一种检索词的实体链接方法及系统与流程
本发明涉及实体链接
技术领域:
,更具体地,涉及一种检索词的实体链接方法及系统。
背景技术:
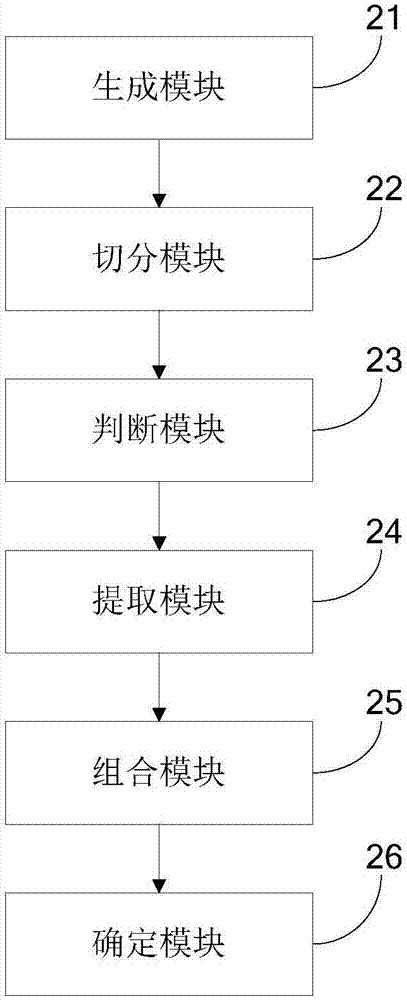
:最近,大规模知识库已经成功地应用于网络搜索引擎,可在检索结果中增加语义信息。例如google使用维基百科知识库为检索主题添加结构化的详细信息以及一些相关网站的链接。在文本中识别提及并将其链接到指定知识库的过程被称为实体链接,实体是存在于世界上的某个对象或者对象的集合,提及是实体在具体的文本中出现的形式。以维基百科作为知识库,以句子“北京是中国的首都”为例,其对应得到实体链接结果如表1所示:表1:提及与实体对应图文本中提及维基百科中实体北京北京市中国中华人民共和国实体链接主要分为三步:(1)识别提及;(2)在知识库中为每一个提及找到相应的候选实体;(3)根据上下文对候选实体进行消歧。其中实体消歧是最具挑战的子任务,主要是由实体名称的多样性和实体的歧义性决定的。实体名称的多样性和实体的歧义性:一个实体可能在不同的文本中有不同的提及,例如提及“北京”和“京”都同样指实体“北京市”;同一个实体名称可以指代不同的提及,例如“苹果”可以指提及“苹果公司”和水果“苹果”。技术实现要素:本发明提供了一种检索词的实体链接方法及系统,能够对实体链接中的实体准确的消歧。根据本发明的一个方面,提供一种检索词的实体链接方法,包括:s1,利用训练语料来生成实体提及字典和词语、提及、实体的向量模型;s2,对检索词进行切分,得到检索词的所有切分形式,并得到每一种切分形式后的多个词项;s3,当词项为提及时,从所述实体提及字典中提取该提及的候选实体集合,遍历所有词项,得到每一种切分形式对应的至少一个候选实体集合;s4,对每一种切分对应的所有候选实体集合中的实体进行全组合,形成多个实体链接候选结果,遍历检索词的每一种切分,得到检索词对应的所有的实体链接候选结果;s5,利用所述词语、提及、实体的向量模型对所有的实体链接候选结果进行打分排序,确定分数最高的实体链接结果作为检索词的最佳实体链接结果。根据本发明的另一个方面,还提供了一种检索词的实体链接系统,包括:生成模块,用于利用训练语料生成实体提及字典和词语、提及、实体的向量模型;切分模块,用于对检索词进行切分,得到检索词的所有切分形式,并得到每一种切分形式后的多个词项;判断模块,用于判断每一种切分后的每一个词项是否为提及;提取模块,用于当所述判断模块判断出词项为提及时,从所述实体提及字典中提取该提及的候选实体集合,遍历所有词项,得到每一种切分对应的提及和多个候选实体集合;组合模块,用于对每一种切分对应的所有候选实体集合中的实体进行全组合,形成多个实体链接候选结果,遍历检索词的每一种切分,得到检索词对应的所有的实体链接候选结果;确定模块,用于利用所述词语、提及、实体的向量模型对所有的实体链接候选结果进行打分排序,选择分数最大的链接结果确定为检索词的最佳实体链接结果。本发明的有益效果为:首先基于实体链接语料来生成所需的词语、提及以及实体的向量模型,并抽取实体提及字典;然后,结合搜索会话提供的语义信息和用户点击确认的实体链接结果,对检索词的每一种实体链接候选结果计算相应的局部特征和全局特征,并使用机器学习方法svmrank从训练数据得到所有特征的权重,计算候选结果的分值,分值最高的实体链接组候选结果为最后的链接结果,该方法所产生的实体链接结果得到了较高的准确率和召回率,对比现在的研究方法具有明显优势。