具有上下文增强的共享体验的制作方法
视频远程呈现技术使个体能够使用音频和视频来通信。这种技术一般涉及捕获位于第一位置处的第一个体的视频和音频,通过网络将视频和音频传输到位于第二位置处的第二个体,并且将视频和音频输出给第二个体。第一个体也可以接收第二个体的视频和音频。以此方式,个体可以使用相机、显示器屏幕、麦克风、以及其他装备来促进实时会话。然而,视频远程呈现技术经常提供对正被显示的内容的相对较少的见解。
技术实现要素:
本公开描述了用于增强视频内容以加强视频内容的上下文的技术。在一些实例中,视频可以在第一位置处被捕获,并且被传输到视频被输出的一个或多个其他位置。围绕捕获视频的用户和/或察看视频的用户的上下文可以被用来利用附加内容来增强视频。例如,本技术可以处理:与一个或多个用户相关联的语音或其他输入,与一个或多个用户相关联的凝视,针对一个或多个用户的先前会话,由一个或多个用户标识的感兴趣区域,一个或多个用户的理解水平,环境状况等。基于该处理,技术可以确定与视频一起提供的增强内容(例如,视觉、音频等)。增强内容可以以叠加方式与视频一起被显示(或者输出),以加强察看视频的用户的体验。增强内容可以被显示在视频内的特征的位置处。
本公开还描述了用于当视频继续在背景中被显示时维持视频的一部分的显示的技术。在一些实例中,视频可以在第一位置处被捕获并且被传输到第二位置,在第二位置处视频基本上被实时输出。当视频被显示时,用户可以选择将被暂停的视频的一部分。基于该选择,视频帧可以被暂停,而视频的其余部分继续在背景中被呈现。背景视频可以根据与视频帧不同的对焦水平、图像分辨率水平、透明度水平等而被显示。
此发明内容被提供以简化形式介绍一系列概念,这些概念将在以下的具体实施方式中被进一步描述。此发明内容不旨在标识所要求保护的主题内容的关键或者必要特征,也不旨在被用于帮助确定所要求保护的主题内容的范围。例如,术语“技术”可以指代如由上面所述的上下文所允许的并且贯穿本文档的(多个)系统、(多个)方法、计算机可读指令、(多个)模块、算法、硬件逻辑和/或(多个)操作。
附图说明
具体描述参考附图而被描述。在附图中,附图标记最左侧的(多个)数字标识附图标记首次出现在其中的图。不同图中的相同附图标记指示相似或等同项。
图1图示了本文所述的技术可以被实现的示例架构。
图2图示了图1的服务提供商的示例细节。
图3图示了图1的计算设备的示例细节。
图4图示了用来显示与环境相关的增强内容以及与由用户提供的语音输入相关的增强内容的示例界面。
图5图示了用来显示针对通过图像处理来标识的对象的增强内容的示例界面。
图6图示了用来将增强内容显示为动画的示例界面。
图7a-图7c图示了暂停视频的一部分而视频的其余部分在背景中继续的示例过程。
图8图示了用来将注释数据与视频的一部分相关联的示例界面。
图9图示了用来利用内容来增强视频的示例过程。
图10图示了用来当视频在背景中继续被显示时维持视频的一部分和/或用于移除视频的该部分的显示的示例过程。
图11图示了用来将注释数据与视频和/或地理位置相关联的示例过程。
图12图示了用来探索远程环境的示例全景系统。
具体实施方式
本公开描述了用于增强视频内容以加强视频内容的上下文的技术。在一些实例中,视频可以在第一位置处被捕获并且被传输到第二位置,在第二位置处视频被实时输出。围绕捕获视频的用户和/或察看视频的用户的上下文可以被用来利用附加内容来增强视频。例如,技术可以分析各种信息,诸如由用户提供的语音输入、用户的凝视方向、用户的理解水平、被捕获的视频、环境状况、标识感兴趣区域的用户输入等,以标识要与视频一起提供的内容。内容可以以叠加方式在视频上与视频一起被显示,以加强察看视频的用户的体验。
为了说明,当用户移动通过环境时,用户可以使用设备来捕获用户的环境的视频。该设备可以将视频传输到服务提供商,其中视频被发送到远程用户以供察看。服务提供商也可以确定增强内容以添加到视频来加强远程用户的察看体验。这可以包括确定与视频相关联的上下文,诸如捕获视频的用户的上下文,察看视频的用户的上下文,视频的环境的上下文等。然后,服务提供商可以寻找与上下文相关的增强内容,并且提供用于在视频上以叠加方式显示的增强内容。在一个示例中,服务提供商可以处理从正在捕获视频的用户接收的语音输入,以确定用户正在谈论用户环境中的特定对象。然后,服务提供商可以取回与特定对象相关的内容,并且使得该内容在视频上以叠加方式被显示给远程用户。这里,内容可以与视频内对象的位置相关地被显示,并且当对象的位置在视频内变化时与该位置相关地被维持。在另一示例中,服务提供商可以处理与正在察看视频的远程用户相关联的语音输入,以确定用户对视频内所显示的特定对象有兴趣(或者具有关于特定对象的问题),并且提供与特定对象相关的内容。
本公开还描述了用于当视频继续在背景中被显示时维持视频的一部分的显示的技术。在一些实例中,视频可以在第一位置处被捕获并且被传输到第二位置,在第二位置处视频被实时输出。当视频被显示给用户时,用户可以选择将被暂停的视频的一部分。基于此选择,视频的该部分可以被暂停,而视频的其余部分在背景中继续。背景视频可以根据与视频的该部分不同的对焦水平、图像分辨率水平、透明度水平而被显示。这可以使正在察看视频的用户能够检查或者以其他方式察看视频的所选择区域,同时仍然允许视频在背景中继续。
为了说明,当用户移动通过环境时,用户可以使用设备来捕获用户的环境的视频。设备可以将视频传输到服务提供商,其中视频基本上实时地被发送到远程用户。当远程用户察看视频时,用户可以选择视频的特定区域,诸如通过触摸屏、手势输入或者其他输入。服务提供商可以标识当远程用户选择被作出时所显示的帧,以及与视频的区域对应的帧的一部分(或者整个帧)。然后,服务提供商可以使得帧的该部分被暂停,并且当视频在背景中继续时在视频的其余部分上以叠加方式被维持。背景视频可以利用比帧的该部分更少的对焦、更少的图像分辨率、更多的透明度等来显示。此后,服务提供商可以接收信号(例如,来自捕获视频的用户、察看视频的用户,自动信号等)来移除帧的该部分的显示。这种信号可以使得帧的该部分被移除而不被显示,并且从其所在的当前位置继续视频(例如,实时地全屏继续)。
在许多实例中,本文所讨论的技术加强了察看体验。例如,增强内容可以被添加到视频以提供围绕:视频从中被捕获的环境、捕获视频的用户、察看视频的用户等的各种上下文信息。以此方式,察看经增强的视频的用户可能能够更好地理解视频中所描绘的主题内容。此外,这可以消除供用户执行手动搜索以找到与视频相关的内容所需的时间、精力和/或计算资源。附加地或备选地,视频的一部分可以被暂停并且在前景中被维持,而视频在背景中继续。这可以使得察看视频的用户能够检查或以其他方式察看视频的所选择区域,同时仍然允许视频继续被显示。
在一些实例中,技术可以在全景视频的上下文中被实现。即,全景视频可以被捕获和/或显示。与传统视频相比,全景视频可以具有相对宽视角。例如,全景视频可以与大于特定角度的视角相关联(例如,大于90度、120度、150度、180度、210度、240度、270度、300度或者330度)。在一个实施方式中,全景视频表示360度的视角。尽管在其他实例中技术可以在其他类型的视频或图像的上下文中被实现,诸如具有相对窄视角的视频、3维视频(3d)、静止图像等的传统视频。
提供本简要介绍是为了方便读者,而不是旨在限制权利要求的范围,也不是旨在限制前述部分。此外,下文所详细描述的技术可以以多种方式并且在多种上下文中被实现。参考以下附图提供示例实施方式和上下文,如下文中更详细地描述的。然而,以下实施方式和上下文仅是许多示例中的一些示例。
示例架构
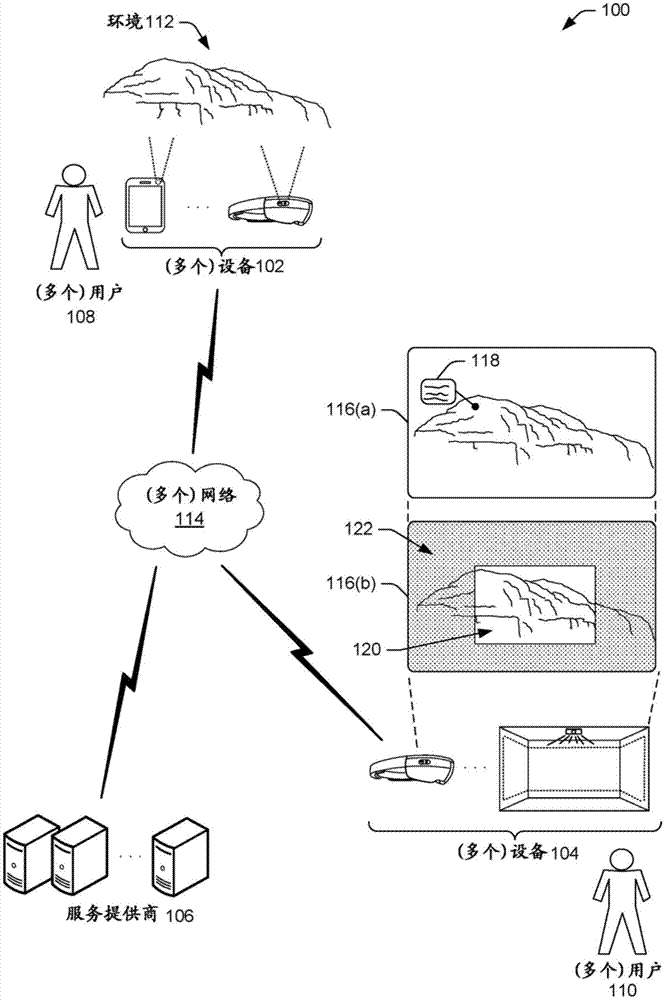
