循环流化床生活垃圾焚烧锅炉CO排放预测系统及方法与流程
本发明涉及能源工程领域,特别地,涉及一种循环流化床生活垃圾焚烧锅炉co排放预测系统及方法。
背景技术:
垃圾焚烧由于能够良好实现垃圾处理技术的减容化、减量化、无害化和资源化,近十几年内,在国家相关产业政策的引导下,国内垃圾焚烧行业取得了蓬勃的发展。从上世纪90年代开始,国内多家科研结构对中国城市生活垃圾(municipalsolidwaste,msw)燃烧机理进行了大量深入研究,掌握了混合收集、水分高、成分复杂的城市生活垃圾的燃烧特性,根据我国对煤、煤矸石等劣质燃料循环流化床(circulatingfluidizedbed,cfb)燃烧技术的开发经验的基础上,开发出了循环流化床垃圾焚烧锅炉,从1998年浙江大学开发的第一台流化床垃圾焚烧炉投入运行开始,表现出了适用于对国内高水分、热值偏低且波动性很大的生活垃圾进行大规模的焚烧处理的特点。目前,cfb垃圾焚烧技术已经在国内的多个城市进行了推广应用,截止2015年底,国内已建成垃圾焚烧锅炉70余台,日处理垃圾量6.9万吨,为我国的垃圾焚烧处理行业做出了重要的贡献。
锅炉尾部烟气co排放量是衡量锅炉是否经济环保运行的重要标志之一,能够直观的反映出当前锅炉的运行状态。co排放量越高表征锅炉的气体未完全燃烧热损失q3越大,锅炉的热效率越低,使锅炉运行的经济性下降。另一方面,《生活垃圾焚烧污染控制标准》(gb18485-2014)规定co排放浓度的1小时均值和24小时均值分别不得超过100mg/m3和80mg/m3,否则将面临环保部门停产整顿的处罚。同时,生产人员和管理人员有可能需要某种运行工况下co的排放情况,以便于对锅炉的运行进行优化调整。因此,构建一个足够精度的co排放预测模型具有十分重要的意义。
国内外的研究人员对循环流化床锅炉的co排放特性建模进行了研究,主要有以下几种方法。一种是根据cfb锅炉燃烧动力学、流体力学、传热传质的特性,在经过合理的简化假设之后建立,通过数学描述的方式建立机理模型。这种方法能够反映co排放量的变化趋势,但由于假设模型和真实模型之间的偏差而无法达到足够的精确度;另一种方法是在大量的试验台试验或者现场试验的基础上,通过回归分析的方法建立关于co排放变化特性的经验模型。这种方法需要耗费大量的人力物力,时间成本高,同时无法保证试验覆盖所有的工况,具有一定局限性;第三种方法利用计算流体力学、计算传热学和化学反应的简化机理模拟炉内燃烧过程,精确地求解co的生成情况,显示了良好的效果具有很大的发展潜力。但这种方法主要受限于流体力学模型和化学反应的简化机理与实际情况的差距,需要高端的计算机配置和很长的计算时间,因此采用这种方法仍处于初步发展阶段。此外,cfb垃圾焚烧锅炉的给料系统均匀性较差,入炉垃圾的热值波动性大、组分复杂、多边性强,是co排放建模过程中的面临的主要困难之一,它要求所建立的co排放特性模型具有良好的自适应能力,上述三种建模方法在这方面仍有所欠缺。
随着电子技术、计算机技术和信息技术的发展,集散控制系统(distributedcontrolsystem,dcs)广泛的应用于cfb生活焚烧锅炉的运行过程,包含温度、压力、流量等参数在内的过程数据都被完善得保存下来,这些历史数据中包含丰富过程信息,是人们认识和了解生产过程的重要途径之一,具有很高的挖掘价值。利用神经网络(artificialneuralnetwork,ann)、支持向量机(supportvectormachine,svm)和随机森林(randomforest,rf)等智能算法进行数据挖掘建模是当前非常受欢迎的一种建模思想,它的建模过程简洁清晰,避免了对建模对象进行深入的机理分析,尤其适用于那些过程十分复杂且为完全被认识清楚的过程。随机森林算法一种用于解决分类或者回归等问题的集成学习方法,该方法综合了bagging集成学习、cart决策树算法和特征随机选取思想,具有优秀的自学习能力、非线性映射能力和泛化能力。相较于神经网络和支持向量机算法,随机森林算法具有算法设置参数少、数据集适应力高、抗噪声能力强、训练速度快等优点,同时,它能够处理高维数据,并且能够得到变量的重要性排序,因此在处理这种多变量耦合的复杂的工业过程时具有更好的表现。
