一种适用于多种卷积模式的FIR滤波器实现的制作方法
本发明涉及计算机及电子科学领域,特别涉及深度学习领域卷积神经网络的硬件实现,一种兼容步伐为1卷积计算与步伐为2卷积运算的通用架构及硬件实现。
背景技术:
卷积神经网络(cnn)由于其在图像,音频等领域卓越的表现,如今已成为当前最为流行,且应用最广泛的深度学习算法之一。随着近年来卷积神经网络的飞速发展,大卷积核在模型中的应用已经越来越少,目前各个模型中运用最广泛的是3*3与5*5的卷积运算,并且步伐为2的卷积运算也被越来越多的模型运用到。而针对步伐为2的卷积运算,却一直没有一个很好的硬件实现优化方案。传统的步伐为1的卷积运算可以通过快速fir算法以提高并行度并减少乘法器资源。
一个n抽头的fir滤波器在时域的多项式表示为:
或者在z域中可以表示为
若将长度为n的fir滤波器系数序列{h(n)}作为n维离散卷积的系数,则该fir滤波器可以实现一个n维的卷积运算。通过n个该滤波器的组合,可以实现卷积神经网络中n*n的卷积运算。而快速fir算法可以实现高并行度,以及通过增加加法器而减少乘法器的方法来实现低复杂度。但是该方法对于步长为2的卷积运算并不合适,通过该方法进行计算并选择性的输出来实现步长为2的卷积会带来硬件资源的严重浪费,每个周期内都有约50%的硬件资源对计算结果是无影响的。所以一种既能够实现传统步长为1的卷积运算又能实现步长为2的卷积运算,且具有低复杂度、高并行度、高硬件资源利用率的通用硬件架构将成为一种需求。
技术实现要素:
针对上述问题,本发明提出了一种在快速fir算法框架上既可兼容步长为1又可兼容步长为2的卷积计算架构及其硬件实现。本发明在一种硬件架构上实现了三种计算模式,分别为6抽头6并行卷积计算,三个独立的3抽头3并行卷积运算,以及2个独立的步长为2的3抽头3并行卷积计算。本发明具备高通用性,通过对该硬件架构的不同配置,可以实现大部分当前主流的卷积运算。具体发明内容如下:
一种可适用于多种卷积模式的fir滤波器,其硬件架构包括:
1)数据输入选择单元,针对不同的卷积模式,将输入数据进行重新选择排列输入至相应的卷积计算模块。
2)卷积计算单元,基本组成单元是3并行的3抽头快速fir滤波器,并插入了数据选择器控制数据流来针对不同的卷积运算。
3)卷积后计算单元,对卷积计算单元的的输出进行处理计算从而实现对卷积计算单元内多个独立组成单元的级联,形成一个多并行多抽头的快速fir滤波器。
4)数据输出选择单元,针对不同的卷积模式,选择与其对应的计算结果作为模块输出。
本发明的第二种计算模式为三个独立的3抽头3并行快速fir算法硬件结构,其中3抽头3并行快速fir硬件结构是最基本的组成模块,通过公式推导可得每一个输出y与输入x之间的关系:
y0=h0x0-z-3h2x2+z-3[(h1+h2)(x1+x2)-h1x1]
y1=[(h0+h1)(x0+x1)-h1x1]-[h0x0-z-3h2x2]
y2=[h0+h1+h2)(x0+x1+x2)]-[(h0+h1)(x0+x1)-h1x1]-[(h1+h2)(x1+x2)-h1x1]
而对于步长为2的3抽头3并行卷积运算,可以推导出每一个输出y与输入x之间的关系为:
y0=h0x0+z-6(h2x4+h1x5)
y1=h2x0+h1x1+h0x2
y2=h2x2+h1x3+h0x4
通过乘法器与加法器的复用,并且加入多路复用器的方式将步长为2的卷积运算与快速fir算法相结合,从而实现具有高硬件资源利用率,高并行度,高通用性的卷积运算硬件架构。
