用于利用缓冲器高效访问纹理数据的高速缓存体系结构的制作方法
相关申请的交叉引用
本申请要求2016年3月4日递交的美国临时申请62/303,889号的权益,在此通过引用并入该申请的内容。
本发明的实施例概括而言涉及在图形处理单元中使用纹理高速缓存(cache)的技术。
背景技术:
在图形系统中,纹理通常被以压缩格式存储在纹理高速缓存中。例如,块压缩格式可将4x4像素块的颜色和阿尔法压缩成64比特(64b;8字节(8b))。在解压缩之后,有2b的红、绿和蓝(rgb)成分,每个成分分别为5比特、6比特、5比特。从而,此压缩格式实现了4的压缩因子(例如,对于4x4像素块,2b/像素*16像素)/8b=4)。
该压缩格式在存储器要求以及在存储器层次体系的多个级别之间移动纹理所需的带宽上实现了节省。然而,有许多缺点和限制与传统的纹理高速缓存方案相关联。
技术实现要素:
附图说明
图1a是根据本发明的实施例的包括纹理高速缓存体系结构的图形处理系统的框图。
图1b根据本发明的实施例更详细图示了图1a的纹理高速缓存体系结构。
图1c图示了支持astc编解码器的图1a的纹理高速缓存体系结构的实施例。
图2根据一实施例图示了操作图形处理单元的方法。
图3根据一实施例图示了操作图形处理单元的方法。
图4根据一实施例图示了高速缓存数据和标签映射的示例。
图5根据一实施例图示了具有无冲突访问的高速缓存数据和标签映射的示例。
图6根据一实施例图示了对于四方的3x3足迹的高速缓存访问的示例。
图7根据一实施例图示了对于四方的2x2足迹的高速缓存访问的示例。
图8根据一实施例图示了纹理高速缓存体系结构的子块的示例。
图9根据一实施例图示了astc纹素足迹模式的示例。
图10根据一实施例图示了用来组合纹素请求的地址生成控制的示例。
图11根据一实施例图示了astc块大小和纹理高速缓存线边界的示例。
图12图示了一系列访问中的astc块大小和纹理高速缓存边界的示例。
具体实施方式
图1a是根据一实施例图示出图形系统100的框图。在一个实施例中,纹理高速缓存单元110是图形处理单元(graphicsprocessingunit,gpu)106的一部分。在一个实施例中,纹理高速缓存单元110包括纹理高速缓存体系结构,下文关于图1b对其进行更详细描述。
在一个实施例中,gpu106可包括图形硬件,并且实现包括例如一个或多个着色器核的图形流水线(graphicspipeline)。可提供外部图形存储器112来存储额外的纹理数据。在一个实施例中,中央处理单元(centralprocessingunit,cpu)101和关联的系统存储器102可包括用于驱动器软件104的计算机程序指令。总线可用于将cpu101通信地耦合到gpu106,将系统存储器102耦合到cpu100,并且将gpu106耦合到外部图形存储器112。
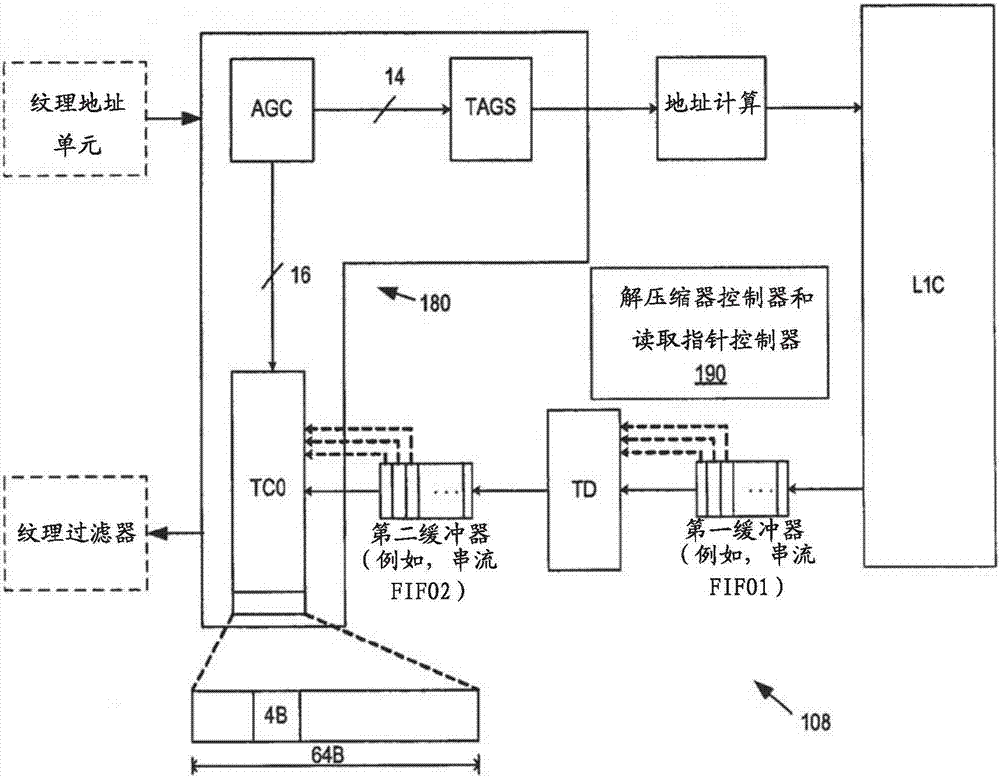
图1b更详细图示了纹理高速缓存体系结构108的实施例。对于未压缩的纹理数据(例如,纹素(texel)数据)提供第0级纹理高速缓存(tc0)。在一个实施例中,tc0高速缓存保存被组织成64b高速缓存线的解压缩纹素,其中每个4b片段被存储在单独的数据存储库中,整条高速缓存线存储在16个数据存储库上。然而,将会理解,可以使用其他高速缓存线大小和片段大小。对于压缩的纹理数据(例如,纹素数据)提供第1级纹理高速缓存(l1c)。
纹理解压缩器(texturedecompressor,td)被布置在tc0和l1c之间。提供了第一和第二缓冲器(buffer)来缓冲数据。虽然缓冲器可按不同方式来实现,但在一个实施例中这些缓冲器被实现为串流(streaming)先进先出(first-in,firstout,fifo),包括这样一种实现方式:其中第一缓冲器是第一fifo(串流fifo1)并且第二缓冲器是第二fifo(串流fifo2)。串流fifo1将来自l1c的压缩数据缓冲到td中。串流fifo2将从td提供的解压缩数据缓冲到tc0中。在一个实施例中,虽然串流fifo使用一种始终用新进入条目替换最旧条目的fifo替换方案,但串流fifo允许读取访问任何条目,而不像常规fifo中那样只是最旧条目。
在一个实施例中,纹理地址单元(在图1b中用虚线示出)生成对于四方(四个像素的群组)的一组访问并且将其递送到以地址生成控制器(addressgenerationcontroller,agc)开始的纹理高速缓存体系结构108的前端180。在一个实施例中,agc将这些访问合并成一组最小数目的非冲突标签访问和数据存储库访问。在一个实施例中,agc随后在tags单元中查找标签,tags单元将未命中递送给地址计算单元。地址计算单元进而生成用来访问l1c高速缓存中的压缩纹理数据的地址。
在一个实施例中,在tc0高速缓存中高速缓存未命中的情况下,agc支持生成地址并且使用(来自tags单元的)标签来利用地址计算块访问来自l1c高速缓存的压缩纹理数据。压缩纹理数据随后被缓冲在串流fifo1中,在td中被解压缩,被缓冲在串流fifo2中,然后被提供到tc0高速缓存。
在一个实施例中,tc0高速缓存支持对解压缩纹理数据的再利用。响应于高速缓存命中,tc0高速缓存的输出可例如被纹理过滤器单元(在图1b中用虚线示出)用来为像素计算纹理。此外,如下文更详细描述的,在一个实施例中,可控制对fifo1和fifo2的读取指针来改善对纹素数据的再利用。在一个实施例中,可例如提供控制块190或其他控制特征来协调td的操作和第一缓冲器(例如,fifo1)和/或第二缓冲器(例如,fifo2)的读取指针。
在一个实施例中,纹理高速缓存单元110接受对一个四方(像素的2x2集合)的纹素数据的请求并且对于四方中的每个活跃像素生成经过滤的纹素,这可涉及对于每个像素访问4个纹素,每周期总共16个纹素。
在一个实施例中,图形系统100具有重组织纹理内的数据的灵活性。在一个实施例中,驱动器104重组织纹理数据以最好地适应期望的请求模式。着色器核可以是容忍延时的,因为它们是高度多线程的以利用存在于图形应用中的天然并行性。另外,每个周期到达纹理高速缓存的多个请求可以是相关的,因为它们对应于代表单个四方作出的纹素请求。