图1图示了本文所述技术可以被实现的示例架构100。架构100包括一个或多个设备102(此后称“设备102”),一个或多个设备102被配置为经由服务提供商106与一个或多个设备104通信(此后称“设备104”)。例如,一个或多个用户108(此后称“用户108”)可以采用设备102与采用设备104的一个或多个用户110(此后称“用户110”)通信。用户108和/或用户110可以通过任何通信模态来通信,诸如文本、触摸、手势、手语、语音等。设备102可以被配置为捕获用户108所位于的环境112(例如,真实世界环境)的数据,并且将数据发送到服务提供商106。服务提供商106可以将数据发送到设备104以用于经由设备104输出。设备104可以类似地捕获用户110所位于的环境的数据,并且经由服务提供商106将数据发送到设备102。设备102、设备104、和/或服务提供商106可以经由一个或多个网络114来通信。一个或多个网络114可以包括多种不同类型网络中的任何一个或组合,诸如蜂窝网络、无线网络、局域网(lan)、广域网(wan)、个人区域网络(pan)、互联网等。
设备102和/或设备104可以包括任何类型的计算设备,诸如膝上型计算机、台式计算机、服务器、智能电话、电子阅读器设备、移动手持机、个人数字助理(pda)、便携式导航设备、便携式游戏设备、视频游戏控制台、平板计算机、手表、便携式媒体播放器、可穿戴设备、耳机、运动感测设备、电视、计算机监视器或显示器、机顶盒、车辆中的计算机系统、应用、相机、机器人、全息系统、安全系统,恒温器、烟雾检测器、对讲机、家庭媒体系统、照明系统、供暖、通风和空调(hvac)系统、家庭自动化系统、投影仪、自动柜员机(atm)等。在一些实例中,可穿戴设备可以包括手表、珠宝、健身跟踪设备等。此外,在一些实例中,耳机可以包括:头戴式显示器(hmd)(例如,光学头戴式显示器(ohmd))、一幅混合现实的头戴式智能眼镜、虚拟现实耳机、音频耳机等。尽管可穿戴设备和耳机被单独描述,但是在一些实例中,可穿戴设备可以包括耳机。此外,在一些实例中计算设备可以被称为移动设备,而在其他实例中计算设备可以被称为固定设备。
同时,服务提供商106可以包括一个或多个计算设备,诸如一个或多个台式计算机、膝上型计算机、服务器等。一个或多个计算设备可以被配置在集群、数据中心、云计算环境或者其组合中。在一个示例中,一个或多个计算设备提供对设备102和/或设备104远程操作的云计算资源,其包括计算资源、存储资源等。
如上所述,设备102和/或设备104可以捕获环境的数据,并且将数据发送到服务提供商106以促进设备102和/或设备104之间的通信。在一些实例中,服务提供商106可以促进实时远程呈现视频会议,而在其他实例中其他类型的技术可以实时地或以其他方式来实现。为了便于在图1的讨论中进行说明,设备102将在向设备104提供视频和其他内容的上下文中被讨论,其中视频和其他内容被输出到用户110。然而,视频和其他内容可以类似地从设备104被提供到设备102以用于向用户108输出。此外,内容可以在任何数目的设备和/或用户之间被提供。
在一些实例中,服务提供商106可以增强被传送到设备102和/或设备104的内容。这种增强可以基于各种上下文,诸如正在捕获视频的用户108的上下文,正在察看视频的用户110的上下文,环境112的上下文等。例如,服务提供商106可以接收来自设备102的与环境112有关的视频、音频、和/或其他内容,并且将视频、音频、和/或其他内容与增强内容相关联。增强内容通常可以添加附加的上下文以加强在察看视频、音频、和/或其他内容时用户110的体验。如图所示,服务提供商106可以经由设备104提供用户界面116,以显示用户108所位于的环境112的视频。在图1的示例中,用户界面116(a)将经增强的内容显示为视频上的标注118。标注118可以包括任何类型的内容,诸如与视频中已经被标识的山峰有关的细节。在此,标注118相对于山峰的位置而被定位,使得用户110可以察看与山峰有关的附加细节。增强处理的进一步细节和示例将在下文中被讨论。
附加地或备选地,服务提供商106可以在视频继续被显示在背景中时,使得视频的一部分被维持。在图1的示例中,用户110已经通过设备104提供触摸输入,以选择视频的区域120。这样,服务提供商106标识当选择被做出时所显示的帧,并且用户界面116(b)暂停与区域120对应的视频帧的一部分。此外,用户界面116(b)继续在背景122中显示视频的其余部分。如图所示,背景122以离焦(例如,模糊方式)来显示视频。这允许用户110以静态方式察看视频的特定部分,并且维持与正由设备102捕获的当前内容有关的至少一些上下文。这可以有助于避免用户110不得不暂停整个视频并且错过设备102处当前发生的情况(例如,在实时内容的情况下)。视频按入处理的进一步细节和示例将在下面被讨论。
示例架构100可以促进各种技术的实施方式。在一些示例中,服务提供商106可以促进虚拟现实(vr)环境和/或混合现实(mr)(例如,增强现实(ar)、增强虚拟等)。在其他示例中,服务提供商106可以促进视频电话会议、视频聊天等。在其他示例中,服务提供商106可以促进广播或者其他形式的分发内容。这样,示例架构100可以实时地、接近实时地、非实时地等来提供内容。
尽管图1的示例架构100包括服务提供商106,但是在一些实例中服务提供商106可以被省略。例如,设备102可以与设备104直接通信。此外,在图1的示例中,环境112表示室外环境。然而,在其他示例中环境112可以表示室内或用户可以位于的任何其他环境。此外,尽管技术可以在增强和/或暂停视频的上下文中被讨论,但是技术可以被实现在其他类型内容的上下文中,诸如静止图像、音频、动画、全息图等。
示例服务提供商
图2图示了图1的服务提供商106的示例细节。服务提供商106可以被配备有一个或多个处理器202、存储器204、和/或一个或多个网络接口206。一个或多个处理器202可以包括中央处理单元(cpu)、图形处理单元(gpu)、微处理器等。存储器204可以包括可由一个或多个处理器202执行以执行特定功能(例如,软件功能)的模块。术语“模块”可以表示用于讨论目的的软件的示例划分,并且不旨在表示任何类型的要求或所需方法、方式或组织。相应地,尽管各种“模块”在本文中被讨论,但是它们的功能和/或类似功能可以被不同地布置(例如,被组合到较少数目的模块中、被分解到较多数目的模块中等)。尽管某些功能和模块在本文中被描述为由可由一个或多个处理器执行的模块实现,但是任何或所有的模块可以完全或者部分地由一个或多个硬件逻辑组件实现,以执行所述功能。例如但不限于,可以被使用的说明性类型的硬件逻辑组件包括:现场可编程门阵列(fpga)、专用集成电路(asic)、应用标准产品(assp)、片上系统(soc)、复杂可编程逻辑器件(cpld)等。如图所示,存储器204可以包括内容提供商模块208、增强模块210、按入模块212、注释模块214、语音识别和自然语言处理(nlp)模块216、以及智能个人助理模块218。
内容提供商模块208可以从设备102和/或设备104接收内容,和/或向设备102和/或设备104提供内容。在一些实例中,内容提供商模块208可以接收来自捕获数据的设备的数据(例如,视频、音频、输入等),并且将数据发送到另一设备。为了说明,内容提供商模块208可以利用增强内容或不利用增强内容来促进两个设备之间的实况视频电话会议。此外,在一些实例中,内容提供商模块208可以取回被存储在环境内容存储库220中的视频内容(或者任何其他环境内容),并且将视频内容(或者其他环境内容)提供给用于输出的设备。环境内容数据存储库220通常可以存储视频、音频、输入、或者从用户所位于的环境捕获的其他数据(也被称为环境内容)。内容提供商模块208还可以将增强内容与从环境中捕获的数据一起或者分别地提供给设备。例如,内容提供商模块208可以使得增强内容以叠加方式被显示在视频内容上。
增强模块210可以确定要与环境内容一起提供的增强内容(例如,从环境中捕获的数据)。为此,增强模块210可以分析各种信息,诸如由用户提供的语音输入、用户的凝视方向、用户的理解水平、正被捕获的视频、环境状况、标识感兴趣区域的用户输入等。基于分析,增强模块210可以标识被存储在增强内容存储库222内、或者在其他位置要与视频一起提供的增强内容。在一些实例中,增强模块210可以执行图像处理(例如,特征检测)来标识在视频或静止图像内的特征。该特征可以包括边缘、角、脊、斑点、对象等。在一些实例中,对象可以与不止一个特征相关联。增强模块210可以使用该特征来标识增强内容。进一步地,内容提供商模块208可以使用该特征以叠加方式(例如,与特征的位置相关地)将增强内容定位在视频上。
