一种基于用户词典的网络社交文本大数据处理方法及系统与流程
本发明涉及一种基于用户词典的网络社交文本大数据处理方法及系统。
背景技术:
随着互联网技术的迅速发展,网络无时无刻地不在影响着人们的生产、生活乃至社会发展。根据IDC(网络数据中心)预测,全球数据的额总量每两年就增加一倍,估计到2020年会达到35ZB,而且绝大部分数据具有非结构或半结构化的特点,人们对大数据的关注程度也日益升高。
同时,互联网的发展也带动了以微博为主导的社交媒体的迅猛发展,不论是国外以Twitter为代表的社交媒体,还是国内以腾讯微博和新浪微博为代表社交媒体,其用户都在不断增长。如此巨大的用户基数,产生了巨大的数据,而这些数据蕴含着巨大的价值。网络社交文本大数据呈现出数量巨大、增长速度快、结构多样化等特点,传统的数据处理方式是总体中抽取样本来进行有关领域的分析,这样分析出来的结果并不是对真实数据的描述,只有采用新的数据处理方式才能获得大数据更加全面有效的信息。正如前文所述,微博文本数据也有非结构化或半结构化的特点,将其结构化处理对数据价值发掘具有重大意义。
早期对于大数据的处理由于受到计算机硬件及技术的影响发展缓慢,巨大的信息资源并没有完全被发掘出来。目前的关于大数据的研究主要集中在云计算、视觉分析、数据挖掘等方面,大数据的处理技术中的分布式计算在大型集群中的简化数据处理技术,该技术需要通过计算机相互连接组成分散系统,比较复杂,技术实现较为困难。
技术实现要素:
本发明的目的就是为了解决上述问题,提供一种基于用户词典的网络社交文本大数据处理方法及系统,本发明技术提出相应的网络社交文本非结构或半结构化数据如何转化为结构性的数据,对网络社交文本大数据分析价值的挖掘,以及网络社交文本大数据处理的方法与技术。采用集中式计算的方法,将半结构化数据的数据转化为结构化的数据,本发明主要是对半结构化的数据进行处理,通过对有代表性的样本微博中抽取相关的心理品质关键词,通过人工评判与问卷调查来删减词汇,构建某种心理品质的用户词典。基于模糊匹配及权重设置(程度级别词语与否定词)对微博文本消息中的关键词进行频数统计。
为了实现上述目的,本发明采用如下技术方案:
一种基于用户词典的网络社交文本大数据处理方法,包括:
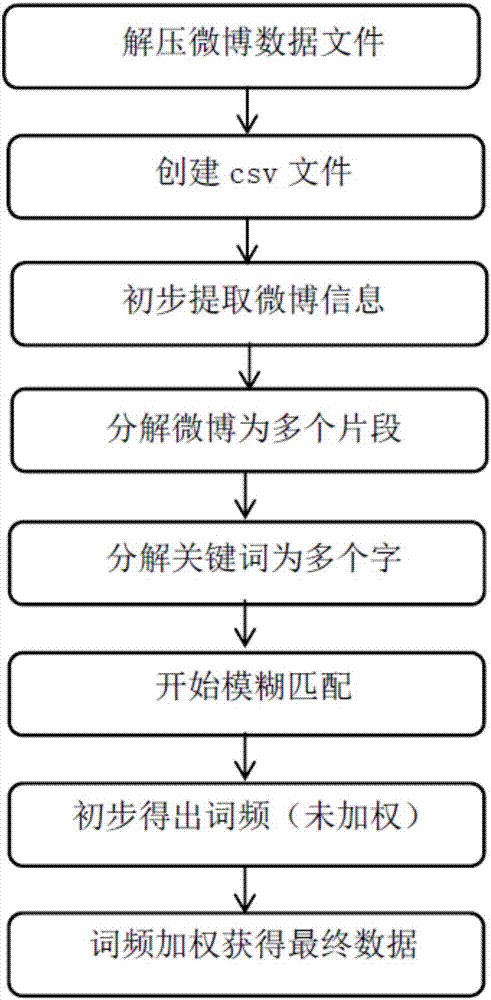
步骤(1):网络社交文本大数据的获取:在新浪微博开放平台上获取新浪微博用户的微博文本,由于微博文本数据存储空间大以及为了保证大数据的获取速度,从网上下载了文本压缩文件;然后对文本压缩文件解压缩处理得到包含微博数据的txt文件,对包含微博数据的txt文件进行数据信息初步的提取;
步骤(2):用户词典的构建:从微博数据中筛选符合待研究心里品质的词汇,对该词汇进行预处理,根据预处理后的词汇编制调查问卷,根据调查问卷的问卷题目筛选结果,构建用户词典;
步骤(3):将微博文本消息与用户词典中的关键词进行模糊匹配,对关键词词频进行统计:
步骤(31):根据微博发布的时间点来划分微博片段,同时将用户词典中待匹配的关键词分解为单个字;
步骤(32):判断关键词当中的每一个字是否均在微博片段的文本消息中出现一次,若是,则关键词词频加一;若不是则关键词词频不变;对所有微博片段进行分析,找出用户词典中的各个关键词在每个月份的词频。
统计每个月份含有各个关键词的频数,以csv文件格式进行保存;词频统计csv文件的第一列是关键词,第一行是含有该关键词的月份。
根据各个关键词在每个月份的词频,判断被研究人员的待研究心理品质。
若某个微博片段中含有多个关键词,则该微博片段的内容会同时与不同关键词进行模糊匹配。