在一个实施例中,tc0高速缓存中的数据的组织是基于常见数据访问模式的,以允许得到以最小数目的数据存储库和标签查找来处理一组纹素访问。在一个实施例中,基于存在于一组访问中的局部性模式,数据被组织到tc0高速缓存中以改善tc0高速缓存的高速缓存性能。例如,在构成tc0纹理高速缓存的数据存储的数据存储库间,可以以搅拌模式存储数据。另外,很可能被一起访问的数据可被一起分组到高速缓存线中以减少不同高速缓存线的数目并且因此减少所需要的不同标签查找的数目。本文公开的示例高速缓存体系结构支持每周期只需要最多4个标签查找的操作并且只利用16个数据存储库。然而,将会明白,在替换实施例中可利用其他数目的标签查找和数据存储库。
参考图1c,额外地或替换地,一实施例促进了利用可变大小块的纹理压缩方案,例如自适应可缩放纹理压缩(adaptivescalabletexturecompression,astc)编解码器。在一个实施例中,这可包括合并来自不同大小块的解压缩数据的合并器(coalescer,cls)模块以及具有控制特征来控制cls、解压缩器和对缓冲器的读取指针并且支持对可变大小块(例如astc的那些)的使用的控制块192,这些在下文更详细描述。
在较旧的纹理压缩方案中,每个压缩块包含固定2之幂(power-of-two)纹素并且被以固定块大小存储。例如,早前描述的纹理压缩方案将2b纹素的4x4块压缩成8b,给出了4的恒定压缩因子。利用每个维度上的纹素中的2之幂压缩大小和2之幂块大小,包含2d纹理中的纹素(u,v)的压缩块的起始地址的计算只涉及u,v和纹理的基地址上的特定移位操作。另外,在一个实施例中,解压缩tc0中的高速缓存线包含单个或较小的2之幂压缩块的整体。在一个实施例中,压缩块不被分割在解压缩高速缓存的多条高速缓存线之间。
astc纹理压缩方案可以把从4x4到12x12纹素不等的可变大小块压缩成16b以捕捉依据要求的质量支持某个范围的压缩因子的益处。有了这种可变大小块,地址计算可变得更复杂。例如,7x5块导致除以7并且计算包含期望纹素的压缩块的存储器地址。这种除法可消耗大量的面积和功率。
在一个实施例中,tc0高速缓存在未压缩域中操作,其中纹素地址是利用纹素的未压缩(u,v)坐标来识别的。响应于tc0高速缓存中的未命中,在地址计算单元中计算未命中的非压缩高速缓存线的压缩块地址。
在一个实施例中,fifo1的大小被设定为改善性能。当从l1c请求astc或其他压缩块时,l1c返回包含一组两个或更多个压缩块(例如,多个块)的高速缓存线。例如,如果astc压缩块是16b并且高速缓存线是64b,则l1c返回四个压缩块。这些块中的一个或多个被保存在fifo1中。考虑到纹理请求中的访问的局部性,td在其存在于fifo1中期间可要求小时间窗口内的这些块中的一些。在这种情况下,td可直接从fifo1取回它,而无需作出对l1c的另一请求(不然的话它就必须作出),从而节省了访问l1c所需的功率并且可能改善了性能。
在一个实施例中,fifo2的大小被设定为改善性能。当块被td解压缩时,其生成解压缩的纹素。但是块中的许多纹素对于在当前高速缓存线中填入纹素可能不是立即需要的。然而,可能存在来自tc0的其他高速缓存线未命中请求,这些请求需要这些纹素。在一个实施例中,解压缩的纹素被存入到串流fifo2中。如果一些纹素是满足后续tc0高速缓存线填充确实需要的,则它们被从串流fifo2中取回,从而避免了td对整个压缩块的另一次解压缩。
在一个实施例中,fifo1和fifo2的串流fifo使用先进先出替换策略,消除了对于额外的替换策略管理状态的需要。在一个实施例中,串流fifo还具有表示在所有先前引用被处理之后fifo的未来状态的标签。在一个实施例中,串流fifo的一个方面在于它们捕捉纹理地址流中的短期空间局部性。在一个实施例中,控制硬件检测到fifo1中的所需压缩块或fifo2中的纹素群组存在并且计算分别从fifo1或fifo2访问它们的读取指针。也就是说,控制读取指针来利用第一读取指针选择第一缓冲器内的个体条目并且利用第二读取指针选择第二缓冲器内的个体条目。控制读取指针的能力允许了关于在td中访问l1c或对块解压缩方面的潜在节省。
图2是图示出根据一实施例的方法的流程图。压缩纹素数据被存储在第一纹理高速缓存(例如,l1c高速缓存)中。解压缩纹素数据被存储20在第二纹理高速缓存(例如,tc0高速缓存)中。对于一组像素的纹素数据接收215请求。对于请求的纹素数据安排220对于第一或第二纹理高速缓存的访问。
图3是图示出根据一实施例的方法以强调缓冲的方面的流程图。对于第一组像素的纹素数据接收305第一请求。从第一纹理高速缓存(例如,l1c高速缓存)取得310请求的压缩纹素数据。取得的压缩纹素数据被缓冲315在第一缓冲器中。例如,第一缓冲器可包括fifo1。第一缓冲器的输出被提供320给纹理解压缩器以对一个或多个压缩纹素数据块解压缩。所得到的解压缩纹素数据被缓冲325在第二缓冲器中。例如,第二缓冲器可包括fifo2。第二缓冲器的输出被提供330给第二纹理高速缓存(例如,tc0)。在一些实施例中,由第一缓冲器存储的一个或多个压缩纹素数据块除了请求的纹素数据以外还包括第二纹素数据。在一些实施例中,存储到第二缓冲器中的一个或多个未压缩纹素群组除了请求的纹素数据以外还包括第三未压缩纹素数据。这个第三纹素数据被用于构成在以后的事务中被tc0高速缓存请求的纹素数据的未压缩高速缓存线的一些部分。
图4根据一实施例图示了tc0高速缓存中的高速缓存数据和标签映射。在一个实施例中,每个周期处理16个请求,对应于对代表图示的四个像素(p0、p1、p2、p3)的2d纹理的16个请求,它们被映射到属于四方的纹素空间。每个像素与对应于纹素空间中的单位方形的角落的四个请求相关联,因此例如在坐标(u,v)、(u+1,v)、(u,v+l)和(u+l,v+1)处。通过将tc0级别的高速缓存线内的数据布置为包含纹素空间中的方形(或接近方形)区域,对于特定像素的这四个请求大多位于一高速缓存线内并且多个1b/2b请求在许多情况下甚至可共同位于4b双字内。
