一种基于深度卷积神经网络和证据K近邻的人脸核实方法与流程
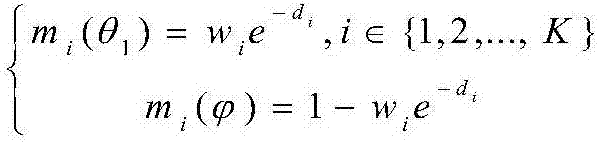
本发明涉及人工智能和模式识别技术领域,具体涉及一种基于深度卷积神经网络和证据k近邻的人脸核实方法。
背景技术:
身份验证具有重大的应用价值,作为保证信息安全的重要技术之一,一直以来是研究的热点,二代身份证的人脸验证具有非常大的应用领域。早期的人脸验证大都针对约束环境下的人脸识别,并取得了非常好的效果。然而在无约束环境下,光照,用户姿势,年龄更替等外在因素,人脸认证的正确率不尽人意。
近年来,随着深度学习概念的提出,通过深度神经网络模型提取特征,广泛应用于各领域特征提取并取得了重大的进步。
证据理论,也称为dempster/shafer证据理论(d-s证据理论),属于人工智能范畴,最早应用于专家系统中,具有处理不确定信息的能力。由于人脸之间存在环境干扰因素(如光照)和自身因素(如姿势),所获取的信息会包含一定的不确定性信息。另外,人脸核实准确性也受到模板库完备性影响,传统分类方法比如knn,svm等不能处理这部分不确定信息,容易产生误判。而证据理论能够针对这些问题提出有效的解决方案。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于深度卷积神经网络(deepconvolutionalneuralnetwork,dcnn)和证据k近邻(evidenceknearestneighbor,ek-nn)的人脸核实方法,结合证据推理中的d-s、pcr5组合规则和k近邻理论,增强了人脸核实的鲁棒性,提升了人脸核实的准确性和速度。
本发明的目的可以通过采取如下技术方案达到:
一种基于深度卷积神经网络和证据k近邻的人脸核实方法,所述人脸核实方法包括下列步骤:
s1、人脸特征提取,采集人脸图像并通过训练深度卷积神经网络进行人脸特征的提取;
s2、近邻证据的构造和融合,通过提取的人脸特征,找到人脸模板库m个近邻类,类内选择k个近邻,进行证据的构造和基本置信指派,使用d-s证据理论类内融合得到类的总的bpa;
s3、类别间证据融合,pcr5规则处理证据冲突,融合所得的全局mass转换成待识别人脸属于各个模式类别的pignistic概率,设计分类规则,得出结果。
进一步地,所述步骤s1中采集人脸图像之后进行人脸图像预处理,具体过程如下:
对人脸图像进行人脸检测、对齐、归一化操作,采用adaboost算法和asm算法进行人脸检测和关键点定位,再按照瞳孔坐标位置进行归一化为100*100的图像,将归一化的图像进行灰度处理并且采用quotientimage方法去除光照干扰。
进一步地,所述深度卷积神经网使用tensorflow进行搭建,包括七层,其中,
第一层是卷积运算操作层,输入是100×100像素大小的人脸对齐图像,有大小为5×5像素的32个过滤器,填充值为2,步长为1,输出为100×100×32的二维图像,激活函数设置为relu函数;
第二层是卷积运算层和下采样层,输入是100×100×32的二维图像,卷积层有大小为5×5像素的64个过滤器,填充值为2,步长为1,使用的激活函数是relu函数,下采样层使用2×2的核,步长为2,进行avgpooling下采样输出为:50×50×64,然后进行正则化处理;
第三层是卷积运算操作层与下采样层,输入是50×50×64的图像,采用大小为3×3像素的64个过滤器,填充值为1,使用的激活函数是relu函数,使用2×2的核进行avgpooling下采样输出为:25×25×64的二维图像;
第四层是卷积运算操作层与采样层,输入是25×25×64的图像,采用大小为3×3像素的16个过滤器,填充值为1,使用的激活函数是修正线性单元函数,采样层使用maxpooling,输出为13×13×16的二维图像;
