一种国际贸易文件处理方法、系统以及一种服务器与流程
技术领域
本发明涉及文件处理技术领域,特别是国际贸易文件技术领域,具体为一种国际贸易文件处理方法、系统以及一种服务器。
背景技术:
国际贸易中会有大量的贸易文件产生、传递。贸易文件例如:发票、合同、箱单、提单等不仅用于贸易双方的商业约定还用于物流过程中的整个环境,同时进出口口岸的报关报检、银行信用证申请、保险购买、外汇购汇都需要这些贸易文件;这些贸易文件的原件有签字、盖章拥有法律效应,所以在贸易文件流转过程中多由人工处理原件或复印件。
国际贸易涉及货权转移、货款结算、结汇收汇、关税退税、各国海关和商检监管,虽然目前提倡无纸化、电子化但是在贸易、物流、金融等环节流转过程中仍旧使用具有法律效应的原始单证或原始单证扫描件,依旧依靠人工操作和录入。
目前贸易文件在进出口过程中进行报关报检、物流流转等诸多环节中,贸易信息的传递有两种思路:
1、依靠email传递图片格式扫描件、PDF及WORD、EXCEL文件或通过快递递送贸易文件原件,再由外贸服务商进行制单与录入,目前人工的效率为20-30单/天。
2、依靠ERP接口,一些拥有技术能力的货主企业开放ERP接口给外贸服务商,用来传递一部分订单数据。但外贸服务商会有多家而且会更换,而进出口的产品也会不断变化、各国的海关政策也在不断调整,所以基于生产数据而非正式贸易文件的数据不但容易出错,而且数据分发、数据对接存在隐患,况且只是处理了一部分单证,仍旧需要人工处理。
当前,贸易单证文件的录入比较成熟,各大外贸服务企业都有相应的软件;但由于贸易单证是企业之间签订没有固定格式,而且不同地域不同国家的书写习惯、用词都存在差异。海量的国际贸易文件的结构化工作存在处理量大、精度要求高的特点,国内相关研究开展较为迟滞,因而目前继续一种处理海量国际贸易文件的解决措施。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种国际贸易文件处理方法、系统以及一种服务器,用于解决现有技术中无法有效处理海量国际贸易文件的问题。
为实现上述目的及其他相关目的,本发明的实施例提供一种国际贸易文件处理方法,所述国际贸易文件处理方法包括:对图像国际贸易文件和文档国际贸易文件进行分类;识别所述图像国际贸易文件并将识别后的所述图像国际贸易文件和所述文档国际贸易文件统一转换为XML文件;根据所述XML文件附带的文件特征对所述XML文件进行分类;对所述XML文件进行分析处理确定所述XML文件中结构化部分和非结构化部分;对所述非结构化部分中的内容进行边界判别,确定标题区域和内容区域;对所述结构化部分有线框则依据线框,无线框则进行自适应投影;利用最大熵模型进行命名实体识别、根据规则判断句尾和基于本体表格的关系数据抽取,并将国际贸易信息元素以结构体的形式存储,完成国际贸易文件的结构化存储。
于本发明的一实施例中,所述XML文件附带的文件特征包括单词、线框、印签标识的坐标。
于本发明的一实施例中,采用随机森林模型对所述XML文件进行分类。
于本发明的一实施例中,将所述XML文件载入预设的国际贸易知识库,在所述国际贸易知识库中对所述XML文件进行分析处理;其中,根据所述国际贸易知识库中的概念确定所述XML文件中非结构化部分, 根据所述XML文件的表头特征、表底特征来确定所述XML文件中的结构化部分。
于本发明的一实施例中,对所述结构化部分进行处理还包括:当所述XML文件为单页时,根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取;当所述XML文件为多页时,根据相似度匹配判别结构化部分并对判别的结构化部分进行合并后根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取。
