一种数据分析方法与流程
本发明涉及数据处理分析领域,具体而言,涉及一种数据分析方法。
背景技术:
大数据(bigdata)一词经常被用以描述和指代信息爆炸时代产生的海量信息。研究大数据的意义在于发现和理解信息内容及信息与信息之间的联系。
目前大部分的互联网公司都会在后台存储有用户的数据信息,成为用户大数据信息,通过分析这些数据信息,获取用户的行为,从而可以推荐用户感兴趣的网页或者商品信息,或者调整网页的页面满足用户的喜好,或者预测用户行为,为其提供更好的服务,这样才会给公司带来更多的用户,才能有利于互联网公司的发展。
互联网公司的竞争日趋激烈,通过合适的分析用户数据对其进行个性化的服务,能有效的保留用户,以防客户流失。目前针对数据分析的算法较多,但大多算法都是在成熟的算法中进行的相应改进,并不适合所有的情景。如何设计一种能提高分析效率,解决有价值的稀少数据的分析算法是亟不可待解决的问题。
技术实现要素:
本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
为此,本发明提供了一种数据分析方法,具体步骤如下:
步骤1,读取数据库中存储的数据集合;
步骤2,采用项目集合概率法进行计算第一门限值s1;
步骤3,根据所述第一门限值s1和项目属性计算第二门限值s2;
步骤4,提取数据库中的数据集合,并计算其中每个项目数据集合特定值,判断所述项目数据集合特定值是否大于等于所述第一门限值s1,若大于等于所述第一门限值s1,则进行步骤5,若判断小于所述第一门限值s1,则进行步骤6;
步骤5,采用预设的第一规则算法计算关联规则;
步骤6,判断所述项目数据集合特定值是否大于等于所述第二门限值s2,若大于等于第二门限值s2,则进行步骤7,所小于所述第二门限值,则进行步骤8;
步骤7,采用预设的第二规则算法计算关联规则;
步骤8,删除小于所述第二门限值的项目数据集合;
重复上述步骤4-8,直至数据库中的所有项目数据集合都处理完毕;
显示计算的关联规则结果。
更具体的,步骤2具体为:
步骤21,遍历数据库,统计每个项目集合在数据库中出现概率;
步骤22,根据用户预设的第一百分比值,找出最接近所述第一百分比值对应的两个项目集合的概率值;
步骤23,计算两个项目集合的概率差值;
步骤24,用户预设的第一百分比值与所述两个项目集合的概率差值相加,结果为第一门限值s1。
更具体的,步骤3具体为:
第二门限值通过以下公式进行计算,
其中β为用户设定的允许降低的范围,q(t)为项目属性,其通过以下公式进行计算,
其中,t为每个项目的利润,b和c为用户预设的值,且b2+c2≠0。
优选的,所述β取值为:10%-50%;所述b和c的取值为:5<b<50,10<c<80。
优选的,所述第一规则算法为apriori算法。
更具体的,步骤7具体为:
步骤71,计算数据库中所有数据集合的相关支持度;
步骤72,对小于第一门限值s1且大于等于第二门限值s2的项目数据集合判断其特定值是否大于等于相关支持度,若大于等于相关支持度,则进行步骤74,若小于相关支持度则进行步骤73;
步骤73,删除小于相关支持度的项目数据集合;
步骤74,重复步骤72-73,直至数据库中的所有小于第一门限值s1且大于等于第二门限值s2的项目数据集合都处理完毕。
更具体的,所述相关支持度的具体计算公式为:
rsup(d1,d2,...,dk)=max(sup(d1,d2,...,dk)/sup(d1),
sup(d1,d2,...,dk)/sup(d2),...,sup(d1,d2,...,dk)/sup(dk))
其中rsup(d1,d2,...,dk)为相关支持度,sup(dk)为数据集d=(d1,d2,...,dk)中的dk的支持度。
