一种燃煤机组的多煤种配煤掺烧寻优方法与流程
本发明涉及煤电技术领域,特别是涉及一种燃煤机组的多煤种配煤掺烧寻优方法。
背景技术:
目前,火力发电厂锅炉选型有相对应的设计煤种,当煤质超过锅炉的适应范围,将会给锅炉的安全、经济性带来很大影响。近年来、特别是南方内陆电厂,设计煤种不能满足需求,煤源煤质不稳定,导致了锅炉炉膛结焦、超温、爆管、灭火、出力下降、锅炉效率下降等问题。目前各火力发电厂已普遍采用配煤掺烧技术,通过在煤粉进入炉膛前将不同煤种依据一定原则按一定比例进行混配,实现确保燃煤质量均衡化、调节燃煤品质、降低燃料成本、减少污染物排放、拓宽煤源管道等目标。火力发电中,燃煤占发电成本的60%以上,采用配煤掺烧技术的火电厂均获得了巨大的经济效益,是影响火电厂经济成本的重要因素。对入炉煤种进行配煤掺烧,可有效降低火电厂燃煤成本;与此同时,做好燃煤配煤掺烧,对锅炉的安全、稳定、经济运行具有重要的意义。
不同的煤种掺配,即使最终化验结果一致,但燃烧特性也会完全不同。火电厂在做配煤掺烧工作时,主要依靠组织掺烧试验或者燃料相关管理人员的工作经验作为判断来进行配煤掺烧。前者需要稳定特定工况、煤质,试验条件苛刻且样本量偏少,难以真实反映设备运行状况和人员操作水平。后者缺乏数据支撑,特别是中储式制粉系统掺配与耗用分离,中间环节多,煤质复杂,变化延迟大,工况变化大,受人工计算对数据处理粗略性的影响,所得配煤掺烧方案不够精确,应用的配煤掺烧方法简单,同时,仅依靠脑力,并不能建立起庞大的数据库给配煤掺烧工作提供寻优指导;很难寻找到历史同工况下最低煤耗、最低供电成本对应的掺配方案,使得历史产生的大量可作为指导的数据不能被有效利用起来,燃煤供电成本也不能有效降低。
技术实现要素:
本发明的目的是提供一种燃煤机组的多煤种配煤掺烧寻优方法,以实现降低电厂燃煤成本。
为解决上述技术问题,本发明提供一种燃煤机组的多煤种配煤掺烧寻优方法,包括:
按照模糊控制原理建立配煤掺烧数据库;
生成综合度电成本标杆库;
针对设定的不同运行工况,寻找最优配煤掺烧方案。
优选的,所述按照模糊控制原理建立配煤数据库,包括:
将电厂的运行工况进行离散化处理,并按照不同工况进行分组;
将不同煤种配比作为输入因子,进行离散化分组处理;
记录不同工况和煤种占比对应的供电煤耗,建立配煤掺烧数据库。
优选的,电厂的运行工况包括运行机组、负荷和环境温度。
优选的,所述生成综合度电成本标杆库,包括:
实时调取数字化煤场的各煤种当前煤价信息;
将各煤种煤价与配煤掺烧数据库中煤耗及掺配比进行计算,生成度电燃料成本标杆库;
统计发电变动成本,生成综合度电成本标杆库。
优选的,所述针对设定的不同运行工况,寻找最优配煤掺烧方案,包括:根据运行机组、负荷以及环境温度,在标杆数据库中寻找历史最优的配煤掺烧方案。
优选的,以煤耗最低为目标,在标杆数据库中寻找历史最优的配煤掺烧方案。
优选的,以综合电度成本最低为目标,在标杆数据库中寻找历史最优的配煤掺烧方案。
