一种食材/食谱知识图谱的本体映射方法及装置与流程
本发明涉及饮食领域,更具体的说,涉及一种食材/食谱知识图谱的本体映射方法。本发明同时还揭示了一种食材/食谱知识图谱的本体映射装置。
背景技术:
近年来,随着语义网的不断发展,万维网中含有越来越多的本体的形式的知识。本体作为一种新颖的知识表现形式,能够与知识图谱相结合,对现实世界的实体或概念进行描述,其在语义网的发展扮演着极其重要的作用,基于本体的应用也越来越多,包括电子工程、化学、远程教育等。随着语义网中的本体的不断增加,必然存在相关或相同的应用领域存在相近或相同的本体,由于这些本体的来源不同,本体的构建方式不同,因此这些本体之间可以信息互补,因此使用本体映射技术将相关本体映射是一件具有重大意义的工作。
然而,目前并未出现针对食材、食谱领域的本体映射知识图谱或者系统,仅仅使用通用本体映射系统来对食材、食谱领域的本体进行映射,无法挖掘出食材、食谱领域本体更深层次的信息,因此本体映射的效果也不好,达不到实用的标准。
技术实现要素:
本发明为解决上述现有技术中存在的技术问题,提供了一种食材/食谱知识图谱的本体映射方法,该方法针对食材/食谱领域专门设计,不仅能够对本体的实例进行映射,还能够对本体的概念进行映射,同时还能深入的挖掘出相应的等价关系以及上下位关系,实现本体之间的信息互补。
为达到上述目的,本发明采用的技术方案如下:
一种食材/食谱知识图谱的本体映射方法,包括:获取实例数据并根据实例数据的类别属性构建本体集合;从本体集合中挑选出需要相互映射的第一本体o1和第二本体o2,根据第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp;基于决策树模型对待映射实例对集合ip进行实例映射并获得实例映射结果,实例映射结果中包含等价实例对集合set1和不等价实例对集合set2;基于支持向量机模型对待映射概念对集合cp进行概念映射并获得概念映射结果,概念映射结果中包含等价概念对集合set3以及上下位概念对集合set4;根据实例映射结果和概念映射结果获得本体映射结果;其中,实例数据为食材实例数据,本体集合为食材本体集合;或者,实例数据为食谱实例数据,本体集合为食谱本体集合。
进一步地,从本体集合中挑选出需要相互映射的第一本体o1和第二本体o2,根据第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp的步骤包括:
s11,对待映射实例对集合ip和待映射概念对集合cp进行表示,其中,
ip={(i11,i21),(i11,i22),…,(i11,i2m),(i12,i21),…,(i12,i2m),…,(i1n,i21),…,(i1n,i2m)},
cp={(c11,c21),(c11,c22),…,(c11,c2t),(c12,c21),…(c12,c2t),…,(c1s,c21),…,(c1s,c2t)},
i1i为第一本体o1的实例,c1k为第一本体o1的概念,i2j为第二本体o2的实例,c2p为第二本体o2的概念,i∈{1,2,…,n},k∈{1,2,…,s},j∈{1,2,…,m},p∈{1,2,…,t},n为第一本体o1中实例的总量,s为第一本体o1中概念的总量,m为第二本体o2中实例的总量,t为第二本体o2中概念的总量;
s12,如果第一本体o1中还有未标记的第一实例,则从中取出一个实例i1i并标记,把第二本体o2中的实例全部不标记;否则转至s15;
s13,如果第二本体o2中还有未标记的第二实例,则从中取出一个实例i2j并标记;否则转至s12;
s14,由步骤s12和步骤s13得到的两个实例组成一个待映射实例对(i1i,i2j)并将该实例对放入待映射实例对集合ip中,转至s13;
