一种基于时间线的病历文本医学知识发现方法与流程
本发明涉及一种基于时间线的病历文本医学知识发现方法,特别是涉及对包含时间信息的电子病历文本结构化和医疗知识发现的方法。
背景技术:
随着医疗信息系统的发展,电子病历中数据的复杂性不断增强、数据量不断增大。电子病历包含许多有价值的信息,比如说,电子病历的诊断过程、诊断结果以及其中尚未发现的医疗知识。其中,包含时间信息的叙事性病历文本是非常重要的信息。在电子病历中,一般会记录患者患病的时间、症状和不良反应,而这些信息一般存在于以自然语言描述的文本中,在文本中基于时间信息的医疗知识挖掘是本方法的重点。
本专利提出基于时间信息的电子病历文本结构化和知识发现方法,通过基于规则匹配的语义分析技术,自动从电子病历中现病史、家族史中提取患者的病情发展时间线,在每一个时间点描述发生的生理信息变化和发生的事件,并通过关联疾病库、药品库等信息,用于疾病分析和预测。该方法的提出,能解决非结构化的电子病历文本中患者信息难以定量分析的问题,对有效利用电子病历的非结构化数据具有借鉴意义。
技术实现要素:
针对上述问题,本发明的目的是提供一种能识别电子病历非结构化文本中时间信息,并构建基于时间线的患者病情发展模型,用于识别其中医疗知识的方法。
为实现上述目的,本发明采取以下技术方案:提供一种基于时间线的病历文本医学知识发现方法,包括以下步骤:
(1)构建病历文本分析库存储患者的电子病历信息,包括现病史、个人史和家族史的病历叙事性文本信息;
(2)构建病历时间文本规则库,其中定义能识别中文时间表达式的正则表达式;
(3)构建医学知识库,其中,本方法包括疾病知识库、药品知识库和不良反应库;
(4)对病历样本库中的病历文本进行按句号、逗号进行拆分;
(5)对步骤(4)中的产生的文本块(没有标点符号的文本)使用语义分析工具进行中文分词,并对每个词的词性标注,标注成名词、动词、介词等;
(6)对步骤(5)中各个词语依据步骤(2)的时间规则进行正则表达式匹配,寻找出时间名词,并进行标记;
(7)根据步骤(5)中识别的时间文本先后顺序,从句子的层次重新对病历文本进行排序,构建基于时间线的XML文本结构;
(8)依据步骤(3)的医学知识库,从已经标注词性的文本中进行二次标注,将其中的药品、疾病知识和不良反应进一步在文本中标注出来;
(9)从文本块中取连续两个词、三个词或n个词,提取中其中的生理指标和事件信息。
所述的步骤(3)中,疾病知识库采用基于ICD-10编码的国际疾病分类库,结合了每种疾病对应的详细信息。药品知识库包含西药、中成药和中草药三类信息。药品不良反应库采用《WHO药品不良反应术语集》。
所述的步骤(5)中采用的语义分析工具是Stanford Natural Language Processing(Stanford NLP)语义分析工具包进行实现,先进行中文分词,然后利用语义分析工具对其中词语进行词性标注。
所述的步骤(6)使用的时间规则,包括计算具有年月日的绝对时间,如“2016年1月1日”,也包括识别如“几天后”的相对模糊的时间信息。对非绝对时间,根据最近的时间点,计算出该模糊时间的绝对时间。
所述的步骤(8)中第一次标注的形式如(W,T),其中W表示词语,T表示W的词性。第二次使用医学知识库记性标注,采用(W,T,C)表达,其中,C表示与医学知识库的关联关系,表示该词属于哪个词库,哪种信息(疾病、不良反应、药品)。
所述的步骤(9),在提取步骤(8)的内容后,对每一个文本块中的词语序列中相邻两词、相邻三词组合进行文本规则挖掘,其中具体包括以下步骤:
(91)按两个相邻词(键,值)来匹配,匹配Key-Value的键值对文本。