另外,锅炉运行过程是一个时变的过程,包括燃料特性和设备特性都是随着时间变化的,因此要求co预测模型能够不断的更新。co排放预测系统不但要满足要对模型进行训练和更新,还要将模型的计算结果送往不同的场所,所以,需要合理设置系统的架构。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种循环流化床生活垃圾焚烧锅炉co排放的预测系统及方法。本发明在分析cfb生活垃圾焚烧锅炉运行机理的基础上,选择co排放预测模型的输入变量,采用gammatest算法确定训练样本的个数,利用随机森林算法对样本集进行训练建模,并自适应地对co排放预测模型进行更新,最终利用异构计算环境构建co排放预测系统。
本发明解决其技术问题所采用的技术方案是:一种循环流化床生活垃圾焚烧锅炉co排放的实时预测系统。该系统与循环流化床锅炉的集散控制系统以及生产管理系统相连,包括数据通讯接口和上位机,在上位机中对co排放预测模型进行训练和更新,然后将预测结果通过通讯接口送往集散控制系统和生产管理系统,所述上位机包括:
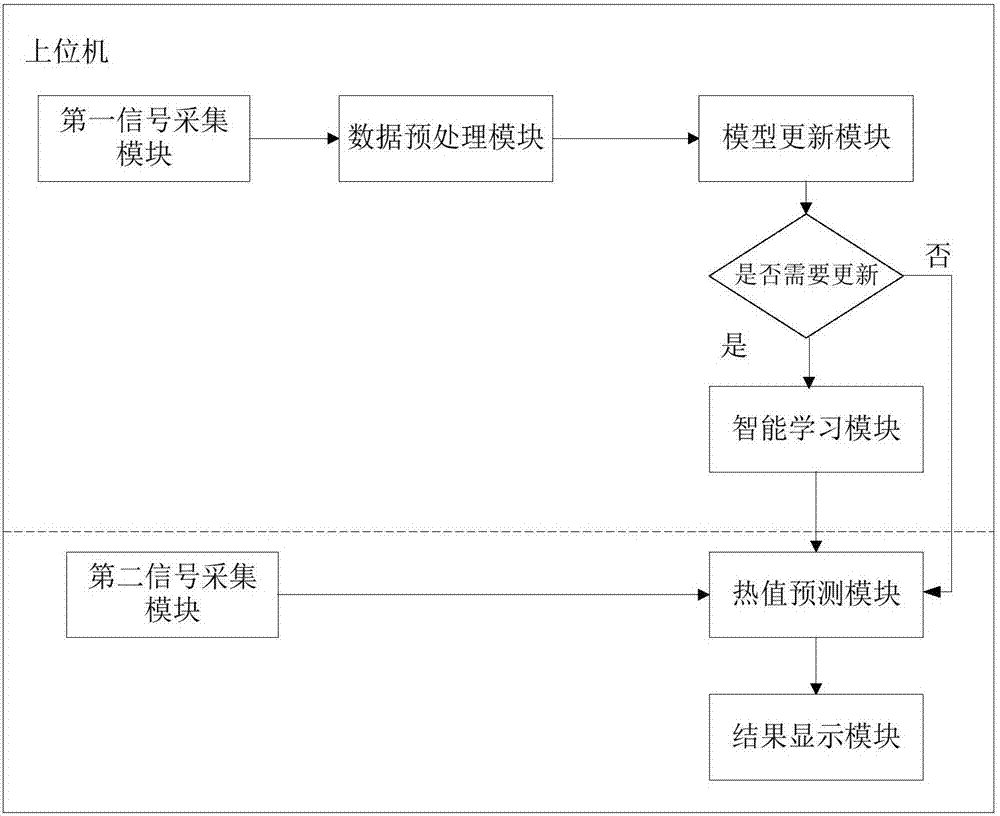
第一信号采集模块。该模块用于采集cfb生活垃圾焚烧锅炉在焚烧指定生活垃圾时的运行工况状态参数和操作变量,并组成垃圾热值预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数;
数据预处理模块。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的训练样本x*(m×n)。预处理过程采用以下步骤进行:
1.1)根据拉伊达准则,剔除训练样本x(m×n)中的野值;
1.2)剔除锅炉停炉运行工况,锅炉停炉时炉膛给煤机和给料机的开度为零,并且炉膛中温度接近常温;
1.3)剔除炉膛压火运行状况,锅炉压火时一次风机、二次风机引风机炉膛给煤机和给料机的开度为零,但是炉膛密相区的温度维持在350℃~450℃;
1.4)剔除给料机堵塞工况,给料机堵塞需要运行人员通过给料口的摄像头拍摄的画面对给料情况进行判断,给料机堵塞时,运行人员会显著地调高给料机的开度,反映在运行数据上,即给料机的开度大于35%;
1.5)数据归一化处理。按照式(1)将数据变量映射到[01]的区间内。
式中xj表示第j变量所组成的向量,min()表示最小值,max()表示最大值。
模型更新模块。该模块对co排放预测模型的性能进行判断,并决定是否对预测模型进行更新,当co排放量与模型预测排放量的误差超过±5%时,更新模型。
智能学习模块。智能学习模块是co排放预测系统的核心部分,该模块先利用gammatest算法寻找最优的训练样本尺寸,然后利用随机森林算法对样本进行训练学习,算法步骤如下:
1)利用gammatest算法寻找最优的训练样本尺寸。gammatest算法是对所有光滑函数均适用的非参数估计方法,该方法不关注输入输出数据之间的任何参数关系,只对输入输出数据进行计算即可得到模型的噪声方差,对于如下形式的数据集
{(xi,yi),1≤i≤m}(2)