在一种图示中,增强模块210可以基于由用户所提供的输入来确定针对视频的增强内容。例如,正在捕获视频的用户108可以在用户108捕获环境112的视频时提供语音或其他输入。语音或其他输入可以讨论环境112内的对象(例如,特定岩石)。增强模块210可以与语音识别模块和nlp模块216协同操作(如下文所讨论的),以确定语音或其他输入是指代该对象。然后,增强模块210可以确定与对象相关的增强内容,诸如,岩石如何被形成的描述、形成岩石的元素的类型等。增强内容可以在环境112的视频被显示给用户110时被显示给用户110。备选地或附加地,增强模块210可以与语音识别模块和nlp模块216协同操作,以确定针对用户110的语音或其他输入是指代视频中的特定对象。增强模块210可以经由设备104类似地标识和提供与对象相关的增强内容。
在另一图示中,增强模块210可以基于用户关于视频或者与视频一起被输出的其他内容(例如,由用户所提供的音频)的理解水平,来确定针对视频的增强内容。例如,增强模块210可以(基于处理由语音识别模块和nlp模块216的语音输入)确定用户108正在以比正在察看环境112的视频的用户110所理解的更详细方式来解释环境112。此处,增强模块210可以确定解释用户108正在陈述的情况的增强内容(例如,提供可以被用户110更好地理解的更高水平概括)。备选地或附加地,增强模块210可以确定用户108正在以比用户110理解环境的水平更不详细的方式解释环境。此处,增强模块210可以确定提供比用户108正在陈述的情况更多细节的增强内容。
被输出的用户关于环境内容的理解水平可以基于各种信息。例如,当前会话、先前会话、或者由用户提供的其他输入或内容可以被分析,以标识词汇使用、句子/段落结构、句子/段落的长度等。在另一示例中,用户简档可以指示用户已经获得的教育、用户所理解的主要或次要语言、针对用户的人口统计学信息、或者关于用户的其他信息。
在又一图示中,增强模块210可以基于针对视频所标识的感兴趣区域,确定针对视频的增强内容。例如,增强模块210可以标识:用户110正在凝视的视频区域,由用户110通过触摸/语音/手势输入所选择的视频区域,用户110正指向的视频区域,被按入的视频区域(例如,为了检查而被暂停)等。备选地或者附加地,增强模块210可以标识与在环境112内用户108正在凝视的位置对应的视频中的区域,和/或与用户108正在指向的位置对应的视频中的区域。在标识感兴趣区域时,增强模块210可以执行图像处理以标识感兴趣区域内的特征,并且然后标识与特征相关的增强内容。
在进一步的图示中,增强模块210可以基于用户的兴趣确定针对视频的增强内容。例如,如果正在察看环境112的视频的用户110对动物有兴趣,并且动物在视频中被标识,则增强模块210可以取回与动物相关的增强内容,诸如与动物有关的细节。备选地或附加地,增强模块210可以类似地基于正在捕获视频的用户(例如,用户108)的兴趣取回要被输出到用户110的增强内容。用户的兴趣可以基于针对用户的用户简档、与用户的先前会话、购买历史等。
在又进一步的图示中,增强模块210可以基于环境状况确定针对视频的增强内容。环境状况可以包括:环境的位置、环境的温度、视频在环境处被捕获时的一天中的时间等。例如,对于沙漠环境的视频,增强模块210可以取回描述沙漠温度的增强内容。
增强内容可以包括任何类型的内容,诸如图像、视频、音频、动画、图形用户界面元素(例如,图标、下拉菜单等)、视觉表示(例如,图形)、广告等。尽管增强内容(也被称为增强数据)被图示为被存储在服务提供商106的存储器204内(例如,在增强内容数据存储库222内),但是在一些实例中服务提供商106从其他源取回增强内容。例如,服务提供商106可以在线搜索以找到与视频内所标识特征(例如,对象)相关的内容。该内容可以作为增强内容而被取回和提供。
按入模块212可以在视频继续在背景中被显示时,使得视频的一部分的显示被维持。例如,当视频经由设备104被显示时,用户110可以选择将被暂停的视频的一部分(例如,通过触摸、文本、手势、或者语音)。按入模块212可以选择当用户110被提供选择时所显示的视频帧。在用户110指定视频中将被暂停的特定区域的实例中,按入模块212还可以标识与所选择区域对应的帧的一部分。在任何情况下,按入模块212可以在视频的其余部分在背景中继续时,使得帧(或帧的部分)被暂停。
在一些实例中,背景视频可以根据与视频帧不同的对焦水平、图像分辨率水平、透明度水平等而被渲染。即,背景视频可以被更改成不同的格式。例如,背景视频可以利用比该帧更低/更大的对焦水平、更低/更大的图像分辨率(例如,空间分辨率、每平方英寸像素数(ppi)等)、和/或更多/更少的透明度来显示。在一些实施方式中,通过显示背景内容中更少的细节,处理资源和/或网络带宽可以被节省。
在一些实例中,诸如当整个帧(或者帧的一部分)被选择要被暂停时,该帧(或帧的部分)可以被收缩或扩大到特定大小。这可以是预定大小或者基于用户输入。附加地或备选地,该帧(或帧的部分)可以被定位在显示器屏幕上的特定位置处(例如,中心、右侧角、左侧角等)。例如,用户可以提供触摸输入以将帧(或者帧的部分)移动到位置。备选地,帧(或帧的部分)可以被自动定位。
按入模块212也可以在事件发生或信号被接收时,移除帧(或者帧的该部分)的显示。当移除帧(或帧的该部分)的显示时,视频可以从当事件发生或信号被接收时视频所处的位置以未经更改的形式(例如,原始格式)继续。作为一个示例,按入模块212可以接收来自设备102和/或设备104的用户输入以结束帧(或帧的部分)的显示。用户输入可以从用户108通过设备108来提供,和/或从用户110通过设备104来提供。用户输入可以包括语音、文本、触摸、手势或任何其他输入。在一些实例中,用户输入可以通过设备102和/或设备104上的按钮(例如,物理按钮)来提供。作为另一示例,按入模块212可以接收来自设备102和/或设备104的触发信号,以结束帧(或帧的部分)的显示。在一些实例中,触发信号在设备102处被生成,并且当事件在设备102处被检测到时被发送给服务提供商106,诸如用户108到达特定地理位置处(例如,旅游的目的地位置、旅游的起始位置、预定位置等),或者接收到与来自用户108的语音输入(例如,指示用户108已经开始再次谈话)相关联的音频信号。当事件在设备102处被检测到时,这可以指示用户108期望将用户110的焦点返回到环境112的视频。在其他实例中,触发信号在设备104处被生成,并且当事件在设备104处被检测到时被发送到服务提供商106,诸如自从发起帧(或帧的部分)的显示以来所经历的一段时间,或者接收到与语音输入(例如,预定命令)相关联的音频信号。当事件在设备104处被检测到时,这可以指示用户110将焦点返回到环境112的整个视频的期望。
注释模块214可以将注释数据与视频相关联。例如,当视频帧被暂停时,用户110可以提供注释数据以与帧相关联。注释数据可以包括图像(例如,用户的图片)、音频、文本、视频、所写入的内容(例如,通过手写笔)或者任何其他内容。注释模块214可以分析被暂停的视频帧,来标识与该帧相关联的地理位置。例如,注释模块214可以标识被包括在视频内的地标的位置。然后,注释模块214可以将注释数据与地理位置和/或视频帧相关联。在一些实例中,这可以允许用户110留下具有特定位置的笔记或其他内容,使得另一用户可以在访问该位置时察看该笔记或其他内容。在一些实施例中,用户可以通过提供用户输入以定位注释数据来将注释数据与视频内的特定对象/特征相关联。例如,用户可以上传注释数据,该注释数据然后可以在显示器屏幕上被察看,并且然后提供触摸输入(或其他形式的输入)以相对于在视频内的特定对象/特征定位该注释数据。注释模块214可以创建特定对象/特征与注释数据之间的链路(包括确定特定对象的地理位置/特征,以及将注释数据与地理位置相关联)。这可以允许其他用户在察看地理位置和/或视频中的特定对象/特征时察看该注释数据。