s15,结束,生成待映射实例对集合ip。
进一步地,从本体集合中挑选出需要相互映射的第一本体o1和第二本体o2,根据第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp的步骤包括:
s21,如果第一本体o1中还有未标记的第一概念,则从中取出一个概念c1k并标记,把第二本体o2中的概念全部不标记;否则转至s24;
s22,如果第二本体o2中还有未标记的第二概念,则从中取出一个概念c2p并标记;否则转至s21;
s23,由步骤s21和步骤s22得到的两个概念组成一个待映射概念对(c1k,c2p)并将该概念对放入待映射概念对集合cp中,转至s22;
s24,结束,生成待映射概念对集合cp。
进一步地,基于决策树模型对待映射实例对集合ip进行实例映射并获得实例映射结果,实例映射结果中包含等价实例对集合和不等价实例对集合的步骤包括:
s31,将待映射实例对集合ip中的所有实例对加入队列q1,并将训练实例对加入队列q2,训练实例对通过人工标注获得;
s32,使用q2中的训练实例对作为训练数据训练获得一个基于监督学习的决策树模型;
s33,从队列q1中选取一个实例对出列,将该实例对的特征向量输入决策树模型,由决策树模型判断该实例对中的两个实例是否等价,若等价则将该实例对添加至等价实例对集合set1;反之,则将该实例对添加至不等价实例对集合set2;
s34,如果q1不为空,就转至s33;
s35,实例映射结束,获得实例映射结果。
进一步地,步骤s32包括:
s41,从队列q2中抽取正例放入等价实例对集合set1,从q2中抽取负例放入不等价实例对集合set2;
s42,对队列q1和队列q2中的所有实例对,依次抽取每个实例对中每个实例的特征;若有特征缺失,则标记为null;
s43,对队列q1和队列q2中的每个实例的特征向量进行清洗,清洗规则为:去除字符串中的括号以及标点符号,然后利用编辑距离计算出文本相似度;
s44,清洗完毕后,判定每个实例对中两个实例的特征是否接近,判定方法为:若两个实例的对应特征的字符串完全相同,则判定两个实例的对应特征相同;或者,若两个实例的对应特征的文本相似度大于预设阈值,则判定两个实例的对应特征相同;
s45,根据所有训练实例对的数据构建决策树模型,并引入熵函数entropy(d)衡量数据的纯净度,其中,
pr(car)指类别标签car在训练数据集d中出现的概率,ca为所有类别标签组成的类别集合,|ca|为类别集合ca中类别标签的数量。
进一步地,步骤s45包括:
s51,根据一组训练数据集d及一组未被用来构建决策树模型的属性特征集合a,构造一个根节点;
s52,如果训练数据集d只存在被标注为两实例等价的正例,则把步骤s51构造的根节点标注为“两实例等价”,转至s58;
s53,如果训练数据集d只存在被标注为两实例不等价的负例,则把步骤s51构造的根节点标注为“两实例不等价”,转至s58;
s54,如果属性特征集合a是空集,则比较训练数据集d中正例和负例的数量,若正例数量大于或等于负例数量,则把步骤s51中构造的根节点标注为“两实例等价”然后转至s58,否则把步骤s51中构造的根节点标注为“两实例不等价”然后转至s58;若训练数据集d为空集,则把全部训练数据中出现次数最多的类别属性放入s51中用于构建根节点,并将相应的根节点标注为“两实例不等价”,转至s58;
s55,根据特征az将训练数据集d划分为v个不相交的子集d1,d2,…,dv,则划分后得:
从中选出能够使entropyaz(d)值最小的特征az;
s56,将步骤s51中构造的根节点标注为“用特征az来划分”;
s57,根据属性az的取值个数将训练数据集d划分成相同组数的数据,然后对每组数据分别转至步骤s51中运行;