图4图示了在从0...9a...f以十六进制编号的16个存储库间如何布局纹素数据的示例。16个纹素(0...9a...f)的群组被包含在标签存储中具有单个标签的高速缓存线中。纹素的4x4方形集合(图示为包含十六进制数0...9a...f的方形)被映射到编号clo至cl15的每条高速缓存线。为了例示,纹素内的数字表示保存该数据的存储库。在此示例中,高速缓存线的标签被包含在由tb<num>指示的标签存储库中。为了例示,具有加粗轮廓的纹素方形例示了用于为像素计算过滤纹理值的纹素(例如,cl0tb0中的纹素0、1、2和3用于像素p0;cl4tb0中的纹素a和b以及cl5tb1中的纹素0和1用于像素p1;cl2tb2中的纹素6、7、c和d用于像素p2;并且cl3tb3中的纹素c、d、e和f用于像素p3)。
图4图示了当纹素数据大小是4b时高速缓存线如何被映射到四个标签存储库(tb0、tb1、tb2和tb3)的示例。在此情况下,纹理是每个4b大小的纹素的二维(2d)阵列。在一个实施例中,驱动器和纹理解压缩器协作来如图所示布局数据。每条高速缓存线的16个方形的每一者表示一纹素并且纹素内的数字表示保存该数据的存储库。注意在一个实施例中,按z序或莫顿序布局数据以利用两个维度上的局部性,这与利用一个维度或另一维度上的局部性的传统布局不同。z序(也称为莫顿序)是在保留数据点的局部性的同时映射多维数据的功能。
标记为(p0,p1,p2,p3)的方形指示出来自纹理请求的四方的四个像素映射到纹素空间中的何处。注意,虽然它们倾向于被映射到纹素空间中的方形,但它们也可被映射到纹素空间中的任何区域。邻近每个像素的虚线框中的纹素方形指示用于执行双线性过滤或加权平均来计算过滤纹理值的纹素。
在图4的这个示例中,每个像素使用非重叠的四个纹素,因此总共16个纹素需要被从高速缓存取得。这可表示罕见的极端情况,但被选择来概括例示tc0高速缓存的操作。
在一个实施例中,取决于高速缓存实现方式,tc0高速缓存的操作可考虑到对纹素访问的一个或多个约束。在一个实施例中,tc0高速缓存被配置为在数据访问期间至多访问来自每个存储库的一个唯一纹素。然而,在图4的示例中,每个像素要求对来自特定存储库的纹素数据的访问。例如,像素p2和p3访问被映射到存储库c和d的纹素,从而由于在数据访问期间从每个存储库至多访问一个唯一纹素的约束,对于像素p2和p3的访问发生在至少两个周期中。可能约束的另一个示例是对于tc0高速缓存的约束,即对于一标签存储库可作出不多于一个标签访问。
关于纹素访问的任何约束可被agc考虑来组织纹素访问的序列。在一个实施例中,图1b中所示的agc起到如下作用:将一个四方的访问分割成多个集合,使得每个集合可在没有数据存储库冲突或标签存储库冲突的情况下被执行(如果该约束适用的话)。在一个实施例中,agc可在一个周期中安排对于图4的p0和p2的访问,因为它们涉及用于高速缓存线clo和cl2的非冲突标签存储库tbo和tb2和用于p0的非冲突数据存储库(0,1,2,3)和用于p2的非冲突数据存储库(6,7,c,d)。类似地,对于p1和p3的访问仅分别涉及用于像素p1和p3的非冲突标签存储库tbo、tb1和tb3以及非冲突数据存储库(a,b,0,l)和(c,d,e,f)。
虽然一个四方的四个像素可映射到纹理空间中的任意位置,但它们在纹理空间中可倾向于接近。具体地,在有适当mip映射表面的情况下,纹理空间中的四方的像素之间的距离对于双线性采样倾向于小于1.5并且对于三线性采样的较高mip级别/较低mip级别分别倾向于小于1.0/2.0。
图5根据一实施例图示了对16个纹素的无冲突访问。图5代表了访问代表单个四方的16个纹素的场景,其中所有16个纹素都可在单个周期中被访问。当四方的像素在纹素空间中映射到的位置之间在纹素空间中水平和垂直分离时,足迹(或布局)是纹素的4x4集合,如加粗轮廓所示。方形p0、p1、p2和p3表示像素在纹素空间中的位置并且可以看出所有四个像素的四个相邻纹素的并集是纹素的4x4集合(带有加粗轮廓),随后称为纹素足迹。
在图5的情形中,纹素足迹中的纹素分布在四条高速缓存线上并且这些高速缓存线进而映射到四个不同的标签存储库。从而,可以并行访问标签,而没有存储库冲突。具体地,加粗纹素方形的编号是全异的;没有两个加粗方形具有表明它们映射到相同数据存储库的相同数字。因此,所有16个纹素可被以无冲突方式访问。一般地,无论4x4纹素足迹的位置如何,所有16个纹素都将被映射到不同的存储库,而且这些纹素映射到至多4条高速缓存线,这4条高速缓存线映射到不同的标签存储库。因此,无论4x4纹素足迹如何,都存在无冲突访问。对于此情况,agc着眼于纹素足迹并且在这种情况下将所有标签访问和数据存储库访问安排到单个周期。
图6图示了当执行双线性滤波时用于适当mip映射的纹理的纹素足迹的实施例。当纹素空间中的间距是大约1.5纹素时,像素倾向于共享相同纹素并且因此纹素足迹经常是如图6中所示的3x3。在此情况下,带有加粗轮廓的九个纹素具有不同的数字,表明足迹中没有两个纹素映射到相同的存储库。另外,所有九个纹素属于映射到不同标签存储库的两条高速缓存线之一。与之前一样,无论3x3足迹的定位如何,这些观察结果都适用。
在一些情况下,像素在纹素空间中可能是翘曲的。例如,纹素足迹可能是斜的或者以其他方式在水平/垂直方向上未对齐。即使在这种情况下,所有纹素都可被以无冲突方式访问,只要像素间间距小于1.5纹素。
图7根据一实施例图示了四方的最小2x2足迹。图7示出了当像素映射到纹素空间中的如此小的区域以至于纹素足迹被减小到最小2x2足迹9时的纹素足迹(即,带有加粗轮廓的四个纹素)。这在进行三线性过滤时可发生在例如较高的(不那么详细的)mip级别。此足迹可被以无冲突方式处理,其中四个纹素映射到不同的存储库,并且所有四个纹素可属于单条高速缓存线。
从而,在一示例实施例中,tc0高速缓存支持每周期四个标签查找。64b的每个tc0高速缓存线被映射到16个存储库,每个32b宽。每个存储库具有单个读取端口。如果四方的请求要求对每个存储库的多于一次访问或者多于四次标签查找,则该请求被分割在多个周期上,以便在每个周期中满足这些约束。
