一种风险预估模型的构建方法及装置与流程
本发明实施例涉及风险评估领域,尤其涉及一种风险预估模型的构建方法及装置。
背景技术:
颈椎病又称颈椎综合征,是颈椎骨关节炎、增生性颈椎炎、颈神经根综合征、颈椎间盘脱出症的总称,是一种以退行性病理改变为基础的疾患。主要由于颈椎长期劳损、骨质增生,或椎间盘脱出、韧带增厚,致使颈椎脊髓、神经根或椎动脉受压,出现一系列功能障碍的临床综合征。
据资料显示,近年来,随着手机、电脑等电子设备的普及,越来越多的人每天长时间伏案工作或低头刷屏,这导致颈椎病发病率逐年升高,发病人群也越来越年轻化。
当前,如何提前预估颈椎病的发病风险,以便及时采取措施防止颈椎病的发生,已成为当下亟需解决的一大问题。
技术实现要素:
本发明实施例提供一种风险预估模型的构建方法及装置,用以解决现有技术中无法提前预估颈椎病的发病风险的问题。
本发明实施例提供一种风险预估模型的构建方法,包括:
从多个候选危险因素中,选择至少一个目标危险因素;
从多个数据样本中,选择第一数据样本集和第二数据样本集;所述多个数据样本中的每个数据样本包括所述至少一个目标危险因素对应的因素值以及风险结果;
根据所述第一数据样本集中的数据样本进行模型训练,得到多个初始风险预估模型;
根据所述第二数据样本集中的数据样本,分别对所述多个初始风险预估模型进行性能评价;
选择所述多个初始风险预估模型中性能评价符合要求的风险预估模型。
在一可选实施例中,所述从多个候选危险因素中,选择至少一个目标危险因素,包括:
基于所述风险结果,对所述多个候选危险因素进行单因素分析,以获取所述多个候选危险因素中可能度P<第一阈值的危险因素;
对所述P<第一阈值的危险因素进行多因素回归分析,以获得所述P<第一阈值的危险因素中的检验水平为设定值的至少一个危险因素,作为所述至少一个目标危险因素。
在一可选实施例中,所述根据所述第一数据样本集中的数据样本进行模型训练,包括:
采用SVM中的不同核函数,分别对所述第一数据样本集中的数据样本进行模型训练,以获得多个SVM预估模型;
所述不同核函数包含高斯核函数、线性核函数、多项式核函数以及Sigmoid核函数中的至少两个。
在一可选实施例中,所述分别对所述多个初始风险预估模型进行性能评价,包括:
将所述第二数据样本集中的数据样本作为输入,分别运行所述不同核函数对应的SVM预估模型,以获得所述不同核函数对应的SVM预估模型的输出结果;
根据所述不同核函数对应的SVM预估模型的输出结果,分析所述不同核函数对应的SVM预估模型的性能指标;
所述选择所述多个初始风险预估模型中性能评价符合要求的风险预估模型,包括:
将所述第二数据样本集中的数据样本作为输入,运行Logistic预估模型,以获得所述Logistic预估模型的输出结果;
根据所述Logistic预估模型的输出结果,分析所述Logistic预估模型的性能指标;
将所述不同核函数对应的SVM预估模型的性能指标,分别与所述Logistic预估模型的性能指标做比较;
选择所述不同核函数对应的SVM预估模型中比较结果符合要求的SVM预估模型。
在一可选实施例中,所述将所述第二数据样本集中的数据样本作为输入,分别运行所述不同核函数对应的SVM预估模型,以获得所述不同核函数对应的SVM预估模型的输出结果,包括:
将所述第二数据样本集中的数据样本作为输入,分别运行所述不同核函数对应的SVM预估模型,以获得所述不同核函数对应的SVM预估模型的ROC曲线;
所述根据所述不同核函数对应的SVM预估模型的输出结果,分析所述不同核函数对应的SVM预估模型的性能指标,包括:
根据约登指数最大化的标准,选择所述不同核函数对应的SVM预估模型的ROC曲线的切点值;
根据所述切点值,计算所述不同核函数对应的SVM预估模型的性能指标。
在一可选实施例中,所述性能指标包括以下至少一种:
ROC曲线下的面积、灵敏度、特异度、约登指数、阳性预测值、阴性预测值、预测准确率。
在一可选实施例中,所述从多个数据样本中,选择第一数据样本集和第二数据样本集之前,还包括:
对原始数据样本中的少数类数据样本进行数据平衡处理,得到新的少数类数据样本;
将所述新的少数类数据样本合并到所述原始数据样本中,得到所述多个数据样本。
在一可选实施例中,所述从多个数据样本中,选择第一数据样本集和第二数据样本集,包括:
按预设比例,随机抽取所述多个数据样本中的部分数据样本,形成所述第一数据样本集;
将所述多个数据样本中剩余的数据样本,作为所述第二数据样本集。
在一可选实施例中,所述从多个数据样本中,选择第一数据样本集和第二数据样本集,包括:
从多个数据样本中,提取指定类别的数据样本;
对所述指定类别的数据样本进行划分,以获得所述第一数据样本集和所述第二数据样本集。
在一可选实施例中,所述从多个数据样本中,提取指定类别的数据样本,包括以下至少一种:
从多个数据样本中,提取同性别的数据样本;
从多个数据样本中,提取年龄段相同的数据样本;
从多个数据样本中,提取相同工作性质的数据样本。
在一可选实施例中,所述候选危险因素包括一下至少一种:
一般人口学因素、职业相关因素、体育锻炼因素、生活行为特征因素、环境因素、睡眠因素、体格因素。
本发明实施例提供一种风险预估模型的构建装置,包括:
第一选择模块,用于从多个候选危险因素中,选择至少一个目标危险因素;
第二选择模块,用于从多个数据样本中,选择第一数据样本集和第二数据样本集;所述多个数据样本中的每个数据样本包括所述至少一个目标危险因素对应的因素值以及风险结果;
模型训练模块,用于根据所述第一数据样本集中的数据样本进行模型训练,得到多个初始风险预估模型;
模型评价模块,用于根据所述第二数据样本集中的数据样本,分别对所述多个初始风险预估模型进行性能评价;
模型选择模块,用于选择所述多个初始风险预估模型中性能评价符合要求的风险预估模型。
在一可选实施例中,所述第一选择模块,用于:
基于所述风险结果,对所述多个候选危险因素进行单因素分析,以获取所述多个候选危险因素中可能度P<第一阈值的危险因素;
对所述P<第一阈值的危险因素进行多因素回归分析,以获得所述P<第一阈值的危险因素中的检验水平为设定值的至少一个危险因素,作为所述至少一个目标危险因素。
在一可选实施例中,所述模型训练模块,用于:
采用SVM中的不同核函数,分别对所述第一数据样本集中的数据样本进行模型训练,以获得多个SVM预估模型;
所述不同核函数包含高斯核函数、线性核函数、多项式核函数以及Sigmoid核函数中的至少两个。
在一可选实施例中,所述模型评价模块,用于:
将所述第二数据样本集中的数据样本作为输入,分别运行所述不同核函数对应的SVM预估模型,以获得所述不同核函数对应的SVM预估模型的输出结果;
根据所述不同核函数对应的SVM预估模型的输出结果,分析所述不同核函数对应的SVM预估模型的性能指标;
所述模型选择模块,用于:
将所述第二数据样本集中的数据样本作为输入,运行Logistic预估模型,以获得所述Logistic预估模型的输出结果;
根据所述Logistic预估模型的输出结果,分析所述Logistic预估模型的性能指标;
