一种多米诺优化的GPU加速电力上三角方程组回代方法与流程
本发明属于电力系统高性能计算应用领域,尤其涉及一种多米诺优化的gpu加速电力上三角方程组回代方法。
背景技术:
潮流计算是电力系统中应用最广泛、最基本和最重要的一种电气运算。在电力系统运行方式和规划方案的研究中,都需要进行潮流计算以比较运行方式或规划供电方案的可行性、可靠性和经济性。同时,为了实时监控电力系统的运行状态,也需要进行大量而快速的潮流计算。因此,在系统规划设计和安排系统的运行方式时,采用离线潮流计算;在电力系统运行状态的实时监控中,则采用在线潮流计算。
而实际生产过程中,无论离线潮流和在线潮流计算都对潮流的计算速度有这比较高的要求。在涉及规划设计和安排运行方式的离线潮流中,因设备落地方案等情况复杂,需要仿真运行的种类多,潮流计算量大,单个潮流计算时间影响整体仿真时长;而在电力系统运行中进行的在线潮流计算对计算时间敏感度高,需要实时给出潮流计算结果,如在预想事故、设备退出运行对静态安全的影响的潮流计算中,系统需要计算大量预想事故下潮流分布,并实时地做出预想的运行方式调整方案。
gpu是一种众核并行处理器,在处理单元的数量上要远远超过cpu。传统上的gpu只负责图形渲染,而大部分的处理都交给了cpu。现在的gpu已经法阵为一种多核,多线程,具有强大计算能力和极高存储器带宽,可编程的处理器。在通用计算模型下,gpu作为cpu的协处理器工作,通过任务合理分配分解完成高性能计算。
稀疏线性方程组求解是电力系统潮流计算中很重要的计算部分,其中回代运算次数更多。对方程组系数矩阵进行lu符号分解后,得到上三角变换矩阵u的稀疏结构,根据u阵的稀疏结构,对u矩阵各行进行并行化分层,其中每层中的列的计算相互独立,没有依赖关系,天然可以被并行的计算处理,适合gpu加速,但是随着层数增加,每层中的行数变少,并行加速效果急剧下降,无法使程序充分发挥gpu的优势。
因此,亟待解决上述问题。
技术实现要素:
发明目的:本发明的目的是提供一种能大幅减少电力潮流线性方程组回代运算的计算时间并能提升潮流计算速度的一种多米诺优化的gpu加速电力上三角方程组回代方法。
潮流计算:电力学名词,指在给定电力系统网络拓扑、元件参数和发电、负荷参量条件下,计算有功功率、无功功率及电压在电力网中的分布。
gpu:图形处理器(英语:graphicsprocessingunit,缩写:gpu)。
技术方案:为实现以上目的,本发明公开了一种多米诺优化的gpu加速电力上三角方程组回代方法,所述方法包括:
(1)cpu中根据雅可比矩阵的lu符号分解结果,即上三角变换矩阵u的稀疏结构,对上三角变换矩阵u各行进行并行化分层,进一步生成回代运算所需的运算顺序eorderu;并将gpu计算所需数据传输至gpu;
(2)在gpu中设置上三角变换矩阵u各行的标志位marku;
(3)在gpu中调用lu回代运算内核函数lubackward。
其中,所述步骤(1)中,并行化分层将上三角变换矩阵u的n行归并到若干层中,然后根据先小层号后大行号的原则进行排序,生成上三角变换矩阵u的回代运算顺序eorderu;gpu计算所需的数据包括:上三角变换矩阵u,运算顺序eorderu,线性方程组维度n,线性方程组的前推运算结果y。
优选的,所述步骤(2)中,在gpu的设备内存中为上三角变换矩阵u各行设置标志位marku(k),k表示行号,并置值为0,表示没有完成第k行的计算。在内核函数计算完成第k行时,将标志位marku(k)置为1。
再者,所述步骤(3)中,lu回代运算内核函数定义为lubackward<nblocks,nthreads>,其线程块大小nthreads固定为128,线程块数量nblocks=(n-1)/nthreads+1;
进一步,所述内核函数lubackward<nblocks,nthreads>的计算流程为:
(2.1)cuda自动为每个线程分配线程块索引blockid和线程块中的线程索引threadid;
(2.2)将blockid和threadid赋值给变量bid和t,之后通过bid和t来索引bid号线程块中的t号线程;
(2.3)第bid号线程块中的t号线程负责计算运算顺序eorderu中的第bid*blockdim+t行,设行号为k,k=eorderu[bid*blockdim+t],其中,blockdim=nthreads;