第五层是全连接层,输入是2704维的向量,即上一神经网络层的输出展开后的向量,输出1000维的向量,使用的激活函数是修正线性单元函数;
第六层是dropout层,输入是1000维的输入向量,输出160维的向量,采用的激活函数是修正线性单元函数防止过拟合,dropout层仅产生40%的输出;
第七层是输出层,通过softmax分类器产生一个10548维向量。
进一步地,所述步骤s2具体过程包括:人脸模板库的建立、近邻证据的构造、近邻证据置信指派和融合。
进一步地,所述人脸模板库中将第m类人脸n张图片求出类中心点和类最大边界距离作为人脸m的特征,具体建立过程如下:
假设第m类人脸第n张图片经过深度卷积神经网络之后提取l维特征,特征为xm,n={cm,n,1,cm,n,2,…,cm,n,l},第m类人脸总共n张人脸图片建立的m类中心点xm={xn,1,xn,2,…,xn,l},其中:
最大边界距离是每个人脸到中心距离的欧氏距离最大值,构造m类的最大边界距离dm作为m类的另外一个特征:
最后n类人脸建立一个模板矩阵,下面用ψ表示:
ψ的每一个行向量代表同一个人脸的特征向量的平均值,由ψ可知模板库里面一共有n个人脸。
进一步地,所述近邻证据的构造具体过程如下:
假设待识别人脸的特征向量为xs={c1,c2,…,cl},首选寻找m个近邻类中心点,近邻类的选择需要满足两个条件:
a.与类中心点距离尽可能近;
b.在类的最大边界距离之内;
也即,根据欧氏距离:
根据特征距离大小从小到大选取m-1个近邻,加上距离模板库较远的归为一个类,总共m个类。近邻样本集合为:
{c1,c2,...,cm-1}。
进一步地,所述近邻证据置信指派和融合具体过程如下:
令cm用θm表示,把m个预选类包含的命题作为一个辨识框架θ,即{θ1,θ2,…,θm-1,θm},在其中每个类里使用欧氏距离分别选取k个近邻点构造证据;
k个紧邻点通过以下方法构造近邻证据:
其中,mi(θ1)表示在近邻类别θ1里第i个近邻点构造的证据,
最后使用d-s证据理论得到类的总的bpa。
进一步地,所述步骤s3中采用pcr5规则处理证据冲突,原理是将冲突信息按比例精确分配给相应的命题,得到不存在冲突的证据,在d-s模型下pcr5规则可以表示如下:
其中,
进一步地,所述步骤s3中采用以下规则进行分类决策:
a.所识别的类pignistic概率与其他类的pignistic概率差值要大于设定的阈值σ,这个阈值的设定可以根据测量每个类的边界点的pignistic概率差值来估计;
b.当识别的类的bpa的值小于未知基本信任指派值时,则判断目标t为不能准确分类。
满足以上两条,判断pignistic概率值最大的类为识别的类。
本发明相对于现有技术具有如下的优点及效果:
1、本发明将深度卷积神经网络应用人脸认证当中,并构建深度卷积神经网络,通过设置较大的卷积核,深度卷积神经网络结构的深度较小,使用新方法提取特征并取得了很好的效果。
2、本发明提出一种新的证据k类近邻构造算法,该算法通过构建人脸中心点和最大边界距离特征,大大减少了人脸库的匹配数量,通过寻找k近邻中心点的方式,大大减少了计算量,提高了实时性。
3、本发明使用距离长短作为置信指派的依据,最重要的是类内使用k个点证据融合,相比k近邻算法提高了类的置信度,提高了整个算法的准确性。
附图说明
图1是本发明设计的深度卷积神经网络结构;
图2是本发明针对人脸认证提出的基于深度卷积神经网络和证据k近邻的人脸核实方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
本实施例公开了一种基于深度卷积神经网络和证据k近邻的人脸核实方法,具体包含以下步骤:
s1、人脸特征提取,采集人脸图像并通过深度卷积神经网络进行人脸特征的提取。
本发明选择目前比较流行的深度卷积神经网络用来进行人脸特征的提取工作。在步骤s1中,对采集到的数据集采用adaboost算法和asm算法进行人脸检测和关键点定位,再按照瞳孔坐标位置进行归一化为100*100的图像,将归一化的图像进行灰度处理并且采用quotientimage方法去除光照干扰,接着采用本发明搭建的深度卷积神经网络对人脸进行特征提取工作,获取的特征向量为x={c1,c2,...,cl},l为维度。
s2、近邻证据的构造和融合,利用步骤s1获得的人脸特征,找到人脸模板库m个近邻类,类内选择k个近邻,进行证据的构造和基本置信指派,使用d-s证据理论类内融合得到类的总的bpa。
在步骤s2中,具体包括人脸模板库的建立、近邻证据的构造、近邻证据置信指派和融合。具体说明如下:
s201、人脸模板库的建立:假设第m类人脸第n张图片经过深度卷积神经网络之后提取l维特征,特征为xm,n={cm,n,1,cm,n,2,…,cm,n,l},第m类人脸总共n张人脸图片建立的m类中心点xm={xm,1,xm,2,…,xm,l},其中:
最大边界距离是每个人脸到中心距离的欧氏距离最大值,这里需要构造m类的最大边界距离dm作为m类的另外一个特征:
最后n类人脸建立一个模板矩阵,下面用ψ表示:
ψ的每一个行向量代表同一个人脸的特征向量的平均值,由ψ可知模板库里面一共有n个人脸。
任意类m人脸拥有两个特征:一个是中心点xm,一个最大边界距离dm。
s202、近邻证据的构造:
建立人脸模板库之后,接着要找到近邻类,假设待识别人脸的特征向量为xs={c1,c2,…,cl},首先需要找到人脸模板库里面与待识别目标近邻的m个类,需要满足两点规则:
a.与类中心点距离尽可能近;
b.在类的最大边界距离之内。
根据欧氏距离:
根据特征距离大小从小到大选取m-1个近邻,加上距离模板库较远的归为一个类,总共m个类。近邻样本集合为:
{c1,c2,...,cm-1}。
s203、近邻证据置信指派和融合:
特征距离越小,说明其类别属性和待识别目标接近,构造的近邻证据权重越大。令cm用θm表示,把步骤s202中的m个预选类包含的命题作为一个辨识框架θ,即{θ1,θ2,…,θm-1,θm},在其中每个类里分别选取k个近邻点构造证据。例如在θm类里选取目标t的k个近邻点及对应的欧式距离从小到大排序的集合为{(x1,d1),(x2,d2)...(xk,dk)},根据每个类里的每个近邻点的欧式距离映射到基本概率分配(bpa)是一个负指数函数,以θ1为例,则可以构造k近邻证据为:
其中,mi(θ1)表示在近邻类别θ1里第i个近邻点构造的证据,mi(φ)表示在类别θ1下分配给未知的精确信任,wi表示第i个近邻证据所占权重,由以下公式确定:
把每一个近邻类里的证据用d-s规则进行组合,首先简要介绍一下d-s组合规则,根据证据理论的知识,假设在辨识框架θ下有两个证据m1和m2,其焦员分别是bi和aj(i,j=1,2,3...),则把证据按以下组合:
其中,c表示组合后的新命题,m(c)表示组合后的bpa,其值表示指派c的基本信任指派值,而
在近邻证据组合上,根据上面可知在近邻类里kc=0,用d-s规则可以得到θm类的总的bpa如下:
s3、类别融合与决策,类别间证据融合,处理证据冲突,融合所得的全局mass转换成待识别人脸属于各个模式类别的pignistic概率,设计分类规则,得出结果。
根据步骤s2假设得到各个类别总的bpa的集合为{m1,m2,m3,...,mm},它们分别指派不同的类别,所以在进一步进行证据组合会存在一定冲突,例如θ1和θ2类别进行组合会得到:
m(φ)=m(θ1∩θ2)=m1(θ1)·m2(θ2)
证据理论中要求空集