本发明的实施例还提供一种国际贸易文件处理系统,所述国际贸易文件处理系统包括:国际贸易文件文件分类模块,用于对图像国际贸易文件和文档国际贸易文件进行分类;识别转换模块,用于识别所述图像国际贸易文件并将识别后的所述图像国际贸易文件和所述文档国际贸易文件统一转换为XML文件;XML文件分类模块,用于根据所述XML文件附带的文件特征对所述XML文件进行分类;结构化确定模块,用于对所述XML文件进行分析处理确定所述XML文件中结构化部分和非结构化部分;非结构化处理模块,用于对所述非结构化部分中的内容进行边界判别,确定标题区域和内容区域;结构化处理模块,用于对所述结构化部分有线框则依据线框,无线框则进行自适应投影;数据处理存储模块,用于利用最大熵模型进行命名实体识别、根据规则判断句尾和基于本体表格的关系数据抽取,并将国际贸易信息元素以结构体的形式存储,完成国际贸易文件的结构化存储。
于本发明的一实施例中,所述XML文件附带的文件特征包括单词、线框、印签标识的坐标。
于本发明的一实施例中,采用随机森林模型对所述XML文件进行分类。
于本发明的一实施例中,所述国际贸易文件处理系统还包括载入模块,用于将所述XML文件载入预设的国际贸易知识库,在所述国际贸易知识库中对所述XML文件进行分析处理;其中,所述非结构化处理模块根据所述国际贸易知识库中的概念确定所述XML文件中非结构化部分, 所述结构化处理模块根据所述XML文件的表头特征、表底特征来确定所述XML文件中的结构化部分。
于本发明的一实施例中,所述结构化处理模块还用于处理:当所述XML文件为单页时,根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取;当所述XML文件为多页时,根据相似度匹配判别结构化部分并对判别的结构化部分进行合并后根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取。
本发明的实施例还提供一种服务器,所述服务器包括处理器和存储器,所述存储器存储有程序指令,其特征在于,所述处理器运行程序指令实现如上所述的方法中的步骤。
如上所述,本发明的一种国际贸易文件处理方法、系统以及一种服务器,具有以下有益效果:
本发明通过将各类国际贸易文件统一转换为XML文件,并对所述XML文件进行分析处理确定所述XML文件中结构化部分和非结构化部分,用最大熵模型进行命名实体识别、根据规则判断句尾和基于本体表格的关系数据抽取,并将国际贸易信息元素以结构体的形式存储,完成国际贸易文件的结构化存储,所以本发明能有效的从图像及电子文件中抽取国际贸易信息,形成贸易信息的结构化数据,有效处理海量国际贸易文件,从而加快报关、报检的制单录入速度,降低企业的贸易成本,提高国际贸易文件的处理准确率。
附图说明
图1显示为本发明的一种国际贸易文件处理方法的流程示意图。
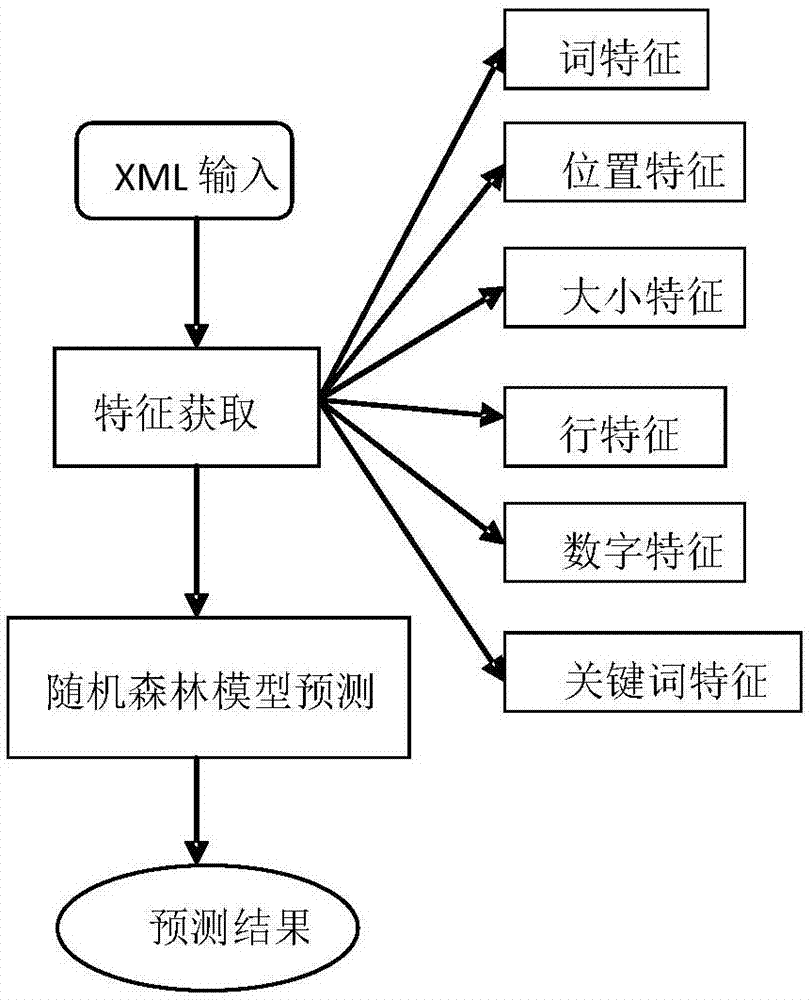
图2显示为本发明的一种国际贸易文件处理方法中文本分类的示意图。
图3显示为本发明的一种国际贸易文件处理方法中文本分类的实例图。
图4显示为本发明的一种国际贸易文件处理方法中数据处理和存储示意图。
图5显示为本发明的一种国际贸易文件处理方法中数据处理和存储的实图。
图6显示为本发明的一种国际贸易文件处理系统的原理示意图。
元件标号说明
具体实施方式
以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效。
请参阅图1至图6。须知,本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。同时,本说明书中所引用的如“上”、“下”、“左”、“右”、“中间”及“一”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