式中,x∈rn表示输入,对应的输出标量为y∈r。
gammatest假定的模型关系是:
y=f(x1,…,xn)+r(3)
式中,f是一个光滑函数,r是一个表示数据噪声的随机量。不失一般性,可假定r的均值为0(否则可在f中加入常数项),方差为var(y)。gammatest就是计算一个统计量γ,用它来评价输出量的方差,显然,如果数据的关系符合光滑模型,并且没有噪声,这个方差是0。γ的计算过程如下:
1.1)计算输入数据的距离统计量。用xi表示第i个输入数据,xn[i,k]表示输入样本的第k近邻域点,计算如下统计量:
式中,|·|表示欧拉距离,p为最远邻近距离(nearestneighbor)。
1.2)计算输出数据的距离统计量。用yi表示第i个输出数据,yn[i,k]表示输出样本的第k近邻域点,计算如下统计量:
式中符号的意义同(4)式。
1.3)计算统计量γ。为了计算γ,分别计算邻近距离从1到p的统计量(δm(1),γm(1)),(δm(2),γm(2)),…,(δm(p),γm(p))。对这p个统计量构造一元线性回归模型,用最小二乘法进行拟合,得到的一次线性函数的截距就是gammatest统计量γ,γ值越小表示样本中的噪声越小。
定义另一个统计量vratio:
式中,δ2(y)表示输出y的方差。vratio可以用来评价光滑模型对该数据的模拟能力,vratio越接近0,表示该模型的预测性能越好。
2)将gammatest算法寻优得到最优训练样本用于构建随机森林模型,随机森林是一个由一组决策树分类器{h(x,θk),k=1,2,…,k}组成的分类器,其中θk是服从独立同分布的随机向量,k表示随机森林中决策树的个数,在给定自变量x下,每个决策树分类器通过投票来决定最优的分类结果。如果把决策树看成分类任务中的一个专家,随机森林就是许多专家在一起对某种任务进行分类。分类树的实现按照自顶向下、递归分裂的原则进行,在所有分类树中,根结点拥有全部训练样本数据,训练过程依据纯度最小原则,将该节点分裂为左节点和右节点,两个节点分别设定为训练数据的一个子集,按照相同的方式使节点继续分裂下去,直到满足分支终止条件而停止训练,若在某个节点上的所有分类数据来自同一个类别,则该节点的纯度为0,又称为gini值。假设集合t中包含n个类别的记录,并分裂成r个部分n1,n2,……,nr,每个部分对应的集合为t1,t2,……,tr,那么这个分裂的gini系数按照公式(7)和(8)计算:
式中,t指总的训练样本集,pj代表类别j出现的频率,ginisplit(t)指所有类别的gini值。
生成随机森林的具体步骤如下:
2.1)从原始训练数据集t中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,作为根结点开始训练。
2.2)设总共有n个特征,则在每一棵树的每个节点处随机抽取mtry个特征(mtry≤n),通过计算每个特征蕴含的信息量,在mtry个特征中选择一个最具有分类能力的特征进行节点分裂。
2.3)每棵树最大限度地生长,不做任何剪裁。
2.4)将生成的多棵树组成随机森林,对于回归问题,预测输出为所有树输出值的平均值,得到训练好的co排放预测模型。
3)利用训练好的co排放预测模型和测试样本对模型进行测试,如果模型的预测co排放量和实际co排放量的相对预测误差超过±5%时,则重新选择样本进行训练,直到满足精度要求为止。
第二信号采集模块。用于从数据库中选择需要预测co排放的运行工况,或者实时地采集当前锅炉的运行工况。
预测模块。该模块用于对指定的样本进行co排放预测,或者对当前锅炉运行工况下的co排放进行实时预测。
结果显示模块。显示co排放的预测结果,或者对co排放的预测结果进行统计分析。
