一种基于双流神经网络的人体图像动作识别方法与流程
本发明涉及计算机视觉技术领域,更具体地,涉及一种基于双流神经网络的人体图像动作识别方法。
背景技术:
图像识别一直是计算机视觉中的热门研究领域,而其中的rgb人体图像动作识别,由于容易过拟合、可用于训练模型的代表性数据集较少等原因,一直是研究的重点课题。
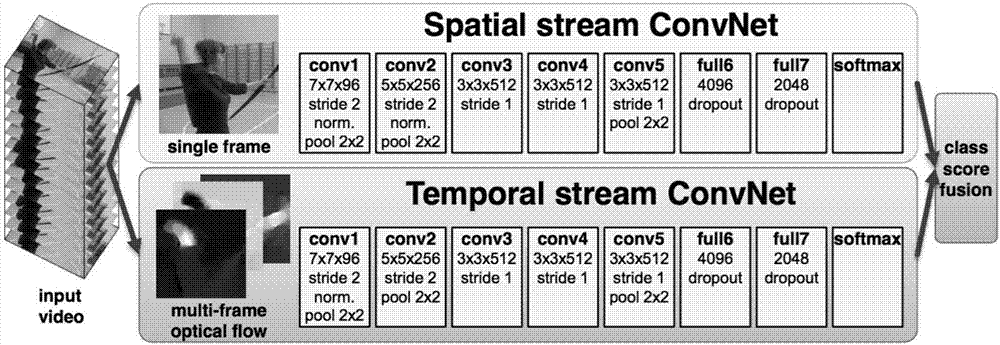
由于单个rgb图像的识别准确率一直难以提升,因此[1]提出了一种新的神经网络模型来进行识别。该模型由两个神经网络组成,第一个为空间神经网络,输入数据为传统的单个rgb图像,第二个为时间神经网络,输入数据为与第一个网络rgb图像对应的光流图,光流图是由两张相邻时刻的rgb图像合成得到,通过计算两张图之间像素点的变化,可以得到一张含有变化信息的光流图,因此光流图可以用来记录时间信息,从而被用于时间神经网络。因此[1]通过两个网络,可以同时得到时间与空间信息,在最后将两者融合并做出最终预测,从而可以更准确地对rgb图像进行识别。接下来在[2]中,对于网络的融合进行了改进。在传统的双流神经网络[1]中,两个神经网络的融合是在最后的输出层,而[2]提出一种新模型,在两个网络的处理过程中就进行融合,经过实验这一方法确实会有更高的准确率。在上述两个模型的处理过程中,对于网络的输入始终仅限于某张图片及其对应的光流图,但并没有考虑更长时间范围内的输入,为了解决这一问题,[3]提出了一种新的模型训练方法,在此方法中,训练网络时的输入不再是单个的rgb图片及其对应的光流图,而是将整个视频切分成帧,设一共有n帧,即n张rgb图片,那么将整个视频分成3段,每段含n/3张图片,从每段中提取一张图片,然后将3段的提取内容结合在一起,再输入到网络中训练模型。由于是从整体的视频帧里提取数据,因此特征会带有全局性,能更好地用于动作识别。
对于传统的双流神经网络,缺点在于虽然模型考虑了时间特征,但此特征仅限于一小段时间以内,但很多人体动作,比如双杠,撑杆跳等,均是由一系列复杂的动作组合而成,如果仅考虑一小段时间,那么可能会仅识别到如挥手,抬腿等基本动作,而错过了真正的动作。而在之后的网络层中间融合的模型也依然没解决该问题。对于[3]提出的算法——时间分割网络(tsn),为全局信息提供了一种新的提取方法,但它的局限性在于,将视频切分后,仅从每一段提取一张图片,得到的信息太过单薄,对于复杂动作而言,可能仍然无法得到足够的时间信息,用来识别当前动作。
[1]simonyan,karen,andandrewzisserman."two-streamconvolutionalnetworksforactionrecognitioninvideos."advancesinneuralinformationprocessingsystems.2014.
[2]feichtenhofer,christoph,axelpinz,andandrewzisserman."convolutionaltwo-streamnetworkfusionforvideoactionrecognition."proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2016.
[3]wang,limin,etal."temporalsegmentnetworks:towardsgoodpracticesfordeepactionrecognition."europeanconferenceoncomputervision.springerinternationalpublishing,2016.
