一种基于ARM处理器的玉米lncRNA筛选分类方法与流程
本发明涉及生物信息学研究领域,具体涉及一种基于arm处理器的玉米lncrna筛选分类方法。
背景技术:
rna的二级结构就是指因碱基互补配对,rna自身折叠构成的茎-环结构。因碱基互补配对,rna虽然是单链却会自身折叠在部分区域构成双螺旋结构,使得rna的三维空间结构变得复杂。除典型配对(waston-crick配对,a=u、g≡c)外,还有g=u(wobblebasepairs摆动配对)这种例外情况。g≡c稳定性最高,g=u稳定性最低。二级结构中茎是碱基连续构成配对的地方,按照上述a=u、g≡c、g=u的配对规则构成的双螺旋区域。部分没有形成配对的单链部分为环。
在研究有关rna的问题时,我们通过rna一级序列可以获得有关rna的部分信息,而对rna二级结构的研究可以进一步探索其具有的生物学功能。rna二级结构预测是现在生物信息学领域的焦点问题,发展到今天,已经有许多算法解决这个问题。总结常用的二级结构预测算法有以下4类:动态规划算法,比较序列分析法,组合优化算法,启发式算法。目前使用生物实验方法实现rna二级结构预测耗时耗力,而基于计算方法的预测局限于序列整体结构的准确性,忽略局部结构保守的功能组件,不适用于长序列的预测需求。为满足lncrna二级结构预测的需求,所以提出lncrna分段二级结构预测新方法。
序列比对算法主要有三个,枚举法、动态规划算法、blast算法。枚举法是最容易想到且易理解的一个方法,但是此方法没有任何优化,时间复杂度较高,无法在合理时间内计算。故而枚举法只能理论可行,无法实际应用在较长序列中。动态规划算法是在解决决策问题时的一种最优化的方法。动态规划是在针对最优化问题时,会有多种可行解,所有可行解都有自己的值,寻找最优解的值就是动态规划的作用。其思想是将大问题分割,分别求解后,再将解合并,在求解过程中去除多数不需计算的非最优解,节省很多时间。考虑基于动态规划算法的比对,其时间复杂度正比于两条序列,即计算量相当于计算以两条序列长度建立的二维矩阵。若是可以减少二维矩阵中部分的计算量则可以提升计算速度,blast算法尽量围绕最优比对路径来计算,减少了很多不必要的运算。
技术实现要素:
本发明设计开发了一种基于arm处理器的玉米lncrna筛选分类方法,本发明的发明目的是减少运算时间,提高筛选速度以及筛选准确性的问题。
本发明提供的技术方案为:
一种基于arm处理器的玉米lncrna筛选分类方法,包括如下步骤:
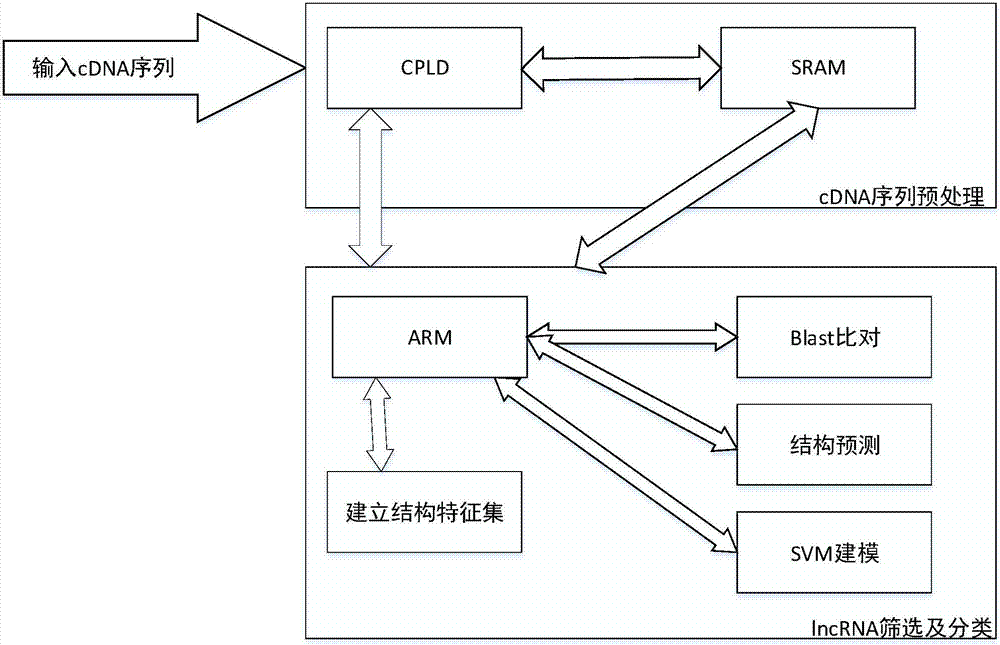
步骤一、将将玉米全长cdna序列输入cpld,其通过编码关联表将cdna序列以编码的形式存储于sram中;
步骤二、筛选长度大于200的cdna序列,对cdna进行开放阅读框预测并确定阈值,确定长度小于所述阈值的cdna,其与已知蛋白作同源比对,对不同源部分进行保留,对已有植物lncrna作二级结构预测,提取二级结构特征,同时对剩余序列作二级结构预测,保留满足结构特征的部分,将待筛选的cdna序列与小rna序列进行比对,排除小rna前体;
步骤三、收集已知功能的玉米lncrna序列,并进行结构预测,对功能lncrna进行结构特征提取并筛选,构建已知功能玉米lncrna结构特征集,将所述步骤二筛选出的玉米lncrna进行二级结构提取,比对所述结构特征集,对所述lncrna功能确认分类。
优选的是,在所述步骤二中,对所述阅读框预测包括如下步骤:预测已有lncrna与编码rna的开放阅读框,依据开放阅读框长短区分编码和非编码,设定开放阅读框长度合理阈值并筛选出小于此阈值的序列。
优选的是,在所述步骤二中,所述小rna包括mirna、shrna、sirna。
优选的是,在所述步骤二中,所述待筛选的序列与所述小rna序列通过blast算法进行比对。
