一种海量DNA数据的传输方法及系统与流程
本发明涉及生物信息学数据压缩传输领域,更具体地,涉及一种海量dna数据的传输方法及系统。
背景技术:
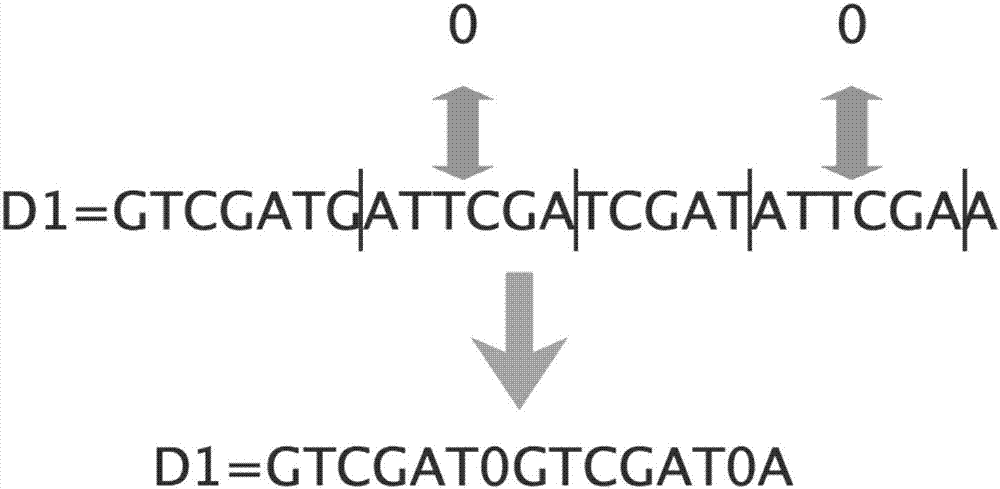
:目前实施的千人基因组计划、国际单体型图计划和孟德尔遗传疾病计划等项目,利用下一代测序技术产生了海量的dna测序数据,使得生物信息学数据呈现爆炸性增长。这些数据含有人类目前尚未了解的生物学知识,通过对这些数据的分析与处理,揭示其生物学内涵,提取出对人类有用的信息,可以给生物学和医学领域的相关研究带来更大的辅助。但是,在促进生物学和医学发展的同时,不同研究所之间传递数据的成本也高的惊人。如何压缩传输量,较少传输成本成为了当下急需解决的问题。生物遗传物质的自我复制操作致使在同一个体的dna序列中存在着大量完全重复的片段,另外还存在特殊的镜像重复、反转重复、互补回文结构等重复片段。人类的不同个体基因的相似程度达99%,而和近亲物种间基因序列的近似程度也可高达98%,植物dna序列中重复序列含量可达80%以上。因此,dna序列不仅数据量大且含有很多的冗余信息,这些数据冗余是dna压缩传输的基础。后缀数组是一种为文本索引设计的数据结构,该结构由记录了字符串的各个后缀的字典序索引的数组构成。利用后缀数组可以快速查找字符串中的最长重复子串。本发明利用后缀数组的这种用途,通过对生物基因序列查找最长重复子串,将查到的最长重复子串生成字典索引,删减重复子串再查找最长重复子串,不断循环该过程。从而实现了对dna序列的编码压缩过程。技术实现要素:本发明为解决以上现有技术在传输dna数据时传输数据量过大导致传输成本高昂的缺陷,提供了一种海量dna数据的传输方法,该方法通过对dna数据进行压缩从而达到降低传输数据量的目的。为实现以上发明目的,采用的技术方案是:一种海量dna数据的传输方法,利用发送客户端、去重服务器和接收客户端进行数据的传输,传输方法具体包括以下步骤:s1.在发送客户端,读入第一条dna序列d1;s2.求取dna序列d1的后缀数组sa,使用sa[m]记录第m位后缀对应的首字母位置,即suffix[sa[m]]在所有后缀中是第m小的后缀;s3.扫描后缀数组sa,通过比较相邻后缀来找出最长的重复字符串str[k];s4.在去重服务器上构建数组a,将str[k]存入数组a的第t个存储单元a[t]中,t表示存储单元的下标,其初始值为1;s5.使用t替换掉dna序列d1中出现的所有重复字符串str[k],dna序列d1经过替换后形成新的序列d[1];s6.令t=t+1,然后对d[1]重复执行步骤s2~s5直至d[1]中剩余的碱基小于e个或最长重复子串小于f个,此时在d[1]中剩余的碱基段的开头和结尾分别插入分隔符;s7.对其余的dna序列依次执行步骤s8~s9的处理:s8.读入一条dna序列di,对其执行步骤s2~s3的操作,求取到该dna序列最长的重复字符串str[h],然后扫描数组a,判断数组a中是否存储有与str[h]匹配的匹配项,若是则使用匹配项所在的存储单元的下标g替换dna序列中出现的所有重复字符串str[h],dna序列di经过替换后形成新的序列d[i];否则令t=t+1,然后将重复字符串str[h]存入数组a的第t个存储单元a[t]中;并使用t替换掉dna序列di中出现的所有重复字符串str[h],dna序列di经过替换后形成新的序列d[i];s9.对d[i]重复执行步骤s8直至d[i]中剩余的碱基小于e个或最长重复子串小于f个,此时在d[i]中剩余的碱基段的开头和结尾分别插入分隔符;s10.通过步骤s1~s9的处理完成对dna数据的压缩,将经过压缩的dna数据和数组a发送到接收客户端;s11.接收客户端读入dna序列,然后利用数组a中存储单元t存储的重复字符串替换相邻两个分隔符之间的数字t,然后将分隔符删除,此时完成dna序列的解压;s12.传输完成。上述方案中,本发明提供的方法借助后缀数组求取dna序列的最长重复子串,然后将最长重复子串存入数组中,并用数组下标替换dna序列中的最长重复子串,通过不断的替换最长重复子串而达到压缩传输数据量的目的。