课程先后序计算方法和设备与流程
本发明涉及计算机技术,具体涉及课程先后序计算方法和设备。
背景技术:
掌握学习(masterylearning)由本杰明·布卢姆(benjaminbloom)于1968年首先正式提出,表明学生必须在基础知识上达到一定程度的掌握(例如,基础知识的90%),然后才能继续学习后续的知识概念。从此,知识概念之间的先后序关系成为学校和大学设计课程的基石。先后序关系本质上可以看作是知识概念间的依赖。对人们学习、组织、应用和产生知识至关重要。运用概念间先后序关系来组织知识结构可以改进对课程的规划,自动生成阅读列表和提高教育质量等任务。以往,是由老师或助教提供知识概念间的先后序关系。
然而,在大型开放式网络课程(massiveopenonlinecourses)时代,需要面对拥有成千上万种学习背景的学生,由老师或则助教安排课程的学习顺序变得并不可行。同时,大型开放式网络课程的快速发展提供了数千门课程,学生可以自由选择其中的课程来学习,而学生的兴趣各不相同,这也使得由老师或助教安排课程的学习顺序变得不可行。因此,需要从大型课程空间中自动挖掘知识概念之间先后序关系的方法,使来自不同背景的学生可以轻松探索知识空间,更好地设计个性化学习时间表。
技术实现要素:
鉴于上述问题,本发明提出了克服上述问题或者至少部分地解决上述问题的课程先后序计算方法和设备。
为此目的,第一方面,本发明提出一种课程先后序计算方法,其特征在于,包括步骤:
s201、根据辅助语料,获得第一语料中的概念实体的向量表示;
s202、至少计算概念实体对之间的语义关系特征、平均位置距离特征、分布不对称特征和复杂程度距离特征;
s203、至少根据获得的概念实体对之间的语义关系特征、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系;
s204、通过概念实体的先后顺序,获得课程的先后顺序;
或课程先后序计算方法包括步骤:
s101、根据辅助语料,获得第一语料中的概念实体的向量表示;
s102、计算概念实体对之间的复杂程度距离特征;以及计算以下6种特征中的至少5种:语义关系特征、视频引用距离特征、通用句子引用距离特征、辅助文本引用距离、平均位置距离特征、分布不对称特征;
s103、根据获得的概念实体对之间的复杂程度距离特征,以及根据在步骤s102中获得5种特征,采用随机森林方法训练获得概念的先后序关系;
s104、通过概念实体的先后顺序,获得课程的先后顺序。
可选的,对于有序概念实体向量<a,b>之间的复杂程度距离特征通过下述方式计算获得:
cld(a,b)=avc(a)·ast(a)-avc(b)·ast(b);
其中,max(i(c,a))和min(i(c,a))分别指a在课程c中第一次和最后一次出现的视频序号;包含概念实体a的课程为c(a),|c(a)|的值等于第一语料中包含概念实体a的课程的个数,|c|的值等于第一语料中课程的个数,cld(a,b)即复杂程度距离特征。
可选的,对于有序概念实体向量<a,b>之间的语义关系特征通过下述方式计算获得:
其中,va、vb分别为a、b的词向量嵌入表示,ω(a,b)即a和b之间的语义关系特征。
可选的,有序概念实体向量<a,b>之间的视频引用距离特征通过下述方式获得:
vrd(a,b)=vrw(b,a)-vrw(a,b);
其中,d表示输入的第一语料中的所有课程,c表示第一语料中的某一课程,v表示是课程c的某一视频字幕;f(x,v)表示概念实体x在视频v中的频数;r(v,x)表示概念实体x是否出现在视频v中出现,函数值为1,否则为0;vrd(a,b)即视频引用距离特征。
可选的,有序概念实体向量<a,b>之间的通用句子引用距离特征通过下述方法获得:
gsrd(a,b)=gsrw(b,a)-gsrw(a,b);
