一种基于比例分布的风速预测校正方法与流程
本发明涉及一种采用BP神经网络预测风速,基于风速整体分布比例来校正预测风速的方法,尤其适用于工程结构抗风分析中,准确提升预测风速的精度。
背景技术:
风载荷对于天线结构来说是一个重要的因素,影响天线的电性能和指向精度。天线运行系统需要知道至少未来一天的风速来规划工作。风速预测作为一种提前预测,如果能做到较高精度的预测,将能够很好的为天线的后续运行规划作出重要参考。风速预测的目的是预测下一段时间的风速,因为不同观测任务对天线指向精度的要求是不同的,从而可以基本大致确定下一时间段可以做哪些观测任务。准确地实现天线附近环境的短期风速预测,对于天线的规划设计、运行的安全稳定性有很重要的意义。
目前风速短期预测主要的方法有:持续法、时间序列法、卡尔曼滤波法、神经网络法、组合预测法等。各种方法的平均相对误差大约在20%~40%左右。造成这种误差的原因主要有以下三个方面:
a.风场的风速特性是否有规律可循;
b.预测模型的选择;
c.预测时间的长短。
BP神经网络是最具有代表性的神经网络模型之一,在风速预测方面有着广泛的应用。采用BP神经网络预测风速后,采用一天或者几天的实测值和预测值来对比,验证预测的效果。但是事实上风速预测的准确与否和很多因素有关系,风速波动就是一个至关重要的因素。往往是风速变化平稳的情况下对比预测效果良好,风速波动强烈的情况下对比预测效果就不太好。因此一天或者几天的预测效果对比并不能验证预测方法的效果,应该从风速整体分布比例上来对比预测效果。
技术实现要素:
基于上述问题,本发明的目的在于解决目前实现本发明目的的技术解决方案是,创建一种基于实测风速和预测风速整体分布比例建立的校正预测风速的方法,该技术在很大程度上解决了BP神经网络模型预测风速精度低的问题,使预测风速在整体分布比例上与实测风速更加接近。
针对上述问题,本发明首先根据某地实测数据采用BP神经网络进行风速预测。然后,做出实测风速和预测风速的分布比例图,计算实测风速和预测风速两条分布曲线的均方根偏差。最后拟合出校正多项式模型,将每一个之前预测的风速代入多项式模型中,比较各个多项式模型下优化的效果,确定最优校正模型。解决上述问题所采用的技术方案流程如下:
本发明解决其技术问题所采用的方法步骤如下:
一种基于比例分布的风速预测校正方法,包括以下步骤:
步骤1,风速数据收集处理:
建立风塔,设置传感器采集记录风速数据,数据筛选处理,求得每小时实测风速平均值;
步骤2,采用BP神经网络方法预测风速:
对实测风速数据进行归一化处理,确定网络输入输出预测值和隐层神经元个数,训练网络,建立预测模型,进行风速预测,得到每小时的预测风速值;
步骤3,计算实测预测风速整体分布比例偏差:
以x轴为风速大小,y轴为风速分布比例,绘制实测风速和预测风速整体分布比例图,并计算实测风速和预测风速整体分布比例曲线的均方根误差ra;
步骤4,拟合校正多项式:
以x轴为预测风速,y轴为实测风速,绘制预测风速-实测风速散点图,设置百分比从1到100,确定对应的百分比点,采用多项式拟合这些点,得到100个校正多项式模型;
步骤5,选出最优校正模型:
将步骤2中每小时的预测风速值分别代入步骤4得到的100个多项式模型中,得到校正后的预测风速值,再次计算校正之后新的预测风速和实测风速在整体分布比例上的偏差,从中选出最小的偏差,与之对应的多项式模型即为最优校正模型。
进一步,步骤2中,对实测风速数据进行归一化处理,通过下式计算得到:
式中,d(t)为网络输入归一化前的数据,X(t)为归一化之后的数据,min(d(t))为风速数据最小值,max(d(t))为风速数据最大值。
进一步,网络的输出预测值进行反归一化处理:
Y(t)=o(t)*(max(d(t))-min(d(t))+min(d(t))
式中,Y(t)为网络输出反归一化后的数据,o(t)为神经网络的输出。
进一步,所述步骤2中,建立预测模型如下:
其中Hj为隐含层输出,f为隐含层激励函数,vij输入和隐含层的权值,xi为网络输入,a1和aj为阈值,m为隐层神经元数,o1为网络的输出,wj1为隐含层和输出层的权值。。
进一步,计算实测风速和预测风速分布曲线的均方根误差ra,通过下式计算得到:
式中u为预测风速,v为实测风速,max(u,v)为实测风速和预测风速中的最大值,ti=(i-1)*0.1,f(ti)为实测风速分布比例曲线,g(ti)为预测风速分布比例曲线。
进一步,所述步骤4中,多项式模型如下:
b=p1an+p2an-1+p3an-2+p4an-3+p5an-4+......+pna1+pn+1
式中,a为预测风速需要代入的项,b为校正后的预测风速值,p1、p2、....pn、pn+1分别为系数值,n为多项式的最高次幂。
本发明与现有技术相比,具有以下特点:
因为风速变化平稳的情况下预测效果良好,风速波动强烈的情况下预测效果就不好,所以一天或者几天的预测效果对比并不能验证预测方法的效果。因此应该从风速整体分布比例上来对比预测效果。本发明创建一种基于实测风速和预测风速整体分布比例建立的校正预测风速方法,该方法在很大程度上解决了BP神经网络模型预测风速精度低的问题,使预测风速在整体分布比例上与实测风速更加接近。该方法能够有效提高预测风速的精度,具有明显的先进性和可靠性,因而可以更加准确地指导工程结构的抗风设计。
附图说明
图1是一种校正预测风速方法模型建立流程图;
图2是采用BP预测未来某天24小时预测效果图;
图3是校正之前风速整体分布比例图;
图4是实测-预测散点图;
图5是P%点拟合曲线图;
图6校正之后风速整体分布比例图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
参照图1,本发明为了更加清晰的说明上述5个步骤,绘制了一种校正预测风速方法模型的建立流程图,如图1所示。现以新疆奇台2011-2012年实测风速数据为例来介绍本专利的实施方式,具体如下:
1)风速数据收集处理:
建立风塔,设置传感器采集记录风速数据,经数据筛选处理求得每小时实测风速平均值;
本实施例以新疆奇台风场从2011年1月1号零时开始到2012年12月31日24时每隔一分钟采集到的风速数据进行研究。实测方法是通过建立风塔来进行测量,在不同高度处设置风速传感器以记录不同高度处的每一小时内收集的风速数据,求得平均值,代表这一小时的风速。
通过数据处理,将位于每一小时内的风速数据求得平均值,代表这一小时的风速。之后,挑选、剔除不合格数据,如果某天24小时的风速数据不完整,将这一整天的风速数据删除。风速数据四舍五入保留小数点后一位数字。
2)采用BP神经网络方法预测风速:
对实测风速数据进行归一化处理,确定网络输入输出、隐层神经元个数,训练网络,建立预测模型,进行风速预测,得到每小时的预测风速值;
数据归一化处理:
由于神经网络输入层神经元一般为Sigmoid形,整个网络的输入就会给压缩在一个较小的范围以内,为了提高训练速度、灵敏度以及有效避开Sigmoid形函数的饱和区,要求输入数据的值在0~1之间,BP神经网络预测方法将风速值换算成[0,1]区间的值,这样就需要对数据进行归一化处理:
同样网络的输出预测值也要进行反归一化处理:
Y(t)=o(t)*(max(d(t))-min(d(t))+min(d(t))
式中d(t)为网络输入归一化前的数据,X(t)为归一化之后的数据,min(d(t))为风速数据最小值,max(d(t))为风速数据最大值,o(t)为神经网络的输出,Y(t)网络输出反归一化后的数据;
神经网络隐层神经元个数的确定:
使用逐渐增加隐含层神经元个数的办法,虽然这种方法比较费时,但却较为稳妥。隐层神经元从3-13逐步选取,比较预测效果。预测效果最好所对应的神经元数为最优隐层神经元数。由于每个月份的风速数据规律不一样,建立预测模型所对应隐层神经元的个数也不一样,所以对每个月都选出最优神经元数。