本发明通过设计一种新的数据分析方法,改进了门限值的情况,避免在数据分析过程中将某类因素形成的候选集被过高的门限值过滤掉,使分析出的关联规则较趋向于某类因素的弊端,使得整体的分析结果更全面化,更完善,另外通过此分析方法,使得数据的分析更加高效客观。
附图说明
图1示出了根据本发明的一种数据分析方法流程图;
图2示出了计算第一门限值的流程示意图;
图3示出了第二规则算法的流程示意图。
具体实施方式
目前关于关联规则算法有较多的研究,大多数的算法是以apriori算法作为基础,进行改进或者提出新的思路。但算法中需要确定门限值,此时都是由设计者通过自己的经验进行确定,为了改进门限值的情况,避免在数据分析过程中将某类因素形成的候选集被过高的门限值过滤掉,使分析出的关联规则较趋向于某类因素,提出了一种新的数据分析方法,采用了相关联的两个门限值进行分析。
由于目前互联网中的数据具有稀疏性、分布性等特点,有些数据在数据库中的出现频率不满足分析用户给定的最小支持度,但是在它的出现次数中,又以很高的比率与某一特定的数据同时出现,这些数据是有价值的少量数据。由于目前的数据分析方法有门限值的设定,而此门限值是用户根据自身经验设置的,采用此门限值进行分析可能会把某些有价值的少量数据过滤掉,而通过本发明设计的方法则可以避免过滤掉有价值的少量数据,做到分析的全面性和客观性,提高了分析的准确性。
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
设d={d1,d2,...,dm}为数据项集合,db是与任务相关的数据库,t代表一个数据项子集,即
如果在数据库中存在s比例的记录包含a∪b,定义关联规则
定义有价值的少量数据为rdvalue,d∈db,sup(d)<min_sup,其中min_sup为最小支持度,p(d)为d出现概率,如p(d)≈p(u),称d为有价值的少量数据。
由用户指定的用于在分析多数项集合过程中使用的特定值为第一门限值s1,由用户指定的用于分析少量数据项集过程中使用的特定值为第二门限值s2,其中s1>s2。
图1示出了根据本发明的一个实施例的数据分析方法流程图。
如图1所示,根据本发明的一种数据分析方法,包括:步骤1,读取数据库中存储的数据集合;步骤2,采用项目集合概率法进行计算第一门限值s1;步骤3,根据所述第一门限值s1和项目属性计算第二门限值s2;步骤4,提取数据库中的数据集合,并计算其中每个项目数据集合特定值,判断所述项目数据集合特定值是否大于等于所述第一门限值s1,若大于等于所述第一门限值s1,则进行步骤5,若判断小于所述第一门限值s1,则进行步骤6;步骤5,采用预设的第一规则算法计算关联规则;步骤6,判断所述项目数据集合特定值是否大于等于所述第二门限值s2,若大于等于第二门限值s2,则进行步骤7,所小于所述第二门限值,则进行步骤8;步骤7,采用预设的第二规则算法计算关联规则;步骤8,删除小于所述第二门限值的项目数据集合;重复上述步骤4-8,直至数据库中的所有项目数据集合都处理完毕;显示计算的关联规则结果。
其中数据库中存储有各种项目的数据集合,其集合形式由用户进行设定。优选的,数据集合采用list表格形式进行存储,或者采用数组的形式进行存储,其中集合的维度都是由用户预先设置的。
计算数据集合的特定值属于本领域中的常用规则算法,本发明不再一一赘述。
针对步骤2计算第一门限值则通过以下步骤进行。
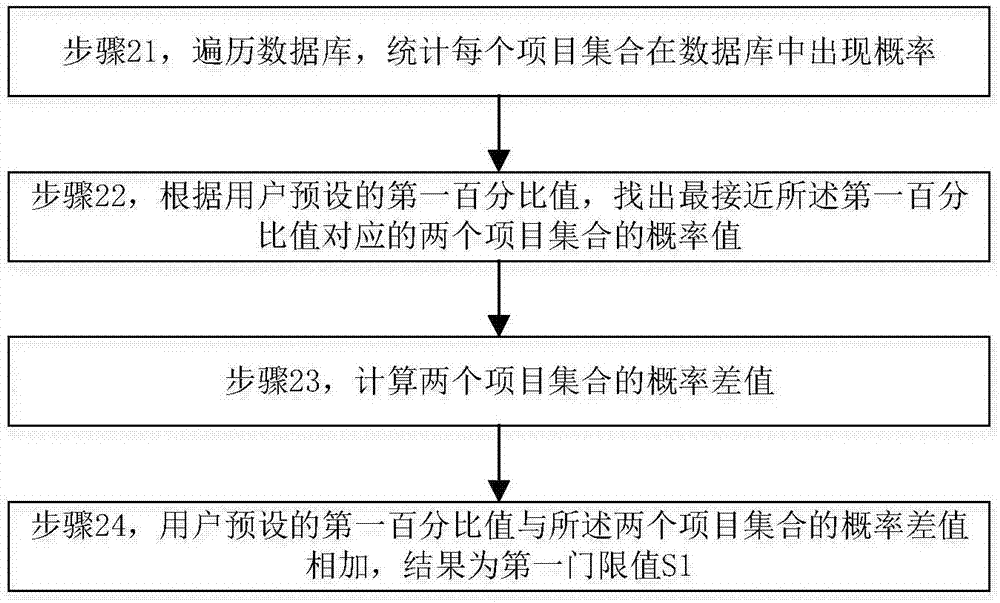
图2示出了计算第一门限值的流程示意图。
如图2所示,第一门限值的计算步骤如下:
步骤21,遍历数据库,统计每个项目集合在数据库中出现概率;
步骤22,根据用户预设的第一百分比值,找出最接近所述第一百分比值对应的两个项目集合的概率值;
步骤23,计算两个项目集合的概率差值;
步骤24,用户预设的第一百分比值与所述两个项目集合的概率差值相加,结果为第一门限值s1。
每个项目集合在数据库中出现的概率采用本领域中常用的做法,由于属于现有技术,则本发明不再赘述。采用此方法计算第一门限值可以提高有价值的稀少数据的影响度,不会因为预先设定的固定门限值而把一些有价值的稀少数据过滤掉,造成对数据分析结果的影响。
例如,用户设定第一百分比值为60%。通过计算得出数据集合中最接近的两个项目集合的概率值为58%和61%。则这两个概率的差值为3%,所以最后得出的第一门限值s1为60%+3%=63%。
针对第二门限值的计算具体为:
第二门限值通过以下公式进行计算,
其中β为用户设定的允许降低的范围,q(t)为项目属性,其通过以下公式进行计算,
其中,t为每个项目的利润,b和c为用户预设的值,且b2+c2≠0。其中s1>s2。
利润高时其权重值较高,计算出的s2将会较低;利润低时其权重值较低,计算出的s2将会较高。被分析出关联规则的机会将较高,也就是将大大提高分析出利润较高的项目的关联规则。
更优的,所述β取值为:10%-50%;所述b和c的取值为:5<b<50,10<c<80。上述b和c的取值是在分析了多数的数据之后取得的经验值,当在此值的情况下,得出的s2值会更符合数据分析的需求,不会因为数值的多大而丢失一些有价值的稀少数据。
所述第一规则算法为apriori算法。
apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。apriori算法属于本领域的常规算法,本发明不再一一赘述。
针对步骤7的第二规则算法通过以下步骤进行。
图3示出了第二规则算法的流程示意图。
如图3所示,第二规则算法的步骤如下:
步骤71,计算数据库中所有数据集合的相关支持度;
步骤72,对小于第一门限值s1且大于等于第二门限值s2的项目数据集合判断其特定值是否大于等于相关支持度,若大于等于相关支持度,则进行步骤74,若小于相关支持度则进行步骤73;
步骤73,删除小于相关支持度的项目数据集合;
步骤74,重复步骤72-73,直至数据库中的所有小于第一门限值s1且大于等于第二门限值s2的项目数据集合都处理完毕。
此算法主要是为分析包含支持度低,但项目利润高的关联规则。
上述的相关支持度的具体计算公式为:
rsup(d1,d2,...,dk)=max(sup(d1,d2,...,dk)/sup(d1),
sup(d1,d2,...,dk)/sup(d2),...,sup(d1,d2,...,dk)/sup(dk))
其中rsup(d1,d2,...,dk)为相关支持度,sup(dk)为数据集合d=(d1,d2,...,dk)中的dk的支持度。其中dk表示项目集合。
数据库预存储n个项目的数据集合,n大于等于2。
通过本发明设计的方法则可以避免过滤掉有价值的少量数据,做到分析的全面性和客观性。利用本方法所分析出的关联规则包含有利润较高的项目,做到了整个分析的客观和全面性。例如,在某购物网站的后台存储器中存储有各种品类商品的集合,其中记录了每个品类商品的利润以及销量等信息,而其中某个品类的利润较大,但由于用户设置了门限值的情况,很可能使得此品类最终被过滤掉,造成了数据分析的不全面;而利用本发明的方法则可以很好的避免因为门限值的设置而导致数据分析的不全面性,更有利于发现数据集合中的关系。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!