一种基于词向量、卷积神经网络的实体消歧方法与流程
本发明属于互联网信息技术领域,具体涉及一种实体消歧方法,特别涉及一种基于词向量、卷积神经网络的实体消歧方法。
背景技术:
随着移动互联网的普及,微博、博客、贴吧、论坛、及各大新闻网站、政府工作网站等极大的方便了人民的生活。这些平台上的数据绝大部分都是以非结构化或半结构化的形式存在,导致这些数据中存在着大量的歧义现象。如果能对这些含有歧义的实体进行准确的消歧,将会为后期利用产生极大的便利。
目前主流的实体消歧算法底层模型多是基于词袋模型,词袋模型固有的局限性,导致这些算法都不能够充分利用上下文的语义信息,导致实体消歧效果还有很大的提升空间。词嵌入是近年来机器学习的热点,词嵌入的核心思想就是为每一个词语构造一个分布式表示,这样避免了词汇与词汇之间的鸿沟。卷积神经网络是神经网络模型的一个分支,可以有效的捕捉局部特征,再全局建模。若能够采用卷积神经网络对词嵌入进行建模,那么能够得到比词袋模型更有效的语义特征。而且基于局部感知和权值共享的思想,卷积神经网络模型中参数大大减少,训练速度较快,谷歌的alphago的核心就是两个卷积神经网络。
本发明将词向量和卷积神经网络结合起来,针对待消歧实体上下文和知识库实体摘要信息,分别构造语义表示,训练卷积神经网络,进行预测。大大提高了实体上下文的语义描述能力。
技术实现要素:
发明目的:本发明针对现有实体消歧方法难以利用上下文的语义信息的现状,提供一种基于词向量、卷积神经网络的实体消歧方法,旨在捕捉上下文语义信息来帮助实体消歧。
技术方案:
一种基于词向量、卷积神经网络的实体消歧方法,包括步骤:
步骤1:根据应用场景收集的包含待消歧实体的文本集,并对文本集进行预处理,确定文本集中每一个待消歧实体及其上下文特征;
步骤2:根据领域知识构建的待消歧实体的知识库,并搜索知识库,确定每一个待消歧实体的候选实体集合及集合中每一个候选实体的描述特征;
步骤3:取以待消歧实体为中心的一个固定大小窗口中的名词的词向量构成一个词向量矩阵,作为待消歧实体的上下文语义特征;取知识库中每一个实体的摘要信息在计算tf·idf后权重比较大的前20个名词的词向量构成词向量矩阵,作为知识库实体的语义特征;
步骤4:将文本中已知的无歧义实体联合知识库目标实体以及候选实体构成训练集合,并输入到卷积神经网络模型进行训练,调整模型中的参数;
步骤5:对每一个待消歧的实体和知识库候选实体集合组成的样本,输入到步骤4得到的卷积神经网络模型,分别得到待消歧实体和知识库候选实体集合中每一个知识库实体的语义特征向量;
步骤6:基于语义特征向量,计算待消歧实体和知识库候选实体集合中每一个实体的余弦相似度;取相似度最大的候选实体即为待消歧实体的最终目标实体。
所述步骤1中的预处理为用中科院中文分词程序ictclas对文本集进行词性标注分词,然后根据停用词表过滤掉停用词,并且针对一些专有名词以及比较难识别的实体名创建一个名字字典。
所述步骤2中调用中文分词程序ictclas对知识库中的实体描述进行词性标注分词,根据停用词表过滤掉停用词。
