一种基于双层粒子群算法的渠系配水优化方法与流程
本发明涉及基于双层粒子群算法的渠系配水优化方法。
背景技术:
渠系优化配水是指在配水渠道及其下级渠道过水能力一定的条件下,为满足灌区农作物某次灌水的要求,采取一定的方法与技术,对配水渠道轮灌组合进行优化。作为水资源优化配置领域一个重要的研究方向,科学合理的渠系优化配水决策可以减少渠系输水过程中的渗水损失和无效弃水,对提高水分利用率和提高粮食产量有着重要的意义。由于地形地势、外界条件的差异和实际情况的复杂性,多数情况下渠道流量并不相等,在此情况下建立渠系优化配水模型,并采用合适、高效的算法对模型进行求解。
针对这种有约束的非线性化,多决策变量的优化问题,新近发展起来的智能优化方法如遗传算法、蚁群算法、模拟退火算法、粒子群算法,为渠系优化配水模型求解提供新的契机。
马孝义、赵文举等在这方面做了大量的研究,算法上也进行了逐步改进。马孝义等(马孝义,刘哲,甘学涛.下级渠道流量不等时渠系优化配水模型与算法研究[j].灌溉排水学报,2006,25(05):17-20.)采用最为经典的和最常用的智能算法中的遗传算法(geneticalgorithm,ga)来解决此类问题,通过遗传算子的选择、交叉、变异操作,作用于整个种群,同时又强调个体的整合,利用遗传算法的并行机制以及全局优化特性,从群体中逐步筛选出最优目标个体,以求得最优结果。赵文举等(赵文举,马孝义,刘哲,甘学涛.基于自适应遗传算法的渠系优化配水模型研究[j].系统仿真学报,2007,19(22):5137-5140.)则采用自适应遗传算法,能在进化过程中按个体的优劣和群体分散程度自动调整遗传控制参数,可显著加快收敛速度和提高计算稳定性。同时赵文举等[3](赵文举,马孝义,张建兴,朱亚磊.基于模拟退火遗传算法的渠系配水优化编组模型研究[j].水力发电学报,2009,28(05):210-214,113.)又采用模拟退火遗传算法的混合算法,遗传算法虽有鲁棒性和全局搜索性能较强等特点,但其搜索速度慢,容易出现早熟等问题,模拟退火算法具有摆脱局部最优的能力等优点,所以将两种算法融合,针对固定惩罚函数遗传算法的模型求解方法中存在量纲难统一、搜索精度不高和过早收敛到局部最优解的问题,引入动态罚函数来约束条件,提出模拟退火算法求解模型。
此三类基于遗传算法以及混合遗传算法求解渠系优化配水模型,包括以下主要步骤:
1建立渠系优化配水模型与约束条件;
2编码设计;
3适应度函数设计以及约束条件的处理方法;
4通过遗传操作选择交叉与变异算子,增加种群多样性,同时保留精英群体,淘汰部分落后群体;
5达到循环停止条件,输出最优解决方案。
采用遗传算法、自适应遗传算法、模拟退火遗传算法求解下级渠系流量不等时的渠系优化配水模型,虽有鲁棒性强和全局搜索性能较强的优点以及混合其他算法等优点,仍然存在一些不足与缺点。
①遗传算法设计复杂,当涉及到大量个体的时候,需要较长的计算时间;
②遗传算法在解群规模、选择方式、收敛数据、杂交变异方式等控制参数均需经验确定,有可能出现早熟收敛、使得它不一定总是获得全局最优解;
③因为算法属于随机算法,需要多次运算,不能稳定的得到解;
技术实现要素:
本发明的目的是为了解决现有下级渠系流量不等时的渠系优化配水模型中遗传算法设计复杂,当涉及到大量个体的时候,需要较长的计算时间;遗传算法在解群规模、选择方式、收敛数据、杂交变异方式等控制参数均需经验确定,有可能出现早熟收敛、使得它不一定总是获得全局最优解;需要多次运算,不能稳定的得到解的问题,而提出一种基于双层粒子群算法的渠系配水优化方法。
一种基于双层粒子群算法的渠系配水优化方法具体过程为:
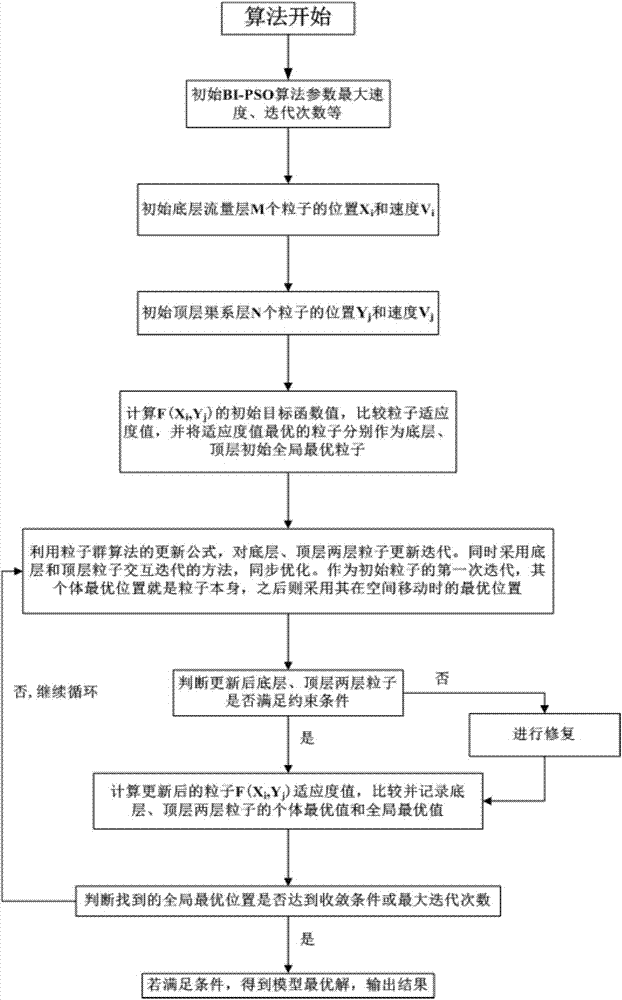
步骤一、初始化bi-pso算法的参数,随机产生满足底层约束条件的初始解粒子的位置xi和速度vi的模型,满足顶层约束条件的初始解粒子的位置yj和速度vj的模型;具体过程为:
bi-pso算法为双层粒子群算法;
双层粒子群算法由2层结构组成,分别称为顶层和底层,顶层为渠系层,底层为流量层;
bi-pso算法的参数包括渠系层粒子规模m1、流量层粒子规模m2、渠系层粒子速度范围[-r1,r1]、流量层粒子速度范围[-r2,r2]、渠系层的斗口个数n、迭代次数n1、学习因子c1和学习因子c2;
所述m1、m2、n、n1为正整数;r1、r2为实数;c1、c2为非负数;
对粒子采用向量的编码方法,渠系层的粒子particle1=(bmk,bmk,...,bmk,...bmk)、流量层的粒子particle2=(cdk,cdk,...,cdk,...cdk),
bm为斗口,cd为渠道流量,k=1,...,n,1—n为正整数但不能重复;
底层流量层约束条件为:任一下级渠道的实配水流量应在其设计流量的0.6~1.0倍;下级渠道的设计流量和下级渠道的实配水流量分别为qj、qj*
0.6qj≤qj*≤1.0qj(1)
流量层每个粒子的每一维度都应满足此约束条件;
顶层渠系层的约束条件为:顶层粒子的每一维度的范围为1~n,且不能重复,n为正整数代表斗口个数;
顶层=下级渠道的斗渠编号;底层=下级渠道的斗渠配水流量;
步骤二、计算f(xi,yj)的初始目标适应度函数值,作为初始粒子的第一次迭代,个体最优位置即为粒子本身,比较粒子的适应度值,将最优适应度值对应每一层的粒子分别作为底层、顶层初始全局最优位置粒子;
步骤三、采用底层和顶层交互迭代,同步优化的方法,进行初始解粒子的速度与位置的更新;
步骤四、判断更新后底层和顶层两层粒子是否满足约束条件,如不满足对其进行修复,如满足,则执行步骤五;
步骤五、计算更新后每组粒子的适应度值,与步骤二中的个体最优位置和每一层全局最优位置粒子的适应度值相比,如果更新后每组粒子的适应度值大于步骤二中的每一层全局最优位置粒子的适应度值,则用更新后的每组粒子对应替换步骤二中的每一层内的全局最优粒子的位置和其个体最优位置,若更新后每组粒子的适应度值只大于步骤二中的个体最优适应度值,则用更新后的每组粒子只对应替换步骤二中的其个体最优位置,若每组粒子其适应度值不大于其个体最优适应度值,则不进行替换,将更新后的每组粒子作为全局最优解,执行步骤六;
每一组粒子包括一个xi和一个yj;
步骤六、判断找到的全局最优解是否达到收敛条件或最大迭代次数,如果达到收敛条件或最大迭代次数,则已得到了双层粒子群优化算法的的最优解,输出结果,如果没达到收敛条件或最大迭代次数,则转到步骤三;
所述收敛条件为:前后两次适应度值差小于10-4;输出的结果为:下级渠道轮灌组的划分和下级渠道的实际流量。
本发明的有益效果为:
本发明提出的bi-pso算法,将渠系层和流量层分开,解决了下级渠系流量不等时渠系优化配水模型中遗传算法设计复杂,当涉及到大量个体的时候,需要较长计算时间的问题,采用向量的方式对粒子进行编码,符合思维习惯,从而使算法设计变得简单,不需考虑遗传算法在解群规模、选择方式、收敛数据、杂交变异方式等的控制参数,即可获得全局最优解,计算效率提高,求解速度快,减弱了由于地形、作物种植结构、外界条件的不同与变化,对渠道优化配水的影响,减少了配水时间,不需多次运算,即可得到稳定的解。
结合表1、表2、表3所示结果可得出本发明一种基于双层粒子群算法的渠系配水优化方法对下级渠道轮灌组的划分精确,每组轮灌组合引水持续时间均为113.4h,设计流量为0.3m3·s-1,优化配水流量为0.223m3·s-1-0.233m3·s-1之间,优化配水流量与设计流量的百分比满足约束条件。
附图说明
图1为本发明双层粒子群算法模块图;
图2为本发明双层粒子群算法流程图。
具体实施方式
具体实施方式一:结合图1、图2说明本实施方式,本实施方式的一种基于双层粒子群算法的渠系配水优化方法的具体过程为:
步骤一、初始化bi-pso算法的参数,随机产生满足底层约束条件的初始解粒子的位置xi和速度vi的模型,满足顶层约束条件的初始解粒子的位置yj和速度vj的模型;具体过程为:
bi-pso算法为双层粒子群算法;
双层粒子群算法由2层结构组成,分别称为顶层和底层,顶层为渠系层,底层为流量层;
bi-pso算法的参数包括渠系层粒子规模m1、流量层粒子规模m2、渠系层粒子速度范围[-r1,r1]、流量层粒子速度范围[-r2,r2]、渠系层的斗口个数n、迭代次数n1、学习因子c1和学习因子c2;
渠系层有多少个斗口,就有多少个斗渠;
所述m1、m2、n、n1为正整数;r1、r2为实数;c1、c2为非负数;
如表1所示为双层粒子群算法的其中一组参数的例子。
表1双层粒子群算法的参数设置
粒子的编码
针对渠系优化配水模型的特点,用向量对粒子进行编码,对函数优化问题或有约束的优化问题是有效的,即把每层粒子编码成n维向量。
对粒子采用向量的编码方法(blockmouth=bm=斗口、canaldischarge=cd=渠道流量),渠系层的粒子particle1=(bmk,bmk,...,bmk,...bmk)、流量层的粒子particle2=(cdk,cdk,...,cdk,...cdk)(k=1,...,n,1-n为正整数但不能重复),
例如particle1=(6,3,16,11,7,17,14,8,5,19,15,1,2,4,18,13,9,20,10,12)为一个粒子。对应(第一维度代表斗口6,第二维度代表斗口3,第三维度代表斗口16,第四个维度代表斗口11,第五个维度代表斗口7,第六个维度代表斗口17,第七个维度代表斗口14,第八个维度代表斗口8,第九个维度代表斗口5,第十个维度代表斗口19,第十一个维度代表斗口15,第十二个维度代表斗口1,第十三个维度代表斗口2,第十四个维度代表斗口4,第十五个维度代表斗口18,第十六个维度代表斗口13,第十七个维度代表斗口9,第十八个维度代表斗口20,第十九个维度代表斗口10,第二十个维度代表斗口12)、