附图说明图1为本发明一个实施例的检索词的实体链接方法流程图;图2为本发明另一个实施例的检索词的实体链接系统示意图;图3为检索词的实体链接系统中的生成模块的内部连接框图;图4为检索词的实体链接系统中的确定模块的内部连接框图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。参见图1,为本发明一个实施例的检索词的实体链接方法,包括:s1,利用知识库中的训练语料来生成实体提及字典和词语、提及、实体的向量模型;s2,对检索词进行切分,得到检索词的所有切分形式,并得到每一种切分形式后的多个词项;s3,当词项为提及时,从所述实体提及字典中提取该提及的候选实体集合,遍历所有词项,得到每一种切分形式对应的至少一个候选实体集合;s4,对每一种切分对应的所有候选实体集合中的实体进行全组合,形成多个实体链接候选结果,遍历检索词的每一种切分,得到检索词对应的所有的实体链接候选结果;s5,利用所述词语、提及、实体的向量模型对所有的实体链接候选结果进行打分排序,确定分数最高的实体链接结果作为检索词的最佳实体链接结果上述步骤s1中,本实施例首先使用包含实体链接标注的语料来生成实体链接所需要的实体提及字典,并训练实体、词以及提及的向量模型;实体提及字典用于识别文本中的提及,并得到其候选实体;实体和词的向量模型用于计算各种语义相关度,是步骤b的基础。设已标注的语料中实体链接格式为处理语料中所有的实体链接,抽取实体提及字典其中mi是一个提及,是对于提及mi的一组候选实体的集合。对语料中标注的实体链接进行处理,形成由词语、提及、实体组成的文本,在处理完的语料上训练skip-gram模型,获得词语、提及、实体的低维向量表示,用于计算语义相关度。词语、提及、实体的向量模型获取需要以下的步骤:处理语料中每个实体链接标注对实体添加“e:”前缀,对提及添加“m:”前缀,将实体链接的标注转换为两个带有前缀的词语“m:提及e:实体”。以语料中的句子“/是//的/首都”为例(“/”为分词分隔符),处理后该句子成为“m:北京/e:北京市/是/m:中国/e:中华人民共和国/的/首都”。去掉语料中的标点符号,使用skip-gram模型学习获得词语、提及和实体的向量表示。skip-gram模型是一种从文本语料中学习获得词向量的机器学习方法。给定一系列的训练词ω1,ω2,ω3,…,ωt,模型的训练目标是最大化以下目标函数:其中c是训练文本的大小,p(ωt+j|ωt)的详细定义为:公式中和是词ω的输入输出向量,而w是语料中包含不同词的总个数。通过学习到的向量模型可以获得词之间的语义相关度。步骤s2对检索词进行全切分,得到检索词的所有切分形式。检索词一般较为简短,本实施例使用全切分的方法得到检索词的所有切分形式。以检索词“网球明星李娜”为例,对其进行全切分可以得到32种切分结果,如“网球\明星\李娜”、“网球明星\李娜”、“网球\明星李娜”、“网\球\明\星\李\娜”等。给定检索词q,其所有切分结果集合表示为rq={q1,q2,…,qn},其中qi表示检索词q的一种切分,表示为一个切分项的序列qi=(ti1,ti2,…,til)。步骤s2通过全切分的方式得到检索词的所有切分形式rq,步骤s3针对每一种切分qi,在a1步骤得到的实体提及字典中查找每个词项,判断每个词项是否为一个提及;如果是字典中的提及,则从字典中提取其对应的候选实体进入消歧阶段,否则判断为普通词。本步骤得到每一个切分qi的提及和候选实体集合,表示为c(qi)={<mi1,ei1>,<mi2,ei2>,…},其中eij表示提及mij对应的候选实体集合。