s58,结束,获得构建而成的决策树模型。
进一步地,基于支持向量机模型对待映射概念对集合cp进行概念映射并获得概念映射结果,概念映射结果中包含等价概念对集合set3以及上下位概念对集合set4的步骤包括:
s61,为待映射概念对集合cp的所有概念对生成对偶概念对并将相应的对偶概念对添加至待映射概念对集合cp形成一个新的集合cp’中;
s62,对集合cp’的所有概念对计算五种不对称相似度,五种不对称相似度包括:概念反编辑距离相似度、概念集合杰卡德相似度、概念向量相似度、概念文本上下文相似度以及实例集合杰卡德相似度;
s63,人工标注部分概念对的上下位关系,并使用该些已标注的概念对作为训练数据训练获得一个基于监督学习的支持向量机模型;
s64,使用支持向量机模型预测集合cp’中所有未标注的概念对,在遍历所有被标注有上下位关系的概念对中,若其对偶概念对也存在上下位关系,则判定相应的概念对中两个概念为等价关系;反之,则判定相应概念对中两个概念仍为上下位关系;
s65,概念映射结束,获得概念映射结果。
进一步地,步骤63包括:
s71,抽取cp’中所有已标注的概念对的特征向量和类别标签作为训练数据m,m={(x1,y1),(x2,y2),...,(xn,yn)},其中xi为一个概念对的特征向量,yi为一个概念对的类别标签,n为已标注的概念对的个数;
s72,获取一个决策平面以分割正例训练数据和负例训练数据,定义决策平面<w*x>+b=0,并定义正例和负例的边界,其中正例h+:<w*x>+b-1=0,负例h-:<w*x>+b+1=0,w为决策平面的法向量,b为决策平面的偏置,则将支持向量机模型需要学习的问题转化为在满足第一约束条件的情况下正例和负例之间的边距d的最小化问题,其中,
第一约束条件为:yi*(<w*xi>+b)≥1,i=1,2,...,n;
s73,采用标准拉格朗日乘子法,根据边距d和第一约束条件求解得到目标函数lp,其中:
ai为拉格朗日乘子,且目标函数lp满足kkt条件;
s74,根据目标函数lp和kkt条件求得目标函数lp的对偶函数ld,其中:
且对偶函数ld满足第二约束条件:
s75,求解对偶函数ld获得法向量w和偏置b用以构建分类函数f(z),根据分类函数f(z)对新的概念对进行判定,其中:
f(z)=sign(<w*z>+b);
sign(<w*z>+b)为符号函数,如果<w*z>+b>0,则sign(<w*z>+b)返回1,相应的概念对被判定为正例;如果<w*z>+b小于0,则sign(<w*z>+b)返回0,相应的概念对被判定为负例。
进一步地,步骤s42中,
特征为食材特征,食材特征包括:食材名称、食材别称、食材功效、食材储藏方法、食材烹饪要点、食材简介;或者,
特征为食谱特征,食谱特征包括:食谱名称、食谱别称、食谱口味、食谱烹饪工艺、食谱烹饪难度、食谱描述。
本发明同时还揭示了一种食材/食谱知识图谱的本体映射装置:
一种食材/食谱知识图谱的本体映射装置,包括:获取模块,用于获取实例数据;本体构建模块,用于根据实例数据的类别属性构建本体集合;集合生成模块,用于根据挑选出的需要相互映射的第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp;实例映射模块,用于基于决策树模型对待映射实例对集合ip进行实例映射并获得实例映射结果,实例映射结果中包含等价实例对集合set1和不等价实例对集合set2;概念映射模块,用于基于支持向量机模型对待映射概念对集合cp进行概念映射并获得概念映射结果,概念映射结果中包含等价概念对集合set3以及上下位概念对集合set4;本体映射模块,用于根据实例映射结果和概念映射结果获得本体映射结果;其中,实例数据为食材实例数据,本体集合为食材本体集合;或者,实例数据为食谱实例数据,本体集合为食谱本体集合。