particle2=(cd1,cd2,cd3,cd4,cd5,cd6,cd7,cd8,cd9,cd10,cd11,cd12,cd13,cd14,cd15,cd16,cd17,cd18,cd19,cd20)。对应(第1个维度代表斗口1的实际流量,第2个维度代表斗口2的实际流量,第3个维度代表斗口3的实际维度,第4个维度代表斗口4的实际流量,第5个维度代表斗口5的实际流量,第6个维度代表斗口6的实际流量,第7个维度代表斗口7的实际流量,第8个维度代表斗口8的实际流量,第9个维度代表斗口9的实际流量,第10个维度代表斗口10的实际流量,第11个维度代表斗口11的实际流量,第12个维度代表斗口12的实际流量,第13个维度代表斗口13的实际流量,第14个维度代表斗口14的实际流量,第15个维度代表斗口15的实际流量,第16个维度代表斗口16的实际流量,第17个维度代表斗口17的实际流量,第18个维度代表斗口18的实际流量,第19个维度代表斗口19的实际流量,第20个维度代表斗口20的实际流量)的实际流量。
底层流量层约束条件为:任一下级渠道的实配水流量应在其设计流量的0.6~1.0倍;下级渠道的设计流量和下级渠道的实配水流量分别为qj、qj*
0.6qj≤qj*≤1.0qj(1)
流量层每个粒子的每一维度都应满足此约束条件;
底层流量层的约束条件参考文献(马孝义,刘哲,甘学涛.下级渠道流量不等时渠系优化配水模型与算法研究[j].灌溉排水学报,2006,25(05):17-20.);
顶层渠系层的约束条件为:顶层粒子的每一维度的范围为1~n,且不能重复,n为正整数代表斗口个数,
例如n=20,particle1=(6,3,16,11,7,17,14,8,5,19,15,1,2,4,18,13,9,20,10,12)为一个渠系层粒子;
顶层渠系层的约束条件,是因为将渠系斗口编号为正整数,且不能重复,根据这个原因,产生约束条件;
顶层和底层都是在下级渠道分的,跟上级渠道没有关系。这里的两级就是,上下两级渠道的意思,跟分层没有什么关系;
支渠和斗渠,为其中的上下两级渠系,支渠与斗渠相比灌溉面积大,支渠与灌溉水源相连,而斗渠直接深入基层向用水单位配水。这个是灌区部门对渠系的定义。
顶层=下级渠道的斗渠编号;底层=下级渠道的斗渠配水流量;
步骤一是建立模型;步骤二-六是模型的求解方法;
步骤二、计算f(xi,yj)的初始目标适应度函数值,作为初始粒子的第一次迭代,个体最优位置即为粒子本身,比较粒子的适应度值,将最优适应度值对应每一层的粒子分别作为底层、顶层初始全局最优位置粒子;
步骤三、采用底层和顶层交互迭代,同步优化的方法,进行初始解粒子的速度与位置的更新;
步骤四、判断更新后底层和顶层两层粒子是否满足约束条件,如不满足对其进行修复,如满足,则执行步骤五;
步骤五、计算更新后每组粒子的适应度值,与步骤二中的个体最优位置和每一层全局最优位置粒子的适应度值相比,如果更新后每组粒子的适应度值大于步骤二中的每一层全局最优位置粒子的适应度值,则用更新后的每组粒子对应替换步骤二中的每一层内的全局最优粒子的位置和其个体最优位置,若更新后每组粒子的适应度值只大于步骤二中的个体最优适应度值,则用更新后的每组粒子只对应替换步骤二中的其个体最优位置,若每组粒子其适应度值不大于其个体最优适应度值,则不进行替换,将更新后的每组粒子作为全局最优解,执行步骤六;
每一组粒子包括一个xi和一个yj;
步骤六、判断找到的全局最优解是否达到收敛条件或最大迭代次数,如果达到收敛条件或最大迭代次数,则已得到了双层粒子群优化算法的的最优解,输出结果,如果没达到收敛条件或最大迭代次数,则转到步骤三;