将所述不同核函数对应的SVM预估模型的性能指标,分别与所述Logistic预估模型的性能指标做比较;
选择所述不同核函数对应的SVM预估模型中比较结果符合要求的SVM预估模型。
本发明实施例提供的风险预估模型的构建方法及装置,通过筛选出数据样本所包含的至少一个目标危险因素,利用第一数据样本集中的数据样本的目标危险因素值,训练得到与风险结果相关的多个初始风险预估模型;通过第二数据样本集中的数据样本,分别对得到的多个初始风险预估模型进行性能评价,从而得到性能评价符合要求的风险预估模型;利用本发明实施例构建的风险预估模型,可以有效评价颈椎病的发病风险,从而有利于及时采取措施防止颈椎病的发生。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种风险预估模型的构建方法流程图;
图2为本发明实施例提供的一种风险预估模型的选择方法流程图;
图3为不同退行性颈椎疾病患病风险预估模型ROC曲线;
图4为基于SMOTE算法的男女SVM预估模型ROC曲线;
图5为本发明实施例提供的一种风险预估模型的构建装置。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种风险预估模型的构建方法,如图1所示,包括:
步骤101:从多个候选危险因素中,选择至少一个目标危险因素。
在一可选实施例中,候选危险因素为致使人体患脊柱退行性颈椎病的危险因素,可以包括以下至少一种:
一般人口学因素、职业相关因素、体育锻炼因素、生活行为特征因素、环境因素、睡眠因素、体格因素。
其中,一般人口学因素,如年龄、性别、民族、文化程度、收入水平等。职业相关因素,如职业类型、工作强度、工作姿势、同一工作姿势持续时间等。体育锻炼因素,如锻炼强度、锻炼频率等。生活行为特征,如吸烟、饮酒、交通方式、家务活动强度等。环境因素,如工作或生活环境中是否存在振动等。睡眠因素,如睡眠时间等。体格因素,如身高、体重、腰围、臀围等。
发明人在实现本发明的过程中,通过对大量脊柱退行性颈椎病发病案例的研究及以社区为基础进行的脊柱退行性疾病患病现状的调查研究,发现上述因素均与脊柱退行性颈椎病的发生有着密切的关系,上述候选危险因素可利用性高、涵盖面广,既节省了筛选危险因素的时间,又有利于获取到较为全面的目标危险因素。
在一可选实施例中,可以对所述多个候选危险因素进行单因素分析,以获取所述多个候选危险因素中可能度P<第一阈值的危险因素;可选的,第一阈值可以是0.05,但不限于此;
对所述可能度P<第一阈值的危险因素进行多因素回归分析,以获得所述可能度P<第一阈值的危险因素中的检验水平为预设值的至少一个危险因素,作为所述至少一个目标危险因素。所述预设值可以为0.05,但不限于此。
可选的,本发明实施例中可以通过X2检验、t检验等统计学检验方法,对候选危险因素进行单因素分析,从候选危险因素中选择出可能度P<0.05的危险因素。可选的,本发明实施例可以通过线性回归、非线性回归等回归方法,对选择出的可能度P<0.05的危险因素进行多因素回归分析,以获得检验水平为0.05的至少一个目标危险因素。
通过对多个候选危险因素进行单因素分析,找出显著性危险因素;通过对找出的显著性危险因素进行多因素回归分析,确定目标危险因素;双重筛选确保了得到的目标危险因素的可利用性,为风险预估提供了较为可靠的数据基础。
步骤102:从多个数据样本中,选择第一数据样本集和第二数据样本集;所述多个数据样本中的每个数据样本包括所述至少一个目标危险因素对应的因素值以及风险结果。
本发明实施例中,多个数据样本可以通过问卷调查、从数据库获取等各种方式获得。每个数据样本包括至少一个目标危险因素对应的因素值以及对应的风险结果;风险结果为阳性或阴性。每个目标危险因素对应的因素值可以根据统计学方法赋予,既可以包括确定值,也可以包括离散变量。例如,以目标危险因素为调查地点为例,则该危险因素对应的因素值可以为:0=中心城区、1=郊区、2=农村;例如,以目标危险因素为年龄,则该危险因素对应的因素值可以为:0=“<30岁”;1=“30-45岁”;2=“45-60岁”;3=“>60岁”;例如,以目标危险因素为性别,则该危险因素对应的因素值可以为:0=男,1=女。
例如,以社区为基础,进行脊柱退行性疾病患病现状调查,得到阴性数据样本和阳性数据样本。数据样本对应的目标危险因素为性别因素和年龄因素。根据数据样本的性别和年龄,赋予每个数据样本对应的性别因素值(0=男,1=女)和年龄因素值(0=0-30岁”、1=30-45岁”、2=45-60岁”、3=60岁以上”)。
在一可选实施例中,按预设比例,随机抽取多个数据样本中的部分数据样本,形成第一数据样本集;将多个数据样本中剩余的数据样本,作为第二数据样本集。通过随机抽选数据样本组成数据样本集,能够确保第一数据样本集和第二数据样本集中数据样本的随机性和公平性。
在一具体实施例中,第一数据样本集中数据样本占样本总量的70%,第二数据样本集中数据样本占样本总量的30%。第一数据样本集中的数据样本足够多时,能保证训练得到可靠的风险预估模型,提高了预估的准确度。
在其他实施例中,可以根据需要调整第一数据样本集和第二数据样本集中数据样本的选择方式,本发明不做限定。
步骤103:根据所述第一数据样本集中的数据样本进行模型训练,得到多个初始风险预估模型。
在本发明实施例中,采用支持向量机(Support Vector Machine,SVM)中的不同核函数,分别对第一数据样本集中的数据样本进行模型训练,以获得多个SVM预估模型。这里不同核函数包含高斯核函数、线性核函数、多项式核函数以及Sigmoid核函数中的至少两个。
SVM基于结构风险最小化(SRM)原理,而不是传统统计学的经验风险最小化(ERM),表现出很多优于现有分类方法的性能;通过采用SVM中的高斯核函数、线性核函数、多项式核函数以及Sigmoid核函数训练出的SVM预估模型,可靠性更高。
在其他实施例中,也可以根据需要选择Logistic、LDA等分类算法训练预估模型,本发明不做限定。
步骤104:根据所述第二数据样本集中的数据样本,分别对所述多个初始风险预估模型进行性能评价。
在本发明实施例中,将第二数据样本集作为测试样本,将第二数据样本集中的数据样本作为输入,分别运行多个初始风险预估模型,获得多个初始风险预估模型的性能指标,基于多个初始风险预估模型的性能指标对多个初始风险预估模型进行性能评价。
可选的,基于上述不同核函数对应的SVM预估模型,可以将第二数据样本集中的数据样本作为输入,分别运行不同核函数对应的SVM预估模型,以获得不同核函数对应的SVM预估模型的输出结果;根据不同核函数对应的SVM预估模型的输出结果,分析不同核函数对应的SVM预估模型的性能指标。
可选的,上述SVM预估模型的性能指标包括以下至少一种:ROC曲线下的面积、灵敏度、特异度、约登指数、阳性预测值、阴性预测值、预测准确率。
上述性能指标能够有效评价预估模型的预估准确度,因而通过上述性能指标筛选出的风险预估模型的可靠性更高。
在其他实施例中,还可以根据需要,用第二数据样本集中的数据样本对其他预估模型进行性能评价,本发明不做限定。
