一种基于大数据技术的燃煤机组烟尘浓度分析方法与流程
本发明属于能源领域,具体涉及一种基于大数据技术的燃煤机组烟尘浓度分析方法。
背景技术:
随着我国节能减排工作的不断深入开展,燃煤机组污染物排放标准要求越来越严苛。2014年,国家发改委、环保部等部门联合制定了《煤电节能减排升级与改造行动计划(2014-2020年)》,提出了燃煤机组达到燃气轮机组污染物排放标准的要求,即所谓的超低排放,要求在基准氧含量6%条件下,烟尘、二氧化硫、氮氧化物排放浓度分别不高于10、35、50mg/nm3。其中,烟尘浓度较2011版大气污染物排放标准下降了至少50%(注:2011版大气污染物排放标准中,烟尘浓度排放限值对于重点地区为20mg/nm3)。
为了响应国家政策的号召,江苏省燃煤机组于2014年开始大力开展超低排放改造,江苏方天电力技术有限公司在政府部门和有关政策的支持下,致力于开展超低排放系统数据在线监控和超低排放电价考核管理工作,将燃煤机组超低排放系统相关数据实施联网集成,其中包括负荷工况参数和烟囱排口烟尘浓度、氧量、温度、湿度、压力以及除尘系统电场二次电流、二次电压等过程参数。
燃煤机组烟尘浓度的测量一直以来都是发电企业关注的焦点问题之一,目前普遍采用的测量方法有直接测量法和抽取式测量法。由于燃煤机组烟道结构复杂,烟气流场分布往往存在不均现象,加上烟气成分相互干扰,对烟尘测量结果均为造成影响,而根据国家颁布的《固定污染源烟气排放连续监测技术规范》,烟尘的超低排放标准已低于目前国家规定的允许误差范围。由于燃煤机组污染物排放浓度数据不仅影响空气质量,涉及污染排污费用收取,同时也影响环保补贴电价考核工作的开展,因此,如何评估监测数据中烟尘浓度数据的可信度和监测仪表的可靠性成为了亟需解决的问题。
技术实现要素:
本发明的针对现有技术中的不足,提供一种基于大数据技术的燃煤机组烟尘浓度分析方法。
为实现上述目的,本发明采用以下技术方案:
一种基于大数据技术的燃煤机组烟尘浓度分析方法,其特征在于,包括如下步骤:
对机组历史数据进行预处理,依次包括停机数据剔除、电场运行状态计算以及烟尘浓度计算;
对处理后的机组历史数据进行聚类分析。
为优化上述技术方案,采取的具体措施还包括:
所述停机数据剔除具体包括:设置燃煤机组发电机功率的边界条件,剔除处于停机状态的数据。
所述电场运行状态计算具体包括:以电场额定电流和额定电压为基础,对电场二次电流和二次电压进行分析,判断除尘设备电场是否运行。
所述烟尘浓度计算具体包括:按照数据预处理要求,将机组的原样本数据转换成模型样本数据,所述模型样本数据包括时间、机组负荷、所有一次电场运行状态、所有二次电场运行状态和烟尘排放浓度,所述烟尘排放浓度按照如下公式折算到标准状态:
式中,soot为折算后的烟尘排放浓度,soot实测为实测烟尘排放浓度,t为烟气温度,p为烟气压力,x为烟气湿度,o2实测为实测氧浓度。
所述对处理后的机组历史数据进行聚类分析具体包括:使用聚类算法对不同运行工况进行划分,分析每种工况下不同的运行方式的数据分布。
针对已划分好的工况,根据工况下除尘系统电场的不同运行方式对数据进行划分,得到特定工况下不同运行方式数据的分布图。
采用高斯分布对每个工况下的烟尘浓度数据集p={p1,p2,...,pn}进行描述,其中n为样本数,均值μp和方差
本发明的有益效果是:对机组负荷工况和除尘设施相关系统海量数据进行深度挖掘分析,提取特定负荷工况、特定除尘设施运行状态下的烟尘浓度分布情况,实现对烟尘浓度监测数据的可信度和监测仪表可靠性进行评估,有利于监管部门掌握全省超低排放机组烟尘数据运行真伪情况,提升监测水平和快速响应能力,保证超低排放管理工作的正常有序开展。
附图说明
图1是划分好的工况示意图。
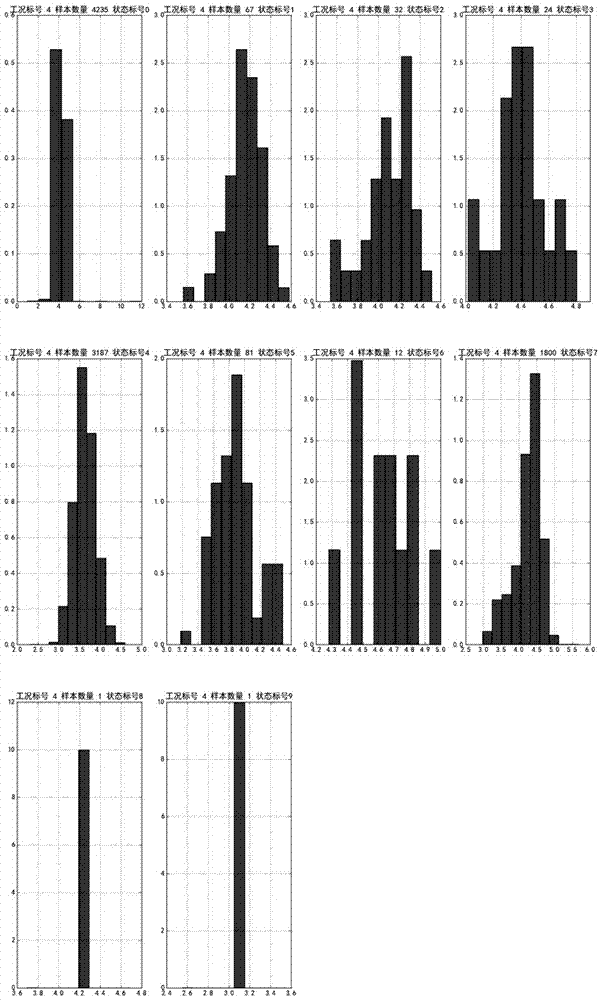
图2是特定工况下不同运行方式数据的分布图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。
本发明是采取如下技术方案进行实现的。