(2.4)第bid号线程块中的t号线程中,变量i从k+1递增到n,如果u(k,i)≠0,并且marku(i)=1,采用公式x(k)=y(k)-x(i)×u(k,i)来计算回代结果x的第k个元素x(k),若marku(i)不等于1,线程等待,直到marku(i)为1继续执行;
(2.5)采用公式x(k)=x(k)/u(k,k)更新x(k);
(2.6)设置第k行的标志位为1,marku(k)=1。
有益效果:与现有技术相比,本发明具有以下显著优点:首先本发明根据电力潮流线性方程组的雅可比矩阵的lu符号分解结果,即u阵的稀疏格式,可以减少不必要的浮点计算;其次根据u阵的稀疏结构将u矩阵的各行分到可以并行计算的不同层次,并根据层号小的排在前面,层号相同时,行号大的排在前面的原则进行排序,生成上三角变换矩阵u的回代运算顺序eorderu;再者gpu中为矩阵u的每行设置标志位,在计算具体某一行时,查询与其相关的行是否计算完成,即标志位是否为1,这样可以将部分密集的浮点计算提前完成,提高了回代运算的计算速度,解决了电力系统概率潮流计算耗时大的问题。
附图说明
图1为本发明的流程示意图;
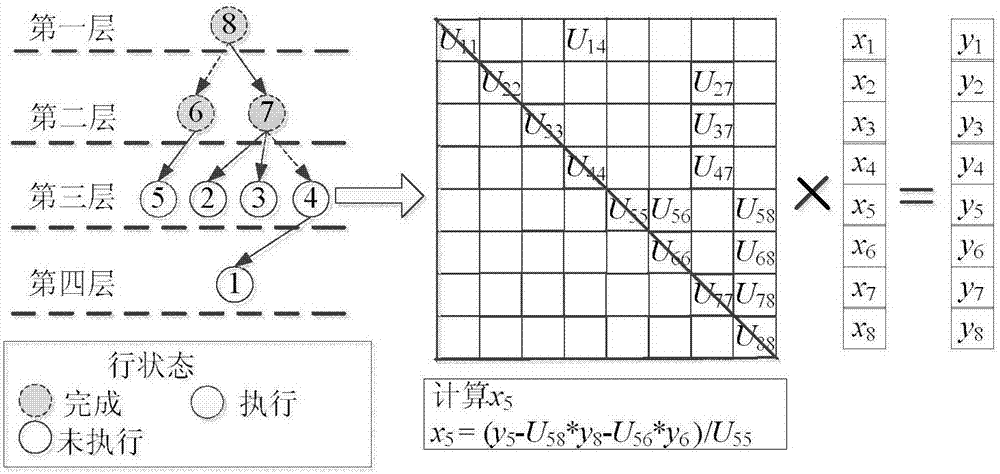
图2为本发明所使用的算例;
图3为发明采用多米诺的优化前的计算示意图;
图4为发明采用多米诺的优化后的计算示意图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明。
如图1所示,本发明一种多米诺优化的gpu加速电力上三角方程组回代方法,该方法分为以下几个步骤具体实现:
步骤1:cpu中生成回代运算顺序,传输计算数据
cpu中根据雅可比矩阵的lu符号分解结果,即上三角变换矩阵u的稀疏结构,对上三角变换矩阵u各行进行并行化分层,并行化分层将上三角变换矩阵u的n行归并到若干层中;然后根据层号小的排在前面,层号相同时,行号大的排在前面的原则进行排序,生成上三角变换矩阵u的回代运算顺序eorderu;接着,cpu将gpu计算所需数据传输给gpu,数据包括:上三角变换矩阵u,运算顺序eorderu,线性方程组维度n,线性方程组的前推运算结果y;
其中,并行化分层原理参见“directmethodsforsparselinearsystems”timothya.davis,siam,philadelphia,2006,“针对不规则问题的并行算法设计与体系结构优化”,陈晓明。
步骤2:gpu中设置标志
在cpu调用gpu的内核函数执行运算之前,先为上三角变换矩阵u的每一行设置一个标志位marku(k),k表示行号,并置值为0,表示没有完成第k行的计算。在内核函数计算完成第k行时,将标志位marku(k)置为1。
步骤3:调用lu回代运算内核函数lubackward
lu回代运算内核函数定义为lubackward<nblocks,nthreads>,其线程块大小nthreads固定为128,线程块数量nblocks=(n-1)/nthreads+1;
lubackward<nblocks,nthreads>的计算流程为:
(2.1)cuda自动为每个线程分配线程块索引blockid和线程块中的线程索引threadid;
(2.2)将blockid和threadid赋值给变量bid和t,之后通过bid和t来索引bid号线程块中的t号线程;
(2.3)第bid号线程块中的t号线程负责计算运算顺序中的第bid*blockdim+t行,设行号为k,k=eorderu[bid*blockdim+t],其中,blockdim=nthreads;
(2.4)第bid号线程块中的t号线程中,变量i从k+1递增到n,如果u(k,i)≠0,并且marku(i)=1,采用公式x(k)=y(k)-x(i)×u(k,i)来计算回代结果x的第k个元素x(k),若marku(i)不等于1,线程等待,直到marku(i)为1继续执行;
(2.5)采用公式x(k)=x(k)/u(k,k)更新x(k);
(2.6)设置第k行的标志位为1,marku(k)=1。
本发明以一个维度为8的线性方程组上三角矩阵u的回代运算为例来说明多米诺的加速效果,具体运算过程如图2所示。按照步骤1中所述,将上三角矩阵u的8行分到4层中,如图3所示,每层并行进行计算。采用多米诺优化后,在计算第5行时,与第5行相关的第8行的标志位为1,第5行的一部分计算提前完成,通过这种优化,节省了计算时间,具体如图4所示。对于8阶的线性方程组回代运算而言,节省时间的效果不明显,但是当矩阵维度较大时,加速效果显著。
- 还没有人留言评论。精彩留言会获得点赞!