本发明技术方案的有益效果如下:
本发明揭示了一种食材/食谱知识图谱的本体映射方法,该方法能够通过决策树模型和支持向量机模型分别对本体的实例和概念进行映射,从而获得本体映射结果,建立起本体之间的联系,从而挖掘出食谱/食材之间的深层次信息,为饮食领域的智能化提供数据基础。本发明同时还揭示了一种食材/食谱知识图谱的本体映射装置,该装置能够用于建立本体映射,挖掘出食材/食谱本体之间的联系。
附图说明
图1是本发明所述方法其中一实施例的步骤框图;
图2是本发明所述方法其中一实施例的流程示意图;
图3是本发明所述方法其中一实施例中实例映射步骤的流程示意图;
图4是本发明所述方法其中一实施例中概念映射步骤的流程是有图;
图5是本发明所述装置的模块架构图。
具体实施方式
以下通过附图和具体实施例对本发明所提供的技术方案做更加详细的描述:
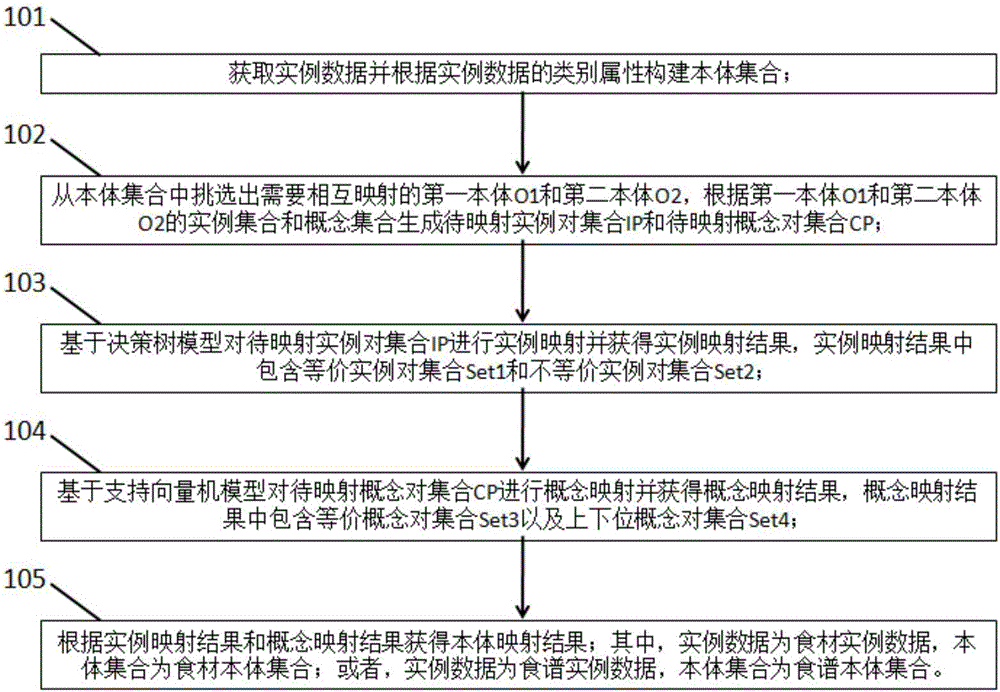
附图1揭示了本发明所述方法的具体实施例。如图1所示的,是本发明所述方法的步骤框图,该实施例中揭示了一种食材/食谱知识图谱的本体映射方法,包括:
步骤101,获取实例数据并根据实例数据的类别属性构建本体集合;
步骤102,从本体集合中挑选出需要相互映射的第一本体o1和第二本体o2,根据第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp;
步骤103,基于决策树模型对待映射实例对集合ip进行实例映射并获得实例映射结果,实例映射结果中包含等价实例对集合set1和不等价实例对集合set2;
步骤104,基于支持向量机模型对待映射概念对集合cp进行概念映射并获得概念映射结果,概念映射结果中包含等价概念对集合set3以及上下位概念对集合set4;
步骤105,根据实例映射结果和概念映射结果获得本体映射结果;其中,实例数据为食材实例数据,本体集合为食材本体集合;或者,实例数据为食谱实例数据,本体集合为食谱本体集合。
该实施例中,采用不同的算法模型分别对本体的实例和概念进行映射,完成了本体之间的实例映射和概念映射,能够获得实例之间的等价关系,以及概念之间的等价关系和上下位关系。由于本体通常是用以对实例以及概念进行描述的,因此获得了本体之间的实例映射结果和概念映射结果,也就相应的可以获得本体之间的映射结果。该实施例中获得的本体映射结果能够用于构建知识图谱,为饮食领域的智能化提供了数据基础。其中,若所获取的实例数据为食材实例数据,则构建的本体集合为食材本体集合,相应获得的本体映射结果为食材本体之间的映射结果;若所获取的实例数据为食谱实例数据,则构建的本体集合为食谱本体集合,相应获得的本体映射结果为食谱本体之间的映射结果。
如图2所示的,是本发明所述方法其中一实施例的流程示意图。该实施例中的方法,包括步骤:
步骤201,获取实例数据:其中的实例数据可以通过自建数据库获取,也可以通过接入第三方数据平台的方式获取;
步骤202,构建本体集合:通过实例数据构建本体集合,属于一种自下而上的本体集合构建方法;
步骤203,生成待映射实例对集合ip;
步骤204,基于决策树模型对集合ip进行实例映射:优选地,通过监督学习的决策树模型对集合ip进行实例映射;
步骤205,生成待映射概念对集合cp;
步骤206,基于支持向量机模型对集合cp进行概念映射:优选地,基于监督学习的支持向量机模型对集合cp进行概念映射;
步骤207,获得本体映射结果。
通过上述实施例,能够获得本体映射结果,用于构建食材或食谱领域的知识图谱。
作为本发明所述方法的其中一实施例,所述从所述本体集合中挑选出需要相互映射的第一本体o1和第二本体o2,根据第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp的步骤包括:
s11,对所述待映射实例对集合ip和所述待映射概念对集合cp进行表示,其中,ip={(i11,i21),(i11,i22),…,(i11,i2m),(i12,i21),…,(i12,i2m),…,(i1n,i21),…,(i1n,i2m)},
cp={(c11,c21),(c11,c22),…,(c11,c2t),(c12,c21),…(c12,c2t),…,(c1s,c21),…,(c1s,c2t)},
i1i为第一本体o1的实例,c1k为第一本体o1的概念,i2j为第二本体o2的实例,c2p为第二本体o2的概念,i∈{1,2,…,n},k∈{1,2,…,s},j∈{1,2,…,m},p∈{1,2,…,t},n为第一本体o1中实例的总量,s为第一本体o1中概念的总量,m为第二本体o2中实例的总量,t为第二本体o2中概念的总量;
s12,如果第一本体o1中还有未标记的第一实例,则从中取出一个实例i1i并标记,把第二本体o2中的实例全部不标记;否则转至s15;
s13,如果第二本体o2中还有未标记的第二实例,则从中取出一个实例i2j并标记;否则转至s12;
s14,由步骤s12和步骤s13得到的两个实例组成一个待映射实例对(i1i,i2j)并将该实例对放入待映射实例对集合ip中,转至s13;
s15,结束,生成所述待映射实例对集合ip。
作为本发明所述方法的其中一实施例,所述从所述本体集合中挑选出需要相互映射的第一本体o1和第二本体o2,根据第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp的步骤包括:
s21,如果第一本体o1中还有未标记的第一概念,则从中取出一个概念c1k并标记,把第二本体o2中的概念全部不标记;否则转至s24;
s22,如果第二本体o2中还有未标记的第二概念,则从中取出一个概念c2p并标记;否则转至s21;
s23,由步骤s21和步骤s22得到的两个概念组成一个待映射概念对(c1k,c2p)并将该概念对放入待映射概念对集合cp中,转至s22;
s24,结束,生成所述待映射概念对集合cp。
上述实施例中,生成的待映射实例对集合ip和待映射概念对集合cp将用于通过机器学习方法以及算法模型完成相应的实例映射和概念映射。
如图3所示的,揭示了本发明所述方法其中一实施例中实例映射步骤的流程示意图。作为本发明所述方法的其中一实施例,所述基于决策树模型对所述待映射实例对集合ip进行实例映射并获得实例映射结果,所述实例映射结果中包含等价实例对集合和不等价实例对集合的步骤包括:
步骤301,将待映射实例对集合ip中的所有实例对加入队列q1,并将训练实例对加入队列q2,所述训练实例对通过人工标注获得;
步骤302,使用q2中的训练实例对作为训练数据训练获得一个基于监督学习的决策树模型;
步骤303,从队列q1中选取一个实例对出列,将该实例对的特征向量输入所述决策树模型;
步骤304,由所述决策树模型判断该实例对中的两个实例是否等价;
步骤305,若等价则将该实例对添加至等价实例对集合set1;
步骤306,反之,则将该实例对添加至不等价实例对集合set2;
步骤307,如果q1不为空,就转至步骤303;
步骤308,实例映射结束,获得所述实例映射结果。
该实施例中,关于步骤302,还包括:
s41,从队列q2中抽取正例放入等价实例对集合set1,从q2中抽取负例放入不等价实例对集合set2:由于在实际的映射中,负例数量多于正例数量,所以按照预设比例从set1和set2中随机抽取训练数据,优选地,所述预设比例为1:4,且抽取的总数据量不超过500个;