步骤105:选择所述多个初始风险预估模型中性能评价符合要求的风险预估模型。
基于上述步骤104中对多个初始风险预估模型的性能评价,可以从多个初始风险预估模型中选择性能评价符合要求的风险预估模型。
可选的,在本发明实施例中,可以将Logistic预估模型作为比较基准,通过与Logistic预估模型进行比较,从多个初始风险预估模型中选择性能评价符合要求的风险预估模型。选择方法包括:
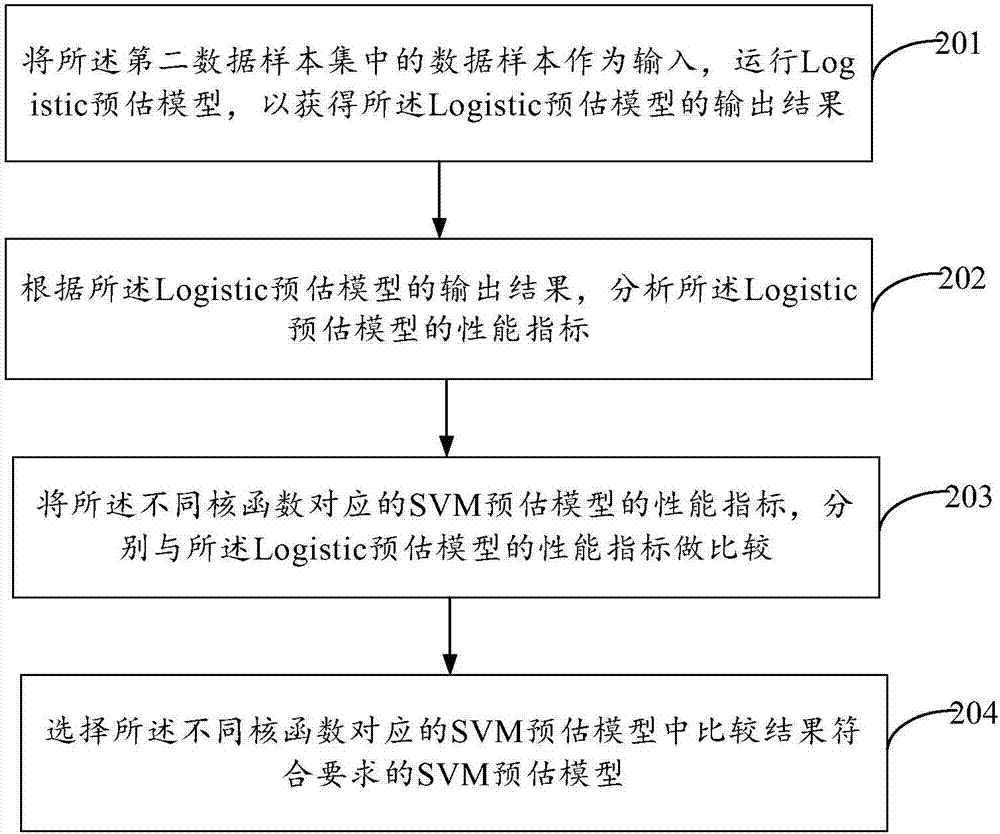
步骤201:将所述第二数据样本集中的数据样本作为输入,运行Logistic预估模型,以获得所述Logistic预估模型的输出结果;
步骤202:根据所述Logistic预估模型的输出结果,分析所述Logistic预估模型的性能指标;
步骤203:将所述不同核函数对应的SVM预估模型的性能指标,分别与所述Logistic预估模型的性能指标做比较;
步骤204:选择所述不同核函数对应的SVM预估模型中比较结果符合要求的SVM预估模型。
Logistic预估模型是疾病风险预估工作中常用的模型,是经过大量实践证实的较为可靠的模型,通过Logistic预估模型对SVM预估模型进行评价,评价结果的可靠性较高。
在其他实施例中,也可以采用LDA、多重线性回归等其他预估模型对SVM预估模型进行评估,本发明不做限定。
在本发明的一具体实施例中,上述将第二数据样本集中的数据样本作为输入,运行不同核函数对应的SVM预估模型或Logistic预估模型,以获得不同核函数对应的SVM预估模型或Logistic预估模型的输出结果的步骤,包括:
将第二数据样本集中的数据样本作为输入,运行不同核函数对应的SVM预估模型或Logistic预估模型,以获得不同核函数对应的SVM预估模型或Logistic预估模型的ROC曲线。相应地,基于不同核函数对应的SVM预估模型或Logistic预估模型的输出结果,分析不同核函数对应的SVM预估模型或Logistic预估模型的性能指标的步骤,包括:
根据约登指数最大化的标准,选择所述不同核函数对应的SVM预估模型或Logistic预估模型的ROC曲线的切点值;根据所述切点值,计算所述不同核函数对应的SVM预估模型或Logistic预估模型的性能指标。可选的,性能指标可以包括以下至少一种:ROC曲线下的面积、灵敏度、特异度、约登指数、阳性预测值、阴性预测值、预测准确率。
在本发明上述实施例或下述实施例中,可选的,步骤102之前还包括:
对原始数据样本中的少数类数据样本进行数据平衡处理,得到新的少数类数据样本;将所述新的少数类数据样本合并到所述原始数据样本中,得到所述多个数据样本。
在本发明实施例中,通过合成少数类过取样算法,对少数类样本进行数据平衡处理,得到新的少数类数据样本。通过对少数类数据进行数据平衡处理,得到数量均衡的阳性数据样本和阴性数据样本,进一步提高了数据样本训练出来的预估模型的可靠性。
在本发明上述实施例或下述实施例中,可选的,步骤102的一种实施方式包括:
从多个数据样本中,提取指定类别的数据样本;
对所述指定类别的数据样本进行划分,以获得所述第一数据样本集和所述第二数据样本集。
在本发明实施例中,所述从多个数据样本中,提取指定类别的数据样本,包括以下至少一种:
从多个数据样本中,提取同性别的数据样本;
从多个数据样本中,提取年龄段相同的数据样本;
从多个数据样本中,提取相同工作性质的数据样本。
发明人根据大量的临床研究和统计调查发现,性别、年龄段、工作性质的差异均会严重影响脊柱退行性颈椎病的发病率,根据不同的性别、年龄段、工作性质分别训练不同的风险预估模型,能够有效提高模型预估的准确率和可靠性。
本发明实施例提供的风险预估模型的构建方法,通过筛选出数据样本所包含的至少一个目标危险因素,利用第一数据样本集中的数据样本的目标危险因素值,训练得到与风险结果相关的多个初始风险预估模型;通过第二数据样本集中的数据样本,分别对得到的多个初始风险预估模型进行性能评价,从而得到性能评价符合要求的风险预估模型;利用本发明实施例构建的风险预估模型,可以有效评价颈椎病的发病风险,从而有利于及时采取措施防止颈椎病的发生。
以下为本发明的一具体实施例:
1、数据样本来源:
2010年北京地区社区人群骨科退行性疾病研究数据库。
上述数据库调查现场为北京地区。
首先按照区域(中心城区、郊县城区和农村)进行分层,每一层中按照简单随机抽样,各抽取两个区,共抽取6个区;在每一区中采用简单随机抽样,抽取1个居民社区或者1个村庄;在每个抽中的居民社区中,根据楼层住户数量,随机抽取2-3座楼进行调查,每个村中随机抽取其中的2-5条街道(胡同)进行调查;抽中的楼或街道上的每个家庭中符合条件的人员全部纳入调查。
调查对象为北京地区居住时间半年以上的居民。
纳入标准:
性别不限;年龄18岁以上;有自主行为能力;知情同意;有症状者在二级及以上医院进行了影像学检查并得到确诊的结果。
排除标准:
颈椎病复发患者;因外伤导致的颈椎病;颈椎先天性发育异常;拒绝参加本研究;脊柱侧弯患者;肿瘤患者;其他脊柱相关疾病:胸腰椎疾病、强直性脊柱炎等;患有免疫系统疾病;曾行脊柱手术者;患有血液系统疾病;颈椎病治愈者。
共有3859例研究对象纳入统计分析。其中,男性1820例(47.27%),女性2029例(52.73%);年龄范围为18.20-98.30岁,平均年龄45.85岁,标准差为16.19岁;汉族3766例,占97.56%。
纳入的退行性颈椎疾病危险因素:
研究指标设定为二级指标,包括8项一级指标,每个一级指标中包括若干二级指标。一级指标和二级指标如下:
1)一般人口学资料:年龄、性别、民族、文化程度、收入水平;
2)职业相关因素:职业类型、工作活动强度、工作体位、同一工作体位持续时间;
3)体育锻炼:锻炼强度、锻炼频率;
4)生活行为特征:吸烟、饮酒、家务活动强度;
5)振动:工作或生活环境中是否存在振动;
6)睡眠状况:睡眠时间;
7)体格测量指标:BMI,腰臀比;
8)女性绝经
描述性统计分析方法:
对于正态分布的计量资料,采用均数和标准差进行集中和离散趋势的描述;对于偏态分布的计量资料,采用中位数和四分位数间距进行集中和离散趋势的描述;对于计数资料,采用率和率的标准误进行集中和离散趋势的描述。统计软件为SPSS18.0(SPSS Inc.,Chicago,IL)。
2、退行性颈椎疾病目标危险因素的筛选:
采用χ2检验进行退行性颈椎疾病候选危险因素单因素分析。经单因素分析具有统计学意义的因素进入Logistic回归模型。采用多因素Logistic回归进行退行性颈椎疾病危险因素的筛选。进入和排除模型的检验水平分别选取0.05和0.1。采用后退法(Backwald:Conditional)进行变量的筛选。变量赋值表见表1。分析软件采用的是SPSS18.0(SPSS Inc.,Chicago,IL)。关于退行性颈椎疾病危险因素的各种分析结果,可参见后续4.结果部分的描述。
表1危险因素赋值表
3、风险预估模型构建的方法