技术实现要素:
本发明针对现有技术无法提取足够的时间信息来进行动作识别的技术缺陷,提供了一种基于双流神经网络的人体图像动作识别方法,该方法能够提取不同粒度的时间段的信息,因此相比传统模型,可以更好地处理长时间的复杂动作,对于rgb人体动作识别整体而言,本发明提供的方法能够更好地提高识别准确率。
为实现以上发明目的,采用的技术方案是:
一种基于双流神经网络的人体图像动作识别方法,包括以下步骤:
s1.构建时间神经网络和空间神经网络;
s2.为时间神经网络和空间神经网络准备足够多的训练视频,然后从训练视频中提取信息对时间神经网络、空间神经网络进行训练,提取信息的步骤如下:
s21.设对视频帧分段的次数为k,k的初始值为1;
s22.将训练视频的视频帧划分为多段,然后分别采集多段视频帧的rgb信息和光流图信息;
s23.令k=k+1然后对每段视频帧执行步骤s22的处理,直至k>a,a为设定的视频分段的次数阈值;
s24.将步骤s2采集的rgb信息输入至空间神经网络中对空间神经网络进行训练,而将步骤s2采集的光流图信息输入至时间神经网络中对时间神经网络进行训练;
s3.分别计算时间神经网络和空间神经网络的损失函数数值,然后判断时间神经网络和空间神经网络的损失函数数值是否小于设定的阈值,若是则结束对时间神经网络和空间神经网络的训练,否则基于时间神经网络和空间神经网络的损失函数数值对时间神经网络和空间神经网络的参数进行迭代更新,然后重复步骤s2对时间神经网络和空间神经网络的训练;
s4.对于测试视频,将其按照步骤s21~s23进行信息的提取,然后将提取的测试视频的rgb信息和光流图信息分别输入至空间神经网络、时间神经网络中,将空间神经网络、时间神经网络的输出融合后得到动作识别结果。
优选地,所述视频帧的光流图信息由视频帧及与视频帧相邻的另一视频帧确定,设视频帧t上的一个像素点为(u,v),则将其移动至视频帧t+1上对应位置的光流向量表示为dt(u,v),视频帧t上的每一个像素点均对应着一个光流向量,通过提取所有像素点的光流向量,即可得到一张与视频帧t对应的光流图。
优选地,所述a设为2。
优选地,所述测试视频提取的rgb信息表示如下:{{s11,s12,……,s1m},{s21,s22,……,s2m},…,{sn1,sn2,……,snm}},其中sij表示第一次划分的第i段里,再次划分后第j段提取的rgb信息,所述训练视频/测试视频提取的光流图信息表示如下:{{s′11,s′12,……,s′1m},{s′21,s′22,……,s′2m},…,{s′n1,s′n2,……,s′nm}},s′ij表示第一次划分的第i段里,再次划分后第j段提取的光流图信息,则步骤s4将提取的测试视频的rgb信息和光流图信息分别输入至空间神经网络、时间神经网络中,空间神经网络、时间神经网络的输出prediction1(v)、prediction2(v′)表示如下:
prediction1(v)
=h1(g(f1(s1,s11,s12,……,s1m),……,fn(sn,sn1,sn2,……,snm)))
prediction2(v′)
=h2(g(f1(s′1,s′11,s′12,……,s′1m),……,fn(sn,s′n1,s′n2,……,s′nm)))
fi函数表示在第一次划分中,将第i段提取的信息s1或s′1融合起来,并加入第i段自身再次划分提取的信息;函数g将各段的信息整合堆叠,形成统一的输入形式,最终输入到空间神经网络或时间神经网络中,函数h1和h2分别代表空间与时间神经网络的网络内计算过程。
优选地,所述将空间神经网络、时间神经网络的输出进行融合的具体过程如下:
prediction(v)=fu(prediction1(v),prediction2(v′))。
优选地,所述步骤s4对时间神经网络和空间神经网络的参数进行迭代更新的具体过程如下:
l(y,h1)和l(y,h2)分别表示空间神经网络与时间神经网络的损失函数,y表示一组向量[0,0,....0,1,0,....,0],当预测类别与真实类别一致时,yi=1,否则为0;h1表示空间神经网络的输出向量,其中h1i表示输出向量关于第i个动作的输出;h2表示时间神经网络的输出向量,h2i其中输出向量关于第i个动作的输出;n代表视频一共有多少种类别。
与现有技术相比,本发明的有益效果是:
本发明提供的方法能够从多层次出发,提取不同粒度的rgb信息和光流图信息,对于同样一段视频,本发明提供的方法可以提取到更多的视频信息用于训练。因此相比传统模型,可以更好地处理长时间的复杂动作,对于rgb人体动作识别整体而言,本发明提供的方法能够更好地提高识别准确率。
附图说明
图1为提取信息的步骤示意图。
图2为提取光流图信息的示意图。
图3为本发明提供的方法与传统的双流神经网络、时间分割网络的对比图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