语音识别和nlp模块216可以将语音转换成文本或另一形式的数据,和/或执行各种操作来处理输入(例如,文本或其他形式的数据)。例如,语音视频和nlp模块216可以接收来自设备102和/或设备104的自然语言输入,并且导出语音输入的含义。语音识别和nlp模块216可以与服务提供商106的任何其他模块协同操作,以促进与自然语言输入(诸如语音输入、文本输入等)相关的各种功能。
智能个人助理模块218可以经由设备102和/或设备104提供智能个人助理。在一些实例中,用户108和/或用户110可以与智能个人助理通信以增强视频内容、暂停视频帧、或者执行其他操作。为了说明,用户110可以执行与智能个人助理的会话,以请求与特定对象相关联的增强内容(例如,“她正在谈论什么”,“请给我提供关于地衣的更多信息”,“她指的是哪个岩画”等)。智能个人助理模块218可以与增强模块210和/或其他模块通信,以将增强内容提供回给用户110。在另一图示中,用户110可以与智能个人助理交谈以暂停视频帧和/或移除视频帧的显示(例如,“暂停该帧”,“返回到实况视频”等)。
示例设备
图3图示了计算设备300(诸如图1的设备102和/或设备104)的示例细节。计算设备300可以包括一个或多个处理器302、存储器304、一个或多个传感器组件306、一个或多个i/o组件308、一个或多个功率组件310、以及一个或多个网络接口312,或者与之相关联。一个或多个处理器302可以包括中央处理单元(cpu)、图形处理单元(gpu)、微处理器等。
一个或多个传感器组件306可以包括:磁力计、环境光传感器、接近传感器、加速度计、陀螺仪、全球定位系统传感器(“gps传感器”)、深度传感器、嗅觉传感器、温度传感器、冲击检测传感器、应变传感器、湿度传感器。
磁力计可以被配置为测量磁场的强度和方向。在一些配置中,磁力计将测量提供给罗盘应用程序,以便向用户提供包括基本方向(北、南、东和西)的参考系中的精确方向。类似的测量可以被提供给包括罗盘组件的导航应用程序。由磁力计获得的测量的其他用途是可预期的。
环境光传感器可以被配置为测量环境光。在一些配置中,环境光传感器将测量提供给应用程序,以便自动调整显示器的亮度来补偿低光和高光环境。由环境光传感器获得的测量的其他用途是可预期的。
接近传感器可以被配置为在没有直接接触的情况下检测靠近计算设备的对象或事物的存在。在一些配置中,接近传感器检测用户身体(例如,用户面部)的存在,并且将此信息提供给利用接近信息来启用或禁用计算设备的一些功能的应用程序。例如,电话应用程序可以响应于接收到接近信息而自动地禁用触摸屏,使得用户的面部在呼叫期间不会无意中结束呼叫或启用/禁用电话应用程序内的其他功能。由接近传感器检测到的接近的其他用途是可预期的。
加速度计可以被配置为测量适当的加速度。在一些配置中,来自加速度计的输出被应用程序用作控制应用程序的一些功能的输入机制。例如,应用程序可以是视频游戏,其中响应于经由加速度计而被接收的输入,角色、其一部分或者对象被移动或者以其他方式被操纵。在一些配置中,来自加速度计的输出被提供给应用程序,以供在横向模式与纵向模式之间切换、计算坐标加速度或者检测降落中使用。加速度计的其他用途是可预期的。
陀螺仪可以被配置为测量以及维持定向。在一些配置中,来自陀螺仪的输出被应用程序用作控制应用程序的一些功能的输入机制。例如,陀螺仪可以被用于精确识别视频游戏应用或一些其他应用的3d环境内的运动。在一些配置中,应用程序利用来自陀螺仪以及加速度计的输入来加强对应用程序的一些功能的控制。陀螺仪的其他用途是可预期的。
gps传感器可以被配置为接收来自gps卫星的信号,以供在计算位置中使用。由gps传感器计算的位置可以由需要或受益于位置信息的任何应用程序使用。例如,由gps传感器计算的位置可以通过导航应用程序来使用,以提供从该位置到目的地的方向、或者从目的地到该位置的方向。此外,gps传感器可以被用来将位置信息提供给外部基于位置的服务。gps传感器可以获得经由利用网络连接组件中的一个或多个来帮助gps传感器获得位置修复的wi-fi、wimax和/或蜂窝三角技术所生成的位置信息。gps传感器还可以被用在辅助gps(“a-gps”)系统中。
一个或多个i/o组件308可以感测个体的或者个体周围的状况。一个或多个i/o组件308可以包括一个或多个面向用户的相机或者其他传感器,以用于跟踪眼睛移动或凝视、面部表情、瞳孔扩张和/或收缩、手势、和/或用户其他特性。在一些示例中,一个或多个i/o组件308可以包括一个或多个面向外部的相机或环境相机,以用于捕获真实世界对象以及个体周围的图像(包括全景图像/视频)。一个或多个i/o组件308可以附加地或备选地包括:一个或多个生物测定传感器(例如,用于测量皮肤电反应的皮肤电反应传感器、心率监测器、用于测量皮肤表面上的温度的皮肤温度传感器、用于测量大脑电活动的脑电图(eeg)设备、用于测量心脏电活动的心电图(ecg或ekg)设备),一个或多个其他相机(例如,网络相机、红外相机、深度相机等),用于测量语音音量、语速等的麦克风或其他声音传感器,光传感器、光学扫描仪等。
附加地和/或备选地,一个或多个i/o组件308可以包括:显示器、触摸屏、数据i/o接口(“数据i/o”)、音频i/o接口组件(“音频i/o”)、视频i/o接口组件(“视频i/o”)、和/或相机。在一些配置中,显示器和触摸屏被组合。在一些配置中,数据i/o组件、音频i/o组件和视频i/o组件中的两个或更多个被组合。i/o组件可以包括离散处理器,离散处理器被配置为支持各种接口,或者可以包括被内置在处理器中的处理功能。
显示器可以是被配置为以视觉形式呈现信息的输出设备。具体地,显示器可以呈现图形用户界面(“gui”)元素、文本、图像、视频、通知、虚拟按键、虚拟键盘、消息传送数据、因特网内容、设备状态、时间、日期、日历数据、偏好、地图信息、位置信息、以及能够以视觉形式被呈现的任何其他信息。在一些配置中,显示器是利用任何有源或无源矩阵技术以及任何背光技术(若被使用)的液晶显示器(“lcd”)。在一些配置中,显示器是有机发光二极管(“oled”)显示器。在一些配置中,显示器是全息显示器。此外,在一些配置中,显示器是全景显示器。此外,在一些配置中,显示器被配置为显示3d内容。其他显示器类型是可预期的。
在至少一个示例中,显示器可以对应于硬件显示器表面。硬件显示器表面可以被配置为,将全息用户界面和其他图形元素与通过硬件显示器表面所见的对象或者在硬件显示器表面上被显示的经渲染的对象图形地相关联。
触摸屏可以是被配置为检测触摸的存在和位置的输入设备。触摸屏可以是电阻触摸屏、电容触摸屏、表面声波触摸屏、红外触摸屏、光学成像触摸屏、色散信号触摸屏、声学脉冲识别触摸屏、或者可以利用任何其他触摸屏技术。在一些配置中,触摸屏作为透明层被结合在显示器顶部,以使用户能够使用一个或多个触摸来与显示器上所呈现的对象或其他信息交互。在其他配置中,触摸屏是被结合在不包括显示器的计算设备的表面上的触摸板。例如,计算设备可以具有被结合在显示器顶部的触摸屏,以及在与显示器相对表面上的触摸板。
在一些配置中,触摸屏是单点触摸屏。在其他配置中,触摸屏是多点触摸屏。在一些配置中,触摸屏被配置为检测离散触摸、单触摸手势和/或多触摸手势。为了方便,这些在本文中被统称为手势。一些示例手势将被描述。应当理解,这些手势是说明性的。此外,所描述的手势、附加的手势、和/或备选手势可以以软件来实现,以供通过触摸屏来使用。这样,开发者可以创建专用于特定应用程序的手势。
在一些配置中,触摸屏支持轻敲手势,其中用户在显示器上所呈现的项目上轻敲触摸屏一次。轻敲手势可以被用来执行各种功能,包括但不限于打开或启动用户轻敲的任何内容。在一些配置中,触摸屏支持双击轻敲手势,其中用户在显示器上所呈现的项目上轻敲触摸屏两次。双击轻敲手势可以被用来执行各种功能,包括但不限于分阶段放大或缩小。在一些配置中,触摸屏支持轻敲和保持手势,其中用户轻敲触摸屏并且至少在预定时间内维持接触。轻敲和保持手势可以被用来执行各种功能,包括但不限于打开特定于上下文的菜单。