附图说明
图1为步长为2的3并行卷积计算硬件结构图。
图2为3抽头3并行快速fir滤波计算硬件结构图。
图3为本发明整体架构图。
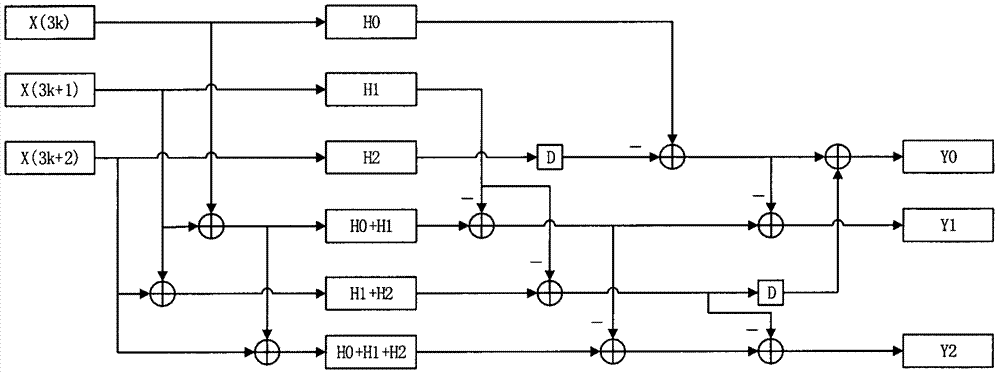
图4为本发明一种适用于多种卷积模式的fir滤波器硬件结构图。
具体实施方式
下面将结合附图对本发明的具体实施作更进一步的说明,步长为2的卷积运算与步长为1的卷积运算在具体实施时有着很大的不同,因为每一次输入的数据与上一次数据间隔为2,这使得用快速fir算法进行并行计算的时候,由于数据的非连续性,使得一半的计算结果都是无用数据。若不使用快速fir算法,由输入与输出的关系:
y0=h0x0+z-6(h2x4+h1x5)
y1=h2x0+h1x1+h0x2
y2=h2x2+h1x3+h0x4
可以得到若将步长为2的卷积运算做成3并行,其硬件结构如图1所示。
该硬件结构一共用到了9个乘法器和6个加法器,每输入6个数据计算得到3个输出,相对于快速fir算法在做到相同并行的条件下,实现了硬件资源的高利用率。
一种快速fir滤波器的硬件结构如图2所示。该硬件结构通过增加加法器减少乘法器的方法来降低硬件实现复杂度并做到了高并行度。对于传统步长为1的卷积运算,该硬件结构可以实现高效的运算。
本发明通过将上述两种硬件结构的融合实现了对步伐为1与步伐为2的卷积运算的高效的支持,在高并行度的前提下具有复杂度低,硬件利用率高,通用性强等特点。图3为本发明的硬件架构,如图该架构包括四个模块:
1)数据输入选择单元,针对不同的卷积模式,将输入数据进行重新选择排列输入至相应的卷积计算模块。
2)卷积计算单元,基本组成单元是3并行的3抽头快速fir滤波器,并插入了数据选择器控制数据流来针对不同的卷积运算。
3)卷积后计算单元,对卷积计算单元的的输出进行处理计算从而实现对卷积计算单元内多个独立组成单元的级联,形成一个多并行多抽头的快速fir滤波器。
4)数据输出选择单元,针对不同的卷积模式,选择与其对应的计算结果作为模块输出。
具体的硬件电路结构如图4所示。本发明通过复用乘法器与加法器并加入多路复用器的方法从而实现了将步长为2的3并行卷积计算硬件结构与三并行快速fir滤波器的融合,在没有增加一个乘法器与加法器的条件下实现了对步伐为2与步伐为1两种卷积模式的兼容。将3个3并行快速fir滤波器级联实现6并行快速fir滤波器。本发明共有三种工作模式可以选择,第一种为3个独立的3并行3抽头快速fir滤波器,通过设置抽头系数h,可以是实现3*3的卷积运算。第二种为2个独立的步长为2的3抽头卷积运算。第三种为单个6并行快速fir滤波器。通过对第三种模式的最后一位抽头系数置0可以实现5*5的卷积运算。只需将数据输入x,抽头系数h,以及工作模式m输入至该硬件电路,本发明会根据输入的模式对x与h进行自动分配,输入至每个子模块进行运算,并将得出的结果通过多路复用器选择与模式相匹配的数据作为结果输出。
当然本发明不仅仅适用于卷积神经网络的计算中,在数字图像处理,数字信号处理,无线通信等领域也有很多适用场景,并且通过乘法器与加法器复用并插入多路复用器的方式对一些其他滤波器的改进可以实现对更多卷积计算模式的匹配。对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中为明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!