分别采用Logistic回归模型和支持SVM进行风险预估模型的构建,建模分析软件选用的是R软件,其中SVM算法采用的为R软件中的e1071工具包。
3.1数据集的分割
数据样本分为两个部分:训练集和测试集。设置种子数,从总体数据中随机抽取70%的数据样本形成训练集,用于模型的构建;剩余的30%形成测试集,用于模型的评价。
3.2采用SMOTE算法处理原始数据
假设有少数类样本,每一个样本,搜索其k(通常取5)个少数类最近邻样本;若向上采样的倍率N,则在其k个最近邻样本中随机选择N个样本,记为1,2,…,N;在少数类样本x与(j=1,2,…..N)之间进行随机线性插值,构造新的少数类样本。
pj=x+rand(0,1)×(yi-x),j=1,2,…,N
式中,表示区间内的一个随机数。将这些新合成的少数类样本点合并到原来的数据集里即可以产生新的训练集。假设某个少数类样本的属性值为(6,4),从少数类别种跳出最近邻居点属性值为(4,3),随机产生一个介于0~1随机数字=0.2。则新合成样本的计算过程为:
Rj=xi+rand(0,1)×(xi-xij)
=(6,4)+0.2×((4,3)-(6,4))
=(6,4)+0.2×(-2,-1)
=(5.6,3.8)
选取样本点数为5,过抽样比为200,欠抽样比为200,最终类间比(患者:非患者)为3:4进行相关参数的设置,完成SMOTE数据集的生成。采用R软件中的DMwR包,实现数据集的SMOTE抽样。
3.3预测建模
基于原始数据集和SMOTE数据集,按照男、女、总体进行分层,使用不同核函数的SVM与Logistic回归对训练集进行建模,其中不同核函数的模型最优参数根据十折交叉验证率最大的标准进行确定。采用的核函数主要包括高斯核函数、线性核函数、多项式核函数和Sigmoid核函数。采用R语言进行预估模型的构建。
3.4模型评价与比较
基于测试集对建立的模型进行ROC评价,根据约登指数最大化的标准选择切点值,计算模型相应的灵敏度,特异度,阳性预测值与阴性预测值以及预测准确率。选择基于SMOTE数据集以及基于原始数据集建立的最优SVM,比较基于SMOTE数据集的SVM与基于原始数据集的SVM以及Logistic回归的模型性能。分别绘制SMOTE数据集的男性、女性以及总体的模型的ROC曲线,探讨性别对于SVM预估模型的影响。
关于预测建模结果、结果评价与比较,可参见后续4.结果部分的描述。
4.结果
4.1退行性颈椎疾病危险因素单因素分析结果
参见表2,在社会人口学因素中,经单因素分析,不同地区、不同年龄、不同性别、不同教育水平人群的患病率的差别有统计学意义(P均<0.05)。
参见表3,在行为特征因素中,交通方式、锻炼强度、锻炼频率、工作体位、某一工作体位持续时间、睡眠时间等是退行性颈椎疾病的危险因素(P均<0.05)。
参见表4,BMI、腰臀比及环境中存在的振动与退行性颈椎疾病相关(P均<0.05)。在女性人群中,绝经是退行性颈椎疾病的危险因素(P<0.001)。
表2社会人口学因素对退行性颈椎疾病影响的单因素分析结果
表3行为特征对退行性颈椎疾病影响的单因素分析结果
表4体格及其他因素对退行性颈椎疾病影响的单因素分析结果
参见表2,经非参数检验,家务活动强度与退行性颈椎疾病存在关联(Kolmogorov-Smirnov Z=2.918,P<0.001),工作劳动强度与退行性颈椎疾病的关联无统计学意义(Kolmogorov-Smirnov Z=1.145,P=0.145)。
表5工作和家务活动强度对退行性颈椎疾病的影响
4.2退行性颈椎疾病多因素Logisitc回归分析结果
参见表6,经多因素Logistic回归分析,居住地类型(郊县城区)、年龄、性别(女)、脑力劳动类型、家务活动强度、交通工具(步行)和睡眠时间(<7小时/天)是退行性颈椎疾病的危险因素。
表6退行性颈椎疾病危险因素多因素Logisitc回归分析结果
与中心城区相比较,郊区人群的危险度是1.467(95%CI:1.100-1.957),农村地区人群中心城区人群OR值的差别无统计学意义(P=0.060);相对于<30岁组人群,30-、45-、60-的OR值依次为2.327、5.303和4.722(95%CI依次为:1.495-3.623,3.417-8.229,2.945-7.571);女性的患病风险高于男性,是男性的1.805倍(95%CI:1.426-2.285);以脑力劳动为主的人群的患病风险是体力劳动人群的1.653倍(95%CI:1.215-2.247),混合型人群与体力劳动人群的患病风险的差别无统计学意义(P=0.187);家务活动强度是颈椎退行性疾病的危险因素,劳动强度每增加一个单位,其风险升高9%(95%CI:3.5%-14.7%);采用不同交通工具上班的人群其患病风险不同,与使用非人力交通比较,步行上班是颈椎退行性疾病的保护性因素,其OR为0.690(95%CI:0.512-0.929),骑自行车与非人力交通工具的差别无统学意义(P=0.555);睡眠时间小于7小时为颈椎退行性疾病的危险因素,其OR值为1.466(95%CI为:1.132-1.899)。
考虑到不同地区人群、不同性别人群和不同年龄人群的生活行为方式可能存在差别,因此从以上三个方面进行亚组分析不同特征人群其颈椎退行性疾病的危险因素。
4.3不同性别人群退行性颈椎疾病多因素Logisitc回归分析结果
参见表7,对于男性,退行性颈椎疾病的独立危险因素包括年龄和振动。并未发现工作体位、工作体位、工作体位持续时间、BMI、腰臀比、交通工具等对男性退行性颈椎疾病的影响。相对于<30岁组,30-岁组、45-岁组和60-岁组的OR分别为2.793(95%CI:1.320-5.911)、4.465(95%CI:2.164-9.210)和5.657(95%CI:2.684-11.923);工作环境中振动的OR为1.603(95%CI:1.043-2.450)。
参见表8,对于女性,除与男性同样存在的年龄这一危险因素外,还包括其他特有的独立危险因素:绝经、劳动类型、家务活动强度、交通工具和睡眠时间。对于不同年龄组的人群,与<30岁组相比,30-岁组、45-岁组和60-岁组的OR分别为1.924(95%CI:1.114-3.323)、5.177(95%CI:3.031-8.843)和3.565(95%CI:1.986-6.399);相对于非绝经期女性,绝经的危险度为1.772(95%CI:1.159-2.710);相对于体力劳动者,脑力劳动者的OR为1.686(95%CI:1.091-2.605),混合型与体力劳动者的差别无统计学意义(P=0.068);家务活动强度每增加一个单位,女性患退行性颈椎疾病的风险升高9.2%(95%CI:1.3%-17.6%);相对于非人力交通工具,步行与骑自行陈上班的OR分别为0.522(95%CI:0.348-0.782)和0.845(95CI:0.558-1.278);相对于每日睡眠时间大于7小时人群,每日睡眠时间<7小时的OR为1.606(95%CI:1.113-2.318)。
表7男性退行性颈椎疾病危险因素多因素Logistic回归分析结果