优选的是,在所述步骤二中,对所述lncrna二级结构预测包括如下步骤:
基于转录时间顺序的lncrna分段,各段结构形成的阶段划分,为可能形成的螺旋区进行打分,根据分值差判断最迫切形成的螺旋区,通过动态规划算法获得以螺旋区为单位的二级结构,确定最优结构形成所述预测的lncrna二级结构。
优选的是,所述lncrna分段长度为160nt,每段与前后分段重叠80nt。
优选的是,在所述步骤三中,对所述玉米lncrna序列分类还包括如下步骤:根据碱基对特征算法,对碱基配对的归一化及未形成配对的各碱基数量的归一化进行计算;根基二级结构特征算法,计算最小mfe对序列全长的归一化、二级结构中发夹环的归一化、平均发夹结构在茎区中的碱基配对比、二级结构中环长的归一化等典型特征;对提取的典型特征进行数量上的一致性分析。
优选的是,在所述步骤三中,对所述玉米lncrna序列分类还包括如下步骤:收集已知某一功能所提取的典型特征与确定未有此功能的玉米lncrna;使用svm建模方法,对模型训练并评估;筛选评估排名位于前3名的特征,作为某一功能的特征集。
本发明与现有技术相比较所具有的有益效果:
1、高性能,低功耗,高性价比,高代码密度。目前arm处理器针对嵌入式应用,在满足性能的前提下,也可达到最低功率消耗。其能兼顾到性能、功耗、代码密度及价格几个方面;
2、丰富的芯片。目前,基于arm内核的各种处理器有上百种。用户可以根据各自的应用需求,结合性能,功能等方面考量,选取合适的芯片设计自己的应用系统;
采用arm处理器实现玉米lncrna的筛选分类,不仅可以便于批量处理数据,同时可以兼顾其更高的处理速度,以及更高的准确率,并且可以便于将其固化到高通量lncrna数据采集仪器中,不仅方便快捷,标准化,模块化此筛选过程,且可以减少人工干预。
附图说明
图1为本发明所述的基于arm处理器的玉米lncrna筛选分类方法的流程图。
图2为本发明所述的基于arm处理器的玉米lncrna筛选分类方法的结构示意图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
如图1、图2所示,现有的lncrna的筛选分类方法,首先按照传统的设计规则采集高通量的lncrna数据,然后对其进行筛选分类等。采集lncrna需要用生物实验仪器进行,采用目前方法,不便于与高通量数据采集仪器等相结合,且人工成本高,速度慢,效率低,因此,急需将lncrna分类方法固化到高通量数据采集仪器中,优化lncrna筛选分类;因此,本发明提供了一种基于arm处理器的玉米lncrna筛选分类方法,该方法所需要的硬件设备包括处理器、内存、主板;本发明包括下列步骤:
1、将cdna序列输入cpld;
其中,cpld(complexprogrammablelogicdevice)为复杂可编程逻辑器件,从pal和gal器件发展而来,相对而言规模大,结构复杂,属于大规模集成电路范围,是一种用户根据各自需要而自行构造逻辑功能的数字集成电路。cpld基本设计方法借助集成开发软件平台,用原理图、硬件描述语言等方法,生成相应的目标文件,通过下载电缆(“在系统”编程)将代码传送到目标芯片中来实现设计。pal指可编程阵列逻辑,是70年代末由mmi公司率先推出的一种低密度、一次性可编程逻辑器件。gal为通用阵列逻辑,从pal发展而来,因为采用了eecmos工艺使得该器件的编程非常方便;
2、cpld通过编码关联表将cdna序列以编码的形式存储于sram中。我们依据序列特征和结构特征共同筛选玉米lncrna;
其中,sram是英文staticram的缩写,它是一种具有静止存取功能的内存,不需要刷新电路即能保存它内部存储的数据。我们依据序列特征和结构特征共同筛选玉米lncrna。
3、选用arm微处理器进行玉米lncrna筛选:
1)将玉米全长cdna序列对应的数字化信息,载入到筛选模型中;
2)筛选长度大于200的cdna序列;
3)对cdna进行开放阅读框预测;预测已有lncrna与编码rna的开放阅读框,依据开放阅读框长短区分编码和非编码,设定开放阅读框长度合理阈值,筛选出小于此阈值的序列;
4)将cdna和已知蛋白作同源比对,保留不同源的部分;
5)对已有植物lncrna作二级结构预测,提取二级结构特征;
6)对剩余序列作二级结构预测,保留满足结构特征的部分;
7)将收集的植物mirna(微小rna)、shrna(短发夹rna)、sirna(小干扰rna)等小rna序列存储于sram中,使用blast算法,将待筛选的序列与小rna序列进行比对,删除其中可能的小rna前体;
其中,转录本长度:序列长度200是一个判断是否为长链非编码rna的决定性的特征;orf长度:orf(开放阅读框,openreadingframe)从起始密码子开始,是在dna中有编码蛋白质的潜能、一段没有终止密码子终结的碱基序列。因为密码子读写的起始位点不同,其序列会有六种可能的阅读和翻译(有两条链,每条链有三种);与已知蛋白的同源性:仅仅orf的特征并不一定能表征蛋白质编码的能力,还需要包含与已知蛋白的同源性的特征;
4、选用arm微处理器进行玉米lncrna分类:
1)收集已知功能的玉米lncrna序列,并进行结构预测;
2)对功能lncrna进行结构特征提取并筛选,将筛选的结果输出到lcd液晶显示器;
3)使用svm建模,构建已知功能玉米lncrna结构特征集,负样本为确定不具有此功能的lncrna。同时通过交叉验证法,对结构特征集评估排名,将排名前三的作为最终特征集元素;
4)对未知功能的玉米lncrna进行二级结构提取;
5)比对建立的功能玉米lncrna特征集,看其匹配程度,匹配度高则可预判为具有此功能,以此对未知功能lncrna进行功能特征识别;
6)未知lncrna功能确认实现分类;
其中,碱基对特征:包括碱基配对的归一化及未形成配对的各碱基数量的归一化计算,其可直观的确定结构特征,是最简单的结构特征之一;二级结构特征:包括茎区、内环、发夹环、多分枝环等基本单元的结构特征,以及最小mfe对序列全长的归一化、二级结构中发夹环的归一化、平均发夹结构在茎区中的碱基配对比、二级结构中环长的归一化等典型特征。对典型特征的提取,能够确定各功能lncrna之间结构上的差异,更好的对lncrna进行功能分类。
如图1、图2所示,本发明提供了一种基于arm处理器的玉米lncrna筛选分类方法,包括如下步骤:
步骤一、挖掘出玉米中长链非编码rna的二级结构特征,然后将玉米全长cdna序列输入cpld,用长链非编码rna的序列特征和结构特征作为识别标准寻找可能的长链非编码rna;
步骤二、将cdna序列以编码序列的形式存储于sram中,然后用arm处理器,进行lncrna筛选及分类;
步骤三、根据序列长度进行第一次筛选,获取长度大于200的cdna序列;
步骤四、之后对已有的长链非编码rna进行orf大小的统计分析,设置合理的阈值,根据此特征进行第二次筛选,获取小于此阈值的序列;
步骤五、将上一步识别的数据与已知蛋白做同源比较,进行第三次筛选,获取非同源序列;
步骤六、将收集的小rna序列存储于sram中,使用blast算法,建立比对需要的本地数据库,将待筛选的长链非编码rna作为数据库,而小rna为比对序列,去除其中可能的小rna前体;
步骤七、对已知功能玉米lncrna进行结构分析,利用svm建模建立功能结构特征集,将筛选出的未知功能lncrna进行特征提取;
步骤八、比对已知特征集,最终将匹配度高的lncrna判定为具有该功能,最后将结果输出到lcd液晶显示器。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!