s42,对队列q1和队列q2中的所有实例对,依次抽取每个实例对中每个实例的特征;若有特征缺失,则标记为null:该实施例中,所述特征为食材特征,所述食材特征包括:食材名称、食材别称、食材功效、食材储藏方法、食材烹饪要点、食材简介;或者,所述特征为食谱特征,所述食谱特征包括:食谱名称、食谱别称、食谱口味、食谱烹饪工艺、食谱烹饪难度、食谱描述;
s43,对队列q1和队列q2中的每个实例的特征向量进行清洗,所述清洗规则为:去除字符串中的括号以及标点符号,然后利用编辑距离计算出文本相似度:由于自然语言的多样性,相同的特征在文字表达方式上并不完全相同,所以需要对q1与q2中的所有数据中的每个实例特征向量进行清洗,对于食材特征来说,主要在食材简介上会存在较大差异,而对于食谱特征来说,主要在食谱描述上会存在较大差异,因此专门针对食材简介和食谱描述的特征,设计了所述清洗规则,从而使本发明所述的方法能够专门针对食材/食谱知识图谱进行本体映射;
s44,清洗完毕后,判定每个实例对中两个实例的特征是否接近,判定方法为:若两个实例的对应特征的字符串完全相同,则判定两个实例的对应特征相同(适用于食材名称、食材别称、食材功效、食材储藏方法、食材烹饪要点的特征,以及食谱名称、食谱别称、食谱口味、食谱烹饪工艺、食谱烹饪难度的特征);或者,若两个实例的对应特征的所述文本相似度大于预设阈值,则判定两个实例的对应特征相同(适用于食材简介的特征,以及食谱描述的特征);
s45,根据所有训练实例对的数据构建决策树模型,并引入熵函数entropy(d)衡量数据的纯净度,其中,
pr(car)指类别标签car在训练数据集d中出现的概率,ca为所有类别标签组成的类别集合,|ca|为类别集合ca中类别标签的数量:使用贪心算法思想构造一个决策树模型,此算法的基本思想是每次使用一个特征将训练数据尽可能“纯净”的分开,最好的情况是分开后每组中数据的类别标签都是相同的,然后在得到的两组数据上重复这个过程直到满足终止条件,为了衡量“纯净度”,这里引入了信息论中熵(entropy)的概念。
该实施例中,关于步骤s45,包括:
s51,根据一组训练数据集d及一组未被用来构建决策树模型的属性特征集合a,构造一个根节点;
s52,如果训练数据集d只存在被标注为两实例等价的正例,则把步骤s51构造的根节点标注为“两实例等价”,转至s58;
s53,如果训练数据集d只存在被标注为两实例不等价的负例,则把步骤s51构造的根节点标注为“两实例不等价”,转至s58;
s54,如果属性特征集合a是空集,则比较训练数据集d中正例和负例的数量,若正例数量大于或等于负例数量,则把步骤s51中构造的根节点标注为“两实例等价”然后转至s58,否则把步骤s51中构造的根节点标注为“两实例不等价”然后转至s58;若训练数据集d为空集,则把全部训练数据中出现次数最多的类别属性放入s51中用于构建根节点,并将相应的根节点标注为“两实例不等价”,转至s58;
s55,根据特征az将训练数据集d划分为v个不相交的子集d1,d2,…,dv,则划分后得:
从中选出能够使entropyaz(d)值最小的特征az;
s56,将步骤s51中构造的根节点标注为“用特征az来划分”;
s57,根据属性az的取值个数将训练数据集d划分成相同组数的数据,然后对每组数据分别转至步骤s51中运行;
s58,结束,获得构建而成的决策树模型。
通过上述实施例,完成了本发明方法中所述的实例映射过程,从而获得了实例映射结果。
如图4所示的,涉及本发明方法其中一实施例的概念映射步骤。作为本发明所述方法的其中一实施例,所述基于支持向量机模型对所述待映射概念对集合cp进行概念映射并获得概念映射结果,所述概念映射结果中包含等价概念对集合set3以及上下位概念对集合set4的步骤包括:
s61,为待映射概念对集合cp的所有概念对生成对偶概念对并将相应的对偶概念对添加至待映射概念对集合cp形成一个新的集合cp’中:例如,一个原概念对为(c1k,c2p),则其对偶概念对为(c2p,c1k);
s62,对集合cp’的所有概念对计算五种不对称相似度,所述五种不对称相似度包括:概念反编辑距离相似度、概念集合杰卡德相似度、概念向量相似度、概念文本上下文相似度以及实例集合杰卡德相似度:对于五种不对称相似度的具体定义如下:
(1)概念反编辑距离相似度:给定一个概念对(c1k,c2p),概念c1k与c2p之间的概念编辑距离相似度,是指两个字串之间,由一个字符串转成另一个字符串所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大,则
rlev(c1k,c2p)=1-lev(c1k,c2p)
其中lev(c1k,c2p)是字符串c1k和字符串c2p之间的编辑距离;
(2)概念集合杰卡德相似度:给定任意一个概念c,利用概念标签l(c),从第三方平台网站返回的页面中抽取出所有的类别,这些类别构成了概念c的一组相关概念rc(c),rc(c)={rc1,rc2,…,rcn},其中rci是第i个相关概念,对于概念对(c1k,c2p),概念c1k与c2p之间的概念集合的杰卡德相似度rcjcd(c1k,c2p)的计算方式如下所示:
其中|rc(c1k)∩rc(c2p)|指c1k的概念集合与c2p的概念集合的交集的元素个数,而|rc(c1k)|表示c1k的概念集合的元素个数;
(3)概念向量相似度:定义概念c的相关概念向量rcs(c)={rc1,rc2,...,rcn}rcv(c),rcv(c)=<rc1(c),rc2(c),…,rcn(c)>,其中rcy(c)表示第y个相关概念rcy出现的次数;对于给定一个概念对(c1k,c2p),概念c1k与c2p之间的概念向量相似度rcvecsim(c1k,c2p)的定义如下所示:
(4)概念文本上下文相似度:对于给定的任意一个概念c,首先利用第三方平台检索概念c的标签l(c),将返回的所有页面作为概念c的文本上下文,并对文本上下文进行分词与去停用词,最后采用词语频率-逆向文档频率方法对得到的每个词语i进行加权,i的权重wi的计算公式如下所示:
其中tfi指i在其文本上下文中出现的次数,dfi是文本上下文包含i的词语的数量,而n为词语的总数;
定义概念c的文本上下文向量为tc(c)=<w1(c),w2(c),…,wn(c)>,其中wv(c)表示第v个词语tc(c)i的重要性,wi(c)n是所有概念的文本上下文进行分词与去停用词处理后的词词语的总量;对于给定的概念对(c1k,c2p),概念c1k与c2p之间的文本上下文的相似度textsim(c1k,c2p)的定义如下:
(5)实例集合杰卡德相似度:首先定义概念c的实例集合为ins(c),利用两个不同本体的实例映射后得到的属于不同本体的等价实例进行计算,则概念对(c1k,c2p)中概念c1k与概念c2p之间的实例集合杰卡德相似度inssim(c1k,c2p)的计算方式如下:
其中|ins(c1k)∩ins(c2p)|指c1k与c2p的实例集合的交集的元素个数,即等价实例的数量,而|ins(c1k)|表示c1k的实例集合的元素个数;
s63,人工标注部分概念对的上下位关系,并使用该些已标注的概念对作为训练数据训练获得一个基于监督学习的支持向量机模型;
s64,使用所述支持向量机模型预测集合cp’中所有未标注的概念对,在遍历所有被标注有上下位关系的概念对中,若其对偶概念对也存在上下位关系,则判定相应的概念对中两个概念为等价关系;反之,则判定相应概念对中两个概念仍为上下位关系;
s65,概念映射结束,获得概念映射结果。