srd(a,b)=srw(b,a)-srw(a,b);
其中,d表示输入的第一语料中的所有课程,c表示第一语料中的某一课程,v表示是课程c的某一视频字幕,s表示字幕v中的一个句子;r(s,x)∈{0,1}表示概念实体x是否出现在句子s中,出现则r(s,x)的值为1,否则为0;ai∈e1~em,e1~em是在辅助语料上与概念实体a语义关系最为接近的m个实体;m为预设值;va、vb分别为a、b的词向量嵌入表示,gsrd(a,b)即通用句子引用距离特征。
可选的,有序概念实体向量<a,b>之间的辅助文本引用距离通过下述方法获得:
wrd(a,b)=wrw(b,a)-wrw(a,b);
其中va、vb分别为a、b的词向量嵌入表示,erw(e,a)表征辅助语料的文章e是否被ra中任一概念所引用,被引用,值为1,否则为0;ra=<e1,…,em>,e1~em是在辅助语料上与概念实体a语义关系最为接近的m个实体;m为预设值,wrd(a,b)即辅助文本引用距离。
可选的,有序概念实体向量<a,b>之间的平均位置距离特征:
其中,包含概念实体x的课程为c(x),|c(x)|的值等于第一语料中包含概念实体x的课程的个数,|c|的值等于第一语料中课程的个数,|c(a)∩c(b)|即含有共现视频的课程数;对于
可选的,有序概念实体向量<a,b>之间的分布不对称特征;
其中,max(i(c,a))和min(i(c,a))分别指a在课程c中第一次和最后一次出现的视频序号;包含概念实体x的课程为c(x),|c(x)|的值等于第一语料中包含概念实体x的课程的个数,|c(a)∩c(b)|即含有共现视频的课程数;|c|的值等于第一语料中课程的个数,集合s(c)={(i,j)|i∈i(c,a),j∈i(c,b),i<j},对于
第二方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上一所述方法的步骤。
第三方面,本发明提供一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上执行的计算机程序所述处理器执行所述程序时实现如上任一所述方法的步骤。
由上述技术方案可知,在本发明中,在计算课程概念先后序时,将课程结构方面的复杂程度特征与其他特征结合,并通过随机森林方法根据上述特征计算课程概念之间的先后序,提高了课程概念先后序识别的准确性,从而对网络上大型开放网络课程提供了一个有效的先后序确认方法。
前面是提供对本发明一些方面的理解的简要发明内容。这个部分既不是本发明及其各种实施例的详尽表述也不是穷举的表述。它既不用于识别本发明的重要或关键特征也不限定本发明的范围,而是以一种简化形式给出本发明的所选原理,作为对下面给出的更具体的描述的简介。应当理解,单独地或者组合地利用上面阐述或下面具体描述的一个或多个特征,本发明的其它实施例也是可能的。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的一个是实施例中采用的数据集对应的相关统计信息表;
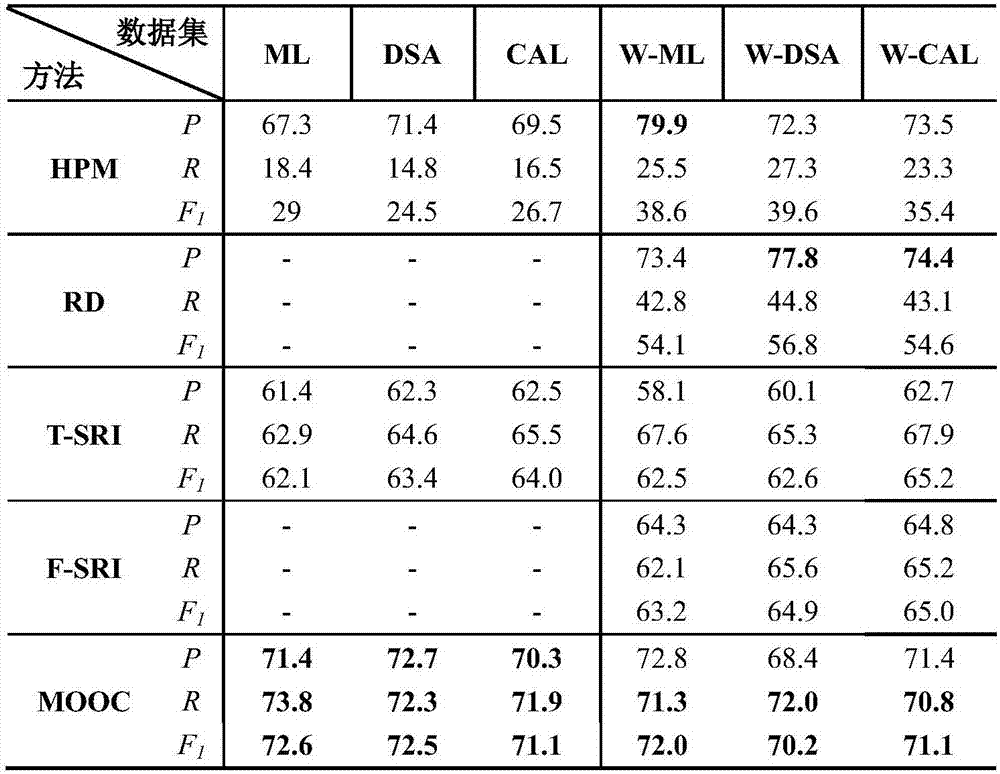
图2为本发明的一个实施例的结果分析表;
图3为本发明的另一个实施例的结果分析表;
图4为本发明的一个实施例的方法流程示意图。
具体实施方式
下面将结合示例性的通信系统描述本发明。
为了便于理解本发明的技术方案和原理,现对于本文中出现的一些术语进行介绍和解释:
语料:大规模的语言实例,例如由人民日报中的2000年之后的报道构成的语料,或由维基百科中的条目和对应条目的网页内容构成语料。语料的组成由语料收集者根据语料的用途决定。
语料库通常是指由经过分词和对分词进行词性标注后的语料构成。
实体(entity):通常是名词,例如“频率”“概率”,“单层神经元网络”,其是知识图谱的顶点;