本发明所提供的一种燃煤机组的多煤种配煤掺烧寻优方法,按照模糊控制原理建立配煤掺烧数据库;生成综合度电成本标杆库;针对设定的不同运行工况,寻找最优配煤掺烧方案。可见,该方法以日常生产数据为基础,用模糊控制原理建立以煤种配比为控制量,经济发电为输出量,运用信息统计分析能力,以解决电厂生产实践中工况变化复杂、煤种复杂、中储式制粉系统燃煤机组中间环节多,干扰因素复杂的问题,从而解决燃烧经济性不高的问题,降低电厂燃煤成本,提升经济效益。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明所提供的一种燃煤机组的多煤种配煤掺烧寻优方法的流程图;
图2为标杆数据库建立流程图;
图3为配煤掺烧最优方案计算模型流程图;
图4为配煤掺烧标杆数据库寻优模型流程图。
具体实施方式
本发明的核心是提供一种燃煤机组的多煤种配煤掺烧寻优方法,以实现降低电厂燃煤成本。
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参考图1,图1为本发明所提供的一种燃煤机组的多煤种配煤掺烧寻优方法的流程图,该方法包括:
s11:按照模糊控制原理建立配煤掺烧数据库;
s12:生成综合度电成本标杆库;
s13:针对设定的不同运行工况,寻找最优配煤掺烧方案。
可见,该方法以日常生产数据为基础,用模糊控制原理建立以煤种配比为控制量,经济发电为输出量,运用信息统计分析能力,以解决电厂生产实践中工况变化复杂、煤种复杂、中储式制粉系统燃煤机组中间环节多,干扰因素复杂的问题,从而解决燃烧经济性不高的问题,降低电厂燃煤成本,提升经济效益。
基于上述方法,具体的,步骤s11的过程具体包括:将电厂的运行工况进行离散化处理,并按照不同工况进行分组;将不同煤种配比作为输入因子,进行离散化分组处理;记录不同工况和煤种占比对应的供电煤耗,建立配煤掺烧数据库。
其中,电厂的运行工况包括运行机组、负荷和环境温度。
进一步的,步骤s12的过程具体包括:实时调取数字化煤场的各煤种当前煤价信息;将各煤种煤价与配煤掺烧数据库中煤耗及掺配比进行计算,生成度电燃料成本标杆库;统计发电变动成本,生成综合度电成本标杆库。
进一步的,步骤s13的过程具体包括:根据运行机组、负荷以及环境温度,在标杆数据库中寻找历史最优的配煤掺烧方案。
其中,以煤耗最低为目标,在标杆数据库中寻找历史最优的配煤掺烧方案。或者,以综合电度成本最低为目标,在标杆数据库中寻找历史最优的配煤掺烧方案
本方法建立多煤种配煤掺烧寻优模型,用于为火电厂提供一种解决中储式制粉系统燃煤机组煤质复杂、从配煤加仓到发电中间环节多,干扰因素复杂的多煤种配煤掺烧方案的模型。详细的,本方法包括以下三个大的步骤:
步骤一:按模糊控制原理建立配煤掺烧数据库;
其中,模糊控制的应用过程首先是对模糊现象进行识别,从中提炼出精确的控制量,对被控对象进行控制。与经典控制理论和现代控制理论相比,模糊控制的主要特点是不需要给被控对象建立复杂的数学模型。通俗的说模糊控制就是利用计算机模拟优秀的操作人员现场控制的经验,按照经验对被控对象实施最有效的控制。
要确定配煤与发电间的数学模型非常困难,但根据统计学原理,同一班操作员,使用相同设备,在相似工况、相似配煤比条件下,最终的发电结果是符合正态分布的。以此原理作为控制规则,建立配煤掺烧数据库。具体的,建立配煤掺烧数据库包括以下步骤:
(1)将电厂的运行机组、负荷、环境温度等工况进行离散化处理,按不同工况建立分组;