此外,为了对于许多情况提供良好的性能,在一个实施例中,驱动器在存储器中组织纹理数据并且硬件解压缩器进一步在tc0高速缓存线中布置数据以使得数据存储库冲突和标签查找达到最低限度。在一个实施例中,纹理数据被组织成mtile,其中高速缓存线被驱动器按莫顿(z)序组织以使得纹素的连续方形块要求最小数目(即,小于预定义数目)的不同高速缓存线并且因此要求最小数目的标签查找。从而,在一个实施例中,只要代表四方的四个纹素的纹理请求映射到mtile内的高速缓存线的2x2块,则不需要多于四个标签查找。
在一个实施例中,在64b的tc0高速缓存线大小的情况下,常见的2b/纹素纹理中的每条高速缓存线保存8x4纹素块。因此,2x2高速缓存线块保存16x8纹素块。四方的纹素足迹可以是3x3纹素块。在适当的mip映射的情况下,最大预期纹素足迹是朝向45度并且在纹素空间中具有2纹素的像素间距离的四方的。这种纹素足迹是(2√2+1=)3.8x3.8块,很好地在2x2高速缓存线块中包含的16x8纹素下。因此,对于许多情况避免了存储库冲突。
在一个实施例中,在请求没有被适当mip映射的情况下,原始的纹理请求被分割成多个请求。在常见的情况中,纹理高速缓存以非常高效的方式处理16个请求,利用了这些请求的预期属性来实现高带宽和高功率效率两者。
图8根据一实施例图示了纹理高速缓存体系结构的一部分的子块。在图6中省略了l1c高速缓存。在一个实施例中,对于tc0高速缓存提供l0数据存储。在一个实施例中,l0数据存储对应于16个存储库,每个存储库有32个字并且每个字有32b。l0数据读取控制块和l0数据写入控制块控制从l0数据存储读取和写入数据。在一个实施例中,l0纵横式交换矩阵被用于输出纹素数据。l0读取延时fifo从agc接收存储库地址。l0行与写入控制延时fifo从l0标签存储接收行地址。
在一个实施例中,第一输入801(来自纹理地址(ta)子单元(图8中未示出))对应于最多达(upto)16个地址。每个请求是对于最多达16个纹素的,对应于纹理基地址和2d纹理中的16个(u,v)坐标。每个请求的纹理基地址在所有16个纹素间是共享的。每个四方由四个像素构成并且每个像素访问布置在具有一对坐标coordu和coord_v的单位方形中的4个纹素。在每一对中,coord_u[i][l]可以是coord_u[i]+1,除了卷绕情况以外。对于3d纹理,每个像素访问布置在单位立方体中的8个纹素,要求另一个坐标coord_w来指定额外的维度。
在一个实施例中,来自ta单元的第一输入分组上的剩余字段是从状态以及输入得出的。mip映射的宽度、高度和深度对于此请求是在mip级别的纹理图像的维度并且是从提供的基地址计算偏移量所需要的。在一个实施例中,纹理格式以特定的纹素大小描述纹理图像的格式。在一个实施例中,该格式的一些方面被下游td子单元使用。在一个实施例中,两个字段nr_samples和sample_idx被用于多重采样的纹理访问。
在一个实施例中,纹素数据输出802由16个纹素的两个集合构成,其中每个纹素32b宽。对于大于32b的纹素大小,输出的2之幂集合被集群在一起以发送单个纹素并且16个纹素的集合是在多个周期中递送的。
箭头803和804图示了与l1c高速缓存的交互。在tc0高速缓存未命中的情况下,向l1c高速缓存作出提供高速缓存线的虚拟地址的请求。由于虚拟地址是48b并且高速缓存线大小的log2是6b,所以此地址是42b。作为响应,l1c递送64b数据。
在一个实施例中,agc对于一个四方的四个像素接收u、v、w维度上的两个坐标位置,总共16个坐标,来指定16个纹素。agc输出由最多达四个标签请求以及从数据阵列访问纹素所需的数据存储库和纵横式交换矩阵控制比特构成。
在一个实施例中,agc接受来自纹理地址单元的16个请求并且在tc0tag存储中生成标签查找。此外,agc生成用于对于16个存储库的每一者选择四个线地址之一并且将32b的数据从每个数据存储库路由到输出端口的控制比特。标签在未命中时被立即更新并且未命中被发送到l1c高速缓存。数据访问被延迟,直到数据从l1c到达为止。延迟的访问请求被保存在延时fifo中并且被以有序方式处理。16个存储库可代表16个纹素被同时读取。数据在输出纵横式交换矩阵处被路由到正确的纹素输出。
在一个实施例中,agc将这16个请求组织成最小数目的集合(例如,一个),以使得一个集合内的纹素请求不访问多于四条高速缓存线并且从16个数据存储库的每一者不多于一个4b取得。在一个实施例中,agc在每个周期中向l0标签存储提供最多达四个标签。l0标签存储写入到l0行与写入控制延时fifo中。在一个实施例中,提供合并器(cls)和cls控制器来支持将解压缩的块合并成标准形式大小。
在一个实施例中,数据写入控制块接受来自合并器的进入数据并且填充tc0数据阵列。lo数据读取控制块弹出被agc写入的rdl0fifo并且协调读出最多达四条高速缓存线以及从这四条高速缓存线选择最多达16个纹素的数据。tc0将最多达16个纹素递送到纹理过滤器。
在一个实施例中,tc0高速缓存参数是2kb大小、64b线大小、32线、4集合、8向集合关联的。在一个实施例中,tc0高速缓存是利用40b基地址和u,v坐标的串接来寻址的,其中u,v坐标对于2d纹理各自是14b,总共40+28=68b。但3d纹理具有三个坐标,每个11b,从而要求在纹素空间中支持40+33=73b的地址宽度。然而,考虑到ctile中的最小纹素块是2x2xl并且在每个轴上ctile中的纹素的数目是2的幂,u,v坐标将始终是偶数的。不必将u,v坐标的lsbl比特存储为标签。这留下了71b的标签比特。每个周期总共有四个进入的标签,它们全都可指向特定的标签存储库。每个标签存储库具有充足的比较器和其他资源来支持最多达四个进入标签上的标签匹配。每个进入的71b标签地址被并行地与全部8个71b标签相比较。在匹配时,5b线地址被向下发送到读取标签延时fifo。
在未命中时,未命中的地址被发送到l1c高速缓存。在一个实施例中,四条高速缓存线请求的每一者可未命中高速缓存,导致在一个周期中生成最多四个未命中。在未命中时,用于该存储库的相应data_ram_line_miss比特被设置。该集合的八条线之一被选择来替换并且其标签被新的标签所覆写。在一些情形中,在替换的标签上可能有未决请求,但由于对于这些请求已经对线地址执行了查找,这意味着可以只是就在第一次使用之前并且因此在任何未决请求之后覆写高速缓存线。在串行高速缓存组织的情况下,标签甚至可以在相应的数据已被从数据ram读出之前被覆写。