步骤s3得到了每一个切分qi的提及和候选实体集合,步骤s4对检索词切分qi的所有候选实体集合中的实体进行全组合,形成多个实体链接候选结果,得到检索词切分qi的多种实体链接候选结果集合r(qi)={ri1,ri2,…,rik},其中rij={<mi1,eij1>,<mi2,eij2>,…}。通过步骤s4得到了检索词对应的多个实体链接候选结果,步骤s5采用词语、提及以及实体的向量模型对所有的实体链接候选结果进行打分排序,选择分数最大的结果作为输出。具体的过程为:根据步骤s1中生成的词语、提及、实体的向量模型,计算每一个实体链接候选结果的多个局部特征值以及多个全局特征值;使用包含实体链接标注结果的检索词集合作为训练数据,基于从语料中抽取的实体提及字典、基于语料训练得到的词语、提及、实体的向量计算实体链接候选结果rij的所有特征值,使用svmrank学习获得每个特征的权值。基于已经学习的权重,计算每一个实体链接候选结果的分值,选择分值最大的实体链接结果作为检索词的最佳实体链接结果输出。其中,在计算每一个实体链接候选结果的多个局部特征值和多个全局特征值时,引入了搜索会话这个概念。搜索会话为搜索引擎用户在一个较短的时间内的连续访问行为,具体包括了用户连续提交的一系列检索词。为了克服检索词较短、缺少上下文信息的问题,同一个搜索会话中已有的检索词也被用于特征计算。在本实施例中,通常计算每一个实体链接候选结果的4个局部特征值和5个全局特征值,上述的每一个实体链接候选结果的多个局部特征值包括链接概率、候选实体与检索词的相关度、候选实体与同一搜索会话的已识别的实体之间的相关度以及候选实体和同一搜索会话中已有检索词之间的相关度;每一个实体链接候选结果的5个全局特征值包括切分粒度、该实体链接候选结果包含的各提及与检索词中其他词的相关度、该实体链接候选结果包含的各提及之间的相关度、该实体链接候选结果包含的各实体之间的相关度以及该实体链接候选结果中所有实体与同一搜索会话中已识别的实体之间的相关度。其中,搜索会话为搜索引擎用户在一个较短的时间内的连续访问行为,具体包括了用户连续提交的一系列检索词。比如,现检索词为“李娜”,若搜索会话中的多个检索词为“网球李娜”,则认为该搜索会话为现检索词的同一会话。下面具体介绍一下每一个实体链接候选结果的4个局部特征值计算,局部特征值包括链接概率、候选实体与检索词的相关度、候选实体与同一搜索会话的已识别的实体之间的相关度以及候选实体和同一搜索会话的已有检索词之间的相关度。(1)链接概率lf1,给定实体链接候选结果中的提及-实体对<mik,eijk>,该特征表示提及mik链接到实体eijk的先验概率,公式如下:其中count(mik,eijk)表示在整个语料文本中提及mik链接到eijk的总次数,公式count(mik)表示语料文本中提及mik出现的总次数。(2)候选实体与检索词的相关度lf2,该特征计算候选实体eijk与整个检索词q的语义相关度,通过使用在步骤a2中生成的向量模型计算,公式如下:其中表示实体eijk的向量,表示检索词q的向量,由q中所有切分项的词向量计算均值求得。表示两个向量之间的距离,公式如下:(3)候选实体与同一搜索会话中已识别的实体之间相关度lf3,计算候选实体eijk与同一个搜索会话中已有检索词中识别出的实体集合e的语义相关度,公式如下:其中实体集合e的向量由对集合中单个实体的向量计算均值求得。(4)候选实体与同一搜索会话中已有检索词之间的相关度lf4,计算候选实体eijk与同一个会话中已有的检索词集合q的语义相关度,公式如下:其中表示同一会话中已有检索词集合q的向量,其值为q中包含的词的向量均值。