概念实体:是一种特殊的实体,该实体是一种课程中概念。
元素:本文为了区别概念1(实体)和概念2(组成实体的实体),因此将组成实体的实体称为元素,即由元素组成实体;例如“单层”“神经元”“网络”构成了实体“单层神经元网络”;有时元素也被称为词;根据语料的某一种或多种统计特征,将语料中的元素映射到向量空间,获得元素的向量表示,元素的向量表示也称为词向量。
实体的向量表示,也称为实体的嵌入表示或实体向量,其是根据语料的某一种或多种统计特征,将语料中的实体映射到向量空间。实体的向量表示与元素的向量表示具有相同的维度。
以下仅以通过课程视频字幕和百科文本的例子说明本发明是如何计算课程的先后序的。百科文本指的是维基百科中,与需要计算先后序课程相关的网页内容。
本领域技术人员应当知道,ppt文本、作业等都可代替本发明中课程视频字幕,或作为本发明课程视频字幕的补充,而教科书、ppt文本等可替代百科文本,或作为百科文本的补充,用于计算课程的先后序。
在本发明的一个实施例中,第一语料w包括各课程的视频字幕,辅助语料f包括百科文本。
通过分词和标注获得第一语料w中的概念实体;根据辅助语料f计算概念实体集合d’中的概念实体的向量表示。由第一语料w中概念实体的向量表示构成的集合标记为w’。第一语料w中的概念实体的向量表示的集合记为w’=<w’1…,w’i…,w’p>。
上述根据辅助语料w计算概念实体集合d’中的概念实体的向量表示,包括:根据skip-gramword2vec处理辅助语料w,获得辅助语料中k个元素的向量表示<x1,…xi,…xk>;若元素x等于实体w,则实体w的向量表示等于元素x的向量表示;若实体w不等于辅助语料w的k个元素中的任一一个,且w可以表示为w=e1+…en,则实体w的向量表示等于各个元素的向量表示之和,其中e1,…en∈{x1,…xi,…xk}。
即通过获得辅助语料中元素的向量表示获得第一语料w中概念实体的向量表示:
其中,vw表示实体w的向量表示,ve是元素e的向量表示,e、e1,…en∈{x1,…xi,…xk}。例如对于处理辅助语料获得“概率”这一概念实体的向量表示ve,则第一语料中的“概率”这一概念实体的向量表示等于ve;若辅助语料中不具有“随机森林分类器”这一概念实体,而仅具有概念实体“随机森林”“分类器”这两个概念实体,则第一语料中“随机森林分类器”这一实体概念的向量表示等于“随机森林”和“分类器”的向量表示之和,若辅助语料中不具“随机森林”“分类器”这两个概念实体的向量表示,则第一语料的概念实体的向量表示的集合w’=<w’1…,w’i…,w’p>中不包含“随机森林分类器”这一概念实体的向量表示。因此,若辅语料中未出现第一语料中的概念实体w,则可通过其他实体的向量表示构造出w的向量表示,从而解决现有技术中若辅助语料中没有对应的概念实体时,无法求解第一语料中概念实体的先后序的问题。
在本发明的一个实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>(为了书写方便,将vw写为w’),至少计算概念实体对之间的课程上下文方面的特征和课程结构方面的特征,课程上下文方面的特征包括视频引用距离特征,通用句子引用距离特征和辅助文本引用距离特征;课程结构方面的特征包括平均位置距离特征、分布不对称特征和复杂程度距离特征,至少根据获得的概念实体对之间的视频引用距离特征,通用句子引用距离特征、辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念语义方面的特征和课程结构方面的特征;课程概念语义方面的特征包括语义关系特征,课程结构方面的特征包括平均位置距离特征、分布不对称特征和复杂程度距离特征,至少根据获得的概念实体对之间的概念语义关系特征、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