(92)按照三个词,匹配(时间、事件、描述)来寻找患者医学事件。
本发明由于采取以上技术方案,其具有以下优点:本发明根据电子病历中包含时间信息的文本的特征,(1)提取其中的时间信息节点,并根据时间顺序构建患者的病情发展模型,使得病情预测更容易;(2)利用现有的医学知识库,依赖时间信息标注其中的疾病、药品和不良反应信息,帮助医学研究者更好地发现潜在的医学知识。
附图说明
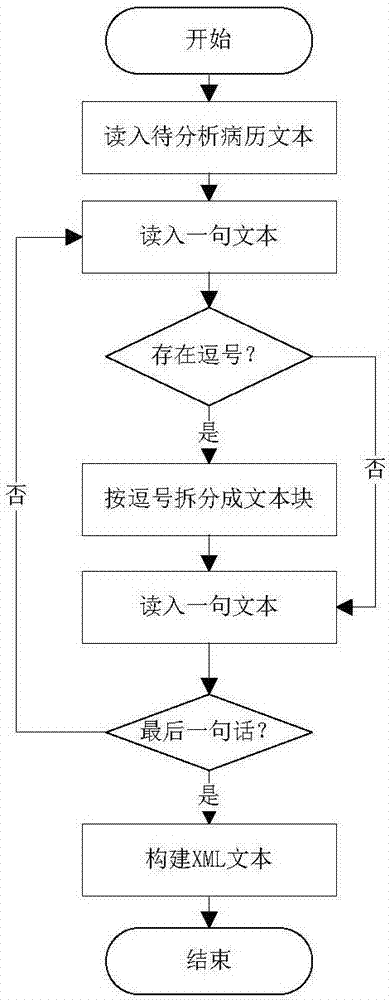
图1是本发明的流程图;
图2是步骤4病历文本按句式拆分的流程;
图3是步骤6匹配病历文本中时间信息流程;
图4是病历文本在结构化过程中数据模型的变化;
图5是步骤8中最终输出的XML结构。
具体实施方式
下面结合附图和实施例对本发明的进行详细的描述。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外,应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明提供一种构建便于医学知识发现的基于时间线患者病情发展模型的方法,如图1所示,包括以下步骤:
步骤1、定义了病历文本存储的数据结构,便于从医院中的电子病历系统中导出对应的数据和保存图1流程中产生的处理结果。分析库中的表结构至少包含的字段包括:电子病历ID、原始病历文本、句式拆分后的病历文本、词性标注后的病历文本,医学知识标注后的病历文本这五个字段;
步骤2、根据电子病历常见的中文时间信息表述形式,手动构建描述时间表达式的正则表达式规则库;
步骤3、构建医学知识库,在这里,主要包含三种医学知识,包括疾病知识、药品知识和不良反应文本。其中,疾病知识是基于国际疾病分类编码(ICD-10)构建的疾病词条库;药品知识库的药品分为三种:西药、中草药和中成药;不良反应库的词条来源于《WHO药品不良反应术语集》;
步骤4、对待分析的整段病历文本进行按句式进行拆分,如图2,其中,分隔符是中文的句号和逗号。如:病历文本“否认肝炎、结核、疟疾病史,高血压史、冠心病史20年。1992年曾患甲状腺癌根治术(中)。”,可以拆分成两句,第一句再拆分两个文本块。按照语法结构,一个句子包含若干用逗号分开的文本块。
步骤5、依据已拆分的病历文本,对其中的每一个文本块(不包含任何句号、逗号)使用语义分析工具,进行该文本块的词性标注。并将标注后的词语集合重新按照出现顺序排序,拼合成文本。其结果如:“高血压/NR,史/NN,、/PU,冠心/NN,病史/VV,20年/NT”。其中/NN等表示前面词的词性标记符号。
步骤6、根据从步骤5、中标注好的文本,依据时间表达规则库,识别其中术语时间信息的词语。对于模糊的时间信息,依据同属一句话或一段话的时间信息进行修正补充,其过程如图3所示;
步骤7、依据病历文本中的时间先后,重新对文本信息进行排序,构建出按时间先后排序的结构化XML文本。从原始文本到步骤7、过程中文本结构的形式变化如图4所示。
步骤8、在时间排序后的病历文本模型中,依据医学知识库,对药品术语、疾病术语和不良反应属于进行二次标注,也保留其词性;
步骤9、对文本块中词语进行两连续词、三连续词的获取,并依据规则分析,区分出其中的患者生理检验指标和特殊医疗事件,生理检验指标的文本如“WBC2.13×109/L、Hb102g/L、PLT177×10^9/L/L”。最终拆分的XML形式如图5所示。
步骤10、在上述步骤的构建的基于时间线的患者病情发展模型中,进行医学知识发现和分析。
- 还没有人留言评论。精彩留言会获得点赞!