一种高炉一氧化碳利用率预测模型的建立方法与流程
本发明涉及钢铁冶炼和高炉技术领域,尤其是一种高炉一氧化碳利用率预测方法。
背景技术:
高炉冶炼过程作为钢铁生产过程的上游工序,其二氧化碳的直接和相关排放占钢铁工业总排放量的90%,能耗则占钢铁工业总能耗的70%。所以,高炉冶炼是钢铁工业实现节能减排的主要潜力所在。高炉一氧化碳利用率是衡量高炉炼铁过程中气固相还原反应的关键参数,高炉的稳定顺行以及能耗高低也与之息息相关。高炉一氧化碳利用率不仅可以间接反应高炉冶炼进程和碳素还原利用率,而且还能直接影响吨铁能耗和高炉能量利用,能很好地评估高炉能源利用的好坏。因此,高炉一氧化碳利用率的准确预测可以为高炉现场优化操作提供指引,对降低高炉能耗指标具有重要的意义和应用价值。
然而,对于高温高压下的高炉冶炼过程,其内部不仅涉及温度场、流场,以及气、液、固三相流体力学作用形成的多相多场严重耦合,而且涉及复杂的多时空尺度,具有非均一、非稳态、非平衡、强非线性等特征。因此,目前还无法准确的对高炉一氧化碳利用率进行预测。
技术实现要素:
本发明目的在于提供一种高炉一氧化碳利用率预测模型的建立方法,用以解决现有技术中存在的无法准确对高炉一氧化碳利用率进行预测的问题。
为实现上述目的,采用了以下技术方案:本发明所述方法包括以下步骤:
步骤1,获取影响高炉一氧化碳利用率的可测因素;
步骤2,获取上述可测因素影响高炉一氧化碳利用率的具体滞后时间;
步骤3,利用无监督聚类方法获得T-S模糊的前件;
步骤4,在对应的特征映射空间上计算双支持向量机超平面,最终获得高炉一氧化碳利用率预测模型。
进一步的,步骤1中,影响高炉一氧化碳利用率的可测因素具体选择热风温度、热风压力、冷风流量、送风比、标准风速、富氧流量、富氧率、半小时喷煤量、顶压、炉腹煤气量、炉腹煤气指数、透气性、阻力系数、炉顶温度14个变量。
进一步的,步骤2中,利用最大信息系数法计算14个变量不同错位的时间序列和高炉煤气利用率时间序列的相关程度;最大信息系数计算公式如下:
其中I*(D,nx,ny)=maxGI(D|G),I(·)为互信息函数,D|G为有序对D作用在网格G上的概率分布,nx和ny分别为x轴和y轴上的分段数,并且有B(n)=n0.6,其中n为数据点个数;
选择相关程度阈值q,对于相关程度大于阈值q的错位时间序列作为最终确定的时间序列,这些确定下的时间序列的错位时间即为对应的影响高炉一氧化碳利用率可测因素的滞后时间。
进一步的,步骤3中,利用无监督聚类方法对包含模型输入输出的样本数据集进行分簇,簇的个数R作为模糊规则的个数,第i个簇的中心为ci=(x1,i,x2,i,...,xd,i),第i个簇的方差为σi=(σ1,i,σ2,i,...,σd,i),其中i=1,2,...,R,d为模型输入个数,从而得到T-S模糊规则前件,其中第i个模糊规则表示如下:
如果并且并且
那么yi=ωi0+ωi1x1+...+ωidxd
其中由如下模糊关系函数描述:
利用加权去模糊化原理,T-S模糊模型的输出如下
其中φi(x)为对于输入x的第i个模糊规则的点火强度,其计算公式如下:
其中μi定义如下:
进一步的,步骤4中,给出如下两个式子,
ψ(x)=[φ1(x)[1xT],φ2(x)[1xT],...,φR(x)[1xT]]T,
其中,wi=[ωi0,ωi1,...,ωid,],那么对于输入x,T-S模糊模型的输出可表示为y(x)=ψ(x)TW;映射函数ψ:x→ψ(x)将输入原空间x映射到特征空间,在特征空间定义两个超平面gup(x)=ψ(x)TW1,gdown(x)=ψ(x)TW2,所述两个超平面对应两个ε不敏感参数ε1和ε2,为了增强模型的泛化能力,求解两个超平面中的W1和W2,给出如下两个约束优化目标函数:
ξi≥0
i∈I
κi≥0
i∈I
其中ξi和κi是表示第i个样本点是否进入ε1(ε2)不敏感区域的松弛变量,λ1和λ2是对应的正则化参数,I表示所有样本的集合;
以上两个优化问题都为二次规划问题,其求解过程类似,这里对第一个优化问题进行说明。首先将第一个优化问题转化成拉格朗日形式如下:
其中,α和β是分别由αi(i∈I)和βi(i∈I)组成的拉格朗日乘子;由K.K.T条件可得如下:
λ1-αi-βi=0,i∈I
yi-W1Tψ(xi)≥ε1-ξi,ξi≥0,i∈I
αi≥0,βi≥0,i∈I
并且有
再根据K.K.T.条件可得如下乌尔夫对偶
s.t.0≤αi≤λ1,i∈I
求解以上乌尔夫对偶可得αi≥0,i∈I,也就可得到W1,同理可计算得到W2,那么根据所获得的两个超平面可得基于双支持向量机的T-S模糊模型如下:
其即为最终获得的高炉一氧化碳利用率预测模型。
一种高炉一氧化碳利用率预测模型的建立装置,影响高炉一氧化碳利用率的可测因素获取单元,用于获取影响高炉一氧化碳利用率的可测因素;影响高炉一氧化碳利用率可测因素的滞后时间获取单元,用于获取影响高炉一氧化碳利用率可测因素的具体滞后时间;T-S模糊模型的前件获取单元,用于获取T-S模糊模型的前件;基于双支持向量机的T-S模糊模型获取单元,用于获取基于双支持向量机的T-S模糊模型。
工作过程大致如下:
在高炉冶炼的过程中,获取影响高炉一氧化碳利用率的可测因素,包括热风温度、热风压力、冷风流量、送风比、标准风速、富氧流量、富氧率、半小时喷煤量、顶压、炉腹煤气量、炉腹煤气指数、透气性、阻力系数、炉顶温度14个变量,再利用最大信息系数法计算14个变量不同错位的时间序列和高炉煤气利用率时间序列的相关程度,选择相关程度阈值q,对于相关程度大于阈值q的错位时间序列作为最终确定的时间序列,这些确定下的时间序列的错位时间即为对应的影响高炉一氧化碳利用率可测因素的滞后时间,进一步利用无监督聚类方法获得T-S模糊的前件,再在特征映射空间上基于双支持向量机原理获得最终的高炉一氧化碳利用率预测模型。
与现有技术相比,本发明方法具有如下优点:设计合理、简单易行,能提高高炉一氧化碳利用率预测的准确性。
附图说明
图1为本发明实施例中高炉煤气利用率与一个影响因素不同滞后时间的相关性计算示意图;
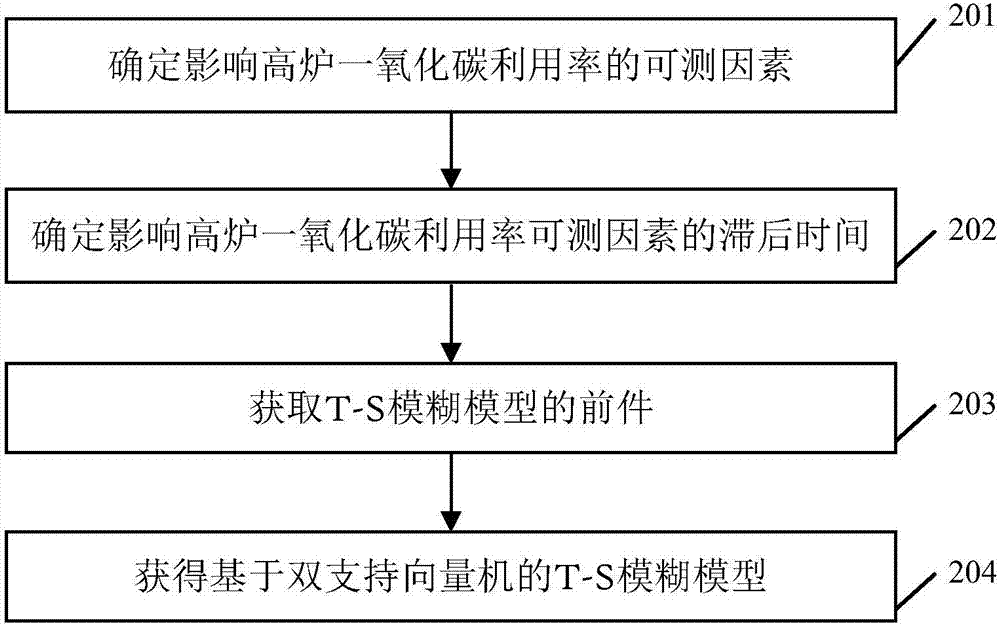
图2为本发明实施例提供的高炉一氧化碳利用率预测模型建立方法的流程图;图3为本发明实施例中提供的高炉一氧化碳利用率预测模型建立装置的结构示意图。
具体实施方式
下面结合附图对本发明做进一步说明:
如图1所示为高炉一氧化利用率与一个影响因素不同滞后时间的相关性计算示意图,
101为高炉一氧化碳利用率时间序列,表示为X1={x1(t),x1(t-1),...,x1(t-n)};
102为这个影响因素滞后1个采样时间所对应的时间序列,表示为
103为这个影响因素滞后2个采样时间所对应的时间序列,表示为利用最大信息系数法计算X1与的相关性,即得到高炉一氧化利用率与这个影响因素滞后1个采样时间的相关性,同理,利用最大信息系数法计算X1与的相关性,即得到高炉一氧化利用率与这个影响因素滞后2个采样时间的相关性。利用最大信息系数法计算高炉一氧化利用率与不同影响因素滞后不同采样时间的相关性过程与以上原理类似。
如图2所示,其为高炉一氧化碳利用率预测模型建立方法的流程图,包括:
步骤201,确定影响高炉一氧化碳利用率的可测因素。具体包括热风温度、热风压力、冷风流量、送风比、标准风速、富氧流量、富氧率、半小时喷煤量、顶压、炉腹煤气量、炉腹煤气指数、透气性、阻力系数、炉顶温度14个变量;
步骤202,确定影响高炉一氧化碳利用率可测因素的滞后时间。具体过程是利用最大信息系数法计算14个变量不同错位的时间序列和高炉煤气利用率时间序列的相关程度,再选择相关程度阈值q,对于相关程度大于阈值q的错位时间序列作为最终确定的时间序列,这些确定下的时间序列的错位时间即为对应的影响高炉一氧化碳利用率可测因素的滞后时间;
步骤203,获取T-S模糊模型的前件。具体过程是利用无监督聚类方法对包含模型输入输出的样本数据集进行分簇,簇的个数R作为模糊规则的个数,第i个簇的中心为ci=(x1,i,x2,i,...,xd,i),第i个簇的方差为σi=(σ1,i,σ2,i,...,σd,i),其中i=1,2,...,R,d为模型输入个数,从而得到T-S模糊规则前件,其中,第i个模糊规则表示如下:
如果并且并且
那么yi=ωi0+ωi1x1+...+ωidxd
其中由如下模糊关系函数描述:
利用加权去模糊化原理,T-S模糊模型的输出如下
其中φi(x)为对于输入x的第i个模糊规则的点火强度,其计算公式如下:
其中μi定义如下:
步骤204,获得基于双支持向量机的T-S模糊模型。具体过程是首先作如下两个定义
ψ(x)=[φ1(x)[1xT],φ2(x)[1xT],...,φR(x)[1xT]]T,
其中,wi=[ωi0,ωi1,...,ωid,],那么对于输入x,T-S模糊模型的输出可表示为y(x)=ψ(x)TW。映射函数ψ:x→ψ(x)将输入原空间x映射到特征空间,这里在特征空间定义两个超平面gup(x)=ψ(x)TW1,gdown(x)=ψ(x)TW2,这两个超平面对应两个ε不敏感参数ε1和ε2,为了增强模型的泛化能力,这里对于求解两个超平面中的W1和W2,给出如下两个约束优化目标函数:
s.t.yi-W1Tψ(xi)≥ε1-ξi
ξi≥0
i∈I
κi≥0
i∈I
其中ξi和κi是表示第i个样本点是否进入ε1(ε2)不敏感区域的松弛变量,λ1和λ2是对应的正则化参数,I表示所有样本的集合。
以上两个优化问题都为二次规划问题,其求解过程类似,这里对第一个优化问题进行说明。首先将第一个优化问题转化成拉格朗日形式如下:
其中,α和β是分别由αi(i∈I)和βi(i∈I)组成的拉格朗日乘子。由K.K.T条件可得如下:
λ1-αi-βi=0,i∈I
yi-W1Tψ(xi)≥ε1-ξi,ξi≥0,i∈I
αi≥0,βi≥0,i∈I
并且有
再根据K.K.T.条件可得如下乌尔夫对偶
s.t.0≤αi≤λ1,i∈I
求解以上乌尔夫对偶可得αi≥0,i∈I,也就可得到W1,同理可计算得到W2,那么根据所获得的两个超平面可得基于双支持向量机的T-S模糊模型如下:
为了实现本发明所述的方法,还提供了一种模型建立装置,如图3所示,具体包括:可测因素获取单元301、滞后时间获取单元302、前件获取单元303、T-S模糊模型获取单元304;利用可测因素获取单元获取影响高炉一氧化碳利用率的可测因素;利用滞后时间获取单元获取影响高炉一氧化碳利用率可测因素的具体滞后时间;利用前件获取单元获取T-S模糊模型的前件;利用T-S模糊模型获取单元获取基于双支持向量机的T-S模糊模型。
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!