一种循环流化床生活垃圾焚烧锅炉co排放预测方法,该方法包括以下步骤:
1)分析循环流化床生活垃圾焚烧锅炉的运行机理和co生成机理,选择垃圾的给料量、给煤量、一次风量、二次风量、烟气含氧量、炉膛负压、床层温度、炉膛稀相区温度作为co排放预测模型的输入变量。
2)采集训练样本。按设定的时间间隔从数据库中采集输入变量的历史数据,或者采集指定工况下的运行参数,组成co排放预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数,同时采集与之对应的co排放量作为模型的输出训练样本y(m×1);
3)数据预处理。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的输入变量的训练样本x*(m×n)和输出变量的训练样本y*(m×1)。
4)利用gammatest算法寻找最优的训练样本尺寸。gammatest算法是对所有光滑函数均适用的非参数估计方法,该方法不关注输入输出数据之间的任何参数关系,只对输入输出数据进行计算即可得到模型的噪声方差,对于如下形式的数据集:
{(xi,yi),1≤i≤m}(1)
式中,x∈rn表示输入,对应的输出标量为y∈r。
gammatest假定的模型关系是:
y=f(x1,…,xn)+r(2)
式中,f是一个光滑函数,r是一个表示数据噪声的随机量。不失一般性,可假定r的均值为0(否则可在f中加入常数项),方差为var(y)。gammatest就是计算一个统计量γ,用它来评价输出量的方差,显然,如果数据的关系符合光滑模型,并且没有噪声,这个方差是0。γ的计算过程如下:
4.1)计算输入数据的距离统计量。用xi表示第i个输入数据,xn[i,k]表示输入样本的第k近邻域点,计算如下统计量:
式中,|·|表示欧拉距离,p为最远邻近距离(nearestneighbor)。
4.2)计算输出数据的距离统计量。用yi表示第i个输出数据,yn[i,k]表示输出样本的第k近邻域点,计算如下统计量:
式中符号的意义同(3)式。
4.3)计算统计量γ。为了计算γ,分别计算邻近距离从1到p的统计量(δm(1),γm(1)),(δm(2),γm(2)),…,(δm(p),γm(p))。对这p个统计量构造一元线性回归模型,用最小二乘法进行拟合,得到的一次线性函数的截距就是gammatest统计量γ,γ值越小表示样本中的噪声越小。
定义另一个统计量vratio:
式中,δ2(y)表示输出y的方差。vratio可以用来评价光滑模型对该数据的模拟能力,vratio越接近0,表示该模型的预测性能越好。
5)将gammatest算法寻优得到最优训练样本用于构建随机森林模型,随机森林是一个由一组决策树分类器{h(x,θk),k=1,2,…,k}组成的成分类器,其中θk是服从独立同分布的随机向量,k表示随机森林中决策树的个数,在给定自变量x下,每个决策树分类器通过投票来决定最优的分类结果。如果把决策树看成分类任务中的一个专家,随机森林就是许多专家在一起对某种任务进行分类。分类树的实现按照自顶向下、递归分裂的原则进行,在所有分类树中,根结点拥有全部训练样本数据,训练过程依据纯度最小原则,将该节点分裂为左节点和右节点,两个节点分别设定为训练数据的一个子集,按照相同的方式使节点继续分裂下去,直到满足分支终止条件而停止训练,若在某个节点上的所有分类数据来自同一个类别,则该节点的纯度为0,又称为gini值。假设集合t中包含n个类别的记录,并分裂成r个部分n1,n2,……,nr,每个部分对应的集合为t1,t2,……,tr,那么这个分裂的gini系数按照公式(6)和(7)计算:
式中,t指总的训练样本集,pj代表类别j出现的频率,ginisplit(t)指所有类别的gini值。
生成随机森林的具体步骤如下:
5.1)从原始训练数据集t中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,作为根结点开始训练。
5.2)设总共有n个特征,则在每一棵树的每个节点处随机抽取mtry个特征(mtry≤n),通过计算每个特征蕴含的信息量,在mtry个特征中选择一个最具有分类能力的特征进行节点分裂。
5.3)每棵树最大限度地生长,不做任何剪裁。
5.4)将生成的多棵树组成随机森林,对于回归问题,预测输出为所有树输出值的平均值,得到训练好的co排放预测模型。
6)利用训练好的co排放预测模型和测试样本对模型进行测试,如果模型的预测co排放量和实际co排放量的相对预测误差超过±5%时,则重新选择样本进行训练,直到满足精度要求为止。
7)模型自适应更新。当co排放量与模型预测排放量的误差超过±5%时,立即更新模型。
本发明的有益效果是:在利用循环流化床生活垃圾焚烧锅炉的运行机理和运行历史数据中隐含的知识的基础上,采用gammatest算法和随机森林集成建模的方法,构建了一种快速经济且自适应更新的系统和方法对锅炉尾部烟气co排放进行实时预测,避开了繁琐复杂的机理建模工作。其中,利用随机森林算法的非线性映射能力、泛化能力和实时预测能力来表征co排放的动态变化特性,为运行人员和设计人员掌握了解co排放的变化特性提供新的途径;利用gammatest算法获取最优的训练样本,避免了模型的在训练的时候出现过拟合和欠拟合的状况。整个建模过程逻辑清晰,需要设置的参数较少,建模自动化程度高,易于掌握和推广。训练良好的co排放预测模型可以服务那些基于模型的控制算法,或者作为软测量仪表与co硬件测量系统相互补充校核。
附图说明
图1是本发明所提出的系统的结构图。
图2是本发明所提出的上位机系统的结构图。
图3是本发明所采用随机森林模型的系统结构图。
图4是本发明所提出的智能建模方法的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
实施例1
参照图1、图2、图3、图4,本发明提供的一种循环流化床生活垃圾焚烧锅炉co排放预测系统,包括循环流化床生活垃圾焚烧锅炉,用于该锅炉运行控制的集散控制系统,数据通讯接口,数据库以及上位机。数据库通过数据通讯接口从集散控制系统中读取数据,并用于上位机的训练学习和测试,上位机通过数据通讯接口与集散控制系统进行数据交换,所述的上位机包括在线学习、在线更新、验证部分和在线预测部分。具体包括:
第一信号采集模块。该模块用于采集cfb生活垃圾焚烧锅炉在焚烧指定生活垃圾时的运行工况状态参数和操作变量,并组成垃圾热值预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数;
数据预处理模块。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的训练样本x*(m×n)。预处理过程采用以下步骤进行:
1.1)根据拉伊达准则,剔除训练样本x(m×n)中的野值;
1.2)剔除锅炉停炉运行工况,锅炉停炉时炉膛给煤机和给料机的开度为零,并且炉膛中温度接近常温;
1.3)剔除炉膛压火运行状况,锅炉压火时一次风机、二次风机引风机炉膛给煤机和给料机的开度为零,但是炉膛密相区的温度维持在350℃~450℃;
1.4)剔除给料机堵塞工况,给料机堵塞需要运行人员通过给料口的摄像头拍摄的画面对给料情况进行判断,给料机堵塞时,运行人员会显著地调高给料机的开度,反映在运行数据上,即给料机的开度大于35%;