本发明的目的在于提供一种国际贸易文件处理方法、系统以及一种服务器,用于解决现有技术中无法有效处理海量国际贸易文件的问题。本发明的实现原理如下:提取图像与电子文件上每个单词、每条线框、每个印签标识的空间坐标,根据坐标与语义进行判断和处理;模糊判断标题后利用标题作为锚点进行空间切分;结构化部分无线框表格的自适应投影;利用最大熵模型、规则进行命名实体识别和基于本体表格的关系数据抽取。
以下将详细阐述本发明的一种国际贸易文件处理方法、系统以及一种服务器的原理及实施方式,使本领域技术人员不需要创造性劳动即可理解本发明的一种国际贸易文件处理方法、系统以及一种服务器。
如图1所示,本实施例提供一种国际贸易文件处理方法,具体地,在本实施例中,所述国际贸易文件处理方法包括以下步骤:
步骤S101,对图像国际贸易文件和文档国际贸易文件进行分类。
步骤S102,识别所述图像国际贸易文件并将识别后的所述图像国际贸易文件和所述文档国际贸易文件统一转换为XML文件。
将对所述图像国际贸易文件图像的识别结果和所述文档国际贸易文件的电子文件统一转换为统一的XML文件,XML文件中附带每个单词、每条线框、每个印签标识的坐标。
步骤S103,根据所述XML文件附带的文件特征对所述XML文件进行分类。
于本实施例中,所述XML文件附带的文件特征包括但不限于单词、线框、印签标识的坐标。
于本实施例中,采用随机森林模型对所述XML文件进行分类。
具体地,如图2和图3所示,一个xml文件作为输入,先进行特征提取,获取单证的词特征、位置特征、大小特征、行特征、数字特征、关键词特征等,生成特征空间,然后输入预先训练好的随机森林模型(例如使用weka随机森林模型),预测出对应的XML文件类别。
于本实施例中,将所述XML文件载入预设的国际贸易知识库,在所述国际贸易知识库中对所述XML文件进行分析处理。
步骤S104,对所述XML文件进行分析处理确定所述XML文件中结构化部分和非结构化部分。
其中,具体地,根据所述国际贸易知识库中的概念确定所述XML文件中非结构化部分, 根据所述XML文件的表头特征、表底特征来确定所述XML文件中的结构化部分。
于本实施例中,利用启发式算法、编辑距离、最长匹配算法,获取所述XML文件句子中的概念和相对位置关系。
步骤S105,对所述非结构化部分中的内容进行边界判别,确定标题区域和内容区域。具体地,对非结构化中的内容进行边界判别,一个概念到左右概念、上下概念来判别标题区域与内容区域。
步骤S106,对所述结构化部分有线框则依据线框,无线框则进行自适应投影。
具体地,对所述结构化部分,有线框则依据线框,无线框则进行自适应行投影、列投影,当结构化内容为复合式或嵌套式可进行自适应合并与拆分。
于本实施例中,对所述结构化部分进行处理还包括:当所述XML文件为单页时,根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取;当所述XML文件为多页时,根据相似度匹配判别结构化部分并对判别的结构化部分进行合并后根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取。
步骤S107,利用最大熵模型进行命名实体识别、根据规则判断句尾和基于本体表格的关系数据抽取,并将国际贸易信息元素以结构体的形式存储,完成国际贸易文件的结构化存储。
具体地,如图4和图5所示,利用最大熵模型、规则进行命名实体识别和基于本体表格的关系数据抽取,并结合国际贸易知识库搜索引擎将国际贸易信息元素以结构体的形式存储,完成结构化过程。
比如图5中的公司名的识别,先根据关键字找出公司大致位置(红色框内容),将文本放入最大熵模型(例如使用开源工具opennl),最大熵模型根据文本的大小写、字符内容、Ngram等特征计算出最优可能的公司名字符串,如果未匹配到,则根据字典判断公司名后缀,然后向前依次扩展一个单词,与数据库进行对比,直至相似度不再增加。
为实现上述国际贸易文件处理方法,如图6所示,本实施例还提供一种国际贸易文件处理系统100,所述国际贸易文件处理系统100包括:国际贸易文件文件分类模块 101,识别转换模块102,XML文件分类模块103,结构化确定模块104,非结构化处理模块105,结构化处理模块106以及数据处理存储模块107。