下面再介绍一下每一个实体链接候选结果的5个全局特征值的计算,每一个实体链接候选结果的全局特征值包括切分粒度、该实体链接候选结果包含的各提及与检索词中其他词的相关度、该实体链接候选结果包含的各提及之间的相关度、该实体链接候选结果包含的各实体之间的相关度以及该实体链接候选结果中所有实体与同一搜索会话中已识别的实体之间的相关度。(5)全局特征中的切分粒度gf1计算切分的程度,公式如下:其中#term_sequences(s)表示当前切分中词块的总数目,#words(q)表示检索词中切分项的数量。(6)全局特征中的候选结果包含的提及与检索词中其他词的相关度gf2,计算当前实体链接候选结果中所有的提及与检索词中其他词的相关度平均值,公式如下:其中q/m表示检索词中除了提及m的其他切分项的集合,而表示q/m的向量,其值为q/m中所有切分项词向量平均值,m表示当前切分中所有的提及。(7)全局特征中的候选结果中各提及之间相关度gf3,计算当前实体链接候选结果中所有提及与其他提及的相关度平均值,公式如下:其中m/m表示当前切分除了提及m以外其他提及的集合,表示m/m的向量,其值为m/m中所有提及向量的平均值。(8)全局特征中的候选结果中各实体之间相关度gf4,计算当前实体链接候选结果中所有的实体与其他候选实体相关度的平均值,公式如下:其中e表示当前切分中所有的实体,e/e表示除了实体e以外其他实体的集合,表示e/e的向量,其值为e/e中所有实体的向量平均值。(9)全局特征中的候选结果中所有实体与同一搜索会话的已识别实体之间相关度gf5计,计算当前实体链接候选结果中所有实体与同一搜索会话中已识别实体集合的相关度平均值,公式如下:其中es表示同一会话中已有的检索词已经识别的所有实体,是es的向量,其值为es中所有实体的向量平均值。上述计算出了每一个实体链接候选结果的4个局部特征和5个全局特征值,使用svmrank计算每一个实体链接候选结果的每一个局部特征值的权值以及每一个全局特征值的权值。svmrank是一种基于支持向量机(supportvectormachine)的排序学习算法。以一组具有实体链接标注结果的检索词作为训练数据,使用svmrank算法,学习获得上述特征的权重,用于计算实体链接候选结果的分数。局部特征的权重和全局特征的权重是在两个独立的学习过程中获得。对于局部特征,将训练数据中已标注的每个实体链接<mk,ek>作为正例,相同提及mk对应的其他候选实体链接{<mk,ek′>|ek′∈ek,ek′≠ek}作为反例,基于svmrank学习获得局部特征的权重向量使得以下式子得到满足:其中,为长度为4的局部特征向量。对于全局特征,将训练数据中的每个检索词整体标注结果r作为正例,将实体链接过程中产生的其他实体链接候选结果{rij|rij∈r(qi),rij≠r}作为反例,基于svmrank学习获得全局特征的权重向量使得以下式子得到满足:其中,为长度为5的局部特征向量。本专利使用上述从训练数据中学习局部特征和全局特征的权重,基于此权重计算实体链接候选结果分值,使用如下的公式计算每一个实体链接候选结果的分数:其中,rij为实体链接候选结果,ωj为局部特征值的权值向量中第j个权值,lfj为4个局部特征值中第j个特征值,μk为全局特征的权重向量中第k个权值,gfk为全局特征值中第k个特征值,score(rij)为检索词第i种切分对应的第j个实体链接候选结果的分数,m、n均为正整数。