所述步骤3中以待消歧实体为中心的一个固定大小窗口中的名词的词向量构成一个词向量矩阵具体为:
1)调用谷歌深度学习程序word2vec对中文维基百科语料库进行训练,从而得到词向量表l,其中的词向量的长度是200维,每一维都是一个实数;
2)对待消歧实体e的上下文conetxte={w1,w2,…,wi,…,wk}中每一个名词wi查询词向量表l,得到每一个名词的词向量vi;
3)根据待消歧实体e的上下文词语的词向量,构建待消歧实体e的上下文词向量矩阵[v1,v2,v3,…vi,…,vk];
4)结束。
所述步骤3中取知识库中每一个实体的摘要信息在计算tf·idf后权重比较大的前20个名词的词向量构成词向量矩阵具体为:
1)对候选实体集合e={e1,e2,…,en}中每一个候选实体ei的描述特征中每一个名词wi查询词向量表l,得到每一个名词的词向量vi;
2)根据描述特征中每一个名词的词向量,构建实体描述的词向量矩阵;
3)结束。
所述步骤4卷积神经网络学习训练具体为:
1)每个待消歧的语义特征和候选实体集合的语义特征作为一个训练样本,输入到神经网络模型;
2)对待消歧的语义特征进行卷积,设定卷积核featuremap的个数为200个,设定卷积核featuremap的大小为[2,200],即长为2、宽为200的矩阵;
3)每个卷积核卷积的结果采用1-max池化,得到每个卷积核的特征;
4)200个卷积核特征组成中间结果,再输入到全连接层,全连接层大小为50,最终得到一个50维的语义特征向量;
5)候选实体集合的语义特征,先求加和平均,然后再输入到一个全连接层,大小同样为50,最终得到一个50维的语义特征向量;
6)神经网络中每一个训练样本的损失函数losse定义为:
losse=max(0,1-sim(e,eε)+sim(e,e′))
其中:eε表示待消歧实体e的目标实体,e′表示候选实体集合中的任一其它候选实体,意思是最大化目标实体和任一其它候选实体语义特征向量相似度之差;
整体损失函数定义为:loss=∑losse;
7)神经网络中的参数均采用均匀分布u(-0.01,0.01)初始化;
8)神经网络中的激活函数均采用tanh双曲正切激活函数;
9)神经网络中的参数采用随机梯度下降进行更新;
10)结束。
所述步骤6实体分类阶段具体为:
1)从文件系统中读取待消歧实体e的语义特征向量a;
2)从文件系统中读取候选实体集合e={e1,e2,…,en}中的语义特征向量集合b={b1,b2,…,bn};
3)遍历候选实体集合,计算e和e中每一个特征向量的余弦相似度
4)选取相似度最大的实体
5)结束。
有益效果:本发明基于词向量、卷积神经网络的实体消歧方法分别对待消歧实体和知识库候选实体构造语义表示。利用训练集合训练神经网络模型,在实体消歧时,将待消歧实体输入到训练好的神经网络模型,输出待消歧实体的最相似候选实体作为最终目标实体。
附图说明
为了更清楚地说明本发明,下面将对本发明所需使用的附图作简单的介绍:
图1为本发明的基于词向量、卷积神经网络的实体消歧方法。
图2为卷积神经网络模型的结构图。