在一些配置中,触摸屏支持平移手势,其中用户将手指放置在显示屏上,并且在移动屏幕上手指的同时保持与触摸屏的接触。平移手势可以被用来执行各种功能,包括但不限于以受控速率移动屏幕、图像或菜单。多点手指平移手势也是可预期的。在一些配置中,触摸屏支持轻拂手势,其中用户在用户希望屏幕移动的方向上滑动手指。轻拂手势可以被用来执行各种功能,包括但不限于水平地或垂直地滚动通过菜单或页面。在一些配置中,触摸屏支持捏紧和伸展手势,其中用户在在触摸屏上利用两个手指(例如,拇指和食指)进行捏紧动作或者将两个手指分离。捏紧和伸展手势可以被用来执行各种功能,包括但不限于逐渐放大或缩小网站、地图、或图片。
尽管上述手势已经参考用于执行手势的一个或多个手指的使用而被描述,但是诸如脚趾的其他附属物或者诸如手写笔的对象可以被用来与屏幕交互。这样,上述手势应当被理解为是说明性的,而不应当被解释为以任何方式受限制的。
数据i/o接口组件可以被配置为促进将数据输入到计算设备,以及将数据从计算设备输出。在一些配置中,数据i/o接口包括连接器,该连接器被配置为提供计算设备与计算机系统之间的有线连接,例如用于同步操作目的。连接器可以是专用连接器或标准化连接器,诸如usb、微型usb、迷你型usb等。在一些配置中,连接器是用于将计算设备与诸如对接站、音频设备(例如,数字音乐播放器)或视频设备的另一设备对接的对接连接器。
音频i/o接口组件被配置为向计算设备提供音频输入和/或输出能力。在一些配置中,音频i/o接口组件包括被配置为采集音频信号的麦克风。在一些配置中,音频i/o接口组件包括被配置为提供用于耳机或其他外部扬声器的连接的耳机插孔。在一些配置中,音频i/o接口组件包括用于音频信号的输出的扬声器。在一些配置中,音频i/o接口组件包括光学音频电缆出口。
视频i/o接口组件被配置为向计算设备提供视频输入和/或输出能力。在一些配置中,视频i/o接口组件包括视频连接器,视频连接器被配置为从另一设备(例如,视频多媒体播放器诸如dvd或蓝光播放器)接收视频作为输入,或者向另一设备(例如,监视器、电视、或一些其他外部显示器)发送视频作为输出。在一些配置中,视频i/o接口组件包括高清晰度多媒体接口(“hdmi”)、迷你型hdmi、微型hdmi、displayport、或者用于输入/输出视频内容的专用连接器。在一些配置中,视频i/o接口组件或其多个部分与音频i/o接口或其多个部分组合。
相机可以被配置为捕获静止图像和/或视频。相机可以利用电荷耦合器件(“ccd”)或者互补金属氧化物半导体(“cmos”)图像传感器来捕获图像。在一些配置中,相机包括帮助在低光环境中拍摄图片的闪光灯。针对相机的设置可以被实现为硬件或软件按钮。由相机捕获的图像和/或视频可以附加地或备选地被用来检测非触摸手势、面部表情、眼睛移动或用户的其他移动和/或特性。
尽管未被图示,但是一个或多个硬件按钮也可以被包括在设备300中。硬件按钮可以被用于控制设备300的一些操作方面。硬件按钮可以是专用按钮或多用途按钮。硬件按钮可以是机械的或者基于传感器的。
一个或多个功率组件310可以包括一个或多个电池,该一个或多个电池可以被连接到电池量表。电池可以是可充电的或一次性的。可充电电池包括但不限于:锂聚合物、锂离子、镍镉和镍金属氢化物。每个电池可以由一个或多个单元制成。
电池量表可以被配置为测量电池参数,诸如电流、电压和温度。在一些配置中,电池量表被配置为测量电池放电率、温度、年龄以及其他因素的影响,来预测一定百分比误差内的剩余寿命。在一些配置中,电池量表向应用程序提供测量,该应用程序被配置为利用测量向用户呈现有用的功率管理数据。功率管理数据可以包括所使用的电池百分比、电池剩余的百分比、电池状况、剩余时间、剩余容量(例如,以瓦时为单位的)、电流消耗、以及电压。
一个或多个功率组件310也可以包括功率连接器,功率连接器可以与前述i/o组件中的一个或多个组合。一个或多个功率组件可以经由功率i/o组件与外部功率系统或充电装备进行接口。
存储器304(以及服务提供商106的存储器204和本文所描述的所有其他存储器)可以包括一个计算机可读介质或计算机可读介质的组合。计算机可读介质可以包括计算机存储介质和/或通信介质。计算机存储介质包括以用于存储信息(诸如计算机可读指令、数据结构、程序模块、或者其他数据)的任何方法或技术实现的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于:相变存储器(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、电阻随机存取存储器(reram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、闪存或其他存储器技术、光盘只读存储器(cd-rom)、数字通用光盘(dvd)或其他光存储装置、磁带盒,磁带、磁盘存储装置或其他磁存储设备、或者可以被用来存储供计算设备访问的信息的任何其他非传输介质。
相比之下,通信介质可以体现计算机可读指令、数据结构、程序模块、或者经调制的数据信号(诸如载波或其他传输机制)中的其他数据。如本文所定义的,计算机存储介质(也被称为“计算机可读存储介质”)不包括通信介质。
如图所示,存储器304可以包括客户端应用314,以促进各种处理。例如,客户端应用314可以与服务提供商106的模块208-218中的任何模块通信以促进本文所讨论的功能。附加地或备选地,客户端应用314可以提供用户界面。
此外,存储器304可以包括凝视跟踪模块316,以跟踪个体的凝视。在各种实施方式中,凝视跟踪模块316可以获得个体的至少一个眼睛的图像,并且分析图像以确定个体的眼睛位置。个体的眼睛位置可以被用来确定个体的凝视路径。在具体实施方式中,个体的眼睛位置可以被用来确定个体观看的方向。在一些情况下,个体的凝视路径可以被近似为进入到场景中的锥形视场或者三棱柱形视场。
凝视跟踪模块316也可以标识被包括在个体的凝视路径中的对象。在具体实施方式中,凝视跟踪模块316可以获得指示被包括在个体正在察看的环境中的对象的位置的信息。在一些情况下,凝视跟踪数据模块316可以获得环境的图像,并且利用环境的图像来确定被包括在环境中的对象的位置。在说明性示例中,凝视跟踪数据模块316可以确定被包括在环境中的对象与环境的参考点之间的距离。另外,凝视跟踪数据模块316可以确定被包括在环境中的对象与察看该环境的个体之间的距离。凝视跟踪数据模块316可以确定个体的凝视路径与环境中一个或多个对象的位置之间的重叠。被包括在个体的凝视路径中的一个或多个对象可以被指定为凝视目标。
示例界面
图4-图8图示了可以被提供来实现本文所讨论的技术的示例界面。尽管特定技术可以参考特定附图而被讨论,但是特定技术可以参考附图中的任何附图而被执行。为了便于说明,图4-图8的界面被讨论为在图1的架构100的上下文内被提供。特别地,当用户108采用设备102来捕获环境112的环境内容(例如,视频、音频等)时,界面被讨论为经由设备104被提供给用户110。然而,界面可以备选地或附加地被提供给用户108和/或被提供在其他上下文中。
图4图示了示例界面400,示例界面400用来显示与环境112相关的增强内容402以及与由用户108和/或用户110所提供的语音输入相关的增强内容404。在该示例中,当环境112的视频406正在被捕获并且提供给用户110时,用户108正在与用户110进行会话。如图所示,视频406可以经由界面400而被呈现。另外,增强内容402和/或增强内容404可以在视频402上以叠加方式被提供。
增强内容402可以与环境112的环境状况相关,诸如环境112的地理位置、环境112的温度、视频406正在被捕获时的一天中的时间等。例如,服务提供商106可以使用由设备102提供的位置数据来提供用户108的位置(例如,峡谷地国家公园)。服务提供商106也可以使用图像处理来提供正在被拍摄的对象的位置(例如,视频406中岩石结构的经度和纬度)。增强内容402还可以包括从设备102上的温度传感器和/或另一源(例如,在线资源)获取的环境112的温度。