表8女性退行性颈椎疾病危险因素多因素Logistic回归分析结果
4.4不同年龄人群退行性颈椎疾病多因素Logisitc回归分析结果
参见表9,对于<30岁组人群,同一体位保持时间和性别是其独立危险因素。与同一体位保持时间<1小时人群相比,其持续时间在1-小时组的危险最高,OR为12.522(95%CI:1.602-97.850),其次是2-小时组,OR为8.750(95%CI:1.058-72.346);持续时间≥3h的人群的危险比值比OR为5.099(95%CI:0.666-39.013),无统计学意义(P=0.117)。
参见表9,对于30-岁组的人群,家务活动强度是唯一的独立危险因素,其OR为1.117(95CI:1.009-1.237)。
表9<30岁与30-岁人群颈椎病危险因素多因素Logistic回归结果
表10 45-岁与60-岁组人群颈椎病危险因素多因素Logistic回归结果
参见表10,对于45-岁组人群,危险因素包括:居住地在农村、女性、脑力劳动者、每日睡眠时间<7小时和振动,保护性因素为步行上班。农村地区人群的患病风险高于中心城区,OR为2.006(95%CI:1.239-3.248);女性的OR为2.961(95%CI:2.030-4.318);脑力劳动者较体力劳动者的OR为1.852(95%CI:1.151-2.980);振动的OR为1.754(95%CI:1.021-3.012)。与非人力交通工具比较,步行的OR为0.571(95%CI:0.361-0.901)。
参见表10,对于60-岁组人群,睡眠时间<7小时、家务活动强度、脑力劳动者和混合型劳动者是高危人群,其OR依次为1.679(95%CI:1.021-2.760)、1.145(95%CI:1.031-1.272)、1.948(95%CI:1.095-3.464)和2.082(95%CI:1.171-3.703)。
4.5数据分割结果
参见表11,随机抽取其中的70%作为训练集,剩余的30%作为测试集。训练集包括2706例样本,测试集包含1154例样本。
表11测试集与训练集样本量
参见表12,训练集与测试集两组研究对象人群的地区分布、年龄构成、性别构成的差别无统计学意义(χ2=0.253、2.601、1.883,P=0.881、0.272、0.170)。两组研究对象颈椎病患病率(13.35%vs.14.73%)的差别无统计学意义(χ2=1.309,P=0.253)。
表12训练集与测试集基本情况比较
4.6 Logistic回归预估模型的构建结果
4.6.1 Logistic回归总体预估模型评价
参见表13根据测试集训练的Logistic回归模型的系数(表13),将其带入验证集进行检验,得到其AUC为0.6970(95%CI:0.6555-0.7385)。
根据约登指数最大化,当模型的切点值为为-1.8968时,灵敏度为72.90%,特异度为60.09%,阳性预测值为24.51%,阴性预测值为92.58%,预测准确率为62.02%。
表13 Logistic回归预估模型评价结果
续表
续表
4.6.2男性Logistic回归预估模型评价
参见表14,根据测试集训练的Logistic回归模型的系数,将其带入验证集做检验,得到其AUC为0.6287(95%CI:0.5588-0.6986)。
根据约登指数最大化,当模型的切点值为-1.7720时,灵敏度为44.83%,特异度为77.50%,阳性预测值为20.80%,阴性预测值为91.42%,预测准确率为73.69%。
表14男性Logistic回归预估模型评价结果
续表
续表
4.6.3女性Logistic回归预估模型构建
参见表15,根据测试集训练的Logistic回归模型的系数,将其带入验证集做检验,得到其AUC为0.6699(95%CI:0.6262-0.7137)。
根据约登指数最大化,当模型的切点值为-0.3010时,灵敏度为59.53%,特异度为67.93%,阳性预测值为58.17%,阴性预测值为69.14%,预测准确率为64.33%。
表15女性Logistic回归预估模型评价结果
续表
续表
4.7采用原始数据构建SVM总体预估模型
本研究通过四种核函数进行支持向量机模型的构建,并完成了模型的评价。通过模型的评价,筛选出预测效能相对较好的模型。
4.7.1采用高斯核进行建模与评价
采用高斯核函数构建SVM时不同参数对应的十折交叉验证率见表16。根据十折交叉验证率的结果,采用高斯核函数构建SVM的最优参数:gamma=1/50,惩罚系数C为50。
参见表17,根据不同加权的SVM结果,当高斯核函数的SVM的参数为gamma=1/50,c=16.7,类间权重为1:3时,参数最优,AUC为0.6746(95%CI:0.6284-0.7208)。
以约登指数最大化为标准,当模型的切点值0.1362时,灵敏度为67.10%,特异度为61.24%,阳性预测值为23.53%,阴性预测值为91.28%,模型预测准确率为62.12%。
表16不同参数的高斯核SVM总体人群十折交叉结果
表17不同加权的高斯核函数SVM结果
4.7.2采用线性核函数进行建模与评价
参见表18,根据线性核函数的不同参数预测准确性的结果,线性核SVM的最优参数为惩罚系数C为0.1,据此建立的线性核函数SVM预估模型。
表18线性核函数不同参数构建SVM预估模型的预测准确性
参见表19,多数类样本权重与少数类样本之比不同,惩罚系数不同,其预测准确率和AUC不同。当加权为1:4时,模型预测准确率最高,AUC为0.6900(95%CI:0.6473-0.7327)。根据约登指数最大化原则,当切点为0.1447时,灵敏度为65.81%,特异度为67.09%,阳性预测为26.22%,阴性预测值为91.69%,准确率为66.89%。
表19不同加权的线性核函数构建的SVM结果
4.7.3采用多项式核函数进行建模与评价
根据不同参数多项式核函数构建的SVM预估模型的十折交叉准确率(表20),另考虑到参数degree越大,C越大,越容易出现过拟合的情况,多项式核函数的最佳参数为gamma=1/30,d=2,C=5。
参见表21,调整类间的加权,当类间加权为1:4,惩罚系数为1.25,d为2时,多项式SVM的性能最优。根据约登指数最大化,当切点值为0.1183时,多项式SVM的灵敏度为77.42%,特异度为54.13%,阳性预测值为23.08%,阴性预测值为93.10%,AUC为0.6928(95%CI:0.6502-0.7355),预测准确率为57.64%。
表20不同参数的多项式核函数SVM预估模型十折交叉准确率
续表
表21不同加权的多项式核函数SVM
4.7.4采用Sigmoid核进行建模与评价
参见表22,根据不同参数Sigmoid核构建的SVM预估模型十折交叉验证率,Sigmoid核函数的最佳参数为gamma=1/100,C=5。
表22不同参数Sigmoid核构建的SVM预估模型十折交叉验证率