1.5)数据归一化处理。按照式(1)将数据变量映射到[01]的区间内。
式中xj表示第j变量所组成的向量,min()表示最小值,max()表示最大值。
模型更新模块。该模块对co的排放预测模型的性能进行判断,并决定是否对预测模型进行更新,当co排放量与模型预测排放量的误差超过±5%时,更新模型。
智能学习模块。智能学习模块是co排放预测系统的核心部分,该模块先利用gammatest算法寻找最优的训练样本尺寸,然后利用随机森林算法对样本进行训练学习,算法步骤如下:
1)利用gammatest算法寻找最优的训练样本尺寸。gammatest算法是对所有光滑函数均适用的非参数估计方法,该方法不关注输入输出数据之间的任何参数关系,只对输入输出数据进行计算即可得到模型的噪声方差,对于如下形式的数据集
{(xi,yi),1≤i≤m}(2)
式中,x∈rn表示输入,对应的输出标量为y∈r。
gammatest假定的模型关系是:
y=f(x1,…,xn)+r(3)
式中,f是一个光滑函数,r是一个表示数据噪声的随机量。不失一般性,可假定r的均值为0(否则可在f中加入常数项),方差为var(y)。gammatest就是计算一个统计量γ,用它来评价输出量的方差,显然,如果数据的关系符合光滑模型,并且没有噪声,这个方差是0。γ的计算过程如下:
1.1)计算输入数据的距离统计量。用xi表示第i个输入数据,xn[i,k]表示输入样本的第k近邻域点,计算如下统计量:
式中,|·|表示欧拉距离,p为最远邻近距离(nearestneighbor)。
1.2)计算输出数据的距离统计量。用yi表示第i个输出数据,yn[i,k]表示输出样本的第k近邻域点,计算如下统计量:
式中符号的意义同(4)式。
1.3)计算统计量γ。为了计算γ,分别计算邻近距离从1到p的统计量(δm(1),γm(1)),(δm(2),γm(2)),…,(δm(p),γm(p))。对这p个统计量构造一元线性回归模型,用最小二乘法进行拟合,得到的一次线性函数的截距就是gammatest统计量γ,γ值越小表示样本中的噪声越小。
定义另一个统计量vratio:
式中,δ2(y)表示输出y的方差。vratio可以用来评价光滑模型对该数据的模拟能力,vratio越接近0,表示该模型的预测性能越好。
2)将gammatest算法寻优得到最优训练样本用于构建随机森林模型,随机森林是一个由一组决策树分类器{h(x,θk),k=1,2,…,k}组成的成分类器,其中θk是服从独立同分布的随机向量,k表示随机森林中决策树的个数,在给定自变量x下,每个决策树分类器通过投票来决定最优的分类结果。如果把决策树看成分类任务中的一个专家,随机森林就是许多专家在一起对某种任务进行分类。分类树的实现按照自顶向下、递归分裂的原则进行,在所有分类树中,根结点拥有全部训练样本数据,训练过程依据纯度最小原则,将该节点分裂为左节点和右节点,两个节点分别设定为训练数据的一个子集,按照相同的方式使节点继续分裂下去,直到满足分支终止条件而停止训练,若在某个节点上的所有分类数据来自同一个类别,则该节点的纯度为0,又称为gini值。假设集合t中包含n个类别的记录,并分裂成r个部分n1,n2,……,nr,每个部分对应的集合为t1,t2,……,tr,那么这个分裂的gini系数按照公式(7)和(8)计算:
式中,t指总的训练样本集,pj代表类别j出现的频率,ginisplit(t)指所有类别的gini值。
生成随机森林的具体步骤如下:
2.1)从原始训练数据集t中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,作为根结点开始训练。