由于微博文本中的程度级别词语和否定词会影响到关键词的模糊匹配,将程度级别词语设置不同的权重;没有出现程度级别词语的权值记为1;否定词权重奇数次出现记为-1,偶数次出现记为1;每个关键词的词频=程度级别词语权值*否定词权重+名词词频。
所述步骤(1)中进行数据信息初步的提取是指采用文本遍历和文本过滤的方法过滤掉无用的信息,保留有用的信息,将有用的信息另存为txt文件。
所述无用的信息包括:网络连接或表情符号;
所述有用的信息包括:用户创建微博的时间、省份、微博内容以及用户性别。
将程度词分为四个等级并赋予相应权重(2,1.75,1.5,0.5)。
所述步骤(2)的步骤为:
步骤(21):确定待研究心理品质的维度;待研究心理品质指的是使用者的所研究的心理主题,待研究心理品质包括:生涯适应力或大五人格;
步骤(22):从微博排名前设定个数的用户的原创微博的微博文本内容中抽取符合待研究心理品质的词汇;抽取的词汇必须包括名词和趋势词;所述趋势词是指能表述事物发展动向的词,对抽取的词汇进行汇总整理,删除重复词汇,对含同义词或近义词进行合并处理;
步骤(23):问卷编制:问卷包括若干个题目,每个题目包括五个选项;每个题目对应一个待研究的心理品质维度;将合并处理的词作为题目,一个词汇对应一个题目,随机抽取人群作为被试人员,问卷采用Likert 5点计分,从非常同意"、"同意"、"不一定"、"不同意"到"非常不同意"五种选项,分别记为5、4、3、2、1分;被试人员对某个题目的选项越集中,说明该题目对应的词汇越具有代表性。按照集中程度来进行问卷题目的删除:计算问卷中每个题目中各个选项的百分比,参考一致性系数的数值标准,保留单个选项百分比大于等于60%和两个选项百分比之和大于等于60%或且相邻三个选项中两两相邻选项百分比不能同时大于等于60%的词汇;
步骤(24):形成用户词典;按照步骤(23)的按照集中程度来进行问卷题目的删除方法,删除被试人员难以达成一致的词汇,保留被试人员能达成一致的词汇,构成了最终的待研究心理品质的用户词典,保留被试人员能达成一致的词汇就是用户词典的关键词;所述用户词典的关键词个数人为设定。
例如:对于研究消费者信心指数来说,我们寻找工薪阶层,具有一定的购买力,请被试人员评价这些词汇在多大程度上符合他对当前(或未来一年)相关经济状况的看法。
一种基于用户词典的网络社交文本大数据处理系统,包括:
网络社交文本大数据的获取单元:在新浪微博开放平台上获取新浪微博用户的微博文本,由于微博文本数据存储空间大以及为了保证大数据的获取速度,从网上下载了文本压缩文件;然后对文本压缩文件解压缩处理得到包含微博数据的txt文件,对包含微博数据的txt文件进行数据信息初步的提取;
用户词典的构建单元,用于从微博数据中筛选符合待研究心里品质的词汇,对该词汇进行预处理,根据预处理后的词汇编制调查问卷,根据调查问卷的问卷题目筛选结果,构建用户词典;
微博文本消息中的关键词模糊匹配,关键词词频统计单元:
根据微博发布的时间点来划分微博片段,将用户词典中待匹配的关键词分解为单个字,
判断关键词当中的每一个字是否均在微博片段的文本消息中出现一次,若是,则关键词词频加一;若不是则关键词词频不变;
对所有微博片段进行分析,找出用户词典中的各个关键词在每个月份的词频。
本发明的有益效果为:
1、将半结构化的数据转化为结构化的数据,具体的来说是二维的数据结构,转换数据结构之后更加地便于对数据进行分析;
2、基于大数据来对数据的总体进行分析,全面进行描述真实的数据,克服了传统数据分析的一些弊端,例如:用样本估计总体,难以描述客观的世界,处理的误差小于传统数据等。
3、微博数据可以实时地被获取到,经过此种处理的方法速度快,经过处理过后得到的数据具有时效性;