参见表23,调整不同类间加权,当gamma=1/100,C=1.25,加权为1:4,此时模型最优,AUC为0.6878(0.6452-0.7305),预测准确率为85.39%。根据约登指数最大化原则,当切点值为0.1294时,Sigmoid核SVM预估模型的灵敏度为64.52%,特异度为65.37%,阳性预测值为24.88%,阴性预测值为91.20%,预测准确率为65.23%。
表23不同加权的Sigmoid核SVM结果
4.7.5采用原始数据构建SVM总体预估模型小结
从ROC曲线下面积AUC考虑,在四种核函数计算的SVM预估模型中,多项式核函数计算出的模型最优,AUC为0.6928(95%CI:0.6502-0.7355),预测准确率为57.64%。
4.8采用原始数据构建男性SVM预估模型
本研究通过四种核函数进行支持向量机模型的构建,并完成了模型的评价。通过模型的评价,筛选出预测男性发病风险效能相对较好的模型。
4.8.1采用高斯核函数进行建模与评价
采用不同参数的高斯核函数构建的SVM预估模型十折交叉验证率见表24。根据十折交叉验证率的结果,采用高斯核函数构建SVM的最优参数:gamma=1/30,惩罚系数C为10。
当高斯核SVM的参数为gamma=1/30,c=5,类间权重为1:2时,参数最优,AUC为0.6109(95%CI:0.5335-0.6882)。
表24男性不同参数的高斯核函数SVM预估模型十折交叉验证率
参见表25,以约登指数最大化,当模型的切点值为0.0861时,灵敏度为74.14%,特异度为45.45%,阳性预测值为15.19%,阴性预测值为93.02%,预测准确率为48.79%。
表25男性高斯核函数不同加权参数构建的SVM结果
4.8.2采用线性核函数进行建模与评价
参见表26,根据线性核函数的不同参数预测准确率结果,线性核函数构建SVM预估模型的最优参数为惩罚系数C=0.1。
表26男性不同参数线性核函数构建的SVM预估模型的预测准确率
参见表27,根据不同加权的线性核函数的SVM预估模型结果,当加权为1:3时,SVM预估模型预测率最高(87.76%),AUC为0.5708(95%CI:0.4908-0.6509)。
根据约登指数最大化,当切点为0.0880时,灵敏度为82.76%,特异度为31.82%,阳性预测为13.79%,阴性预测值为93.33%,准确率为37.75%,AUC为0.5729(95%CI:0.4937-0.6521)。
表27男性不同加权的线性核函数构建的SVM预估模型结果
4.8.3采用多项式核函数进行建模与评价
参见表28,根据不同参数多项式核函数构建的SVM预估模型十折交叉准确率,另参数degree越大,C越大越容易出现过拟合的情况,多项式核函数构建的SVM的最佳参数为gamma=1/50,d=3,C=100。
表28男性不同参数的多项式核函数构建SVM预估模型
续表
参见表29,调整类间的加权,则当类间加权为1:2,惩罚系数为50,d为3时,多项式核函数构建的SVM的性能最优。
根据约登指数最大化,当切点值为0.1011时,多项式核函数构建的SVM的灵敏度为56.90%,特异度为66.59%,阳性预测值为18.33%,阴性预测值为92.13%,AUC为0.5946(95%CI:0.5111-0.6782),预测准确率为65.46%。
表29不同加权的多项式核函数构建的SVM预估模型AUC结果
4.8.4采用Sigmoid核函数进行建模与评价
参见表30,根据不同参数的Sigmoid核函数SVM预估模型十折交叉验证率结果,Sigmoid核SVM的最佳参数为gamma=1/100,C=5。参见表31,调整不同类间加权,当gamma=1/100,C=2.5,加权为1:4时,SVM预估模型最优。
根据约登指数最大化原则,当切点值为0.0995时,Sigmoid核SVM预估模型的灵敏度为68.97%,特异度为53.41%,阳性预测值为16.33%,阴性预测值为92.89%,预测准确率为55.22%,AUC为0.6111(0.5409-0.6812)。
表30男性不同参数的Sigmoid核函数SVM预估模型十折交叉验证率
表31不同加权的Sigmoid核函数构建的SVM预估模型的AUC结果
4.8.5采用原始数据构建男性SVM预估模型小结
从模型AUC曲线下面积考虑,在四种核函数计算的SVM预估模型中,Sigmoid核函数计算出的模型最优,其AUC为0.6111(95%CI:0.5409-0.6812)。
4.9采用原始数据构建女性SVM预估模型
本研究通过四种核函数进行支持向量机模型的构建,并完成了模型的评价。通过模型的评价,筛选出预测女性患病风险效能相对较好的模型。
4.9.1采用高斯核函数进行建模与评价
参见表32,根据不同参数的高斯核函数SVM十折交叉验证率结果,高斯核函数SVM的最优参数为gamma=1/100,惩罚系数C为5。
表32女性不同参数的高斯核函数构建的SVM预估模型十折交叉验证率
参见表33,当高斯核SVM的参数为gamma=1/100,c=2.5,类间权重为1:2时,参数最优,AUC为0.6729(95%CI:0.6107-0.7351)。
根据约登指数最大化,当模型的切点值为0.1699时,灵敏度为54.64%,特异度为74.77%,阳性预测值为32.72%,阴性预测值为88.01%,预测准确率为71.08%。
表33女性高斯核函数不同加权的SVM预估模型AUC结果
4.9.2采用线性核函数进行建模与评价
参见表34,根据不同参数的线性核函数SVM预估模型预测准确率结果,线性核SVM的最优参数为惩罚系数C为0.1,据此建立的线性核函数的SVM预估模型。参见表35,根据不同加权的线性核函数SVM结果,当加权为1:4时,SVM预测率最高。
表34女性线性核函数的不同参数SVM预估模型预测准确性
若根据约登指数最大化,我们得到当切点为0.1974时,灵敏度为58.76%,特异度为76.85%,阳性预测为36.30%,阴性预测值为89.25%,预测准确率为73.53%,AUC为0.7232(95%CI:0.6686-0.7777)。
表35女性不同加权的线性核函数构建的SVM预估模型AUC结果
4.9.3采用多项式核函数进行建模与评价
参见表36,根据不同参数的多项式核函数构建的SVM预估模型十折交叉准确率结果,另由于参数degree越大,C越大越容易出现过拟合的情况,多项式核函数构建的SVM预估模型的最佳参数为gamma=1/100,d=2,C=5。
表36女性不同参数的多项式核函数构建的SVM预估模型十折交叉准确率
续表
续表
参见表37,根据SVM预估模型的参数,调整类间的加权。当类间加权为1:2,惩罚系数为2.5,d为2时,多项式SVM的性能最优。
根据约登指数最大化,当切点值为0.1715时,多项式核函数构建的SVM的灵敏度为50.52%,特异度为78.94%,阳性预测值为35.00%,阴性预测值为87.66%,AUC为0.6659(95%CI:0.6025-0.7293),预测准确率为73.72%。
表37不同加权的多项式函数构建的SVM预估模型AUC结果
4.9.4采用Sigmoid核函数进行建模与评价