计算出检索词的每一个实体链接候选结果的分数后,选择分数最高的链接结果作为检索词的最佳实体链接结果输出。本实施例首先基于实体链接语料来生成所需的词语、提及以及实体的向量模型,并抽取实体提及字典;然后,结合搜索会话提供的语义信息以及用户点击确认的实体链接结果,对检索词的每一种实体链接候选结果计算相应的局部特征和全局特征,使用机器学习方法svmrank从训练数据得到所有特征的权值,计算候选结果的分数,分数最高的实体链接候选结果为最后的链接结果,得到了较高的准确率和召回率,对比现在的研究方法具有明显优势。参见图2,为本发明另一个实施例的检索词的实体链接系统,包括生成模块21、切分模块22、判断模块23、提取模块24、组合模块25和确定模块26。生成模块21,用于利用知识库中的训练语料生成实体提及字典和词语、提及、实体的向量模型。其中,参见图3,生成模块21包括第一生成单元211和第二生成单元212。第一生成单元211,用于将知识库中的实体链接信息处理成预定格式,并生成实体提及字典,所述实体链接信息为提及指向实体的链接,所述实体提及字典中包括提及以及该提及对应的候选实体组合。第二生成单元212,用于生成词语、提及、实体的向量模型,通过对语料中标注的实体链接进行处理,形成由词语、提及、实体组成的文本,在处理完的语料上训练skip-gram模型,获得词语、提及、实体的低维向量。切分模块22,用于对检索词进行切分,得到检索词的所有切分形式,得到每一种切分形式后的多个词项。判断模块23,用于判断每一种切分后的每一个词项是否为提及。所述判断模块23,具体用于:判断每一种切分后的每一个词项在所述实体提及字典的提及表中是否有对应匹配的提及,若有,则该词项是提及,否则,该词项不是提及。提取模块24,用于当所述判断模块23判断出词项为提及时,从所述实体提及字典中提取该提及的候选实体,遍历所有词项,得到每一种切分对应候选实体集合。组合模块25,用于对每一种切分对应的所有候选实体集合中的实体进行全组合,形成多个实体链接候选结果,遍历检索词的每一种切分,得到检索词对应的所有的实体链接候选结果。确定模块26,用于利用所述词语、提及、实体的向量模型对所有的实体链接候选结果进行打分排序,选择分数最高的候选结果确定为检索词的最佳实体链接结果输出。其中,参见图4,确定模块26包括第一计算单元261、第二计算单元262和第三计算单元263。第一计算单元261,用于根据生成的所述词语、提及、实体的向量模型,计算每一个实体链接候选结果的多个局部特征值以及多个全局特征值;第二计算单元262,用于使用svmrank计算每一个实体链接候选结果的每一个局部特征值的权值以及每一个全局特征值的权值;第三计算单元263,用于根据每一个实体链接候选结果的每一个局部特征值、每一个全局特征值、每一个局部特征值的权值以及每一个全局特征值的权值,计算每一个实体链接候选结果的分数。本发明提供的一种检索词的实体链接方法及系统,首先基于实体链接语料来生成所需的词语、提及以及实体的向量模型,并抽取实体提及字典;然后,结合搜索会话提供的语义信息以及用户点击确认的实体链接结果,对检索词的每一种实体链接候选结果计算相应的局部特征和全局特征,使用机器学习方法svmrank训练数据得到所有特征的权值,计算候选结果的分值,分值最高的实体链接候选结果作为最后的链接结果,得到了较高的准确率和召回率,对比现在的研究方法具有明显的优势。最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1