同时,增强内容404可以与从用户108和/或用户110所接收的语音输入相关。例如,当用户108移动通过环境112时,用户108可能正提供对地衣的相当详细的讨论。服务提供商106可以确定(正在察看视频406的)用户110可能无法完全理解用户108所提供的语音(例如,与用户110相比,用户108可能具有针对正被讨论的主题的更高教育水平,用户110可能问出问题-“她指的是什么?”等)。这样,服务提供商106可以利用增强内容404来增强视频406以提供对地衣的更简化的讨论(即,“她的意思是:地衣像胶一样将土壤固定到位”)。在此,增强内容404被显示有指向视频406上地衣所位于的位置处的标注。位置可以通过对视频406执行图像处理而被确定。
图5图示了示例界面500,示例界面500用来显示针对通过图像处理而被标识的对象的增强内容502。具体地,当用户108移动通过环境112并且发现具有岩画的岩石504时,服务提供商106可以分析环境112的视频506以标识用户108和/或110可能感兴趣的岩画508。例如,服务提供商106可以对视频506的中心区域、用户108和/或用户110正在观看的视频506的区域、和/或视频506的另一区域执行图像处理。图像处理可以标识岩画508。附加地或备选地,服务提供商106可以确定用户108和/或用户110正在讨论特定类型的岩画(例如,马)。这样,服务提供商106可以使得增强内容502被呈现在视频506上,并且被锚定到岩画508的位置。如图所示,增强内容502可以提供关于岩画508的信息。
图6图示了示例界面600,示例界面600用来将增强内容602显示为动画。在此,服务提供商106已经标识出描绘环境112内的岩石是如何被形成的动画。增强内容602可以从各种源获得,包括与环境112相关联的在线站点(例如,针对峡谷地国家公园的网页)。增强内容602可以示出150万年前其最初形成时的环境112,以及随着时间继续到当前时间点而改变形式。如图所示,图标604可以被呈现以示出正在被呈现的年份。
界面600还可以显示指示可以被探索的位置606的增强内容。位置606可以表示在环境112内的相机的位置。例如,正在察看界面600的用户110可以选择位置606(a),并且被转换到位于所选择位置606(a)的相机以进一步从不同视角探索环境112。在一些实例中,位置606表示具有相机的其他用户的位置。在此,位置606可以随着用户在环境112内移动而移动。在其他实例中,位置606表示网络相机或其他类型相机(例如,通过公园来定位的网络相机、交通相机等)的静止位置。服务提供商106可以取回与相机的位置606有关的信息(例如,具有相机的用户的gps信息、针对网络相机的地理数据等),并且执行对视频的图像处理来将增强内容定位在适当位置。
图7a-图7c图示了当视频在背景中继续时暂停视频的一部分(例如,视频的该部分的拷贝)的示例过程700。在图7a的702处,界面704可以(例如,随着视频被捕获而实时地)向用户110显示环境112的视频。在702处当视频被显示时,用户110可以选择视频的区域706来暂停。在该示例中,该选择通过经由界面704的触摸输入而被做出,然而在其他示例中其他类型的输入可以被提供。
在选择区域706时,如图7b中708处所示,视频的区域706可以被暂停。即,视频的区域706的拷贝可以被创建并且在前景中被显示。如图所示,视频的区域706可以以原始格式被显示(例如,当内容在702处被显示时),而视频的其余部分可以以不同格式在背景710中实时地继续。例如,背景710中的视频可以利用不同的对焦水平(例如,比区域706更加离焦或者聚焦)、不同水平的图像分辨率(例如,具有比区域706更少或更多的图像分辨率)、不同水平的透明度(例如,比区域706更不透明或透明)等而被显示。在该示例中,背景710中的视频被模糊化,而区域706被维持其最初所呈现的状态。
在图7c的712处,视频可以在区域706保持静止(例如,区域706内的视频的拷贝保持静止)时在背景710中继续。即,与区域706对应的视频帧的一部分可以在界面704中被维持,而视频以模糊方式在背景710中继续实时显示内容。如图所示,背景710中的视频已经被转移到左边。这可以使用户110能够进一步检查视频的区域706,而不丢失实况视频中正在发生的情况的上下文。
尽管未被图示,但是在某个时刻信号可以被接收以结束区域706的显示,并且视频可以从其当前所在的位置继续(例如,显示实况馈送)。换句话说,视频的实况馈送可以返回到以原始格式被显示,而不模糊化和/或包含整个显示屏。备选地,视频可以从输入被接收以暂停视频的区域706时视频的位置继续。
在一些实例中,服务提供商106可以在用户110选择区域706时,分析区域706以用于增强内容。例如,在用户110提供标识区域706的输入之后的过程700期间的任何时间,服务提供商106可以对区域706内的视频执行图像处理,并且标识与区域706内的对象相关的增强内容。
图8图示了示例界面800,示例界面800用来将注释数据与视频的一部分相关联。如图所示,界面800可以以模糊方式显示前景中的视频的静止部分802,以及背景804中的实况视频。在此,界面800可以被显示给用户110。在视频的静态部分802正被显示时、或者在任何其他时间,用户110可以提供注释数据806来与视频的静态部分802相关联。在该示例中,用户110(名为michelle)向用户108(名为sarah)提供注释以感谢她带她参观环境112。注释数据806可以与正被显示的地理位置(例如,静态部分802的地理位置)相关联。换句话说,注释数据806可以被存储在数据存储库中,该数据存储库具有与表示地理位置的数据的关联。这可以允许访问该地理位置的其他人察看注释数据806。附加地或备选地,注释数据806可以在注释数据806被接收时和/或在稍后的时间被实时地提供给用户108。
示例过程
图9、图10和图11图示了用于采用本文所描述的技术的示例过程900、1000和1100。为了便于说明,过程900、1000和1100被描述为正在图1的架构100中被执行。例如,过程900、1000和1100的各个操作中的一个或多个操作可以由设备102、服务提供商106、和/或设备104执行。然而,过程900、1000和1100可以在其他架构中被执行。此外,架构100可以被用来执行其他过程。
过程900、1000和1100(以及本文所描述的每个过程)被图示为逻辑流程图,逻辑流程图中的每个操作表示可以以硬件、软件、或者其组合来实现的操作序列。操作被描述的顺序并非旨在被解释为限制,并且任何数目的所述操作可以以任何顺序和/或并行地被组合以实现该过程。此外,各个操作中的任何操作可以被省略。在软件的上下文中,操作表示被存储在一个或多个计算机可读介质上的计算机可执行指令,计算机可执行指令当由一个或多个处理器执行时将一个或多个处理器配置为执行所叙述的操作。通常,计算机可执行指令包括执行特定功能或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。在一些实例中,在硬件的上下文中,操作可以整个地或部分地由一个或多个硬件逻辑组件实现,以执行所描述的功能。例如但不限于,可以被使用的说明性类型的硬件逻辑组件包括:现场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、片上系统(soc)、复杂可编程逻辑器件(cpld)等。
图9图示了利用内容来增强视频的示例过程900。
在902处,计算设备(例如,设备102、服务提供商106、和/或设备104)可以接收来自第一设备的视频。这可以包括在第一设备捕获视频时接收来自第一设备的视频。视频可以表现第一设备所位于的环境。在一些实例中,视频包括全景视频。