念视频引用距离特征、通用句子引用距离特征、辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,至少根据获得的概念语义关系特征、视频引用距离特征,通用句子引用距离特征、辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念语义关系特征、通用句子引用距离特征、辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,至少根据获得的概念语义关系特征、通用句子引用距离特征、辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念语义关系特征、视频引用距离特征辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,至少根据获得的概念语义关系特征、视频引用距离特征,辅助文本引用距离、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念语义关系特征、视频引用距离特征、通用句子引用距离特征、平均位置距离特征、分布不对称特征和复杂程度距离特征,至少根据获得的概念语义关系特征、视频引用距离特征、通用句子引用距离特征、平均位置距离特征、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念语义关系特征、视频引用距离特征,通用句子引用距离特征、辅助文本引用距离、分布不对称特征和复杂程度距离特征,至少根据获得的概念语义关系特征、视频引用距离特征,通用句子引用距离特征、辅助文本引用距离、分布不对称特征和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
在本发明的另一实施例中,根据上述计算获得的p个概念实体的向量表示w’=<w’1…,w’i…,w’p>,至少计算概念实体对之间的概念语义关系特征、视频引用距离特征、通用句子引用距离特征、辅助文本引用距离、平均位置距离特征和复杂程度距离特征,至少根据获得的概念语义关系特征、视频引用距离特征、通用句子引用距离特征、辅助文本引用距离、平均位置距离特和复杂程度距离特征,采用随机森林方法训练获得概念的先后序关系。
以上实施例只是为了示例说明本发明的实施方案,并不是本发明的全部实施例,本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。
在本发明中,在计算课程概念先后序时,将课程结构方面的复杂程度特征与其他特征结合,并通过随机森林方法根据上述特征计算课程概念之间的先后序,提高了课程概念先后序识别的准确性,从而对网络上大型开放网络课程提供了一个有效的先后序确认方法。
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间的概念语义关系特征:对于概念对<a,b>,表示a是b的先序概念,b是a的后续概念。a和b之间的语义关系(semanticrelatedness,sr)特征记为ω(a,b),
其中,va、vb分别为a、b的词向量嵌入表示。
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间的视频引用距离特征,视频引用距离特征也称为通用视频引用距离特征,对于一个概念对<a,b>,a和b之间的视频引用权重(videoreferenceweight,vrw)定义为:
vrd(a,b)=vrw(b,a)-vrw(a,b)
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间的通用句子引用距离:
可以定义a和b之间的句子引用权重(sentencereferenceweight,srw)和句子引用距离(sentencereferencedistance,srd):
srd(a,b)=srw(b,a)-srw(a,b)
其中r(s,a)∈{0,1}表示概念实体a是否出现在句子s中,出现则r(s,a)的值为1,否则为0。srw(a,b)可以计算出包含a的句子中出现概念实体b的比率。
考虑概念间语义关系,定义通用句子引用权重(generalizedsentencereferenceweight,gsrw)与通用句子引用距离(generalizedsentencereferencedistance,gsrd)特征:
gsrd(a,b)=gsrw(b,a)-gsrw(a,b)
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间的辅助文本引用距离:
辅助文本中也可能蕴含概念间先后序关系信息,因此,给定课程概念实体a,考虑与a在辅助语料上语义关系最为接近的m个实体,形式化为ra=<e1,…,em>,其中e1,…,em属于辅助语料中的实体标注e,定义辅助语料引用权重(wikipediareferenceweight,wrw):
其中erw(e,a)表征辅助语料的文章e是否被ra中任一概念所引用,被引用,值为1;否则为0。wrw(a,b)度量了与a相关的辅助语料实体被与b相关的辅助语料实体引用的频率。
定义辅助文本引用距离(wikipediareferencedistance,wrd)特征为:
wrd(a,b)=wrw(b,a)-wrw(a,b)
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间平均位置距离特征;
形式化定义包含概念实体a的课程为c(a),即c(a)={ci|ci∈d,a∈w′}。形式化定义a在课程c中的索引为i(c,a)。如,a出现在c课程中的第1和第4个视频中,i(c,a)={1,4}。
给定一个概念b,其先续概念实体a通常在b之前被介绍,但a、b可能会被多次提及,所以考虑各自出现位置的平均值,通常存在a的平均距离小于b的平均距离的分布。因此,对于同现于一个视频的两个概念,即
对于
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间的分布不对称特征;
给定一个概念b,为其先序概念a;给定一个包含a的视频va,包含b的视频vb,其中va在序号上先于vb。通常存在f(b,va)<f(a,vb),f(b,va)表示va中b的个数。形式化定义视频序号对集合s(c)={(i,j)|i∈i(c,a),j∈i(c,b),i<j},进一步定义分布不对称(distributionalasymmetrydistance,dad)特征为:
对于
在本文的一个实施例中,通过下述方法计算概念实体对<a,b>之间的复杂程度距离特征;定义概念的平均视频覆盖率(averagevideocoverage,avc)、平均覆盖长度(averagesurvivaltime,avt)为:
其中max/min(i(c,a))指a在c中第一次/最后一次出现的视频序号。
两个概念间的复杂程度距离(complexityleveldistance,cld)特征定义为:
cld(a,b)=avc(a)·ast(a)-avc(b)·ast(b);
给定一个领域的在线课程集合d和其中的课程概念实体向量表示的集合w’=<w’1…,w’i…,w’p>,目标是通过随机森林学习获得一个由w′2空间到{0,1}空间的映射函数p,使得一个概念对<a,b>,其中a,b∈w′,被映射到二分类0和1中,分别表征a不是b的先序概念和a是b的先序概念两种情况。最终得到两个概念是否存在先后序关系的判定结果。