在一个实施例中,采用基于局部性的替换策略来最大限度地利用纹理访问中的空间局部性。当将输入71b标签与高速缓存集合中的标签相比较时,也判定差别是否仅在协调成分的较低比特中。首先从高位未命中标签中选择出牺牲者。当没有高位未命中标签时,从低位未命中标签中选择出牺牲者。在一个实施例中,在相同优先级群组中使用随机选择。由以下标准检测低位未命中。如果在基地址中存在差别,则其是高位未命中。否则,对于2d纹理、切片组织的3d纹理:如果差别仅在每个u,v坐标成分的lsb6比特中,则其是低位未命中。对于3d块组织的3d纹理:如果差别仅在每个u,v,w坐标成分的lsb4比特中,则其是低位未命中。否则,其是高位未命中。
如图8中所示,在一个实施例中,串流fifo1(lsf表示其从l1高速缓存接收数据)保存从l1c递送来的可能压缩的高速缓存线。td将压缩纹素的块解压缩成解压缩高速缓存线。串流fifo2(dsf表示其从解压缩器接收数据)保存这些解压缩高速缓存线。tc0保存被组织成64b高速缓存线的解压缩纹素,其中每个4b片段被存储在单独的数据存储库中,整条高速缓存线存储在16个数据存储库上。
在一个实施例中,每个解码的rgbaastc纹素占据8字节的空间(对于每个成分是浮点16),允许了tc0高速缓存线(64b)保存被组织为具有4列2行的4x2块的8个未压缩纹素。每个压缩的8bastc块包含5x5压缩纹素。在未命中时,tc将请求4cx2r未压缩纹素(4列乘2行)的网格。取决于未压缩网格如何映射到压缩astc网格上,4cx2r网格可映射到多个(1-4个)压缩astc块。
在一个实施例中,cls和关联的控制特征被用于产生可被加载到l0数据存储中的未压缩纹素数据的对齐块。这对于astc中存在的非2之幂块大小维度是有用的。对于其他压缩方案,解压缩因子是小的2之幂,并且每个压缩块容易扩展到64b高速缓存线中。也就是说,对压缩块的小2之幂集合解压缩产生可被直接加载到l0数据存储中的对齐的64b未压缩纹素数据。在一个实施例中,解压缩器与lsf控制器(decompressor&lsfcontroller,dlc)控制器对多个(可变大小)astc块解压缩以产生64b线中的解压缩4x4纹素块。经由到fifo1和fifo2中的读取指针的控制提供额外的协调。
作为示例,考虑如果在没有适当协调和再利用的情况下解压缩和利用astc块则可如何浪费功率和带宽。4b的标称纹素大小,这对于l0数据存储中的64b线意味着4x4块。由于astc非2之幂块在l0数据存储高速缓存线中未在4x4未压缩块上对齐,所以每个这样的块可要求解压缩到最多达4个块(比如6x6),总共6*6*4=144个纹素。这些纹素中只有16个是4x4块所需的。因此,最多达144-16=128个纹素可被丢弃,浪费了解压缩器功率和带宽。另外,这4个块在最坏情况下可在4个单独的64b线上,浪费了l1c访问功率和带宽。
然而,假定在纹理访问模式中有大量的空间局部性。因此,很有可能在填充l0数据存储中的一个4x4块时未使用的解压缩纹素将很快被用于填充其他请求的附近4x4块。类似地,包括l1高速缓存线的4个astc块很有可能要被再用于附近的4x4块。因此,高速缓存压缩的l1高速缓存线和解压缩的astc块的两个小缓冲器(fifo1和fifo2)在减少从l1c取得的高速缓存线块的数目和未使用的解压缩纹素的数目上是有效的。
在串流fifo中,最旧的写入线始终被选择来替换。从而,写入指针在每次写入时被以卷绕方式递增。然而,读取可从写入的窗口内的任何线发生。一条线可被读取多次,从而导致对再利用的利用。返回的l1c高速缓存线被存放到串流fifo1中。解压缩器从串流fifo1读取16b块(对于非astc可能更大),对它们解压缩并且将它们送出到cls。cls收集td输出数据来构造64b高速缓存线并且将它们写入到l0数据存储中。串流fifo是目标在于消除到l1c的过多请求流量的简单高速缓存结构。
tc在解压缩器的输入处使用小缓冲器,因为同一压缩块可能是生成时间上邻近的多个解压缩64b块所需要的。
图8的额外方面包括对于标签未命中接收标签的标签未命中fifo(由标签未命中串行化器串行化)。选择未命中四方请求(selectmissingquadrequest,smqr)块选择未命中请求之一,将其与基地址和来自纹理图像描述符的关联信息配对,并且将整个封包递送到压缩块地址生成单元(compressedblockaddressgeneration,cbag)。具体而言,对于每个维度,cbag计算纹素维度的最小值和最大值。对于2d纹理,输出因此是基地址、(umin,umax)和(vmin,vmax)。在一个实施例中,cbag计算压缩(存储器)地址空间中的最多达4个astc块地址。一般地,此地址计算涉及将每个维度范围除以该维度上的astc块大小。例如,对于5x6块,将(umin,umax)除以5并且将(vmin,vmax)除以6来得到需要的astc块。接下来,计算这些块的每一者的地址。输出是最多达4个astc块地址的集合,其低位4b是零(由于astc块大小是24=16b)。
在一个实施例中,纹理解压缩器(dc)每个周期可处理以预定义组织之一布局的最多达4个输出纹素。在一个实施例中,dsf标签查找和lsf标签查找将存储器访问流量分割成多个预定义的纹素足迹模式并且将它们逐一送出。图9根据一实施例图示了dc可处理的astc纹素足迹模式的示例。图示了六个不同的示例情况,其中图示了在一个或两个周期中处理1、2、3或4个纹素的不同选项。
在一个实施例中,cls被dsf条目信号所控制,dsf条目信号进而通过dsf标签查找接收控制比特。这些控制比特指定来自9个存储库的最多达9个纹素四方的集合(对于4b纹素大小情况),虽然从4像素四方可生成4x4大小块。额外的控制比特指定这些四方的哪些部分被路由到l0数据存储中的64b高速缓存线的哪些部分。cls读取规定的四方,路由数据并且在接收到(例如,来自cc的)准备就绪信号时将64b高速缓存线写入到l0数据存储中。