为解决这个问题,需要采用pcr5规则进行类别间证据融合,原理是将冲突信息按比例精确分配给相应的命题,得到不存在冲突的证据。在d-s模型下pcr5规则可以表示如下:
其中,
k12=m12(θ1∩θ2)=m1·m2
经过pcr5规则将证据融合得到:
以上就是经过pcr5规则进行证据融合后得到的全局bpa,对于辨识框架{θ1,θ2,…,θm-1,θm},也是用pcr5规则把{m1,m2,m3,...,mm}中的冲突部分进行再分配得到每一个类的全局bpa。
pignistic概率判断类别:
求得近邻类的全局bpa后,根据可传递信任模型相关理论,将指派近邻类置信度的全局mass函数值转换为pignistic概率表示,例如对于近邻类θi,判断目标t属于该类别的pignistic概率大小由以下公式来表示:
在步骤3)中,当然不能简单地根据pignistic概率大小来判断目标位于哪一类,为保证判断准确,需要正确识别的类与其他类有一定差异,于是有以下规则进行分类决策:
a.所识别的类pignistic概率与其他类的pignistic概率差值要大于设定的阈值σ,这个阈值的设定可以根据测量每个类的边界点的pignistic概率差值来估计。
b.当识别的类的bpa的值小于未知基本信任指派值时,则判断目标t为不能准确分类。
c.满足以上两条,判断pignistic概率值最大的类为识别的类。
最后,计算出符合以上分类规则的p(ci),i为所得的1到m的某一特定值。那么类别ci即为判定为待识别人脸目标的所属类别。
实施例二
本实施例公开了一种基于深度卷积神经网络和证据k近邻的人脸核实方法,具体包含以下步骤:
1)人脸图像预处理
将人脸模板库中的人脸图像进行人脸检测、对齐、归一化操作,采用adaboost算法和asm算法进行人脸检测和关键点定位,再按照瞳孔坐标位置进行归一化为100*100的图像,将归一化的图像进行灰度处理并且采用quotientimage方法去除光照干扰。
2)神经网络的搭建与训练
下面使用tensorflow进行深度卷积神经网络的搭建。
第一层是卷积运算操作层,这一层输入的是100×100像素大小的人脸对齐图像。有大小为5×5像素的32个过滤器,填充值为2,步长为1,输出为100×100×32的二维图像,激活函数设置为relu函数。
第二层是卷积运算层和下采样层,输入是100×100×32的二维图像,卷积层有大小为5×5像素的64个过滤器,填充值为2,步长为1,使用的激活函数是relu函数,下采样层使用2×2的核,步长为2,进行avgpooling下采样输出为:50×50×64,然后进行正则化处理。
第三层是卷积运算操作层与下采样层,这一层输入的是50×50×64的图像,采用大小为3×3像素的64个过滤器,填充值为1,使用的激活函数是relu函数,使用2×2的核进行avgpooling下采样输出为:25×25×64的二维图像。
第四层是卷积运算操作层与采样层,这一层输入的是25×25×64的图像,采用大小为3×3像素的16个过滤器,填充值为1,使用的激活函数是修正线性单元函数,采样层使用maxpooling,输出为13×13×16的二维图像。
第五层是全连接层,接收的输入是2704维的向量,即上一神经网络层的输出展开后的向量,输出1000维的向量,使用的激活函数是修正线性单元函数。
第六层是dropout层,接收1000维的输入向量,输出160维向量采用的激活函数是修正线性单元函数防止过拟合,dropout层仅产生40%的输出。
第七层是输出层,通过softmax分类器产生一个10548维向量。
最后,交叉熵损失函数来定义costfunction,使用adamoptimizer()函数作为优化器进行优化。
使用casia-webface人脸数据库,作为深度卷积神经网络的训练。