4、大数据处理过程简洁,一台计算机就可以处理,无需构建计算机集群。
附图说明
图1是用户词典构建的过程;
图2是程序处理的过程。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1-2所示,整个数据处理的过程主要分为用户词典构建,否定词的获取,程度级别词语的获取,程序处理。
为了保证所选词汇具有代表性,选取相关研究心理品质领域的热门微博排名前50位博主与前10位媒体的所有原创微博(剔除转发以及图片、视频、音频等),从这些微博信息中筛选符合相关研究心理品质的词汇。
必须和相关研究心理品质的词汇,或者属于某个心理品质维度的词汇。例如,基于消费者信心指数的理论维度,筛选的词汇必须与经济有关,并且属于或类属于消费者满意指数与消费者预期指数以及满意指数的七个维度;要求筛选的词汇是实质词和趋势词的组合(例如:股票上涨)。满意指数的七个维度包括:经济形势、利率、物价、消费、就业、收入、生活质量水平。
在Excel表格内汇总筛选出的全部词汇→删除重复词汇→为保证词汇的普适性和代表性,根据各个词汇在微博的搜索量,删除搜索频次在1000以下的词汇→通过小组评定、专家评定等方式(按照少数服从多数的原则)合并意义相近或相似的词汇(如股票上涨,股价上涨)。
将汇总的词汇分到若干个所研究的心理品质维度中,随机抽取符合研究人群作为被试若干名(视情况而定),请被试评价这些词汇在多大程度上符合他对当前(或未来一年)相关经济状况的看法。问卷采用Likert 5点计分,从“1-完全不符合”到“5-完全符合”。
与传统问卷不同,用户词典问卷旨在考察我们删选出的目标词的有效性。例如,每个选项代表的是被试对该目标词能否代表现在或未来经济形势的看法。因此,被试对某个目标词的选项越集中,说明他们对这个目标词的看法越接近,即这个目标词越具有代表性。计算每个词汇各个选项的百分比,参考一致性系数的数值标准(>0.6),保留单个选项百分比大于等于60%和相邻两个选项百分比之和大于等于60%且相邻三个选项中两两相邻选项百分比不能同时大于等于60%的词汇。按照集中程度来进行删除问卷题目。
按照以上删题标准,共删除被试难以达成一致的词汇,保留被试较能达成一致的词汇,构成了最终的相关研究心理品质的用户词典。
文本消息中的关键词模糊匹配包括:基于程序出现目标词的每一个字,则次数算一次。例:“利率终于下降了”则算“利率下降”关键词出现一次。对所有微博片段进行分析,找出每个月份含有各个关键词的微博片段,若某个片段中含有多个关键词词,则这条微博内容会同时保留在不同关键词相应的文件中。统计每个月份含有各个关键词的频数,以csv文件格式进行保存。
在Excel表格内汇总筛选出的全部词汇、删除重复词汇,为保证词汇的普适性和代表性,根据各个词汇在新浪微博的搜索量,删除搜索频次在1000以下的词汇→通过小组评定、专家评定等方式(按照少数服从多数的原则)合并意义相近或相似的词汇。
获得新浪微博用户2009年8月-2012年9月的微博文本。共包括10个文件夹,每个文件夹包括多个压缩包,压缩包以weibo_datas_XX_XX.rar命名。每个压缩包解压缩之后可以找到名为“SinaNormalRobot”的文件夹,内含“Status”文件夹,打开“Status”即可看到多个.txt格式的文本文件,每个文本文件均包括多条微博内容及其相关信息。共计207个压缩包,总文件大小约580G。在分析之初,利用Python编程调用电脑的WinRar解压缩软件对文件进行自动解压,因此,要求电脑里安装了WinRar解压缩软件,并将winrar.exe的路径添加至系统环境变量PATH中。
