一种基于社区文本数据的话题发现系统的制作方法
本发明涉及一种基于社区文本数据的话题发现系统及方法,属于计算机与网络技术应用领域。
背景技术:
随随着城市信息化的快速建设与发展,国民经济长足的进步,在高速城镇化建设中带来了人口管理、城市交通、环境保护以及社会治安等诸多问题,已经阻碍城市发展的脚步。社区的建设是城市建设的基础,提高社区服务质量直接关系到社区居民日常生活的幸福指数。如何让社区居民能真正享受到智慧城市带来的红利,是社区建设的首要任务,所以要充分利用社区产生数据。
深入去了解社区服务的需求,从文本数据层面进行分析,目前有关于文本数据挖掘多为舆情系统或是对当下较流行的微博客进行分析去做关键人物或网民情绪的分析,针对社区内部及城市管理者产生的数据并没有有效利用起来,目前没有相关文献报导。
技术实现要素:
本发明要解决的技术问题:克服现有技术的不足,提供一种基于社区文本数据的话题发现系统及方法,能够提高社区服务水平、符合社区管理特点、易于使用,可以使社区居民,社区服务人员以及城管参与到社区管理中,加快工作效率,实现社区的智慧化管理。
本发明采用的技术方案之一:一种基于社区文本数据的话题发现系统,包括移动终端服务系统和服务器端系统;移动终端服务系统包括社区文本数据上传模块,负责社区文本数据的采集、提取和上传,接收采集的社区文本数据,并提取所述社区文本数据的类型,并将社区文本数据及类型送上传至服务器端系统的数据预处理模块;所述社区文本数据的类型包括TXT格式、HTML格式、XML格式;服务器端系统包括数据预处理模块、向量提取模块、热点话题提取模块、数据可视模块和数据存储与管理模块;
数据预处理模块:读取社区文本数据上传模块上传的社区文本数据,并进行社区文本数据的清洗和中文分词;所述社区文本数据读取针对不同类型的数据采取不同的读取策略,对于TXT格式的社区文本数据采用JAVA中BufferedReader直接读取成数据流形式,对于HTML与XML格式的社区文本数据均采用DOM的解析模式;所述社区文本数据的清洗完成对社区文本数据中有重复上报的进行剔除;所述中文分词是将清洗后社区文本数据切分成由中文单词组成的词特征向量;
向量提取模块:负责对社区文本数据向量化表示;基于中文语料库对数据预处理模块后得到的词特征向量进行训练,提取关键词词组,并计算出关键词权值;结合词特征向量及关键词权值进行加权平均计算得出文本特征向量;所述词特征向量训练采用Word2Vec的JAVA版本,中文语料库采用项目所在地的新闻语料库(此项目中语料库为陕西省新闻与浙江省新闻,也可以为搜狗新闻语料库);提到关键词词组采用TF-IDF特征提取;
热点话题提取模块:基于向量提取模块中得出的关键词词组和文本的特征向量,采用Single-Pass聚类对文本进行聚类,得到类簇后根据向量提取模块中提取到的关键词词组,对关键词词组中的关键词进行统计,统计完成后降序排列,从而生成热点话题;
数据可视模块:为用户交互界面,完成对外的应用和展示任务,把社区文本上传模块中的得到的社区文本数据与热点话题提取模块中得到的热点话题数据展示在页面端;展示的内容包括社区文本数据的数据总量概况、数据分布概况和数据分析后生成的热点话题,热点话题的展示形式采用表格、柱状图、折线图并且结合地图的多种展示形式,直观的显示数据;所述数据整体概况展示数据概况,数据总种类,数据总量以及各个地区、主题的总量;数据分布概况将数据分布情况在地图上展示出来,直观的显示数据地理位置;数据分析概况将处理后生成的热点话题采用报表、图表并结合地图等形式展示给社区管理人员;