最大迭代次数为步骤一设定的迭代次数n1最大值;
所述收敛条件为:前后两次适应度值差小于10-4;输出的结果为:下级渠道轮灌组的划分和下级渠道的实际流量。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤二中计算f(xi,yj)的初始目标适应度函数值,作为初始粒子的第一次迭代,个体最优位置即为粒子本身,比较粒子的适应度值,将最优适应度值对应每一层的粒子分别作为底层、顶层初始全局最优位置粒子;具体过程为:
f(xi,yj)的初始目标适应度函数值包括目标函数1和目标函数2,f是适应度函数,适应度函数是由目标函数1和目标函数2共同作用的,适应度函数是目标函数通过权重相加取倒数;
目标函数1:
式中,z为输水损失总量,vsu、vsd分别为轮期内上下两级渠道的输水损失总量(m3);au、mu、vu、lu、aj、mdj、lj、vj为定值,qs*为上级配水渠道的实际流量(m3/s),xi取qj*值,qj*为下级渠道的实配水流量(m3/s);j为下级渠系的第j个斗口;au、mu分别为上级渠道的渠床透水系数和指数,lu为上级渠道输水长度(km);vu为上级渠道输水总量(m3);aj、mdj分别为某下级渠道的渠床透水系数和指数;lj为某下级渠道输水长度(km);vj为某下级配水渠道输水总量(m3);
“轮期”,比如:夏灌三轮配水计划时间为2012年6月17日8时至2012年6月24日8时,轮期为168小时,“轮期”是由灌区的水管所制定的;
顶层和底层都是在下级渠道分的,跟上级渠道没有关系。这里的两级就是,上下两级渠道的意思,跟分层没有什么关系;顶层=下级渠系的斗渠;底层=下级渠道的斗渠配水流量;
由此可以近似认为:在渠道输水总量、输水工作长度、渠床土壤性质及衬砌方式、地下水深及出流条件确定情况下,渠道输水损失水量随渠道流量增大而减小。要想减少渠道输水损失,必须在满足渠道流量安全约束条件下(在渠道设计流量的0.6~1.0倍之间变化),增大上下级渠道的流量,流量越大输水损失就越小;
目标函数2:
以各轮灌组引水持续时间差异最小,使得配水渠道进水闸尽可能在同一时间关闭,以各轮灌组引水持续时间差异△t最小为目标函数2,用式(3)表示:
则轮灌组个数p为:
式中:ti、tk分别为第i、k轮灌组的引水持续时间,单位为h;p为轮灌组个数,p取值为正整数;qs为上级配水渠道的引水设计流量,q平均为下级各出水口设计流量的平均值,ceil[]为向上取整函数;floor[]为向下取整函数;
式中:1≤i≤p;j表示下级渠系的第j个斗口;tj表示开着的斗渠口的配水时间;yj为满足顶层约束条件的初始解粒子的位置;
粒子适应度函数的构造
适应度函数要能反映渠道轮灌优化配水模型中渠道输水损失最小(公式(2))和各轮灌组间引水持续时间差异最小(公式(3))。该多目标问题采用权重系数变化法,
将目标函数1和目标函数2线性加权求和并求其倒数构造出粒子的适应度函数,为了避免z和△t在数量级别上的相差,构造适应度函数即:
式中:particle1为计算的渠系层粒子;particle2为计算的流量层粒子;α为目标函数1与目标函数2的权重系数,α=0.5;采用层次分析法等确定,w=灌水定额*支渠水权面积;水权面积就是支渠的灌溉面积,顶层和底层,都是针对支渠的下级的渠系斗渠说的;顶层=下级渠系的斗渠;底层=下级渠道的斗渠配水流量;