BP神经网络结构:输入层--隐层(一层)--输出层输入层选取为4个,输出层选取为1个。通过30天720个数据训练网络,建立预测模型,然后逐步递进预测未来24小时的风速。
预测模型如下:
其中Hj为隐含层输出,f为隐含层激励函数,vij输入和隐含层的权值,xi为网络输入,a1和aj为阈值,m为隐层神经元数,o1为网络的输出,wj1为隐含层和输出层的权值。
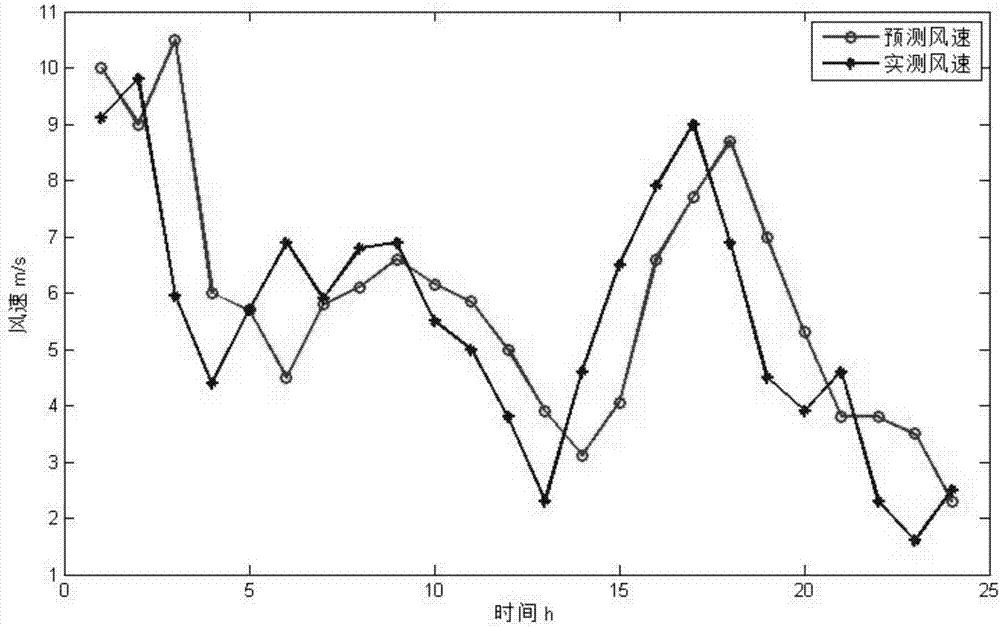
采用BP神经网络预测某一天的效果如图2所示。持续预测两年风速,对于每个实测小时平均风速值就有了对应的预测风速值。
3)计算风速整体分布比例偏差:
以x轴为风速大小,y轴为风速分布比例,绘制实测风速和预测风速整体分布比例图,并计算实测风速和预测风速分布曲线的均方根误差ra:
式中u为预测风速,v为实测风速,max(u,v)为实测风速和预测风速中的最大值,ti=(i-1)*0.1,f(ti)为实测风速分布比例曲线,g(ti)为预测风速分布比例曲线。
绘制实测风速和预测风速整体分布比例图,如图3所示。从中可以看出实测风速和预测风速在分布比例上有着较大的偏差。计算得知均方根偏差为0.1069。
4)拟合校正多项式:
以x轴为预测风速,y轴为实测风速,绘制预测风速-实测风速散点图,设置百分比从1到100,确定横坐标间隔为0.1时对应的百分比点,采用多项式拟合这些点,得到100个多项式模型,多项式模型如下:
b=p1an+p2an-1+p3an-2+p4an-3+p5an-4+......+pna1+pn+1
式中,a为预测风速需要代入的项,b为校正后的预测风速值,p1、p2、....pn、pn+1分别为系数值,n为多项式的最高次幂。
拟合曲线原理:给定一组百分比点(xi,yi),拟合多项式使得:
最小。
实测得到了两年以小时为单位的风速数据,经过数据剔除得到了17520个实测风速数据。采用BP神经网络预测方法之后得到17520个预测值,每个实测风速值都有与之对应的预测风速值,就有17520个点,每个点对应着一个预测值和一个实测值。以x轴为预测风速,y轴为实测风速,绘制这17520个点。预测-实测风速散点图如图4所示。
x轴以0.1为间隔,即x=0、0.1、0.2......。横坐标分别为0、0.1、0.2......的点组成了多个集合,对于每个集合来讲横坐标一致。每个集合,纵坐标从小到大排列,取位于P%的点,即对于每个集合来讲位于P%这个点的纵坐标值大于对应集合里面P%的点。这样确定了多个百分比点,采用多项式来拟合这些点,得到拟合多项式的系数值。
设置P从1到100,采用MATLAB软件中的cftool函数拟合出七次多项式,其中一个百分比拟合情况如图5所示。这样就得到了100个校正多项式模型。
5)选出最优校正模型:
将步骤2)中每小时的预测风速值分别代入步骤4)得到的100个多项式模型中,得到校正后的预测风速值,再次计算校正之后新的预测风速和实测风速在整体分布比例上的偏差,从中选出最小的偏差,与之对应的多项式模型就为最优校正模型。
将每个预测的风速值代入校正多项式模型,得到了新的预测风速值。计算校正之后新的预测风速和实测风速在整体分布比例上的偏差。经过计算得知预测风速和实测风速在整体分布比例上的最小偏差为0.0535,对应的百分数为43%。这样采用最优校正模型将之前的两者的分布比例偏差从0.1069降低至0.0535,降低了49.9%。经过最优校正模型计算后,校正后的预测风速和实测风速整体分布比例如图6所示。在风速分布比例上有效的提高了预测精度,使预测风速分布与实测风速分布更加接近。
以上所述,仅是本发明的实施例,并非对本发明做任何限制,凡是根据本发明技术对以上实施例所做的任何简单修改,变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!