数据存储与管理模块,对社区文本数据上传模块中上传的社区文本数据、数据预处理模块、向量提取模块以及热点话题提取模块中产生的相关数据进行存储与管理;社区文本数据上传模块上传的社区文本数据缓存在HDFS文件系统中,向量提取模块中训练的词向量结果缓存于Redis缓存数据库中,数据预处理模块和热点话题提取模块生成的数据缓存在HBase数据库中;对HDFS文件系统、HBase数据库和Redis缓存数据库进行管理,完成其中的数据增加、删除、修改和查询操作;同时支持定时任务对Redis缓存数据库中的缓存数据进行更新,以及维护HBase数据库中的索引表,优化对数据的查询,对HDFS文件系统中文件块的存储进行合并优化处理。
所述社区文本数据包括民情数据与城管数据,所述民情数据包括社区环境卫生主题数据、社区安全主题数据、社区停车及公告主题数据以及社区管理主题数据,社区管理主题数据指物业与网格员日常执法情况,民情数据由社区居民与社区网格员上传;城管数据由城管人员上传,所述城管数据包括市容环境卫生主题数据、市政主题数据、城市绿化主题数据、城市规划主题数据及工商管理主题数据。
本发明技术解决方案之二:一种基于社区文本数据的话题发现方法,包括:社区文本数据上传步骤、数据预处理步骤、向量提取步骤、热点话题提取步骤、数据可视步骤、数据存储与管理步骤,其中社区文本数据上传步骤由移动终端服务系统完成,移动终端服务系统采集的社区文本数据,提取所述社区文本数据的类型,并将社区文本数据及类型送上传至服务器端系统;所述社区文本数据包括民情数据与城管数据,所述民情数据包括社区环境卫生主题数据、社区安全主题数据、社区停车及公告主题数据以及社区管理主题数据,社区管理主题数据指物业与网格员日常执法情况,民情数据由社区居民与社区网格员上传;城管数据由城管人员上传,所述城管数据包括市容环境卫生主题数据、市政主题数据、城市绿化主题数据、城市规划主题数据及工商管理主题数据;所述社区文本数据的类型包括TXT格式、HTML格式、XML格式;服务器端系统进行数据预处理模块、向量提取模块、热点话题提取模块、数据可视模块和数据存储与管理模块的执行;
数据预处理步骤:读取社区文本数据上传步骤的社区文本数据,并进行社区文本数据的清洗和中文分词;所述社区文本数据读取针对不同类型的数据采取不同的读取策略,对于TXT格式的社区文本数据采用JAVA中BufferedReader(缓存阅读器)直接读取成数据流形式,对于HTML与XML格式的社区文本数据均采用DOM(文档对象模型)的解析模式;所述社区文本数据的清洗完成对社区文本数据中有重复上报的进行剔除;所述中文分词是将清洗后社区文本数据切分成由中文单词组成的词特征向量;
向量提取步骤:基于中文语料库对数据预处理步骤后得到的词特征向量进行训练,提取关键词词组,并计算出关键词权值;结合词特征向量及关键词权值进行加权平均计算得出文本特征向量;所述词特征向量训练采用Word2Vec的JAVA版本,中文语料库采用项目所在地的新闻语料库;提到关键词词组采用TF-IDF(词频-逆文档频率)特征提取;
热点话题提取步骤:基于向量提取步骤中得出的关键词词组和文本的特征向量,采用Single-Pass聚类对文本进行聚类,得到类簇后根据向量提取步骤中提取到的关键词词组,对关键词词组中的关键词进行统计,统计完成后降序排列,从而生成热点话题;
数据可视步骤:为用户交互界面,完成对外的应用和展示任务,把社区文本上传步骤中的得到的社区文本数据与热点话题提取步骤中得到的热点话题数据展示在页面端;展示的内容包括社区文本数据的数据总量概况、数据分布概况和数据分析后生成的热点话题,热点话题的展示形式采用表格、柱状图、折线图并且结合地图的多种展示形式,直观的显示数据;所述数据整体概况展示数据概况,数据总种类,数据总量以及各个地区、主题的总量;数据分布概况将数据分布情况在地图上展示出来,直观的显示数据地理位置;数据分析概况将处理后生成的热点话题采用报表、图表并结合地图等形式展示给社区管理人员;