在904处,计算设备可以确定与捕获视频相关联的第一用户的上下文,和/或与视频的显示相关联的第二用户的上下文。该上下文可以基于由第一用户或第二用户提供的语音或其他输入(例如,指示相应用户正在谈论什么),针对第一用户或第二用户的凝视信息(例如,指示相应用户正在看哪里),第一用户或第二用户的先前会话,与第一用户或第二用户相关联的用户简档,第一用户或第二用户的理解水平,由第一用户或第二用户所指示的视频内的感兴趣区域,第一用户或第二用户的兴趣等。
在906处,计算设备可以对视频执行图像处理。这可以包括分析视频的一个或多个帧来标识特征和/或贯穿一个或多个帧跟踪特征。在一些实例中,图像处理可以分析由第一用户或第二用户所指示的感兴趣区域。
在908处,结算设备可以确定环境(例如,正在被拍摄的环境)的环境状况。环境状况可以包括:环境的位置、环境的温度、视频在环境处被捕获时的一天中的时间等。
在910处,计算设备可以确定针对视频的增强内容。该确定可以基于与捕获视频相关联的第一用户的上下文,与显示视频相关联的第二用户的上下文,环境状况、视频内所标识的特征等。在一些实例中,操作910可以包括在线搜索以找到内容和/或从与内容相关联的源取回内容。在其他实例中,操作910可以取回被本地存储或在其他地方被存储的内容。如果内容被在线找到,则在一些示例中计算设备可以在将内容提供为增强内容之前概括或以其他方式处理内容。
在912处,计算设备可以使得增强内容与视频被一起显示。这可以包括指示第二设备来显示视频和/或增强内容。备选地,这可以包括显示视频和/或增强数据。增强内容可以在视频中的特征的位置处以叠加方式被显示在视频上。此外,在很多实例中,当特征的位置在视频内变化时,增强内容可以被维持与该特征相关。
图10图示了示例过程1000,示例过程1000用来在视频继续在背景中被显示时维持视频的一部分和/或移除视频的该部分的显示。
在1002处,计算设备可以接收来自第一设备的视频。这可以包括在视频由第一设备捕获时接收视频。
在1004处,计算设备可以经由第二设备引起视频的显示。这可以包括将视频发送到第二设备以用于显示、或者经由第二视频直接显示视频。
在1006处,计算设备可以接收用户输入(或者指示)来暂停视频。
在1008处,计算设备可以确定与用户输入(或指示)相关联的视频帧。这可以包括标识当用户输入被接收时所显示的视频帧。
在1010处,计算设备可以确定与所选择区域对应的帧的一部分。在一些实例中,当用户输入标识要暂停的视频的特定区域时,操作1010被执行。这样,操作1010可以在一些实例中被省略。
在1012处,当视频在背景中继续时,计算设备可以引起帧(或者帧的该部分)的显示。例如,帧(或帧的一部分)的第二实例可以被创建/复制并且在前景中被显示,而实况视频继续在背景中显示。操作1012可以包括指示第二设备在前景中显示帧(或帧的部分),并且在背景中继续显示视频的其余部分。备选地,操作1012可以包括在前景中显示帧(或帧的部分),并且在第二设备上的背景中继续显示视频的其余部分。在一些实例中,帧(或帧的部分)可以根据第一显示特性而被显示,并且背景中的视频根据不同的第二显示特性而被显示,诸如不同的对焦水平、图像分辨率水平、和/或透明度水平。这样,操作1012可以暂停视频的一部分(例如,视频的该部分的拷贝),而视频在背景中继续显示。在一些实例中,操作1012可以包括平滑在背景和/或前景中所显示的视频内的内容的移动(例如,移除抖动、生硬移动等)。
在1014处,计算设备可以接收信号以结束帧(或帧的该部分)的显示。信号可以从捕获视频的第一设备和/或呈现视频的第二设备被接收。信号可以包括请求帧(或帧的部分)的显示结束的用户输入,在检测到事件时所生成的触发信号(例如,到达特定位置,接收到与语音输入相关联的音频信号,所经历的时间段等)等。
在1016处,计算设备可以确定结束帧(或帧的该部分)的显示。操作1016可以响应于在操作1014处接收到信号或者响应于其他确定而被执行。
在1018处,计算设备可以移除帧(或帧的该部分)的显示。这可以包括指示呈现帧(或帧的该部分)的第二设备结束呈现或者直接移除帧(或帧的该部分)的呈现。
图11图示了示例过程1100,示例过程1100用来将注释数据与视频和/或地理位置相关联。
在1102处,计算设备可以接收注释数据。注释数据可以包括任何类型的内容,诸如图像、音频、输入、视频等。
在1104处,计算设备可以在注释数据被接收时确定当前正在被呈现的视频的一部分(例如,正在被呈现的已暂停的帧)。
在1106处,计算设备可以确定与视频的该部分相关联的地理位置。这可以包括引用gps或者与正捕获视频的设备相关联的其他位置数据,执行图像处理来标识视频中的特征以及特征的对应地理位置等。
在1108处,计算设备可以将注释数据与视频(例如,视频的该部分)和/或地理位置相关联。在一些实例中,当注释数据与地理位置相关联时,个体可以在探索该地理位置时访问注释数据(例如,在虚拟现实或混合现实上下文中)。
示例全景系统
图12图示了用来探索远程环境的示例全景系统1200。全景系统1200可以包括各种装备(诸如上文参考图3所讨论的组件中的任何组件),以促进用户1202的全景体验。在该示例中,全景系统1200包括触摸表面1204,以使用户1202能够在远程环境中导航。例如,用户1202可以用手或手指来触摸该触摸表面1204,以及从一侧滚动到另一侧或者上下滚动。这可以使得远程环境的定向变化。为了说明,如果用户1202以右向左的动作提供触摸输入,则全景系统120可以移动视频或静止图像内容,使得位于用户1202的右侧上的内容现在面向用户1202的左侧被移动。如图所示,全景系统1200还包括投影仪1206,投影仪1206用来将视频和/或静止图像内容投影到全景系统1200内的墙壁、地板和/或天花板上。在一些实例中,全景系统1200可以使用户1202能够探索远程环境。
示例条款
示例a,一种方法,包括:由一个或多个计算设备接收来自第一设备的全景视频,全景视频表示第一设备所位于的环境;由一个或多个计算设备确定与第一设备相关联的第一用户或者与被指定接收全景视频的第二设备相关联的第二用户中的至少一个的上下文;至少部分地基于上下文,并且由一个或多个计算设备确定与全景视频中的特征相关的增强内容;以及由一个或多个计算设备使得增强内容以及全景视频经由第二设备而被显示以增强视频,增强内容与全景视频中的特征的位置相关地被显示。
示例b,根据示例a的方法,其中确定上下文包括:从第一设备接收与第一用户相关联的语音输入,语音输入在全景视频被捕获的同时被捕获;以及处理语音输入以确定语音输入与特征相关;该方法进一步包括:执行全景视频的图像处理以标识全景视频中的特征。
示例c,根据示例a或示例b的方法,其中确定上下文包括:从第二设备接收与第二用户相关联的语音输入,语音输入在全景视频被显示的同时被捕获;以及处理语音输入以确定语音输入与特征相关;该方法进一步包括:执行全景视频的图像处理以标识全景视频中的特征。
示例d,根据示例a-示例c中的任何一个示例的方法,其中确定上下文包括至少部分地基于第一用户的凝视跟踪数据确定第一用户正在看环境内的特征。
示例e,根据示例a-示例d中的任何一个示例的方法,其中确定上下文包括确定第二用户正在看全景视频中的特征的位置。
示例f,根据示例a-示例e中的任何一个示例的方法,其中确定上下文包括:确定第二用户或者第二用户与智能个人助理的先前会话;并且其中确定增强内容包括确定与第二用户的兴趣或者第二用户与智能个人助理的先前会话的兴趣中的至少一个兴趣相关的增强内容。
示例g,根据示例a-示例f中的任何一个示例的方法,其中接收来自第一设备的全景视频包括接收来自捕获全景视频的头戴式设备的全景视频。
示例h,一种系统,包括:一个或多个处理器;以及存储器,存储器被通信地耦合到一个或多个处理器并且存储可执行指令,可执行指令当由一个或多个处理器执行时使得一个或多个处理器执行包括以下的操作:获得表示第一用户所位于的环境的视频;确定第一用户或者与被指定接收视频的设备相关联的第二用户中的至少一个的上下文;至少部分地基于上下文确定增强内容;以及基本上实时地经由与第二用户相关联的设备提供用于显示的增强内容和视频,增强内容将以叠加方式被显示在视频上。