第一步,数据预处理,对机组历史数据进行预处理,依次包括停机数据剔除、电场运行状态计算和烟尘浓度计算三部分部分。
停机数据剔除:设置燃煤机组发电机功率边界条件,剔除处于停机状态的数据。
电场运行状态计算:以电场额定电流及额定电压为基础,对电场二次电流和二次电压进行分析,判断除尘设备电场是否运行,其中二次电流判断标准为额定电流5%以上,二次电压判断标准为额定电压25%以上。
烟尘浓度计算:按照数据预处理要求(停机数据剔除、电场运行状态计算),将原样本数据转换成模型样本数据。模型样本文件包括时间、机组负荷、所有一次电场运行状态、所有二次电场运行状态、烟尘排放浓度。其中,烟尘排放浓度按照如下公式折算到标准状态:
式中,soot为折算后的烟尘排放浓度,soot实测为实测烟尘排放浓度,t为烟气温度,p为烟气压力,x为烟气湿度,o2实测为实测氧浓度。
第二步,历史数据聚类分析。
工况划分是根据设备的运行参数和其所处的不同运行状态来对设备的运行情况进行分类。由于工况划分是根据数据本身的特点对历史数据进行的一种划分方式,事先并不知道每个工况具体的情况,因此使用非监督性学习中的聚类算法是一种非常好的解决思路。本发明采用凝聚的层次聚类算法agnes对机组历史数据进行工况划分,其基本步骤为:1)将每个对象归为一类,共得到n类,每类仅包含一个对象,类与类之间的距离就是它们所包含的对象之间的距离;2)找到最接近的两个类并合并成一类;3)重新计算新的类与所有旧类之间的距离;4)重复2)和3),直到最后合并成一个类为止。
针对已划分好的工况,根据该工况下除尘系统电场的不同运行方式可以将数据进行划分,得到特定工况下不同运行方式数据的分布图。采用高斯分布对每个工况下的烟尘浓度数据集p={p1,p2,...,pn}(n为样本数)进行描述,其均值μp和方差
第三步,烟尘浓度可信度评估。
在评价实际烟尘数据是否合理时,根据该烟尘数据所处的工况以及电场运行模式的数据分布的特点,可以分为两种情况:
1)当其对应的数据分布为高斯分布时,我们可以直接使用高斯分布的相关性质,直接得到置信度在95%的情况下数据合理的分布区间为(μ-1.96σ,μ+1.96σ),μ为均值,σ为方差;
2)如果所处的数据分布不呈现正态分布时,可以使用wilcoxon检验来测试新的样本数据在置信度为95%的情况下是否符合总体的分布。
以下结合方法的实施过程对本发明作具体的介绍,某600mw级别燃煤超低排放机组,抽取三个月运行数据,约12万条数据,对其烟尘浓度分布情况分析如下。
首先对机组负荷工况进行聚类分析,并将分类工况所对应的浓度分布进行划分,具体情况如表1和图1所示。
表1分类工况所对应的浓度分布
针对已划分好的工况,根据该工况下除尘系统电场的不同运行方式可以将数据进行划分,得到如图2所示的特定工况下不同运行方式数据的分布图。
根据大数定理可以得到,样本数量达到一定数量时,其数据分布表现为近似高斯分布,因此不同情况下的样本数量,可以将数据分布分为两种方式,当数据量足够大时,我们可以认为其分布服从高斯分布;而当样本数量较小时,可以通过shapiro检验来检验一个分布是否满足高斯分布。该检验是一种基于相关性的算法,计算可得到一个相关系数,它越接近1就越表明数据和高斯分布拟合得越好。
由于大数据分析方法是基于机组实际运行数据进行聚类、提取分析得到的结果,因此,在校验当前烟尘浓度值可信度时具有较高的可复现性。而随着超低排放机组不断增多、运行方式类型不断扩充、超低排放系统运行时间不断延长,其分析结果能得到进一步的调整,应用效果将更加准确可靠。
通过以上方法,对机组负荷工况和除尘设施相关系统海量数据进行深度挖掘分析,提取特定负荷工况、特定除尘设施运行状态下的烟尘浓度分布情况,以开展对实际烟尘浓度的可信度评估,可从技术上判断由于烟尘监测仪表测量带来的数据影响,有利于监管部门掌握全省燃煤超低排放机组烟尘浓度数据质量情况,保障超低排放管理工作正常有序开展。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!