图3为实体分类阶段的流程图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明的基于词向量、卷积神经网络的实体消歧方法的流程图如图1所示。
步骤0是本发明的实体消歧方法的起始状态;
在实体识别阶段(步骤1-6):
步骤1是根据应用场景收集包含待消歧实体的文本集;
步骤2是根据领域知识构建的待消歧实体的知识库;
步骤3是调用中科院中文分词程序ictclas对文本集进行词性标注分词,然后根据停用词表过滤掉停用词,并且针对一些专有名词以及比较难识别的实体名创建一个名词字典;
步骤4是调用中文分词程序ictclas对知识库中的实体描述进行词性标注分词,根据停用词表过滤掉停用词;
步骤5是根据应用场景确定每一个关注的待消歧实体及其上下文特征;
步骤6是候选实体的产生,搜索知识库,比较文本中待消歧实体指称项与知识库中实体指称是否相同,若相同,则将这些实体当做是文本中待消歧实体指称项的候选实体,确定每一个待消歧实体的候选实体集合及集合中每一个候选实体的描述特征;
在实体语义表示阶段(步骤7-10):
步骤7是取以待消歧实体为中心的一个固定大小窗口中的名词的词向量构成一个词向量矩阵;(对文本集进行词性标注分词处理后,带有/n标识的词),窗口大小为10;
1)调用谷歌深度学习程序word2vec对中文维基百科语料库进行训练,从而得到词向量表l,其中的词向量的长度是200维,每一维都是一个实数;
2)对待消歧实体e的上下文conetxte={w1,w2,…,wi,…,wk}中每一个名词wi查询词向量表l,得到每一个名词的词向量vi;
3)根据待消歧实体e的上下文词语的词向量,构建待消歧实体e的上下文词向量矩阵[v1,v2,v3,…vi,…,vk];
4)结束。
步骤8是取知识库中每一个实体的摘要信息在计算tf·idf后权重比较大的前20个名词的词向量构成词向量矩阵;若不够20个名词,则取现有的所有名词;
1)对候选实体集合e={e1,e2,…,en}中每一个候选实体ei的描述特征中每一个名词wi查询词向量表l,得到每一个名词的词向量vi;
2)根据描述特征中每一个名词的词向量,构建实体描述的词向量矩阵;
3)结束。
步骤9是将步骤7的词向量矩阵作为待消歧实体的上下文语义特征;
步骤10是将步骤8的词向量矩阵作为知识库实体的语义特征;
在神经网络学习训练阶段(步骤11-12):
步骤11是将文本中已知的无歧义实体联合知识库实体构成训练集合;
步骤12针对步骤11中的训练集合输入到卷积神经网络模型进行训练,调整模型中的参数;
1)每个待消歧的语义表示和候选实体集合的语义特征作为一个训练样本,输入到神经网络模型;
2)对待消歧的语义特征进行卷积,设定卷积核featuremap的个数为200个,设定卷积核featuremap的大小为[2,200],即长为2、宽为200的矩阵;
3)每个卷积核卷积的结果采用1-max池化,得到每个卷积核的特征;
4)200个卷积核特征组成中间结果,再输入到全连接层,全连接层大小为50,最终得到一个50维的语义特征向量;