本文中所指的随机森林(randomforest,简称rf)是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(ensemblelearning)方法。在本发明的一些是实力中,可以利用python的两个模块,分别为pandas和scikit-learn来实现随机森林。
在本文的一个实施例中,采用3个不同领域的大型开放式网络课程数据集:机器学习(machinelearning,ml),数据结构与算法(datastructureandalgorithms,dsa)和微积分(calculus,cal)。由于当前并没有用于先后序关系计算的开放数据集,所以本实验使用开源工具coursera-dl自动下载了著名在大型开放式网络课程网站coursera.org上对应三个领域的所有课程,人工标注出每门课程中的概念(即概念实体)。记概念总数为n,概念间两两构成的非重复概念对数量为n(n-1)/2,为标注二者是否存在先后序关系需要大量人工标注,所以本实验随机采样了概念对总数的25%用于实验,三个具备所选领域知识的人员对每对概念是否存在先后序关系进行标注。例如,对于一个概念对<a,b>,若a是b的先序概念,标注为“+”,否则为“-”。仅三人均认为存在先后序关系的概念对被保留,并使用成对统计的平均值κ作为标记一致性判定。三人均标记一致的概念对构成概念对集合,用于对本算法的计算获得的有序概念对的正确性进行验证。数据集的相关信息如图1所示。
辅助文本语料采用2015年8月的维基百科词条描述文本,共包括4,919,463篇文档。实体标注仅以维基百科中已标注的超链接作为候选,若维基百科所标注链接和给定在线课程中概念的名称相同,则标注为实体,否则不予标注。
对于每一个数据集,使用5折交叉验证的方法,即将数据集平均分为5份,其中4份用于本发明的模型训练,1份用于对发明方法效果的验证。因为数据集中正负例数量差异较大,实验中使用过采样的方法平衡了二者的数量。概念间上下文关系方面的特征需确定关联实体的数量m,本实验设置m=10进行实验。二分类方法使用随机森林(random4forest,rf)进行实验。问题已被形式化为一个二分类任务,所以实验评测使用信息检索领域的常用的一个评价标准:准确率(precision,p),召回率(recall,r)和f1值(fscore,f1)。易知,更高的f1值体现了更优秀的概念间先后序关系计算方法。
采用以上数据集和实验设置,同当前概念先后序关系计算主流方法上下位匹配方法(hpm)、引用距离(rd)和监督关系识别(仅使用教科书特征t-sri和使用原方法所有特征f-sri)进行对比。除了本发明公布的基本数据集,我们还从数据集中筛选出包含于维基百科的概念对集合用于与引用距离和监督关系识别方法进行更具说服力的对比实验,分别记为w-ml、w-dsa和w-cal。使用ml数据集,依次移除某一特征、某一组特征进行实验,用于对本发明所提出的特征计算方法贡献度进行衡量。
如图2所示,不同方法在不同数据集上测评的结果(“mooc”指本发明的方法)。对比f1值可以看出在6个数据集上本发明的方法在计算在线课程概念先后序时都体现出比其他方法更为有效的结果。例如,在ml数据集中,f1值分别高于t-sri和hpm方法10.5%和43.6%。在仅包含维基中存在概念的w-ml、w-dsa和w-cal数据集上,本发明的方法效果也高于其他方法至少5.7%。