2.2)设总共有n个特征,则在每一棵树的每个节点处随机抽取mtry个特征(mtry≤n),通过计算每个特征蕴含的信息量,在mtry个特征中选择一个最具有分类能力的特征进行节点分裂。
2.3)每棵树最大限度地生长,不做任何剪裁。
2.4)将生成的多棵树组成随机森林,对于回归问题,预测输出为所有树输出值的平均值,得到训练好的co排放预测模型。
3)利用训练好的co排放预测模型和测试样本对模型进行测试,如果模型的预测co排放量和实际co排放量的相对预测误差超过±5%时,则重新选择样本进行训练,直到满足精度要求为止。
第二信号采集模块。用于从数据库中选择需要预测co排放的运行工况,或者实时地采集当前锅炉的运行工况。
预测模块。该模块用于对指定的样本进行co排放预测,或者对当前锅炉运行工况下的co排放进行实时预测。
结果显示模块。显示co排放的预测结果,或者对co排放的预测结果进行统计分析。
实施例2
参照图1、图2、图3、图4,本发明提供的一种循环流化床生活垃圾焚烧锅炉co排放预测方法,该方法包括以下步骤:
1)分析循环流化床生活垃圾焚烧锅炉的运行机理和co生成机理,选择垃圾的给料量、给煤量、一次风量、二次风量、烟气含氧量、炉膛负压、床层温度、炉膛稀相区温度作为co排放预测模型的输入变量。
国内的城市生活垃圾多为混合收集,导致入厂、入炉垃圾成分较为复杂,一般主要包括厨余垃圾、纸、塑料、橡胶、织物、木头、竹子以及无机物等主要成分,表现出低热值、高水分和波动性较大的特征。为了保证循环流化床垃圾焚烧锅炉的稳定燃烧,通常会添加煤作为辅助燃料。垃圾在循环流化床中的燃烧是一个十分复杂的剧烈物理化学变化过程,垃圾在进入炉膛之后会经历几个过程:干燥加热、挥发分析出及燃烧、焦炭燃烧。垃圾中质轻易碎的组分如纸纸张、塑料以及细颗粒等会在流化风的作用下进入炉膛上部,经历干燥、挥发分的析出及燃烧以及残炭的燃烧等一系列过程;而密度较大、含水率高以及颗粒尺寸较大的组分如木头、厨余垃圾等终端速度大于流化速度的组分会落入密相区,并在密相区中被床料加热、燃烧,与煤的热量释放规律不同,垃圾中高水分低热值的组分会在密相区中吸收大量的热,而大量的挥发分在悬浮段燃烧。
cfb尾部烟气中co排放量是由炉膛中的温度场分布状况、氧气浓度分布状况和有机挥发分浓度的分布状况决定的。给煤量、给料量和一二次风量共同决定了温度场分布、氧气浓度分布和有机挥发分浓度分布,他们通过床层温度、炉膛稀相区温度和烟气含氧量反映出来。尤其需要注意的是,在实际运行过程中,会出现温度场、组分场分布不均的情况,而通过烟气氧量测点和炉膛温度测点无法完全获知,而炉膛负压的波动情况可以在一定程度上反映它们的波动情况,因此也将它作为模型的输入变量之一。
2)采集训练样本。按设定的时间间隔从数据库中采集输入变量的历史数据,或者采集指定工况下的运行参数,组成co排放预测模型输入变量的训练样本矩阵x(m×n),m表示样本个数,n表示变量的个数,同时采集与之对应的co排放量作为模型的输出训练样本y(m×1);
3)数据预处理。对x(m×n)进行粗大误差处理和随机误差处理,以摒除那些并不是反映锅炉正常运行工况的虚假信息,将锅炉停炉、压火、给料机堵塞等异常工况排除掉,为了避免预测模型的参数之间量纲和数量级的不同对模型性能造成的不良影响,训练样本输入变量均经过归一化处理后映射到[0,1]区间内,得到标准化后的输入变量的训练样本x*(m×n)和输出变量的训练样本y*(m×1)。
4)利用gammatest算法寻找最优的训练样本尺寸。gammatest算法是对所有光滑函数均适用的非参数估计方法,该方法不关注输入输出数据之间的任何参数关系,只对输入输出数据进行计算即可得到模型的噪声方差,对于如下形式的数据集:
{(xi,yi),1≤i≤m}(1)
式中,x∈rn表示输入,对应的输出标量为y∈r。
gammatest假定的模型关系是:
y=f(x1,…,xn)+r(2)
式中,f是一个光滑函数,r是一个表示数据噪声的随机量。不失一般性,可假定r的均值为0(否则可在f中加入常数项),方差为var(y)。gammatest就是计算一个统计量γ,用它来评价输出量的方差,显然,如果数据的关系符合光滑模型,并且没有噪声,这个方差是0。γ的计算过程如下:
4.1)计算输入数据的距离统计量。用xi表示第i个输入数据,xn[i,k]表示输入样本的第k近邻域点,计算如下统计量:
式中,|·|表示欧拉距离,p为最远邻近距离(nearestneighbor)。
4.2)计算输出数据的距离统计量。用yi表示第i个输出数据,yn[i,k]表示输出样本的第k近邻域点,计算如下统计量:
式中符号的意义同(3)式。
4.3)计算统计量γ。为了计算γ,分别计算邻近距离从1到p的统计量(δm(1),γm(1)),(δm(2),γm(2)),…,(δm(p),γm(p))。对这p个统计量构造一元线性回归模型,用最小二乘法进行拟合,得到的一次线性函数的截距就是gammatest统计量γ,γ值越小表示样本中的噪声越小。
定义另一个统计量vratio:
式中,δ2(y)表示输出y的方差。vratio可以用来评价光滑模型对该数据的模拟能力,vratio越接近0,表示该模型的预测性能越好。
5)将gammatest算法寻优得到最优训练样本用于构建随机森林模型,随机森林是一个由一组决策树分类器{h(x,θk),k=1,2,…,k}组成的成分类器,其中θk是服从独立同分布的随机向量,k表示随机森林中决策树的个数,在给定自变量x下,每个决策树分类器通过投票来决定最优的分类结果。如果把决策树看成分类任务中的一个专家,随机森林就是许多专家在一起对某种任务进行分类。分类树的实现按照自顶向下、递归分裂的原则进行,在所有分类树中,根结点拥有全部训练样本数据,训练过程依据纯度最小原则,将该节点分裂为左节点和右节点,两个节点分别设定为训练数据的一个子集,按照相同的方式使节点继续分裂下去,直到满足分支终止条件而停止训练,若在某个节点上的所有分类数据来自同一个类别,则该节点的纯度为0,又称为gini值。假设集合t中包含n个类别的记录,并分裂成r个部分n1,n2,……,nr,每个部分对应的集合为t1,t2,……,tr,那么这个分裂的gini系数按照公式(6)和(7)计算:
式中,t指总的训练样本集,pj代表类别j出现的频率,ginisplit(t)指所有类别的gini值。
生成随机森林的具体步骤如下:
5.1)从原始训练数据集t中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,作为根结点开始训练。
5.2)设总共有n个特征,则在每一棵树的每个节点处随机抽取mtry个特征(mtry≤n),通过计算每个特征蕴含的信息量,在mtry个特征中选择一个最具有分类能力的特征进行节点分裂。
5.3)每棵树最大限度地生长,不做任何剪裁。
5.4)将生成的多棵树组成随机森林,对于回归问题,预测输出为所有树输出值的平均值,得到训练好的co排放预测模型。
6)利用训练好的co排放预测模型和测试样本对模型进行测试,如果模型的预测co排放量和实际co排放量的相对预测误差超过±5%时,则重新选择样本进行训练,直到满足精度要求为止。
7)模型自适应更新。当co排放量与模型预测排放量的误差超过±5%时,立即更新模型。
- 还没有人留言评论。精彩留言会获得点赞!