在一个实施例中,来自dsf标签查找的进入地址在完全关联lsf标签查找中被进行命中测试。未命中被分配以被推进的写入指针处的条目。未命中被发送到l1c。在一个实施例中,既作为串流fifo也作为l1c与解压缩器控制(dlc)之间的缓冲器,lsf控制fifo功能。
图10根据一实施例图示了agc过程流。组织纹素请求的过程被分散在多个步骤上(s0、s1、s2、s3、s4),其中每个步骤尝试组合满足约束集合更大或不同的一组请求。在一个实施例中,约束的集合包括来自每个存储库的不多于四条不同的高速缓存线和不多于一个双字。然而,将会理解可利用其他约束。在第一步骤s1中,检查源自于每个像素的请求以找出用于这些请求的高速缓存线地址。每个高速缓存线地址随后被链接到四个请求的每一者所要求的存储库偏移量。此过程在图8中被称为桶装(bucketing)。第一步骤s1因此产生四个群组,每个群组具有四个桶,每个桶包含最多达四个纹素请求。在后续步骤中,每个桶可包含许多另外的纹素请求,只要它们不与该群组中的其他请求具有存储库冲突。在一个实施例中,驱动器软件组织纹理数据以使得与一像素相关联的请求极为不可能具有存储库冲突。然而,在存在存储库冲突的罕见情况下,相应的像素的请求被单独处理。
在第二步骤s2中,考虑桶对的两个组合。例如,对p0&p1的桶装检查与曾在两个不同桶集合中的像素p0和p1相关联的所有请求是否能被放入单个桶集合中,而同时仍满足约束,即,从每个存储库不多于四条不同高速缓存线且不多于一个双字。在第二步骤结束时,我们具有两个情况的桶装,其中像素被不同的配对。
第三步骤s3检查两组配对是否失败,在失败的情况下我们对p0和p3的第三配对进行桶装并且如果该桶装符合约束的话则发送对p0&p3的请求。在此之后是检查p1&p2(未示出)。然而,最常见的情况是两个情况1和2都符合所有约束,在此情况下该过程考虑桶装所有四个像素,如“桶装p0&p1&p2&p3”所示。再一次,示例情况是此桶装是成功的并且来自四个像素的请求的所有请求都可在同一周期中被处理。
图10也图示了其他情况,例如当像素p0的请求必须被单独发送时,如步骤s4中所示。该过程是层次化的,开始于单个像素的请求,然后构建对,最后是就其标签和数据存储库访问要求而言兼容的像素的四方。该过程在全部四个像素都被桶装在一起的常见情况下高效地终止,但对于在其他情况下迅速确定兼容的子集也是有用的。
图11根据一实施例示出了三个可能块映射的示例的纹理高速缓存边界和astc块图。图12图示了15x15astc纹理的示例。粗黑线1105示出了tc0中的高速缓存线边界和未命中时对dc的请求。细黑线1110示出了纹理的astc5x5块边界。在未命中时,tc0从td中的astc解码器请求4x2纹素网格。取决于高速缓存线未命中,三种类型的请求是可能的。对于0类块,未命中映射在一个astc5x5块内。td将在2个周期中递送解码的纹素(吞吐量而不是延时的度量)。对于1类块,未命中映射到两个astc5x5块。td将在2个(块b)或3个(块a)周期中对该块解码。块a在第二个astc块上要求2个周期(因为其需要对6个纹素解码)并且在第一个astc块上要求1个周期(1cx2r)。块b在两个astc块的每一者上要求1个周期。2类块未命中映射到4个astc5x5块上。块a和b两者对于解码都要求四个周期。在一个实施例中,td被要求对2cx2r、4cx1r(或子集)和1cx2r块解码以支持吞吐量。
除了支持astc以外,串流fifo2在示例实施例中还可高效地支持etc2压缩格式。结果,在一个实施例中,串流fifo2包括4个128比特宽的存储库,足以存储8个astc解码纹素或16个etc2解码纹素。每个存储库在示例实施例中具有对通道掩蔽的支持和写入高64b或低64b的能力。就astc解码纹素的4x2块内的纹素编号而言,存储库0保存纹素0和1,存储库1保存纹素2和3,等等依此类推。在示例实施例中,对于所有三种类型的块都没有存储库冲突发生。
在示例实施例中,如果有灵活性的选择,则解码器对4cx1r或1cx2r块解码。td对于1类块b情况将只对2cx2r块解码。
现在将描述对于astc纹理的纹理高速缓存到纹理解压缩器排序的示例。对于0类块,为了填充高速缓存线,可向td作出对于8个纹素的请求。对于向td单元请求解码,存在两个选择。该请求可以是最多达2个4cxlr块的请求或者最多达2个2cx2r块的请求。
在一个实施例中,对于1类块,对于来自两个astc块的未压缩数据作出请求。其从每个块请求2-4个纹素。在一个实施例中,遵循以下顺序:
·从左上astc块请求1cx2r或2cx2r或3cx2r。
·对于lcx2r请求,在一个实施例中,串流fifo2解压缩器输出对于个体纹素到不同存储库的通道掩蔽具有支持(例如,纹素0被写入到存储库0,纹素4被写入到存储库2,纹素3被写入到存储库1,并且纹素6被写入到存储库3)。
·对于2cx2r情况,请求分别被写入到存储库0和存储库2,或者反之。
·从右上astc块请求1cx2r或2cx2r或3cx2r。
·始终遵循请求的z序。
对于2类块,纹理高速缓存从四个astc块请求数据。在这些情况下,保持z序。
从左上astc块请求1cxlr或2cx1r或3cx1r。
·从右上astc块请求1cx1r或2cxlr或3cxlr。
·从左下astc块请求lcxlr或2cxlr或3cxlr。
·从右下astc块请求lcxlr或2cxlr或3cxlr。
在这些情况下,排序是完全相同的,并且串流fifo2中对通道掩蔽的支持允许了数据被高效地写入。支持3cx2r要求td上的额外缓冲并且这可被进一步分割成两个3cx1r请求。
未压缩域地址和存储器中的相应压缩块的地址之间的关系对于astc中使用的非2之幂块大小可能是复杂的。对齐的64b块所需要的纹素数据可来自多个压缩块。
图12图示了示出astc5x5:64b纹素的示例。边界由细黑线1110图示。块在细黑线中在第一行上从00..02编号,最后一行编号为20…22。高速缓存线包含4个astc块(00、01、10、11)。
纹理高速缓存块是4x264b纹素。块边界由粗黑线1105图示。块在粗黑线中在第一行上从00..03编号并且在第一列上编号为00至50。
第一访问具有作为0的示为阴影块的纹素足迹并且第二访问具有作为1的斜线块足迹。