参见表38根据不同参数的Sigmoid核函数SVM预估模型十折交叉验证率结果,Sigmoid核SVM的最佳参数为gamma=1/100,C=5。参见表39,在此参数下,调整不同类间加权,当gamma=1/100,C=2.5,加权为1:2时,模型最优。
根据约登指数最大化原则,当切点值为0.1626时,Sigmoid核SVM预估模型的灵敏度为74.23%,特异度为52.55%,阳性预测值为25.99%,阴性预测值为90.08%,预测准确率为56.52%,AUC为0.6695(0.6096-0.7294)。
表38女性不同参数的Sigmoid核函数SVM预估模型十折交叉验证率
表39不同加权的Sigmoid核函数构建的SVM预估模型AUC结果
4.9.5采用原始数据构建女性SVM预估模型小结
从模型AUC曲线下面积考虑,在四种SVM核函数计算的模型中,线性核函数计算出的模型最优,AUC为0.7232(95%CI:0.6686-0.7777),预测准确率为73.53%。
4.10采用SMOTE数据构建SVM总体预估模型
本研究通过四种核函数进行支持向量机模型的构建,并完成了模型的评价。通过模型的评价,筛选出预测效能相对较好的模型。
4.10.1采用高斯核函数进行建模与评价
参见表40,根据不同参数的高斯函数SVM十折交叉验证率的结果,高斯核函数构建的SVM的最优参数为gamma=1/30,惩罚系数C为100,AUC为0.8300(95%CI:0.8039-0.8562)。
以约登指数最大化,当模型的切点值为0.3993时,灵敏度为76.66%,特异度为78.73%,阳性预测值为72.98%,阴性预测值为81.82%,预测准确率为77.84%。
表40不同参数高斯函数构建的SVM预估模型十折交叉验证率
4.10.2采用线性核函数进行建模与评价
参见表41,根据不同参数线性核函数构建SVM预估模型的预测准确性结果,线性核函数SVM的最优参数为惩罚系数C为0.5。
表41不同参数线性核函数构建SVM预估模型的预测准确性
根据约登指数最大化,我们得到当阈值0.3492时,灵敏度为78.95%,特异度为53.00%,阳性预测为55.74%,阴性预测值为77.06%,预测准确率为64.12%,AUC为0.7081(95%CI:0.6766-0.7396)。
4.10.3采用多项式核函数进行建模与评价
参见表42,根据不同参数的多项式核十折交叉准确率结果,多项式核SVM的最佳参数为gamma=1/30,d=4,C=200,此时模型的十折交叉验证率为77.95%。
表42不同参数的多项式核函数构建的SVM预估模型的十折交叉准确率
续表
4.10.4采用Sigmoid核函数进行建模与评价
参见表43,根据不同参数的Sigmoid核SVM预估模型十折交叉验证率结果,Sigmoid核SVM的最佳参数为gamma=1/100,C=5,此时模型的十折交叉验证率为65.93%。
表43不同参数的Sigmoid核函数SVM预估模型十折交叉验证率
若根据约登指数最大化原则,当切点值为0.3538时,Sigmoid核SVM预估模型的灵敏度为78.72%,特异度为54.20%,阳性预测值为56.30%,阴性预测值为77.26%,预测准确率为64.70%,AUC为0.7021(95%CI:0.6704-0.7339)。
4.10.5采用SMOTE算法进行数据预处理后构建SVM预估模型小结
本研究分别采用高斯核函数、线性核函数、多项式核函数和Sigmoid核函数进行颈椎病发病风险与模型的构建。通过比较不同核函数SVM预估模型AUC面积,多项式核函数模型AUC最高(0.8339),建立的SVM预估模型的相对较优。
4.11采用SMOTE数据构建男性SVM预估模型
4.11.1采用高斯核函数进行建模与评价
参见表44,根据不同参数的高斯SVM十折交叉结果,高斯核SVM的最优参数为gamma=1/100,惩罚系数C为100时,高斯核SVM的模型最优,十折交叉验证准确率为75.98%,此时AUC为0.7705(95%CI:0.7219-0.8191)。
表44不同参数的高斯核函数构建的SVM预估模型十折交叉验证率
若以约登指数最大化,我们得到当模型的切点值为0.2717时,灵敏度为85.44%,特异度为57.82%,阳性预测值为60.27%,阴性预测值为84.14%,预测准确率为69.65%。
4.11.2采用线性核进行建模与评价
参见表45,根据线性核的不同参数预测准确性结果,当线性核SVM的最优参数为惩罚系数C为0.1时,SVM预估模型的预测率最高,十折交叉验证率为68.67%。
表45不同参数线性核函数构建的SVM预估模型的预测准确率
以约登指数最大化,我们得到当阈值为0.3550时,灵敏度为77.85%,特异度为54.03%,阳性预测为55.91%,阴性预测值为76.51%,预测准确率为64.23%,AUC为0.7025(95%CI:0.6498-0.7552)。
4.11.3采用多项式核函数进行建模与评价
参见表36,根据不同参数的多项式核十折交叉准确率结果,多项式核函数构建的SVM预估模型的最佳参数为gamma=1/30,d=3,C=100,此时模型的十折交叉验证准确率为75.89%。
表46不同参数多项式核函数构建的SVM预估模型的十折交叉准确率
续表
4.11.4采用Sigmoid核函数进行建模与评价
参见表47,根据不同参数的Sigmoid核十折交叉验证率结果,Sigmoid核SVM的最佳参数为gamma=1/100,C=10,此时模型的十折交叉验证准确率为68.67%。
若以约登指数最大化原则,当切点值为为0.3525时,Sigmoid核函数构建的SVM预估模型的灵敏度为78.48%,特异度为53.55%,阳性预测值为55.86%,阴性预测值为0.7687,预测准确率为64.23%,AUC为0.7013(95%CI:0.6486-0.7541)。
表47不同参数的Sigmoid核函数构建的SVM预估模型十折交叉验证率
根据约登指数最大化,当切点值为0.2811时,多项式SVM的灵敏度为85.44%,特异度为66.35%,阳性预测值为65.53%,阴性预测值为85.89%,预测准确率为74.52%,AUC为0.7875(0.7393-0.8358)。
4.11.5采用SMOTE数据构建SVM男性预估模型小结
本研究分别采用高斯核函数、线性核函数、多项式核函数和Sigmoid核函数进行颈椎病发病风险与模型的构建。通过比较男性不同核函数SVM预估模型AUC面积,多项式核函数模型AUC面积最大,为AUC为0.7875(95%CI:0.7393-0.8358),预测准确率为74.52%,建立的SVM预估模型的相对较优。
4.12采用SMOTE数据构建女性SVM预估模型
4.12.1采用高斯核函数进行建模与评价
参见表48,根据不同参数的高斯SVM十折交叉结果,高斯核SVM的最优参数为gamma=1/30,惩罚系数C为50,此时十折交叉验证准确率为80.78%,AUC为0.8688(95%CI:0.8392-0.8984)。
表48不同参数的高斯和函数构建的SVM预估模型十折交叉验证率