于本实施例中,所述国际贸易文件文件分类模块 101,用于对图像国际贸易文件和文档国际贸易文件进行分类。
于本实施例中,所述识别转换模块102用于识别所述图像国际贸易文件并将识别后的所述图像国际贸易文件和所述文档国际贸易文件统一转换为XML文件,其中,所述XML文件中附带每个单词、每条线框、每个印签标识的坐标。
于本实施例中,所述XML文件分类模块103用于根据所述XML文件附带的文件特征对所述XML文件进行分类。
于本实施例中,所述XML文件附带的文件特征包括但不限于单词、线框、印签标识的坐标。
于本实施例中,采用随机森林模型对所述XML文件进行分类。
具体地,如图2和图3所示,一个xml文件作为输入,先进行特征提取,获取单证的词特征、位置特征、大小特征、行特征、数字特征、关键词特征等,生成特征空间,然后输入预先训练好的随机森林模型(例如使用weka随机森林模型),预测出对应的XML文件类别。
于本实施例中,所述结构化确定模块104用于对所述XML文件进行分析处理确定所述XML文件中结构化部分和非结构化部分。
于本实施例中,所述国际贸易文件处理系统100还包括载入模块,用于将所述XML文件载入预设的国际贸易知识库,在所述国际贸易知识库中对所述XML文件进行分析处理;其中,所述非结构化处理模块105根据所述国际贸易知识库中的概念确定所述XML文件中非结构化部分, 所述结构化处理模块106根据所述XML文件的表头特征、表底特征来确定所述XML文件中的结构化部分。
于本实施例中,所述非结构化处理模块105用于对所述非结构化部分中的内容进行边界判别,确定标题区域和内容区域。具体地,对非结构化中的内容进行边界判别,一个概念到左右概念、上下概念来判别标题区域与内容区域。
于本实施例中,所述结构化处理模块106用于对所述结构化部分有线框则依据线框,无线框则进行自适应投影。
具体地,对所述结构化部分,有线框则依据线框,无线框则进行自适应行投影、列投影,当结构化内容为复合式或嵌套式可进行自适应合并与拆分。
于本实施例中,所述结构化处理模块106还用于处理:当所述XML文件为单页时,根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取;当所述XML文件为多页时,根据相似度匹配判别结构化部分并对判别的结构化部分进行合并后根据所述国际贸易知识库中的单元格标题概念和表格表头概念对所述XML文件中的锚点进行信息元素提取。
于本实施例中,所述数据处理存储模块107用于利用最大熵模型进行命名实体识别、根据规则判断句尾和基于本体表格的关系数据抽取,并将国际贸易信息元素以结构体的形式存储,完成国际贸易文件的结构化存储。
具体地,如图4和图5所示,利用最大熵模型、规则进行命名实体识别和基于本体表格的关系数据抽取,并结合国际贸易知识库搜索引擎将国际贸易信息元素以结构体的形式存储,完成结构化过程。
此外本实施例还提供一种服务器,所述服务器包括处理器和存储器,所述存储器存储有程序指令,所述处理器运行程序指令实现如上所述的方法中的步骤。 上述已经对所述方法中的步骤进行了详细描述,在此不再进行赘述。
综上所述,本发明通过将各类国际贸易文件统一转换为XML文件,并对所述XML文件进行分析处理确定所述XML文件中结构化部分和非结构化部分,用最大熵模型进行命名实体识别、根据规则判断句尾和基于本体表格的关系数据抽取,并将国际贸易信息元素以结构体的形式存储,完成国际贸易文件的结构化存储,所以本发明能有效的从图像及电子文件中抽取国际贸易信息,形成贸易信息的结构化数据,有效处理海量国际贸易文件,从而加快报关、报检的制单录入速度,降低企业的贸易成本,提高国际贸易文件的处理准确率。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!