从空高速缓存/缓冲器开始,第一访问将具有(00,01,10,11)的高速缓存线带入lsf中,对astc细黑块00解压缩并存储在dsf中,用未压缩的粗黑块10、20填充tc0。
第二访问对于astc块00在dsf中命中并且对于astc块(01,10,11)在lsf中命中。这节省了对astc块00的重复解压缩和对于包含(01,10,11)的高速缓存线再次访问l1c。
对astc块(01,10,11)执行解压缩。合并器组合所有三个加上解压缩的00来生成未压缩的粗黑块21。这用未压缩的粗黑块21填充tc0。
本发明的实施例的一个示范性但非限制性的应用在移动环境中。在移动环境中,对于将数据从主存储器经由l2高速缓存传送到gpu的纹理高速缓存所要求的存储器带宽和功率存在约束。将双字(4b)从低功率双数据率随机访问存储器(lowpowerdoubledataraterandomaccessmemory,lpddr)移动到l1高速缓存的能量成本被估计为是进行浮点操作的约50倍。从而,本文公开的示例实施例可促进在移动gpu的纹理单元中实现高压缩因子的压缩格式。
虽然压缩格式就数据移动成本而言可能是能量效率高的,但与解压缩相关联的能量成本可能是相当大的。例如,在示例块压缩格式中,解压缩器在两个颜色之间线性插值来生成总共比如四种颜色。解压缩器随后基于纹素地址选择索引并且使用该2b索引来选择四个颜色之一。插值的能量成本可能是相当大的。索引机制引入了两个级别的查找。随着支持多种更精致压缩方案的趋势,解压缩和数据路由能量成本可占整体纹理单元功率的重大部分。
为了将这些成本的一些分摊在多个纹素访问上,纹理高速缓存体系结构的示例实施例在解压缩器和寻址逻辑之间插入第0级(tc0)高速缓存。tc0高速缓存保存解压缩的纹素,这与以压缩格式保存纹素数据的第1级高速缓存(l1c)不同。解压缩的能量成本被分摊在多个周期中、多个纹素访问上。例如,如果在四个连续的周期中从4x4压缩块访问四个纹素,则tc0高速缓存在四个周期中保存未压缩纹素并且解压缩成本只被招致一次,与没有解压缩tc0高速缓存情况下的四次形成对比。
对传统上用于支持非2之幂块尺寸的功率和面积作出贡献的另一因素是虽然高速缓存线包含具有例如8x4这样的2之幂尺寸的未压缩纹素块,但存储器中的压缩块的尺寸可以是非2之幂的,例如7x5。在这种情况下,压缩块的边界可不与高速缓存线中的2之幂块的边界对齐。在这个特定示例中,填充8x4可要求两个7x5块或4个7x5块。结果,纹理解压缩器必须对许多压缩块解压缩来填充高速缓存线中的所有纹素。示例实施例可被利用来对非2之幂块尺寸支持改善的性能。相同压缩块(或同一l1c高速缓存线中的其他块)中的许多可能是填充接下来几个未命中高速缓存线中的纹素所必需的并且必须被从l1c重复取得,导致了浪费的带宽和功率。保存最近访问的压缩块的串流fifo1可起到减少对l1c的访问的作用。如果接下来几个高速缓存线填充请求要求相同的压缩块,则串流fifo1将它们递送到td,而不要求l1c访问。
纹理高速缓存体系结构的实施例的一个方面是纹理高速缓存客户端对于延时是相对不敏感的。在cpu第1级高速缓存中,标签访问和数据访问被并行进行(或者使用某种方式的预测硬件)来将高速缓存命中延时减少到大约1-4个周期。由于涉及例如细节层次(levelofdetail,lod)计算和纹理过滤操作的复杂寻址逻辑,即使在没有任何第1级未命中的情况下纹理单元的延时也可超过50个周期。在高速缓存未命中、然后是到不同地址的高速缓存命中的情况下,cpu高速缓存立即递送命中高速缓存的数据,而不是等待不相关的未命中数据从下一个存储器层次体系级别到达。这种不按顺序的或者未命中之下命中(hit-under-miss)的数据返回可减少cpu中的单个线程的延时,但不在gpu中提供重大的益处,这是由于着色器核访问的向量性和图形流水线的整体有序性。考虑到着色器性能对于纹理延时的相对不敏感性、由于纹理寻址和过滤引起的大的固定成分以及整体图形流水线的有序性,对cpu第1级高速缓存组织的替换方案是有吸引力的。
在一个实施例中,发送到纹理高速缓存体系结构108的所有地址被有序地处理。在高速缓存未命中之后是高速缓存命中的情况下,高速缓存命中的数据的递送被延迟,直到高速缓存未命中的数据之后为止。另外,标签阵列中的命中不一定意味着相应的数据存在于高速缓存中,而只意味着一旦所有先前引用被处理其就将存在于高速缓存中。其中所有引用被有序地整体流传输过高速缓存的这个纹理高速缓存的串流行为带来了重要的益处和设计简化。在图形流水线中,状态和工作是有序的,也就是说,接收到的任何状态只适用于后来的工作请求。对未命中前的命中的无序处理使状态到数据的应用复杂化。例如,纹理过滤逻辑必须认识到较新的状态要被应用到命中,而同时其保持着较旧的状态来应用到未命中。在其他高速缓存中,如果标签比较在主标签阵列上失败,则控制逻辑进一步发起对于在同一高速缓存线上是否有更早的未解决的未命中的检查。在示例实施例中,此检查在串流高速缓存中是不必要的。
在一个实施例中,一种图形处理单元的示例包括:控制器,被配置为接收对于第一像素群组的纹素数据的第一请求;第一缓冲器,存储响应于第一请求从第一纹理高速缓存取得的压缩纹素数据的一个或多个块,压缩纹素数据的一个或多个块至少包括所请求的纹素数据;纹理解压缩器,对存储在第一缓冲器中的压缩纹素数据的一个或多个块解压缩;以及第二缓冲器,存储解压缩的压缩纹素数据的一个或多个块并且将解压缩的所请求的纹素数据作为输出提供到第二纹理高速缓存;其中由第一缓冲器存储的压缩纹素数据的一个或多个块除了所请求的纹素数据以外还包括第二纹素数据。在一个实施例中,第一缓冲器可以是第一fifo缓冲器并且第二缓冲器可以是第二fifo缓冲器。在一个实施例中,由第一缓冲器存储的压缩纹素数据的一个或多个块除了所请求的纹素数据以外还可包括第二纹素数据。在一个实施例中,控制器可被配置为接收对于第二像素群组的纹素数据的第二请求,第一请求的一个或多个块的至少一部分对应于第二像素群组的至少一部分;并且第一缓冲器被配置为响应于第二请求向纹理解压缩器提供该一个或多个块的该部分,而没有从第一高速缓存的第二次取得。在一个实施例中,控制器可被配置为接收对于第二像素群组的纹素数据的第二请求,第二请求的至少一个纹素对应于由于处理第一请求而存储在第二缓冲器中的解压缩纹素数据;并且第一缓冲器被配置为响应于第二请求而向第二纹理高速缓存提供第二请求的该至少一个纹素,而没有从第一缓冲器的第二次解压缩。在一个实施例中,第一纹理高速缓存可被配置为存储非2之幂块大小。在一个实施例中,第二纹理高速缓存可被配置为存储2之幂块大小。在一个实施例中,可包括合并器单元来在存储在第二纹理高速缓存中之前合并解压缩的纹理数据。在一个实施例中,第一纹理高速缓存存储根据自适应可缩放纹理压缩(astc)编解码器的块大小。在一个实施例中,控制器可控制第一缓冲器的第一读取指针以选择第一缓冲器内的个体条目并且控制第二缓冲器的第二读取指针以选择第二缓冲器内的个体条目。