数据存储与管理步骤,对社区文本数据上传步骤中上传的社区文本数据步骤、数据预处理步骤、向量提取步骤以及热点话题提取步骤中产生的相关数据进行存储与管理;社区文本数据上传步骤上传的社区文本数据缓存在HDFS(分布式文件系统)文件系统中,向量提取步骤中训练的词向量结果缓存于Redis缓存数据库中,数据预处理步骤和热点话题提取步骤生成的数据缓存在HBase数据库中;对HDFS文件系统、HBase(分布式面向列的数据库)数据库和Redis(键-值形式的数据库)缓存数据库进行管理,完成其中的数据增加、删除、修改和查询操作;同时支持定时任务对Redis缓存数据库中的缓存数据进行更新,以及维护HBase数据库中的索引表,优化对数据的查询,对HDFS文件系统中文件块的存储进行合并优化处理。访问HDFS与HBase均采用原始API,访问Redis采用封装好的Jedis JAR包。
本发明与现有技术相比具有的有益效果在于:
(1)本发明以发现社区热点话题为目标,依靠社区居民上传文本数据、城市管理人员上报并且结合互联网数据相结合去多维度立体式提取话题,采用比较成熟的关键词提取技术,引入词向量技术,针对社区文本特点选取聚类算法并对其优化完成更好的聚类效果,确保系统高可用、跨平台、可扩展并支持PC端和手机端浏览,其中结合手机端上报民情与城管上报事件,根据社区文本的数据特点,挖掘出更有价值的话题信息,尽可能的满足社区居民和管理者的需求,实现被动信息发布想主动提供服务转换,将社区文本数据的字眼价值更大的发挥出来,为构建和谐社区做出相应的贡献。
(2)本发明采用移动终端与服务器交互方式,使得社区居民、社区管理人员和城管三者相结合的策略,提出一种高效的、稳定的多终端展示的热点话题发现系统,最终为社区居民与管理者提供服务,极大的提高了社区服务质量;本发明充分考虑社区文本的特点,构建了一个方便为社区管理人员研判社区状态的数据支持系统。
(3)本发明提出社区热点话题发现思想,采用中文分词技术、关键词提取技术、词向量提取技术以及对文本采用向量化表示,最后通过Single-Pass聚类算法将社区中出现频次多的的关键词提取出来,最终形成热点话题,对Single-Pass聚类算法优化的实验结果为:
(4)本发明对系统配置的要求不高,不过多人力投入,有占用资源少,价格便宜,易于推广。
附图说明
图1为本发明的系统组成示意图;
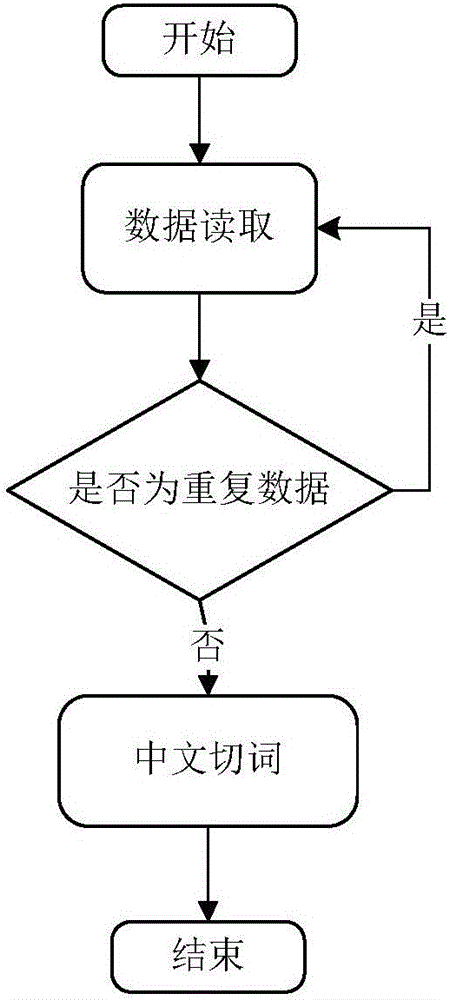
图2为本发明的数据预处理模块流程图;
图3为本发明的向量提取模块流程图;
图4为本发明的热点话题提取模块流程图;
图5为本发明的数据可视模块流程图;
图6为本发明的数据存储与管理模块结构图。
具体实施方式
下面结合附图和具体实施例进一步说明本发明。
如图1所示,本发明包括移动终端服务系统和服务器端系统;移动终端服务系统包括社区文本数据上传模块,负责社区文本数据的采集、提取和上传,接收采集的社区文本数据,并提取所述社区文本数据的类型,并将社区文本数据及类型送上传至服务器端系统的数据预处理模块;所述社区文本数据的类型包括TXT格式、HTML格式、XML格式;服务器端系统包括数据预处理模块、向量提取模块、热点话题提取模块、数据可视模块和数据存储与管理模。