对维基不包含的概念计算效果显著原因分析。hpm和t-sri都是不依赖于课程概念必须存在于维基百科中的概念先后序计算方法,但实验结果中本发明的方法效果都远高于二者(f1值比hpm高43.6%,比t-sri高10.5%)。首先,hpm在计算时能达到一个较高的准确率,但召回率很低。这是因为,当匹配到a“isa”b时,通常蕴含b是a的先序概念的意思,但显然反过来并不是这样的意思,hpm是基于连接词匹配,并不能处理反过来的搭配。其次,t-sri确实体现出了较高的计算效果(f1值稳定在62.1%-65.2%之间)。然而,t-sri只考虑了一些简单的特征,比如课程的序列性和概念间的共现。对在线课程进行更充分考虑、拥有更多设计精巧的特征的本实验方法自然效果更为显著。另外,sri在增加了基于维基百科的特征后(f-sri),效果较t-sri仅提高了0.93%。因此,其实基于维基百科的特征并不是提高概念先后序关系的最主要因素。
如图3所示,特征贡献测评的结果。通过对比移除特征之后分类结果在f1值上体现的变化情况,可以直观的看出:单个特征中,基于课程结构方面的复杂程度距离特征对本发明方法的负面效果影响最大(移除后f1值下降7.4%),与之相反,影响最小的是基于概念语义方面的语义关系特征(移除后f1值下降1.4%);一组特征中,移除课程结构方面的3个特征对本发明方法的负面效果影响最大(移除后f1值下降9.2%),影响最小的是概念语义方面的特征(移除后f1值下降1.4%)。
本文中使用的“至少一个”、“一个或多个”以及“和/或”是开放式的表述,在使用时可以是联合的和分离的。例如,“a、b和c中的至少一个”,“a、b或c中的至少一个”,“a、b和c中的一个或多个”以及“a、b或c中的一个或多个”指仅有a、仅有b、仅有c、a和b一起、a和c一起、b和c一起或a、b和c一起。
术语“一个”实体是指一个或多个所述实体。由此术语“一个”、“一个或多个”和“至少一个”在本文中是可以互换使用的。还应注意到术语“包括”、“包含”和“具有”也是可以互换使用的。
本文中使用的术语“自动的”及其变型是指在执行处理或操作时没有实质的人为输入的情况下完成的任何处理或操作。然而,即使在执行处理或操作时使用了执行所述处理或操作前接收到的实质的或非实质的人为输入,所述处理或操作也可以是自动的。如果输入影响所述处理或操作将怎样进行,则视该人为输入是实质的。不影响所述处理或操作进行的人为输入不视为是实质的。
本文中使用的术语“计算机可读介质”是指参与将指令提供给处理器执行的任何有形存储设备和/或传输介质。计算机可读介质可以是在ip网络上的网络传输(如soap)中编码的串行指令集。这样的介质可以采取很多形式,包括但不限于非易失性介质、易失性介质和传输介质。非易失性介质包括例如nvram或者磁或光盘。易失性介质包括诸如主存储器的动态存储器(如ram)。计算机可读介质的常见形式包括例如软盘、柔性盘、硬盘、磁带或任何其它磁介质、磁光介质、cd-rom、任何其它光介质、穿孔卡、纸带、任何其它具有孔形图案的物理介质、ram、prom、eprom、flash-eprom、诸如存储卡的固态介质、任何其它存储芯片或磁带盒、后面描述的载波、或计算机可以读取的任何其它介质。电子邮件的数字文件附件或其它自含信息档案或档案集被认为是相当于有形存储介质的分发介质。当计算机可读介质被配置为数据库时,应该理解该数据库可以是任何类型的数据库,例如关系数据库、层级数据库、面向对象的数据库等等。相应地,认为本发明包括有形存储介质或分发介质和现有技术公知的等同物以及未来开发的介质,在这些介质中存储本发明的软件实施。
本文中使用的术语“确定”、“运算”和“计算”及其变型可以互换使用,并且包括任何类型的方法、处理、数学运算或技术。更具体地,这样的术语可以包括诸如bpel的解释规则或规则语言,其中逻辑不是硬编码的而是在可以被读、解释、编译和执行的规则文件中表示。
本文中使用的术语“模块”或“工具”是指任何已知的或以后发展的硬件、软件、固件、人工智能、模糊逻辑或能够执行与该元件相关的功能的硬件和软件的组合。另外,虽然用示例性实施方式来描述本发明,但应当理解本发明的各方面可以单独要求保护。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!