以约登指数最大化选择切点值,我们得到当模型的切点值为为0.3559时,灵敏度为85.30%,特异度为79.84%,阳性预测值为76.04%,阴性预测值为87.87%,预测准确率为82.18%。
4.12.2采用线性核函数进行建模与评价
参见表49,根据线性核的不同参数预测准确性结果,线性核SVM的最优参数为惩罚系数C为0.1,此时模型的十折交叉验证准确率为69.26%。
根据约登指数最大化原则,当切点为0.4690时,灵敏度为62.72%,特异度为76.61%,阳性预测为66.79%,阴性预测值为73.26%,预测准确率为70.66%,AUC为0.7616(95%CI:0.7246-0.7987)。
表49不同参数线性核函数构建的SVM预估模型的预测准确率
4.12.3采用多项式核函数进行建模与评价
参见表50,根据上述结果,多项式核函数构建SVM的最佳参数为gamma=1/30,d=4,C=200,此时模型的十折交叉验证准确率为79.49%。
根据约登指数最大化,当切点值为0.3834时,多项式核函数构建的SVM的灵敏度为82.80%,特异度为79.57%,阳性预测值为75.24%,阴性预测值为86.05%,预测准确率为80.95%,AUC为0.8635(0.8339-0.8931)。
表50不同参数的多项式核函数构建的SVM预估模型十折交叉准确率
续表
4.12.4采用Sigmoid核函数进行建模与评价
参见表51,根据不同参数的Sigmoid核SVM十折交叉验证率结果,Sigmoid核SVM的最佳参数为gamma=1/100,C=10,此时模型的十折交叉验证准确率为69.17%。
表51不同参数的Sigmoid核函数构建的SVM预估模型十折交叉验证率
根据约登指数最大化原则,当切点值为0.4702时,Sigmoid核函数构建的SVM预估模型的灵敏度为62.72%,特异度为75.81%,阳性预测值为0.6604,阴性预测值为0.7306,预测准确率为70.20%,AUC为0.7595(95%CI:0.7223-0.7967)。
4.12.5采用SMOTE数据构建女性SVM预估模型小结
本研究分别采用高斯核函数、线性核函数、多项式核函数和Sigmoid核函数进行颈椎病发病风险与模型的构建。高斯核函数模型AUC面积最大,为0.8688(95%CI:0.8392-0.8984),预测准确性高达80.50%,建立的SVM预估模型的相对较优。
5.小结
对于总体人群,居住地类型、年龄、性别、体力劳动类型、家务活动强度、交通工具和睡眠时间等均是退行性颈椎疾病的危险因素。不同性别人群颈椎病发病风险存在差异,基于本申请前述实施例提供的方法可以分别为不同性别的人群构建患病风险预估模型。
如图3所示,对于总体人群,采用SMOTE数据集构建的SVM预估模型优于原始数据集构建的SVM预估模型,亦优于Logistic预估模型。如图4所示,对于男性和女性,采用SMOTE数据集构建的SVM预估模型的AUC面积存在差别,女性高于男性。
参见图5,本发明实施例还提供了一种风险预估模型的构建装置,包括:
第一选择模块10,用于从多个候选危险因素中,选择至少一个目标危险因素;
第二选择模块20,用于从多个数据样本中,选择第一数据样本集和第二数据样本集;所述多个数据样本中的每个数据样本包括所述至少一个目标危险因素对应的因素值以及风险结果;
模型训练模块30,用于根据所述第一数据样本集中的数据样本进行模型训练,得到多个初始风险预估模型;
模型评价模块40,用于根据所述第二数据样本集中的数据样本,分别对所述多个初始风险预估模型进行性能评价;
模型选择模块50,用于选择所述多个初始风险预估模型中性能评价符合要求的风险预估模型。
在一可选实施例中,第一选择模块10用于:
对所述多个候选危险因素进行单因素分析,以获取所述多个候选危险因素中可能度P<第一阈值的危险因素;可选的,第一阈值可以是0.05,但不限于此;
对所述P<第一阈值的危险因素进行多因素回归分析,以获得所述P<第一阈值的危险因素中的检验水平为设定值的至少一个危险因素,作为所述至少一个目标危险因素。可选的,设定值可以是0.05,但不限于此。
在一可选实施例中,模型训练模块30用于:
采用SVM中的不同核函数,分别对所述第一数据样本集中的数据样本进行模型训练,以获得多个SVM预估模型;
所述不同核函数包含高斯核函数、线性核函数、多项式核函数以及Sigmoid核函数中的至少两个。
在一可选实施例中,模型评价模块40用于:
将所述第二数据样本集中的数据样本作为输入,分别运行所述不同核函数对应的SVM预估模型,以获得所述不同核函数对应的SVM预估模型的输出结果;
根据所述不同核函数对应的SVM预估模型的输出结果,分析所述不同核函数对应的SVM预估模型的性能指标;
模型选择模块50用于:
将所述第二数据样本集中的数据样本作为输入,运行Logistic预估模型,以获得所述Logistic预估模型的输出结果;
根据所述Logistic预估模型的输出结果,分析所述Logistic预估模型的性能指标;
将所述不同核函数对应的SVM预估模型的性能指标,分别与所述Logistic预估模型的性能指标做比较;
选择所述不同核函数对应的SVM预估模型中比较结果符合要求的SVM预估模型。
进一步,模型评价模块40具体用于:
将所述第二数据样本集中的数据样本作为输入,分别运行所述不同核函数对应的SVM预估模型,以获得所述不同核函数对应的SVM预估模型的ROC曲线;
根据约登指数最大化的标准,选择所述不同核函数对应的SVM预估模型的ROC曲线的切点值;
根据所述切点值,计算所述不同核函数对应的SVM预估模型的性能指标。
可选的,上述性能指标包括以下至少一种:ROC曲线下的面积、灵敏度、特异度、约登指数、阳性预测值、阴性预测值、预测准确率。
可选的,本实施例提供的构建装置还包括:均衡模块,用于对原始数据样本中的少数类数据样本进行数据平衡处理,得到新的少数类数据样本;将所述新的少数类数据样本合并到所述原始数据样本中,得到所述多个数据样本。
可选的,第一选择模块具体用于:按预设比例,随机抽取所述多个数据样本中的部分数据样本,形成所述第一数据样本集;将所述多个数据样本中剩余的数据样本,作为所述第二数据样本集。
可选的,第一选择模块具体用于:从多个数据样本中,提取指定类别的数据样本;对所述指定类别的数据样本进行划分,以获得所述第一数据样本集和所述第二数据样本集。
可选的,第一选择模块具体用于执行以下至少一种提取操作:
从多个数据样本中,提取同性别的数据样本;
从多个数据样本中,提取年龄段相同的数据样本;
从多个数据样本中,提取相同工作性质的数据样本。
可选的,上述多个候选危险因素包括以下至少一种:
一般人口学因素、职业相关因素、体育锻炼因素、生活行为特征因素、环境因素、睡眠因素、体格因素。
本发明实施例提供的风险预估模型的构建装置与上述实施例提供的风险预估模型的构建方法对应,用于实现上述实施例提供的方法,具体描述参见方法实施例,此处不再赘述。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!