优选地,所述步骤s3通过比较相邻后缀来找出最长重复字符串str[k]的具体过程如下:(1)比较相邻后缀找出其中的重复子串,若重复子串在相邻后缀对应的其中一条字符串中出现两次以上,则将其长度记为len,否则len为0;(2)比较找出的所有的重复子串的len值,取最大的len值对应的重复子串s[i]为最长的重复字符串str[k]。优选地,所述e为8,f为4。优选地,所述分隔符为#号。同时,本发明还提供了一种应用以上方法的系统,其具体的方案如下:包括发送客户端、去重服务器和接收客户端。与现有技术相比,本发明的有益效果是:本发明提供的方法借助后缀数组求取dna序列的最长重复子串,然后将最长重复子串存入数组中,并用数组下标替换dna序列中的最长重复子串,通过不断的替换最长重复子串而达到压缩传输数据量的目的。附图说明图1为删除最长的重复字符串str[k]的示意图。图2为新的序列d1的示意图。图3为插入分隔符的示意图。图4为解压缩的示意图。图5为方法的流程示意图。图6为传输的示意图。具体实施方式附图仅用于示例性说明,不能理解为对本专利的限制;以下结合附图和实施例对本发明做进一步的阐述。实施例1如图5、6所示,本发明提供的方法具体包括以下步骤:第一步:发送客户端读入第一条dna序列d1:ctcgatgattcgatcgatattcgaa。第二步、求取dna序列d1的后缀数组sa,使用sa[m]记录第m位后缀对应的首字母位置,即suffix[sa[m]]在所有后缀中是第m小的后缀。sa={24,23,16,12,4,18,7,21,14,10,2,22,15,11,3,6,0,17,20,13,9,1,5,19,8}。第三步、扫描后缀数组sa,通过比较相邻后缀来找出最长的重复字符串str[k]:(1)比较相邻后缀找出其中的重复子串,若重复子串在相邻后缀对应的其中一条字符串中出现两次以上,则将其长度记为len,否则len为0;比如:s[0]=a,len[0]=1;s[5]=attcga,len[5]=6;s[0]、s[5]表示重复子串。(2)比较找出的所有的重复子串的len值,取最大的len值对应的重复子串s[i]为最长的重复字符串str[k]。本实施例中,找到的最长的重复字符串str[k]为attcga。第四步、在去重服务器上构建数组a,将str[k]存入数组a的第t个存储单元a[t]中。如下表所述:a[0]……a[n]a[63]attcga其中t表示存储单元的下标,其初始值为1,使用t替换掉dna序列d1中出现的所有重复字符串str[k],dna序列d1经过替换后形成新的序列d1。如图1、2所示。第五步、令t=t+1,然后对d1重复执行步骤s2~s5直至d1中剩余的碱基小于e个或最长重复子串小于f个,此时在d1中剩余的碱基段的开头和结尾分别插入分隔符。如图3所示。第六步、对其余的dna序列依次执行第八步、第九步的处理:第八步、读入一条dna序列di,对其执行步骤s2~s3的操作,求取到该dna序列最长的重复字符串str[h],然后扫描数组a,判断数组a中是否存储有与str[h]匹配的匹配项,若是则使用匹配项所在的存储单元的下标g替换dna序列中出现的所有重复字符串str[h],dna序列di经过替换后形成新的序列di;否则令t=t+1,然后将重复字符串str[h]存入数组a的第t个存储单元a[t]中;并使用t替换掉dna序列di中出现的所有重复字符串str[h],dna序列di经过替换后形成新的序列di。第九步、对di重复执行步骤s8直至di中剩余的碱基小于e个或最长重复子串小于f个,此时在di中剩余的碱基段的开头和结尾分别插入分隔符。第十步、通过步骤s1~s9的处理完成对dna数据的压缩,将经过压缩的dna数据和数组a发送到接收客户端;第十一步、接收客户端读入dna序列,然后利用数组a中存储单元t存储的重复字符串替换相邻两个分隔符之间的数字t,然后将分隔符删除,此时完成dna序列的解压;如图4所示。第十二步、传输完成。显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1