如图2所示,数据预处理模块在处理流程顺序为首先进行民情数据和城管数据的读取,其中包括TXT格式、HTML格式、XML格式文本数据的读取。数据清洗功能主要完成对民情数据与城管数据中有重复上报的进行剔除。接下来完成中文切词。
数据预处理模块具体实现如下:
(1)首先进行文本数据读取,可读取的格式为TXT、HTML和XML,根据读取的文件格式不同,其中TXT格式采用JAVA中BufferedReader直接读取成数据流形式,HTML与XML格式数据均采用DOM的解析模式。
(2)接下来需要对读取的数据进行查重判断,也就是当发现读取的文本数据之前已经读取过就剔除掉并读取下一条,如没有读取过则进入分词步骤。
(3)最后对文本数据进行分词处理,中文分词采用的是ICTLAS的JAVA版本,ICTLAS是中国科学院计算技术研究所发布的中文分词开源工具,对文本进行切分,最终将文本数据切分成由中文单词组成的特征向量。
如图3所示,向量提取功能模块数据处理流程首先会判断语料库是否更新,此功能为定时任务一个月执行一次因为词向量训练一次需要耗费4个小时左右,这里需要更新时也是做离线任务处理。其核心的处理流程是对文本数据的处理,首先对采用TFIDF和词典完成对文本关键字的提取,在训练好的数据集中提取次的向量,基于三个关键词的权值和三个关键词的特征向量,进行加权平均计算从而得到文本的特征向量。
向量提取模块具体实现如下:
(1)第一步读取经过预处理模块处理后的数据,判断语料库是否需要更新,如果更新了则采用Word2Vec的JAVA版本重新训练,没有更新则进行下一步提取关键词。
(2)第二步需要提取关键词,采用的是TF-IDF特征提取同时计算出TF-IDF的权值。
(3)第三步读取第一步中训练好的词向量集合,如果词向量集合中没有则选取下一个关键词,如果词向量集合中有则读取出词向量,选取第二步中权值最高的三个关键词和向量。
(4)基于第三步中获得三个关键词的权值和三个关键词的特征向量,进行加权平均计算从而得到文本的特征向量。基于语义加权的文本表示模型的具体计算方法如下:假设需要表示的文本为t,对应的向量表示为y;该文本经过TF-IDF计算后得到的前三个关键词分别为a1i、a2i和a3i,对应的TF-IDF值分别为w1i,w2i和w3i,对应的向量分别为x1={x11;x12;…;x150},x2={x21;x22;…;x250}和x3={x31;x32;…;x350}。则有计算公式如下:
如图4所示,热点话题提取模块输入的数据为文本的特征向量,如果输入的是第一条数据则建立第一个话题,如果不是则用Single-Pass聚类算法聚类,聚类过程是当与中心点的相似度大于Vc时在进行到此类其他的点的距离计算,求出到此类的距离即相似度的值,大于Vn归入相应话题,否则新建话题,统计关键词数量,基于个数排序获取热点话题词组,形成热点话题词云。
热点话题提取模块具体实现如下:
(1)第一步读取向量提取模块中产生的文本特征向量,判断是否为第一条数据,如果是第一条数据则直接建立为新话题,如果不是则进行下一步文本聚类操作。
(2)第二步采用Single-Pass聚类算法聚类,在Single-Pass聚类算法中,点到类的相似度(距离越近,相似度越大)度量一般有有三种,分别是new_distance_max、ave_distance和inner_distance_max,下面对上述三个参数进行解释说明。new_distance_max相似度:新加入的点到已有类的内部所有点的距离的最大值;ave_distance相似度:新加入的点到已有类的内部所有点之间距离的平均值;inner_distance_max相似度:新加入的点到类的内部所有点之间距离的最大值;定义三个阈值分别对应上文所提到的三个相似度。