首先利用Python编程对微博文本进行批处理,遍历所有文本,过滤文本中的无用信息,保留用户的基本信息、发表时间和微博正文等有用信息,将过滤后的信息保存为txt文件,微博原始数据形式及过滤后的微博数据形式。之后的频数分析均在过滤后的微博文本基础上进行。
微博消息最多只有140字的短文本信息,由于一条微博可能含有多个文本片段,每个片段中都有可能包括一个或多个关键词词,以“,”、“。”、“!”、“?”、“;”等标点符号作为微博片段分割的依据,利用Python编程将每条过滤后的微博文本分割为n个片段S1、S2、S3……Sn,在存储微博文本片段时采用一个一行的方式。
在分割后的每个微博片段中,若同时出现目标词的每一个字,则次数算一次。例:“房子价格上涨的真厉害”,同时出现关键词中的每一个字“房”、“价”、“上”和“涨”;则算“房价上涨”目标词出现一次。对所有微博片段进行分析,找出每个月份含有各个目标词的微博片段,若某个片段中含有多个目标词,则这条微博内容会同时保留在不同目标词相应的文件中。统计每个月份含有各个目标词的频数,以csv格式进行保存。关键词包括名词和趋势动词。
知网(HowNet,www.keenage.com)在其官网发布了“情感分析用词语集(beta版)”,共有12个文件。其中“中文情感分析用词语集”与“英文情感分析用词语集”各为6个,一共包含词语17887个。采用知网情感词典中的“中文程度级别词语”,共219词。根据“中文程度级别词语”已有的情感强弱标注,将“极其|extreme/最|most”与“超|over”合并为“极量”;“很|very”为“高量”;“较|more”为“中量”;“稍|-ish”与“欠|insufficiently”合并为“低量”,并分别赋予这四个等级相应的权值(2,1.75,1.5,0.5)(见表1)。参考多篇文献使用的否定词情况,单独构建了一个否定词词库(见表2),共包括49个词汇,并将权重设置为-1,程度级别词语库仍采用上面介绍的219个词汇。
表1程度级别词语词库
表2否定词词库
实际应用中,含有目标词的微博片段存在两种情况,即可能包含程度级别词语,也可能没有包含程度级别词语。若某条微博片段中没有搜索到程度级别词语,则该微博片段仍记为1。若搜索到某个程度级别词语,则记为该程度级别词语的相应权重(如:在某条微博片段中搜索到一个“最”,则该微博片段记为2;搜索到一个“最”,一个“不过”,则该微博片段记为3.75)。最后把所有微博片段的值相加,得到一个数,这个数就是某个目标词在某个月份上的频数。
每个用户的词频=程度级别词语权值*否定词权重,词频为微博用户在该月发布的内容出现关键词的累加。
Python程序分为两个部分,第一部分进行模糊匹配统计出每个月的用户微博内容中出现的关键词频数,其核心是采用遍历的方法处理数据,其中包括遍历文件夹与文件,遍历文本,遍历字符串,以达到匹配、处理数据的目的。第二部分基于第一部分执行完之后再进行执行,依旧进行遍历的算法来进行加权,加权后生成三种不同文件名的csv,分别为无权重无权值、有权重无权值、有权重有权值。最后在将三种文件的数据进行不同算法的处理,整合到总的数据处理结果的csv文件中。用户词典、程度级别词语词库与否定词词库都存储在txt文件中,格式为一行一个,便于python程序读取并保存在列表中。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法
- 利用媒体提示来识别和关联用户设备的系统、方法和介质的制作方法
- 基于用户的媒体内容分节系统和方法
- 对公司社交网络的用户接收的消息进行分类的方法