本发明涉及一种基于双流神经网络的人体图像动作识别方法,包括以下步骤:
s1.构建时间神经网络和空间神经网络;
s2.为时间神经网络和空间神经网络准备足够多的训练视频,然后从训练视频中提取信息对时间神经网络、空间神经网络进行训练,如图1所示,提取信息的步骤如下:
s21.设对视频帧分段的次数为k,k的初始值为1;
s22.将训练视频的视频帧划分为3段,然后分别采集多段视频帧的rgb信息和光流图信息;
s23.令k=k+1然后对每段视频帧执行步骤s22的处理,将每段视频帧再次划分为2段,然后分别采集各段视频帧的rgb信息和光流图信息;
s24.将步骤s2采集的rgb信息输入至空间神经网络中对空间神经网络进行训练,而将步骤s2采集的光流图信息输入至时间神经网络中对时间神经网络进行训练;
s3.分别计算时间神经网络和空间神经网络的损失函数数值,然后判断时间神经网络和空间神经网络的损失函数数值是否小于设定的阈值,若是则结束对时间神经网络和空间神经网络的训练,否则基于时间神经网络和空间神经网络的损失函数数值对时间神经网络和空间神经网络的参数进行迭代更新,然后重复步骤s2对时间神经网络和空间神经网络的训练;
s4.对于测试视频,将其按照步骤s21~s23进行信息的提取,然后将提取的测试视频的rgb信息和光流图信息分别输入至空间神经网络、时间神经网络中,将空间神经网络、时间神经网络的输出融合后得到动作识别结果。
在具体的实施过程中,所述视频帧的光流图信息由视频帧及与视频帧相邻的另一视频帧确定,设视频帧t上的一个像素点为(u,v),则将其移动至视频帧t+1上对应位置的光流向量表示为dt(u,v),视频帧t上的每一个像素点均对应着一个光流向量,通过提取所有像素点的光流向量,即可得到一张与视频帧t对应的光流图。具体如图2所示。
在具体的实施过程中,,所述测试视频提取的rgb信息表示如下:{{s11,s12,……,s1m},{s21,s22,……,s2m},…,{sn1,sn2,……,snm}},其中sij表示第一次划分的第i段里,再次划分后第j段提取的rgb信息,所述训练视频/测试视频提取的光流图信息表示如下:{{s′11,s′12,……,s′1m},{s′21,s′22,……,s′2m},…,{s′n1,s′n2,……,s′nm}},s′ij表示第一次划分的第i段里,再次划分后第j段提取的光流图信息,则步骤s4将提取的测试视频的rgb信息和光流图信息分别输入至空间神经网络、时间神经网络中,空间神经网络、时间神经网络的输出prediction1(v)、prediction2(v′)表示如下:
prediction1(v)
=h1(g(f1(s1,s11,s12,……,s1m),……,fn(sn,sn1,sn2,……,snm)))
prediction2(v′)
=h2(g(f1(s′1,s′11,s′12,……,s′1m),……,fn(sn,s′n1,s′n2,……,s′nm)))
fi函数表示在第一次划分中,将第i段提取的信息s1或s′1融合起来,并加入第i段自身再次划分提取的信息;函数g将各段的信息整合堆叠,形成统一的输入形式,最终输入到空间神经网络或时间神经网络中,函数h1和h2分别代表空间与时间神经网络的网络内计算过程。
在具体的实施过程中,,所述将空间神经网络、时间神经网络的输出进行融合的具体过程如下:
prediction(v)=fu(prediction1(v),prediction2(v′))。
在具体的实施过程中,,所述步骤s4对时间神经网络和空间神经网络的参数进行迭代更新的具体过程如下:
l(y,h1)和l(y,h2)分别表示空间神经网络与时间神经网络的损失函数,y表示一组向量[0,0,....0,1,0,....,0],当预测类别与真实类别一致时,yi=1,否则为0;h1表示空间神经网络的输出向量,其中h1i表示输出向量关于第i个动作的输出,可以简单理解为,当前待预测视频是第i个动作的可能性;h2表示时间神经网络的输出向量,h2i其中输出向量关于第i个动作的输出;其中n代表视频一共有多少种类别。
与传统的双流神经网络不同,本发明提供的方法更加重视从全局角度获取信息,而相比时间分割网络,本发明提供的方法又更加注重对于信息提取的层次。如图3所示。
对于传统的双流神经网络,由于提取信息仅限于视频的一小部分及其对应的一小截光流信息,因此训练模型时的输入信息较为局限。而时间分割网络中,虽然输入信息是根据全视频的长度来采样,但由于提取较为稀疏,因此对于复杂视频,将会遗漏部分信息。而本发明提供的方法具有多层次识别的能力,更进一步地,还可以根据视频类型的不同,定制出不同的网络模型,因此,本发明提供的方法可以极大地提高人体图像识别的准确率。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!