THRESHOLD_NEW对应new_distance_max相似度的阈值、THRESHOLD_AVE对应ave_distance相似度的阈值和THRESHOLD_INNER对应inner_distance_max相似度的阈值。假设新加入的文本为Di,已有类M1。Di到M1的new_distance_max相似度为simnew(Di,M1),Di到M1的ave_distance相似度为simave(Di,M1),Di到M1的inner_distance_max相似度为siminner(Di,M1),则均值相似度计算公式为:
其中参数满足λ+μ+η=1且λ≥0,μ≥0,η≥0,当计算得出三个相似度值均小于其阈值时在则新加入文本Di到M1的相似度sim(Di,M1)为0,当有三者中有一个不小于其阈值的就符合λsimnew+μsimave+ηsiminner的线性组合。根据搜狗新闻语料库的训练结果当λ+μ+η=1且λ≥0,μ≥0,η≥0时,在λ=0.2,μ=0.5,η=0.3情况下聚类效果比较理想。
(3)需要计算此文本特征向量与已有类的相似度,如果相似点与类中心点的相似度值大于Vc,则计算此点与此类其他点的相似度值,并保存最大相似度值,获得此样本点与各类相似度的最大值,如果与类的相似度值最大且大于Vn则将此样本点归入与其比较的类中;如果小于Vn则新建一个类;如果小于Vc则将此文本特征向量与其他类进行相似度计算。
(4)第二步中如果归入到已有话题类中则需要对关键词数量镜像统计,统计出每个关键词一共出现几次。
(5)第四步需要判断是否为最后一条数据,如果是最后一条数据则基于统计的关键词数量降序排列,形成热点话题词词组,如果不是最后一条则跳转回输入文本特征向量。
如图5所示,数据可视模块主要负责处理应用层和展示层的请求,展示整个系统中的数据总量概况、数据分布概况和数据分析后生成的热点话题,热点话题展示方面采用报表、图表并结合地图等形式,在社区生活服务还会配有图片。
数据可视模块具体实现如下:
(1)第一步是系统展示请求,也就是用户通过浏览器输入网址后进行数据展示请求。
(2)第二步中展示的首页信息内容,其中有三个子标题连接,分别是数据整体概况、数据分布概况和数据分析概况。
(3)第三步中就是上述三个数据展示页面,其中采用折线图、柱状图、饼状图、热力图以及词云对数据进行展示,采用的技术是HTML5、CSS、JAVASCRIPT和AJAX。
如图6所示,数据存储与管理模块对社区文本数据上传模块中上传的数据和数据预处理模块、向量提取模块以及热点话题提取模块中产生的数据进行存储与管理。其中HDFS上的原始文本数据来源于社区文本数据上传模块中的民情数据和城管数据,缓存Redis中数据来源于向量提取模块中训练的词向量结果,HBase中的数据来源于数据预处理模块和热点话题提取模块生成的数据。数据存储与管理模块承载着对上述模块产生的数据的存储,并且对HDFS文件系统、HBase数据库和Redis缓存数据库进行管理,完成增、删、改、查操作。访问HDFS与HBase均采用原始API,访问Redis采用封装好的Jedis JAR包。数据存储与管理模块具体实现步骤如下:
(1)原始社区文档数据会存储在HDFS文件系统中,其存储路径存储在HBase数据库中。
(2)训练完成的词向量以键值的形式存储在Redis数据库中。
(3)预处理得到的中间结果数据与热点话题形成后的结果数据均存储在HBase数据库中。
以上详细叙述了本发明的实现过程,未详细描述部分属于本领域公知技术。
- 还没有人留言评论。精彩留言会获得点赞!