建立好适应度函数之后,将步骤一渠系层与流量层初始解粒子的位置xi、yj代入目标函数1和目标函数2,计算每一组粒子的适应度值,比较每一组粒子的适应度值,取适应度值最大的一组粒子,作为顶层渠系层和底层流量层的初始全局最优粒子;
每一组粒子包括一个xi和一个yj;
这里可以说成,直接将xi、yj,代入适应度函数,因为适应度函数是由目标函数1、2推出来的,这里的xi就是目标函数1里的qj*;yj是作用于目标函数2,例如目标函数2中的ti,
根据适应度函数要大的,因为目标函数是输水损失最小,和轮灌组引水时间差异最小,而适应度函数是目标函数的倒数,所以取大的。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤三中采用底层和顶层交互迭代,同步优化的方法,进行初始解粒子的速度与位置的更新;具体的过程为:
全局最优粒子是指每一层所有粒子中的最优粒子,个体最优粒子是指每个粒子在每一次迭代中,位置是在不断变化的,粒子在变化时的最优粒子,所以说个体最优粒子不优于全局最优粒子;
初始化的粒子,初始粒子还没有经过计算,并不知道个体最优粒子是什么,所以就把本身看成个体最优粒子;
在每一次迭代过程中,渠系层或流量层中的粒子都是通过跟踪2个“极值”来更新自己的位置。一个是粒子本身所找到的最优解,即个体极值;另一个是本层内整体种群目前找到的最优解,称为全局解。粒子在找到上述两个极值后,根据下面公式(6)、(7)的两个公式来更新自己的速度与位置。
假设在底层有n维搜索空间,共m个粒子组成粒子群,其中第i个粒子在n维搜索空间中的初始解粒子的位置是xi,记xi=(xi1,xi2,...xin),xi1为第1个维度的初始解粒子的位置,xi2为第2个维度的初始解粒子的位置,xin为第n个维度的初始解粒子的位置,则每个粒子的位置就是一个潜在的解。将xi带入粒子的适应度函数计算出xi的适应度值,根据适应度值的大小衡量xi的优劣,适应度值越大,xi的位置优劣;第i个粒子的“飞翔”速度是一个n维向量,其初始解粒子的速度记为vi,vi=(vi1,vi2,...vin),vi1为第1个维度的初始解粒子的速度,vi2为第2个维度的初始解粒子的速度,vin为第n个维度的初始解粒子的速度,通过公式6迭代更新,得到更新后粒子的速度与位置;
适应度值大好,说明xi位置越优;
n实际上代表就是下级渠道的斗口个数,但从粒子群算法的角度讲可以说成,搜索空间维度;
是一个含义,n实际上代表就是下级渠道的斗口个数,但从粒子群算法的角度讲可以说成,搜索空间维度。
式中:i=1,2...,m,m为粒子的个数,取值为正整数;n=1,2...,n,c1和c2为学习因子,取非负数;r1和r2为介于[0,1]之间的随机数;vin∈[-vmax,vmax],vmax为常数;若在底层pi为底层第i个粒子迄今为止搜索到的最优位置为pi=(pi1,pi2...pin),相反地若在顶层pi为顶层的第i个粒子迄今为止搜索到的最优位置,pi1为底层或顶层第i个粒子第1个维度迄今为止搜索到的最优位置,pi2为底层或顶层第i个粒子第2个维度迄今为止搜索到的最优位置,pin为底层或顶层第i个粒子第n个维度迄今为止搜索到的最优位置,若在底层pg为底层所有粒子迄今为止搜索到的最优位置为pg=(pg1,pg2...pgn),相反地若在顶层pg为顶层所有粒子迄今为止搜索到的最优位置,pg1为底层或顶层所有粒子第1个维度迄今为止搜索到的最优位置,pg2为底层或顶层所有粒子第2个维度迄今为止搜索到的最优位置,pgn为底层或顶层所有粒子第n个维度迄今为止搜索到的最优位置;