(2)将不同煤种配比作为输入因子,也进行离散化分组处理;
(3)记录不同工况和煤种占比对应的供电煤耗;
(4)在数据库中设定分组,分组条件包括:机组、负荷、真空等工况和煤种占比;
(5)对新加入标杆数据库中的数据进行分组识别,首先判断新加入数据是否为异常数据,非异常数据的可以纳入样本库,异常数据的排除,对应指标的选取特征量,在特征量上进行分组判断,将数据放入对应特征量的分组;
(6)分组统计,得出各组的供电煤耗等指标。同时,当运行产生的数据达到一定规模后,对标杆数据库中的样本数据进行更新,从而将运行条件的变更能够实时反映到数据库中。对不同分组中的样本数据进行经济计算,寻找出综合度电成本最低的标杆数据。标杆数据库中的样本数据中保留距离当前时间最近的100条样本数据。
步骤二:生成综合度电成本标杆库;
具体的,生成综合度电成本标杆库包括以下步骤:
(1)实时调取数字化煤场的各煤种当前煤价信息;
(2)将各煤种煤价与配煤掺烧数据库的煤耗、掺配比进行计算,生成度电燃料成本标杆库;
(3)统计计算其他发电变动成本,生成综合度电成本标杆库。
步骤三:针对设定的不同运行工况,寻找最优配煤掺烧方案。
其中,在寻找配煤掺烧方案过程中包括以下两种情况:
情况一:针对在建立标杆数据库阶段,以及标杆数据库中无该条工况的记录的情况下;
情况二:针对系统运行一段时间后,数据库记录的运行数据较多,且能覆盖机组所有工况的情况下,即机组、负荷、煤种占比,能找到同工况下的历史记录数据。
详细的,情况一的步骤具体包括:在进行掺配前,录入机组负荷计划,即在系统中录入掺配计算周期内的每个时间点的负荷,并形成对应的负荷曲线;其中,以一小时为一个时间点;根据输入的负荷计划,计算该发电量及机组运行在设定的负荷计划下所需耗用的标煤量;根据机组发电阶段制定掺配边界条件,即机组在该发电阶段所需的发热量、硫分、挥发分的边界范围;设定不同原煤仓的煤质约束条件,包括原煤仓的发热量、硫分、挥发分的边界范围;以符合锅炉安全运行(不灭火、不结焦)、环保运行(锅炉排放达标)、原煤仓出力稳定为约束条件,以原煤成本最低/最环保为目标条件,用matlab最优化算法进行配煤方案计算,并根据历史经验做出优化调整;根据制定的配煤方案,进行取煤加仓计算,形成取煤方案;将同一工况下的配煤方案、取煤方案归集为一条数据,记录入标杆数据库,作为该工况下的一条数据。此时,该条数据的煤种占比作为一条新的分组出现,保证了标杆数据库中的煤种占比动态且可扩展。
情况二的步骤具体包括:录入机组负荷计划,即在系统中录入掺配计算周期内的每个时间点的负荷,并形成对应的负荷曲线;其中,以一小时为一个时间点根据机组发电阶段制定掺配的边界条件,即机组在该发电阶段所需的发热量、硫分、挥发分的边界范围;在形成掺配方案的过程中,可根据设定的目标工况,即运行机组、负荷计划、环境温度,在标杆数据库中寻找历史最优的掺配方案。
详细的,提供三套寻优方案,分别是煤耗最低,燃煤度电成本低和综合度电成本最低。
其中,综合度电成本=燃煤度电成本+非煤发电变动成本;
其中,燃煤度电成本=供电煤耗*标煤热值/原煤热值*σ(分煤种原煤单价*分煤种占比);