在一个实施例中,一种操作图形处理单元的方法的示例包括:接收对于第一像素群组的纹素数据的第一请求;从第一纹理高速缓存取得所请求的压缩纹素数据;将取得的压缩纹素数据缓冲在第一缓冲器中;将第一缓冲器的输出提供到纹理解压缩器并且对压缩纹素数据的一个或多个块解压缩;将解压缩的纹素数据缓冲在第二缓冲器中;并且将第二缓冲器的输出提供到第二纹理高速缓存;其中由第一缓冲器存储的压缩纹素数据的一个或多个块除了所请求的纹素数据以外还包括第二纹素数据。在一种方法的一个实施例中,第一缓冲器是第一fifo缓冲器并且第二缓冲器是第二fifo缓冲器。在一个实施例中,由第一缓冲器存储的压缩纹素数据的一个或多个块除了所请求的纹素数据以外还包括第二纹素数据。在一个特定实施例中,对第一缓冲器的读取指针被选择来再利用第一缓冲器中的纹素数据以服务多于一个对纹素数据的请求。在一个实施例中,对第二缓冲器的读取指针被选择来再利用第二缓冲器中的纹素数据以服务多于一个对纹素数据的请求。一个实施例包括再利用为第一请求取得的第一缓冲器中的纹素数据来至少部分服务对于第二像素群组的纹素数据的第二请求,而没有从第一纹理高速缓存的第二次取得。在一个实施例中,第一纹理高速缓存被配置为存储非2之幂块大小。在一个实施例中,第二高速缓存被配置为存储2之幂块大小。一个实施例还包括在存储在第二高速缓存中之前合并从第二缓冲器接收的解压缩纹理数据。在一个特定实施例中,来自多个非2之幂块的纹素数据被合并。
在一个实施例中,一种图形处理单元的示例包括:第一纹理高速缓存,被配置为存储压缩纹素数据;第二纹理高速缓存,被配置为存储已从第一纹理高速缓存解压缩的纹素数据;以及控制器,被配置为接收对于像素群组的纹素数据的请求,并且为了该纹素数据安排对第一纹理高速缓存或第二纹理高速缓存的访问。在一个实施例中,控制器还被配置为:判定在第二纹理高速缓存中对于所请求的纹素数据是存在高速缓存命中还是高速缓存未命中;响应于对高速缓存未命中的判定,为所请求的纹素数据访问第一纹理高速缓存;并且响应于对高速缓存命中的判定,为所请求的纹素数据访问第二纹理高速缓存。在一个实施例中,数据基于存在于访问集合中的局部性模式被组织到第二纹理高速缓存中。在一个实施例中,第二纹理高速缓存让纹素数据被分组到按莫顿序组织的与连续二维纹素块相对应的高速缓存线中。在一个实施例中,控制器还被配置为将请求的纹素地址的集合划分成至少一个非冲突存储器访问的序列。在一个实施例中,该至少一个非冲突存储器访问不具有标签冲突或数据存储库冲突。在一个实施例中,控制器还被配置为基于每存储库的不同高速缓存线的数目或双字的数目中的至少一者来组合满足约束集合的纹素请求。在一个实施例中,控制器还被配置为:查找源自于像素群组的每个像素的纹素请求所要求的高速缓存线地址;并且组合满足从每个存储库不多于四条不同高速缓存线和不多于一个双字的约束的纹素请求。在一个实施例中,第二纹理高速缓存具有4向入库标签查找和16向入库数据存储。在一个实施例中,第二纹理高速缓存中的纹素的布局被选择来确保纹素足迹中的四方纹素在不同存储库上。
在一个实施例中,一种操作图形处理单元的方法的示例包括:将压缩纹素数据存储在第一纹理高速缓存中;在第二纹理高速缓存中存储已从第一纹理高速缓存解压缩的纹素数据;接收对于像素群组的纹素数据的请求,并且为了该纹素数据安排对第一纹理高速缓存或第二纹理高速缓存的访问。在一个实施例中,安排包括:判定在第二纹理高速缓存中对于所请求的纹素数据是存在高速缓存命中还是高速缓存未命中;响应于对高速缓存未命中的判定,为所请求的纹素数据访问第一纹理高速缓存;并且响应于对高速缓存命中的判定,为所请求的纹素数据访问第二纹理高速缓存。一个实施例还包括将第二纹理高速缓存中的纹素数据组织到贴片(tile)中,在这些贴片内高速缓存线被以莫顿序组织以使得连续二维纹素块要求小于预定义数目的不同高速缓存线和标签查找。一个实施例还包括将请求的纹素地址的集合划分成非冲突访问集合的集合。在一个实施例中,非冲突访问集合不具有标签冲突或数据存储库冲突。一个实施例还包括基于每存储库的不同高速缓存线的数目或双字的数目中的至少一者来组合满足关于数目的约束的集合的纹素请求。在一个实施例中,组合纹素请求包括组合满足从每个存储库不多于四条不同高速缓存线和不多于一个双字的约束的纹素请求。在一个实施例中,第二纹理高速缓存具有4向入库标签查找和16向入库数据存储。在一个实施例中,第二纹理高速缓存中的纹素的布局被选择来确保纹素足迹中的四方纹素在不同存储库上。在一个实施例中,数据基于存在于访问集合中的局部性模式被组织到第二纹理高速缓存中。
虽然已结合特定实施例描述了本发明,但将会理解并不意图将本发明限制到描述的实施例。相反,意图覆盖可包括在如所附权利要求限定的本发明的精神和范围内的替换、修改和等同。没有这些具体细节中的一些或全部,也可实现实施例。此外,可不详细描述公知的特征以避免不必要地模糊本发明。根据本发明,组件、过程步骤和/或数据结构可利用各种类型的操作系统、编程语言、计算平台、计算机程序和/或计算设备来实现。此外,本领域普通技术人员将会认识到,在不脱离本文公开的发明构思的范围和精神的情况下,也可使用诸如硬连线设备、现场可编程门阵列(fieldprogrammablegatearray,fpga)、专用集成电路(applicationspecificintegratedcircuit,asic)之类的设备。本发明也可有形地体现为存储在诸如存储器设备之类的计算机可读介质上的计算机指令的集合。
- 还没有人留言评论。精彩留言会获得点赞!