5)候选实体集合的语义特征,先求加和平均,然后再输入到一个全连接层,大小同样为50,最终得到一个50维的语义特征向量;
6)神经网络中每一个训练样本的损失函数losse定义为:
losse=max(0,1-sim(e,eε)+sim(e,e′))
其中:eε表示待消歧实体e的目标实体,e′表示候选实体集合中的任一其它候选实体,意思是最大化目标实体和任一其它候选实体语义特征向量相似度之差;
整体损失函数定义为:loss=∑losse;
7)神经网络中的参数均采用均匀分布u(-0.01,0.01)初始化;
8)神经网络中的激活函数均采用tanh双曲正切激活函数;
9)神经网络中的参数采用随机梯度下降进行更新;
10)结束。
在实体分类阶段(步骤13-14):
步骤13是读取文本中待消歧实体和知识库候选实体的样本集合;
步骤14遍历步骤13读取的样本集合,将每一个样本输入到步骤12训练得到的卷积神经网络模型,并输出分类结果;
步骤15是本发明的基于词向量、卷积神经网络的实体消歧方法的结束步骤;
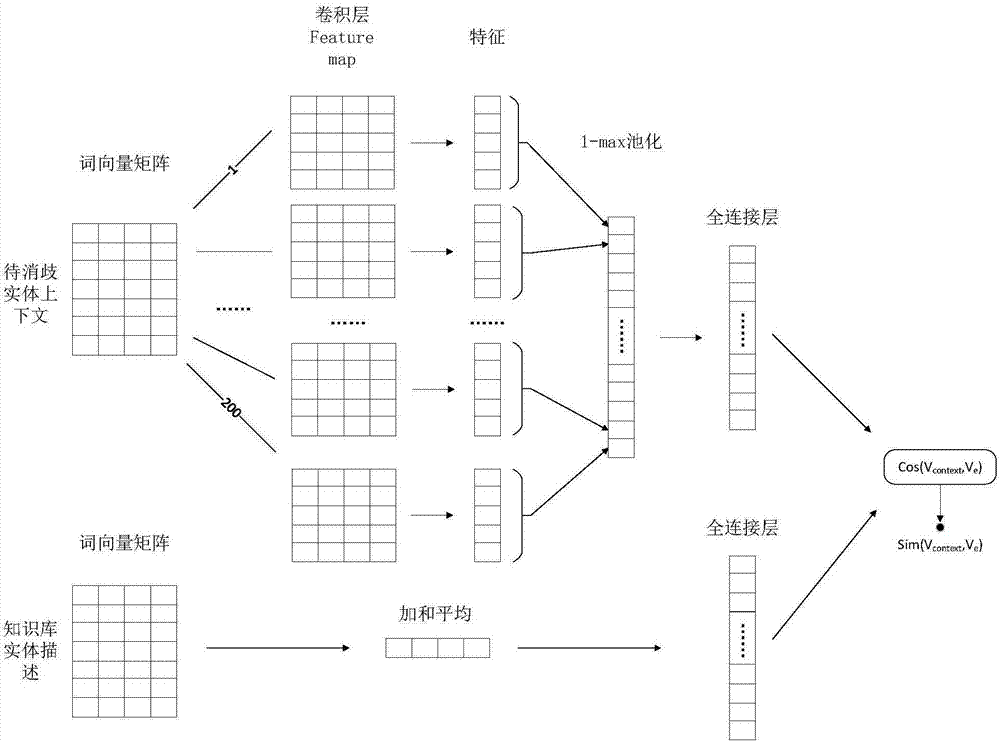
图2是对图1中神经网络学习训练阶段中的步骤12的神经网络结构的详细概括图,包括下面几个组成部分:
词向量矩阵:待消歧实体上下文的词向量矩阵和知识库实体描述特征的词向量矩阵作为卷积神经网络的输入;
卷积层:对待消歧实体上下文词向量矩阵,通过200个不同的卷积核进行卷积,得到每一个卷积核的特征;
1-max池化层:对卷积层输出的特征进行1-max池化,得到一个200维的中间结果;
全连接层:对上述中间结果连接一个大小为50的全连接层,对知识库候选实体的词向量加和平均也连接一个大小为50的全连接层,从而得到两个50维的语义特征向量;
相似度计算:计算两个语义特征向量的余弦相似度;
图3是对图1中实体分类阶段中的步骤14的详细流程描述:
步骤16是图3的起始状态图;
步骤17是读取文件系统中的训练好的神经网络模型;
步骤18是读取文本中待消歧实体和知识库候选实体的样本集合;
步骤19是将样本集合输入到卷积神经网络模型,得到语义特征向量后,遍历知识库候选实体集合,计算待消歧实体和每一个候选实体的语义特征向量的余弦相似度;
步骤20是输出相似度最高的实体作为最终目标实体;
步骤21是图3的结束状态图;
具体:1)从文件系统中读取待消歧实体e的语义特征向量a;
2)从文件系统中读取候选实体集合e={e1,e2,…,en}中的语义特征向量集合b={b1,b2,…,bn};
3)遍历候选实体集合,计算e和e中每一个特征向量的余弦相似度
4)选取相似度最大的实体
5)结束。
综上所述,本发明综合利用词向量、卷积神经网络的方法,分别对待消歧实体上下文和知识库候选实体摘要信息构造词向量矩阵,输入到卷积神经网络模型。训练卷积神经网络模型,调整模型中的参数。在预测阶段,输出最相似的实体作为目标实体。解决了传统的词袋模型中存在词汇鸿沟,从而语义表示能力不足的问题,进一步提高了实体消歧的准确率。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!