假设在顶层有n维搜索空间,共m个粒子组成粒子群,其中第j个粒子在n维搜索空间中初始解粒子的位置是yj,记yj=(yj1,yj2,...yjn),yj1为在顶层第1个维度的初始解粒子的位置,yj2为在顶层第2个维度的初始解粒子的位置,yjn为在顶层第n个维度的初始解粒子的位置,则每个粒子的位置就是一个潜在的解。将yj带入粒子的适应度函数计算出yj的适应度值,根据适应度值的大小衡量yj的优劣,适应度值越大,yj的位置越优;第j个粒子的“飞翔”速度是一个n维向量,其初始解粒子的速度记为vj,vj=(vj1,vj2,...vjn),vj1为在顶层第1个维度的初始解粒子的速度,vj2为在顶层第2个维度的初始解粒子的速度,vjn为在顶层第n个维度的初始解粒子的速度,通过公式7迭代更新,得到更新后粒子的速度与位置;
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤四中判断更新后底层和顶层两层粒子是否满足约束条件,如不满足对其进行修复,如满足,则执行步骤五;具体过程为:
流量层约束条件为:任一下级渠道的实配水流量应在其设计流量的0.6~1.0倍以内;下级渠道的设计流量和下级渠道的实配水流量分别为qj、qj*
0.6qj≤qj*≤1.0qj(1)
即流量层每个粒子的每一维度都应满足此约束条件;
渠系层的约束条件为:顶层粒子的每一维度的范围为1~n,且不能重复,n为正整数代表斗口个数;
具体过程为:
底层、顶层两层粒子如不满足约束条件,则按一下步骤进行修复:
底层流量层粒子某一向量维度若大于设计流量,则按设计流量来计算,若小于0.6倍设计流量,则按设计流量的0.6倍来计算;
顶层渠系层粒子的每一维度的范围为1~n,且不能重复,n为正整数,代表斗口个数。
其它步骤及参数与具体实施方式一至三之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例一种基于双层粒子群算法的渠系配水优化方法具体是按照以下步骤制备的:
张掖市甘州区盈科灌区盈四支一分支渠其下属有20条斗渠,一分支渠的设计流量qs=0.7m3/s,其下属各斗渠的设计流量qj=0.3m3/s;灌水定额为1200立方米/hm2,支渠水权面积为234公顷。(本数据由“黑河生态水文遥感试验(hiwater)”产生。盖迎春,庄金鑫,徐凤英,等.黑河生态水文遥感试验:黑河流域中游渠道流量测量数据集[ds].甘肃兰州:中国科学院寒区旱区环境与工程研究所,2012.)。同时采用双层粒子群算法对已经构建好且经过实例化的多目标渠系优化配水模型进行解算,双层粒子群算法的详细参数设置如表1所示,计算结果如表2、3所示。
表2研究对象最优轮灌组合
表3优化配水过程时间与流量表
注:配水时段的0时为2012年6月17日8时即配水计划开始时间
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!