示例i,根据示例h的系统,其中提供用于显示的增强内容和视频包括:在视频中的特征的位置处指定将以叠加方式被显示在视频上的增强内容;以及当特征的位置在视频内变化时,维持与特征相关的增强内容。
示例j,根据示例h或示例i的系统,其中确定增强内容包括从与第一用户相关联的设备接收将被用作增强内容的注释数据。
示例k,根据示例h-示例j中的任何一个示例的系统,其中确定上下文包括接收来自与第一用户相关联的设备的输入,该输入标识感兴趣区域;操作进一步包括:分析关于感兴趣区域的视频以标识特征;并且其中确定增强内容包括确定与特征相关的增强内容。
示例l,根据示例h-示例k中的任何一个示例的系统,其中确定上下文包括接收来自与第二用户相关联的设备的输入,该输入标识感兴趣区域;操作进一步包括:分析关于感兴趣区域的视频以标识特征;并且其中确定增强内容包括确定与特征相关的增强内容。
示例m,根据示例h-示例l中的任何一个示例的系统,其中确定上下文包括基于针对第二用户的用户简档或者第二用户与智能个人助理的先前会话中的至少一个确定关于视频内容的第二用户的理解水平;并且其中确定增强内容包括确定与关于视频内容的第二用户的理解水平相关的增强内容。
示例n,根据示例h-示例m中的任何一个示例的系统,其中操作进一步包括:从与第二用户相关联的设备接收与视频有关的注释数据;从与第二用户相关联的设备接收对视频的一部分的选择;确定与视频的该部分相关联的地理位置;以及存储注释数据与地理位置之间的关联。
示例o,根据示例h-示例n中的任何一个示例的系统,其中操作进一步包括:确定环境的环境状况,环境状况包括环境的位置、环境的温度、视频在环境处被捕获时的一天中的时间中的至少一个;并且其中增强内容包括指示环境状况的内容。
示例p,根据示例h-示例o中的任何一个示例的系统,其中获得视频包括接收来自被配置为捕获环境的视频的头戴式设备的视频。
示例q,一种系统,包括:一个或多个处理器;以及存储器,存储器被通信地耦合到一个或多个处理器并且存储可执行指令,可执行指令当由一个或多个处理器执行时使得一个或多个处理器执行包括以下的操作:显示表示第一设备所位于的环境的视频;接收与视频的增强有关的输入;标识与视频中的特征相关的增强内容,增强内容至少部分地基于输入;以及在视频被显示时输出增强内容。
示例r,根据示例q的系统,其中接收输入包括经由智能个人助理接收语音输入。
示例s,根据示例q或者示例r的系统,其中标识增强内容包括:在线搜索以寻找与视频中的特征相关的内容;以及从与内容相关联的源取回内容。
示例t,根据示例q-示例s中的任何一个示例的系统,其中视频包括全景视频;该系统进一步包括:被配置为显示增强内容和视频的全景显示屏。
示例aa,一种方法,包括:由一个或多个计算设备引起实况视频的显示;由一个或多个计算设备接收选择实况视频的区域的用户输入;以及至少部分基于用户输入并且由一个或多个计算设备:确定与用户输入相关联的实况视频帧;确定与由用户输入所选择的区域对应的帧的一部分;以及使得在继续离焦显示实况视频的同时在实况视频上以叠加方式聚焦显示帧的该部分。
示例bb,根据示例aa的方法,进一步包括:在实况视频正在由第一设备捕获时,接收来自第一设备的实况视频;其中引起实况视频的显示包括将实况视频发送到第二设备,以用于经由第二设备来显示。
示例cc,根据示例bb的方法,进一步包括:从第一设备接收信号以结束帧的该部分的显示,信号包括请求帧的该部分的显示结束的用户输入、或者在第一设备处检测到事件时所生成的触发信号中的至少一个;以及至少部分地基于信号移除帧的该部分的显示,并且使得聚焦显示实况视频。
示例dd,根据示例cc的方法,其中信号包括在第一设备处检测到事件时所生成的信号,事件包括第一设备到达特定位置或者接收到与语音输入相关联的音频信号中的至少一个。
示例ee,根据示例bb的方法,进一步包括:从第二设备接收信号以结束帧的该部分的显示,信号包括请求帧的该部分的显示结束的用户输入、或者在第二设备处检测到事件时所生成的触发信号中的至少一个;以及至少部分地基于信号移除帧的该部分的显示,并且使得聚焦显示实况视频。
示例ff,根据示例ee的方法,其中信号包括在第二设备处检测到事件时所生成的信号,事件包括自从显示帧的该部分以来所经历的一段时间或者接收到与语音输入相关联的音频信号。
示例gg,一种系统,包括:一个或多个处理器;以及存储器,存储器被通信地耦合到一个或多个处理器并且存储可执行指令,可执行指令当由一个或多个处理器执行时使得一个或多个处理器执行包括以下的操作:使得显示实况视频;接收选择实况视频的区域的用户输入;以及至少部分地基于接收到用户输入,暂停显示在区域内的实况视频的一部分,以及在实况视频的该部分被暂停的同时使得实况视频的显示在背景中继续。
示例hh,根据示例gg的系统,其中使得显示实况视频包括使得根据第一显示特性显示实况视频;以及在实况视频的该部分被暂停的同时使得实况视频的显示在背景中继续包括,使得实况视频的显示根据与第一显示特性不同的第二显示特性而在背景中继续。
示例ii,根据示例hh的系统,其中第一显示特性和第二显示特性各自包括对焦水平、图像分辨率水平、或者透明度水平中的至少一个。
示例jj,根据示例gg-示例ii中的任何一个示例的系统,其中在实况视频的该部分被暂停的同时使得实况视频的显示在背景中继续包括,平滑在背景中所显示的实况视频内的内容的移动。
示例kk,根据示例gg-示例jj中的任何一个示例的系统,其中操作进一步包括:接收请求实况视频的该部分从所显示的内容中移除的用户输入;以及至少部分基于接收到用户输入,结束实况视频的该部分的显示。
示例ll,根据示例gg-示例kk中的任何一个示例的系统,其中操作进一步包括:确定自从暂停实况视频的该部分的显示以来的时间段已经到期;以及至少部分地基于确定自从暂停实况视频的该部分的显示以来的时间段已经到期,结束实况视频的该部分的显示。
示例mm,根据示例gg-示例ll中的任何一个示例的系统,其中操作进一步包括:接收来自与捕获实况视频相关联的设备或者被指定显示实况视频的设备中的至少一个的音频信号;确定音频信号是语音输入;以及至少部分地基于确定音频信号是语音输入,结束实况视频的该部分的显示。
示例nn,根据示例gg-示例mm中的任何一个示例的系统,其中操作进一步包括:从与捕获实况视频相关联的设备或者被指定显示实况视频的设备中的至少一个接收针对实况视频的该部分的注释数据;确定与视频的该部分相关联的地理位置;以及将注释数据与地理位置相关联。
示例oo,一种系统,包括:一个或多个处理器;以及存储器,存储器被通信地耦合到一个或多个处理器并且存储可执行指令,可执行指令当由一个或多个处理器执行时使得一个或多个处理器执行包括以下的操作:当视频正在被第一设备捕获时接收来自第一设备的视频;响应于接收到视频,使得视频经由第二设备而被显示;接收来自第二设备的指示以暂停视频的一部分;以及至少部分地基于接收到来自第二设备的指示,使得当视频的显示在背景中继续时视频的该部分在视频上以叠加方式经由第二设备被显示。
示例pp,根据示例oo的系统,其中视频的该部分包括在视频帧内所定义的区域。
示例qq,根据示例oo或者示例pp的系统,其中:使得视频经由第二设备而被显示包括:使得视频根据第一显示特性而被显示,并且使得当视频的显示在背景中继续时视频的该部分在视频上以叠加方式经由第二设备被显示包括:使得实况视频的显示根据与第一显示特性不同的第二显示特性而在背景中继续。
示例rr,根据示例qq的系统,其中第一显示特性和第二显示特性各自包括图像分辨率水平。
示例ss,根据示例qq的系统,其中第一显示特性和第二显示特性各自包括透明度水平。
示例tt,根据示例oo-示例ss中的任何一个示例的系统,其中操作进一步包括:接收针对视频的该部分的注释数据;确定与视频的该部分相关联的地理位置;以及将注释数据与地理位置相关联。
尽管已经以特定于结构特征和/或方法动作的语言描述了实施例,但是应该理解,本公开不必限于所描述的特定特征或动作。相反,本文公开了特定特征和动作,作为实现实施例的说明性形式。
- 还没有人留言评论。精彩留言会获得点赞!