该实施例中,为所有原概念对生成对偶概念对得到一个新的概念对集合cp’。然后计算每个概念对中两个概念间五种不对称相似度作为每个概念对的特征,再利用显式概念间上下位关系映射规则挖掘出上下位关系和非上下位关系,对并对其添加标签作为已标注概念对。之后,将所有概念对作为结点构建一个完全图谱,并根据每个概念对的特征计算所有结点间边的权重。最后使用基于监督学习的支持向量机算法挖掘概念间的上下位关系,并根据得到的概念间的上下位关系进行概念间等价关系的推断。
该实施例中,关于步骤s63,包括:
s71,抽取cp’中所有已标注的概念对的特征向量和类别标签作为训练数据m,m={(x1,y1),(x2,y2),...,(xn,yn)},其中xi为一个概念对的特征向量,yi为一个概念对的类别标签,n为已标注的概念对的个数;
s72,获取一个决策平面以分割正例训练数据和负例训练数据,定义决策平面<w*x>+b=0,并定义正例和负例的边界,其中正例h+:<w*x>+b-1=0,负例h-:<w*x>+b+1=0,w为所述决策平面的法向量,b为所述决策平面的偏置,则将支持向量机模型需要学习的问题转化为在满足第一约束条件的情况下正例和负例之间的边距d的最小化问题,其中,
第一约束条件为:yi*(<w*xi>+b)≥1,i=1,2,...,n;
s73,采用标准拉格朗日乘子法,根据边距d和所述第一约束条件求解得到目标函数lp,其中:
ai为拉格朗日乘子,且目标函数lp满足kkt条件;
s74,根据所述目标函数lp和kkt条件求得目标函数lp的对偶函数ld,其中:
且对偶函数ld满足第二约束条件:
s75,求解对偶函数ld获得法向量w和偏置b用以构建分类函数f(z),根据分类函数f(z)对新的概念对进行判定,其中:
f(z)=sign(<w*z>+b);
sign(<w*z>+b)为符号函数,如果<w*z>+b>0,则sign(<w*z>+b)返回1,相应的概念对被判定为正例;如果<w*z>+b小于0,则sign(<w*z>+b)返回0,相应的概念对被判定为负例。
以上,本发明所述的方法分别通过决策树模型和支持向量机模型对涉及食材/食谱的本体进行了实例映射和概念映射,确定出了实例之间的等价关系,以及概念之间的等价关系和上下位关系,从而能够获得相应的本体映射结果,最终实现了知识图谱中的本体映射。
本发明同时还揭示了一种食材/食谱知识图谱的本体映射装置,如图5所示,该装置包括:
获取模块,用于获取实例数据;
本体构建模块,用于根据实例数据的类别属性构建本体集合;
集合生成模块,用于根据挑选出的需要相互映射的第一本体o1和第二本体o2的实例集合和概念集合生成待映射实例对集合ip和待映射概念对集合cp;
实例映射模块,用于基于决策树模型对待映射实例对集合ip进行实例映射并获得实例映射结果,实例映射结果中包含等价实例对集合set1和不等价实例对集合set2;
概念映射模块,用于基于支持向量机模型对待映射概念对集合cp进行概念映射并获得概念映射结果,概念映射结果中包含等价概念对集合set3以及上下位概念对集合set4;
本体映射模块,用于根据实例映射结果和概念映射结果获得本体映射结果;
其中,实例数据为食材实例数据,本体集合为食材本体集合;或者,实例数据为食谱实例数据,本体集合为食谱本体集合。
该实施例中所揭示的食材/食谱知识图谱的本体映射装置,采用自底而上的本体构建方法,能够自主学习实例数据,运用决策树模型和支持向量机模型分别构建出本体的实例映射和概念映射,从而最终获得本体映射结果,用于知识图谱的搭建。
上述具体实施方式只是用于说明本发明的设计方法,并不能用来限定本发明的保护范围。对于在本发明技术方案的思想指导下的变形和转换,都应该归于本发明保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!