与解析结果对应的多个结果。
确定模块43用于根据预设的筛选策略从多个结果中确定与多模输入信息对应的多模输出信息推送给用户。
作为一种示例,如图5所示,在如图4所示的基础上,生成模块41包括:第一解析单元411、第二解析单元412和第三解析单元413。
其中,第一解析单元411用于根据语义句法解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成上下文解析结果。和/或,
第二解析单元412用于根据用户行为解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成用户的属性特征和偏好特征。和/或,
第三解析单元413用于根据场景解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成环境特征。
其中,生成上下文解析结果包括以下至少之一:语句的语法结构;语句的中心词;语句的会话行为类型;语句的意图;多轮对话的主题;上下文对话指代消解和补全。
作为一种示例,如图6所示,在如图4所示的基础上,获取模块42包括:第一获取单元421、第二获取单元422、第三获取单元423、第四获取单元424和第五获取单元425。
第一获取单元421用于应用多个对话源对应的不同多媒体属性的资源获取与所述解析结果对应的多个结果。和/或,
第二获取单元422用于应用多个对话源对应的不同语言风格的资源获取与所述解析结果对应的多个结果。和/或,
第三获取单元423用于应用多个对话源对应的不同人物风格的资源获取与所述解析结果对应的多个结果。和/或,
第四获取单元424用于应用多个对话源对应的不同知识库的资源获取与所述解析结果对应的多个结果。和/或,
第五获取单元425用于应用多个对话源对应的不同服务功能的资源获取与所述解析结果对应的多个结果。
在本申请的一个实施例中,确定模块43包括:评分单元431和确定单元432。
其中,评分单元431用于根据预设的筛选指标和对应的权重信息对多个结果进行评分。
确定单元432用于根据与多个结果对应的评分结果确定与多模输入信息对应的多模输出信息。
其中,预设的筛选指标包括以下至少之一:个性化、上下文相关性、主题维持、主动性、或、对话质量。
为了进一步满足用户个性化需求以及用户体验。如图7所示,在如图4所示的基础上,该基于人工智能的人机交互装置还可以包括:第一存储模块44和第二存储模块45。
其中,第一存储模块44用于根据与用户之间的历史交互信息,进行与各语句对应的短期记忆并存储。
第二存储模块45用于根据与各语句对应的短期记忆转换成与多轮对话对应的长期记忆并存储。
本发明实施例提供的基于人工智能的人机交互装置与上述几种实施例提供的基于人工智能的人机交互方法相对应,因此在前述基于人工智能的人机交互方法的实施方式也适用于本实施例提供的基于人工智能的人机交互装置,在本实施例中不再详细描述。
本申请实施例的基于人工智能的人机交互装置,首先根据预设解析策略解析与用户之间的历史交互信息和当前的多模输入信息,生成多维度结构化的解析结果,然后应用多个对话源的特征资源获取与解析结果对应的多个结果,最后根据预设的筛选策略从多个结果中确定与多模输入信息对应的多模输出信息推送给用户。由此,能够提高对话内容的丰富性,满足了用户个性化、趣味性和知识性的需求。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本申请的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!