其中,非煤发电变动成本=液氨度电成本+钢球度电成本+石灰石粉度电成本-干灰度电收入-石膏度电收入
具体的,判断根据目标条件在标杆数据库中能否匹配到多条符合的掺配方案,此时有两种可能的情况如下:
(1)在标杆数据库中不能匹配到同工况下的掺配方案,此时转到情况一中进行配煤掺烧方案的寻优计算,并把得到的方案记录入标杆数据库,作为该目标工况下的一条数据;
(2)匹配到符合该目标工况的多条掺配方案,判断对应的取煤方案在现有的煤场中是否能够重现,当不能重现时,转到情况一进行配煤掺烧方案的寻优计算,当能够重现时,取综合度电成本最低的数据为该工况下的标杆数据。
本方法应用于火电厂燃料全价值寻优系统,所述火电厂燃料全价值寻优系统与火电厂监测信息系统sis系统、企业资源计划erp系统存在数据交互。本方法在选取目标配煤方案时,需要建立标杆数据库的概念,标杆数据库是指将机组运行过程中产生的数据进行记录,并对数据进行分类、筛选、加工、处理、分析和运用。从标杆数据库选出同工况下的历史最优掺配方案作为配煤掺烧寻优的指导依据。在标杆数据库中最优掺配方案选取的过程中,需根据机组、当日负荷计划、环境温度等工况,从标杆数据库中选取历史中同工况的掺配方案,并在得到的掺配方案中选取综合度电成本最低的方案作为最优掺配方案。当出现以下两种情况时,需要以综合度电成本最低为目标通过系统规划求解计算出最优的配煤掺烧方案,第一,在标杆数据库中不能匹配到同工况下的掺配方案,此时按前述的情况一进行配煤掺烧方案的寻优计算,并把得到的方案记录入标杆数据库,作为该目标工况下的一条数据;第二,匹配到符合该目标工况的多条掺配方案,当对应的取煤方案在现有的煤场不能重现时,按前述的情况一进行配煤掺烧方案的寻优计算。本方法得到的配煤掺烧方案不但经济性较高,而且考虑了现有煤场煤质、煤量条件,建立在可实现的基础上,使得所推荐配煤掺烧方案能确保锅炉安全、稳定、经济运行。
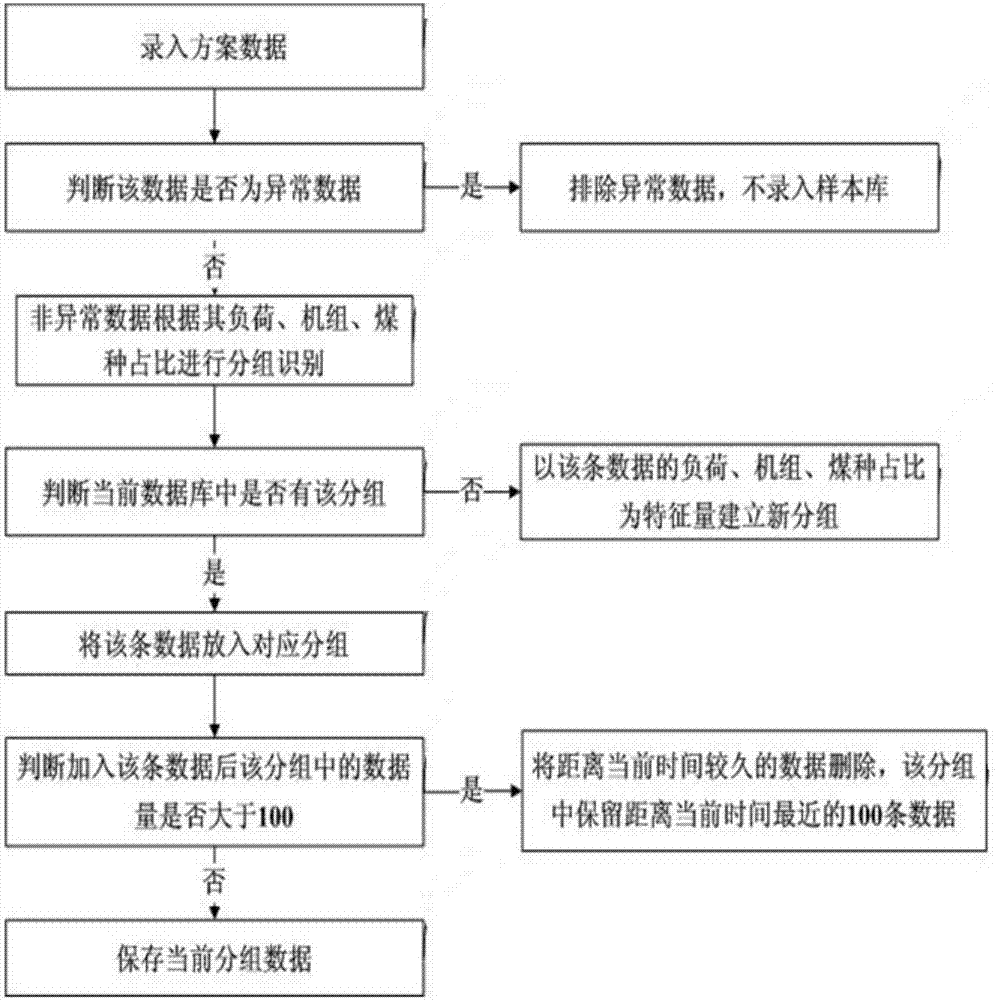
图2为标杆数据库建立流程图,可应用于火电厂的燃煤配煤掺烧系统中,主要用在在标杆数据建立的过程中。标杆数据库建立的流程具体包括如下步骤:
步骤1,将配煤方案、取煤方案归集的一条数据录入标杆数据库;
步骤2,判断该数据是否为异常数据;
步骤3,如果该数据为异常数据,则排除该数据,不录入样本库;
步骤4,如果该数据不为异常数据,则根据该条数据的负荷、机组、煤种占比进行分组识别;
步骤5,首先,判断当前的标杆数据库中是否有该分组;
步骤6,当判定出没有该条分组时,以该条数据的负荷、机组、煤种占比为特征量建立新分组并将该数据保存至该分组;
步骤7,当判定出有该条分组时,将该条数据放入此分组;
步骤8,判断加入该条数据后,该分组中的数据量是否大于100;
步骤9,如果数据量大于100,则需要将距离当前时间较久的数据删除,该分组中保留距离当前时间最近的100条数据;
步骤10,若当前分组数据量未到100条,则保存该分组数据。
图3为配煤掺烧最优方案计算模型流程图,可应用于火电厂的燃煤配煤掺烧系统中,主要用在在标杆数据库中找不到同工况下的数据记录时。配煤掺烧最优方案计算模型的流程具体包括如下步骤:
步骤1,在进行掺配前,录入机组负荷计划,即在系统中录入掺配计算周期内的每个时间点(以一小时为一个时间点)的负荷,并形成对应的负荷曲线;
步骤2,根据输入的负荷计划,计算该发电量及机组运行在设定的负荷计划下所需耗用的标煤量;
其中,发1kwh电量折算为0.1229kg标准煤,每1kg标煤的发热量为29.308kj;
每kwh电量相当热量=0.1229*29307.6==3600kj/kwh;
步骤3,根据机组发电阶段制定掺配边界条件,即机组在该发电阶段所需的发热量、硫分、挥发分的边界范围;
步骤4,设定不同原煤仓的煤质约束条件,包括原煤仓的发热量、硫分、挥发分的边界范围;
步骤5,以符合机组运行、原煤仓约束为条件,以原煤成本最低/最环保为目标条件,用matlab最优化算法进行配煤方案计算;
步骤6,根据制定的配煤方案,进行取煤加仓计算,形成取煤方案;
步骤7,将同一工况下的配煤方案、取煤方案归集为一条数据,记录入标杆数据库,作为该工况下的一条数据。
图4为配煤掺烧标杆数据库寻优模型流程图,可应用于火电厂的燃煤配煤掺烧系统中,主要用在在标杆数据库中有同工况下的数据记录时。配煤掺烧标杆数据库寻优模型流程具体包括:
步骤1,录入机组负荷计划,即在系统中录入掺配计算周期内的每个时间点(以一小时为一个时间点)的负荷,并形成对应的负荷曲线;
步骤2,根据输入的负荷计划,计算该发电量及机组运行在设定的负荷计划下所需耗用的标煤量;
步骤3,根据机组发电阶段制定掺配的边界条件,即机组在该发电阶段所需的发热量、硫分、挥发分的边界范围;
步骤4,在形成掺配方案的过程中,可根据设定的目标条件,即运行机组、负荷计划、环境温度、煤种比例相同的条件下,在标杆数据库中寻找历史最优的掺配方案。
其中,历史最优掺配方案是指同工况(运行机组、负荷计划、环境温度等)下综合度电成本最低的配煤及取煤方案。
判断根据目标条件在标杆数据库中能否匹配到多条符合的掺配方案,此时有两种可能的情况包括:在标杆数据库中不能匹配到同工况下的掺配方案,此时按图3进行配煤掺烧方案的寻优计算,并把得到的方案记录入标杆数据库,作为该目标工况下的一条数据;匹配到符合该目标工况的多条掺配方案,判断对应的取煤方案在现有的煤场中是否能够重现,当不能重现时,按图3进行配煤掺烧方案的寻优计算,当能够重现时,取综合度电成本最低的数据为该工况下的标杆数据。
其中,标杆数据库记录了机组运行过程中产生的所有配煤掺烧方案,一条配煤掺烧方案是指掺配方案与对应的取煤方案的组成的一条数据,由于机组不断运行,更多数据被记录在数据库中,同一工况下的最优掺配方案也在不断更新。数据库中记录的数据可通过燃料配煤掺烧系统与监测信息系统sis、企业资源计划系统erp等系统的数据交互,实现数据导入。
本方法在进行配煤掺烧寻优过程中,通过多煤种配煤掺烧来改变入炉煤质,能有效调节燃煤品质例如调节燃煤发热量、灰分、硫分、挥发分,在入炉煤质符合机组工况、保证锅炉稳定燃烧及排放环保达标的前提下,最大限度地降低燃煤成本,提升电厂经济效益。同时多煤种配煤掺烧技术的使用,扩大了电厂购煤选择范围。
以上对本发明所提供的一种燃煤机组的多煤种配煤掺烧寻优方法进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!