3)人脸模板库的建立:
训练样本选取n类人脸每类人脸都有若干张不同表情、姿态的照片提取特征,求出每类人脸多张图片特征的中心点和相应最大边界距离,组成n类人脸中心点模板库矩阵和n类人脸最大边界距离矩阵。
n类人脸的中心点模板库矩阵:
n类人脸最大边界距离矩阵:
d=[d1,d2,…,dn]。
4)近邻证据的构造
建立人脸模板库之后,接着要找到近邻类,假设待识别人脸的特征向量为xs={c1,c2,…,cl},首先需要找到模板库里面与待识别目标近邻的m个类,m取值需要根据实验效果设计,采用交叉验证法为m设置一个合适值,太大容易导致计算量太大,需要满足两点规则:
a.与类中心点距离尽可能近;
b.在类的最大边界距离之内。
根据欧氏距离:
根据特征距离大小从小到大选取m-1个近邻,加上距离模板库较远的归为一个类,总共m个类。近邻样本集合为:
{c1,c2,...,cm-1}。
5)近邻证据置信指派和融合
把上述步骤中的m个预选类包含的命题作为一个辨识框架θ,即{θ1,θ2,…,θm-1,θm},在其中每个类里分别选取k个近邻点构造证据,这里的k不能大于每类人脸拥有的照片数量,采用实验的方法设置k的最佳值。例如在θm类里选取目标t的k个近邻点及对应的欧式距离从小到大排序的集合为{(x1,d1),(x2,d2)...(xk,dk)},根据每个类里的每个近邻点的欧式距离映射到基本概率分配(bpa)是一个负指数函数,以θ1为例,则可以构造k近邻证据为:
其中,mi(θ1)表示在近邻类别θ1里第i个近邻点构造的证据,mi(φ)表示在类别θ1下分配给未知的精确信任,wi表示第i个近邻证据所占权重,由以下公式确定:
把每一个近邻类里的证据用d-s规则进行组合:
其中,c表示组合后的新命题,m(c)表示组合后的bpa,其值表示指派c的基本信任指派值,
而
在近邻证据组合上,根据上面可知在近邻类里kc=0,用d-s规则可以得到θm类的总的bpa如下:
6)类别融合与决策:
根据以上步骤假设得到各个类别总的bpa的集合为{m1,m2,m3,...,mm},它们分别指派不同的类别,所以在进一步进行证据组合会存在一定冲突,例如θ1和θ2类别进行组合会得到:
需要采用pcr5规则进行类别间证据融合,原理是将冲突信息按比例精确分配给相应的命题,得到不存在冲突的证据。在d-s模型下pcr5规则可以表示如下:
其中,
k12=m12(θ1∩θ2)=m1·m2
经过pcr5规则将证据融合得到:
以上就是经过pcr5规则进行证据融合后得到的全局bpa,对于辨识框架{θ1,θ2,…,θm-1,θm},也是用pcr5规则把{m1,m2,m3,...,mm}中的冲突部分进行再分配得到每一个类的全局bpa。
pignistic概率判断类别:求得近邻类的全局bpa后,根据可传递信任模型相关理论,将指派近邻类置信度的全局mass函数值转换为pignistic概率表示,例如对于近邻类θi,判断目标t属于该类别的pignistic概率大小由一下公式来表示:
为保证判断准确,需要正确识别的类与其他类有一定差异,于是有以下规则进行分类决策:
a.所识别的类pignistic概率与其他类的pignistic概率差值要大于设定的阈值σ,这个阈值的设定可以根据测量每个类的边界点的pignistic概率差值来估计。
b.当识别的类的bpa的值小于未知基本信任指派值时,则判断目标t为不能准确分类。
c.满足以上两条,判断pignistic概率值最大的类为识别的类。
最后,计算出符合以上分类规则的p(ci),i为所得的1到m的某一特定值。那么类别ci即为判定为待识别人脸目标的所属类别。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!