图像处理系统的制作方法
本发明涉及一种图像处理系统,其基于表示对象物的像的特征的模型图案,从输入形状信息检测对象物的像。
背景技术
以往,在从拍摄装置等取得的输入形状信息(输入图像)检测对象物的像的技术中,已知有如下技术:将使对象物的像模型化而得的模型图案(modelpattern)或模板等基准信息与输入形状信息进行匹配,当匹配度超过预定级别时,判断为检测到对象物。作为与这种技术相关的文献有专利文献1~3。
在专利文献1中记载了如下图像处理技术:通过将输入图像中的遮蔽区域以外的区域作为背景图像进行学习,由此分离前景图像和背景图像。在专利文献2中记载了如下技术:将用户生成的模板模型与从输入图像提取的特征量进行匹配,修正构成模板模型的代表点的位置。在专利文献3中记载了如下技术:为了检测图像中的对象物体,在对输入图像和学习用图像实施的图像处理的参数中搜索最优参数,基于该参数对学习用图像和输入图像实施图像处理。
在非专利文献1中记载了从输入图像提取边缘点作为构成模型图案的特征点的方法。边缘点是图像中亮度变化较大的点。一般而言,由于对象物的轮廓线的像的亮度梯度变大,通过将边缘点用作特征量,来进行对象物的轮廓线形状的匹配。例如,将从包含应检测的对象物的图像提取出的边缘点组存储为模型图案,基于从拍摄装置取得的输入图像提取的边缘点组与模型图案的边缘点组的匹配度来检测对象物。作为此类手法已知有广义霍夫变换等。另外,非专利文献2公开了在边缘点以外也提取构成模型图案的要素的方法。在非专利文献2中记载了从输入图像提取sift特征点的方法。
专利文献1:日本特开2011-209966号公报
专利文献2:日本特开2000-215319号公报
专利文献3:日本特开2014-137756号公报
非专利文献1:“コンピュータビジョン”(davida.forsyth(著),jeanponce(著),大北刚(翻译)共立出版)2007.1
非专利文献2:"objectrecognitionfromlocalscale-invariantfeatures",davidg.lowe,proc.oftheinternationalconferenceoncomputervision,corfu(sept.1999)
但是,还存在由输入图像生成的模型图案不能适当地表示对象物的特征的情况。例如,有时在输入图像中,除了像轮廓线等这样的适于检测的边缘点以外,还包含像轮廓线以外的浓淡变化等不适于检测的边缘点。因此,在由输入图像生成模型图案时,有时不应检测的部分也同时被检测。在检测铸件的部件的情况下,由于铸件外表存在轮廓线的个体差,铸件外表面的纹理也常被提取作为边缘点,从匹配精度的观点出发,优选检测机械加工了的部分的轮廓线。
不适于此种检测的要素可通过用户的操作而从模型图案中排除。例如,在由输入图像生成的模型图案中,可以在特定位置进行遮蔽,使得该遮蔽的范围内的要素不被包含为模型图案的要素。另外,构成模型图案的要素不仅能删除,还能新追加,并且还能变更已有的要素的位置。但是,用户通过手动作业来修正模型图案的作业很复杂,为了修正成能在匹配中使用的良好的模型图案而需要知识。希望通过学习能够由输入图像自动生成最优的模型图案。
关于该点,在专利文献1的技术中,通过用户指定人物的位置来学习前景图像和背景图像的分离,但是并不是学习生成模型图案的方法。另外,在专利文献2的方法中,自动修正构成模型图案的特征点的位置,但是并不包含判定被修正的位置是否正确的要素。专利文献3中的学习是制成用于检测对象物的辞典的作业,但是并不反映当构成上述的模型图案的要素不适当时要进行的修正。如上所述,以往技术不能反映在生成用于匹配的模型图案的过程中进行的修正,不能学习生成模型图案的方法。
技术实现要素:
本发明的目的在于提供一种图像处理系统,其学习在生成从输入形状信息取得的模型图案的过程中进行的修正,由此能够对其他输入形状信息自动生成适当的模型图案。
(1)本发明涉及一种图像处理系统(例如后述的图像处理系统1、201、301),其基于表示对象物(例如后述的对象物2)的像的特征的模型图案(例如后述的模型图案50),从输入形状信息(例如后述的输入图像5、cad数据、三次元点组数据)检测所述对象物的像,其中,所述图像处理系统具有:模型图案取得部(例如后述的模型图案取得部31),其取得从所述输入形状信息生成的所述模型图案;模型图案修正部(例如后述的操作面板35),其对由所述模型图案取得部取得的所述模型图案进行修正;机器学习器(例如后述的机器学习器40),其通过使用了学习数据集合的监督学习,生成用于从所述输入形状信息生成所述模型图案的生成信息,该学习数据集合是将由所述模型图案修正部修正而得的所述模型图案的修正信息与所述输入形状信息关联起来而得的,所述图像处理系统能够使用所输入的输入形状信息和所述生成信息来生成反映了学习结果的模型图案。
(2)在(1)记载的图像处理系统中可以是,所述输入形状信息是由视觉传感器(例如后述的视觉传感器11)拍摄的图像信息。
(3)在(1)记载的图像处理系统中可以是,所述输入形状信息是cad数据。
(4)在(1)记载的图像处理系统中可以是,所述输入形状信息是3维点组数据。
(5)在(1)到(4)任意一项记载的图像处理系统中可以是,所述修正信息是设定给构成所述模型图案的要素的权重信息,所述生成信息是用于对所述要素设定权重信息的信息,基于所述生成信息来设定从所述输入形状信息生成的所述要素的权重。
(6)在(1)到(4)任意一项记载的图像处理系统中可以是,所述修正信息是被指定为作为所述输入形状信息中的所述模型图案的区域的信息,所述生成信息是用于指定作为所述输入形状信息中的所述模型图案的区域的信息,从所述输入形状信息基于所述生成信息来指定所述模型图案的区域。
(7)在(1)到(4)任意一项记载的图像处理系统中可以是,所述修正信息是构成所述模型图案的要素的位置、姿势、明亮度等物理量,所述生成信息是用于设定所述要素的物理量的信息,基于所述生成信息设定从所述输入形状信息取得的所述要素的物理量。
(8)在(1)到(4)任意一项记载的图像处理系统中可以是,所述修正信息是表示所述模型图案本身的信息,所述生成信息是用于从所述输入形状信息生成所述模型图案的信息,从所述输入形状信息基于所述生成信息来生成所述模型图案。
(9)在(1)到(8)任意一项记载的图像处理系统中可以是,所述机器学习器从取得所述输入形状信息的多个输入形状信息取得部(例如后述的视觉传感器11、图像处理装置10)取得所述学习数据集合来进行监督学习。
(10)在(9)记载的图像处理系统中可以是,所述输入形状信息取得部是进行图像处理的图像处理装置(例如后述的图像处理装置10),各图像处理装置能够使用通过所述机器学习器的监督学习而得到的学习结果。
根据本发明的图像处理系统,通过学习在生成从输入形状信息取得的模型图案的过程中进行的修正,能够对其他输入形状信息自动生成适当的模型图案。
附图说明
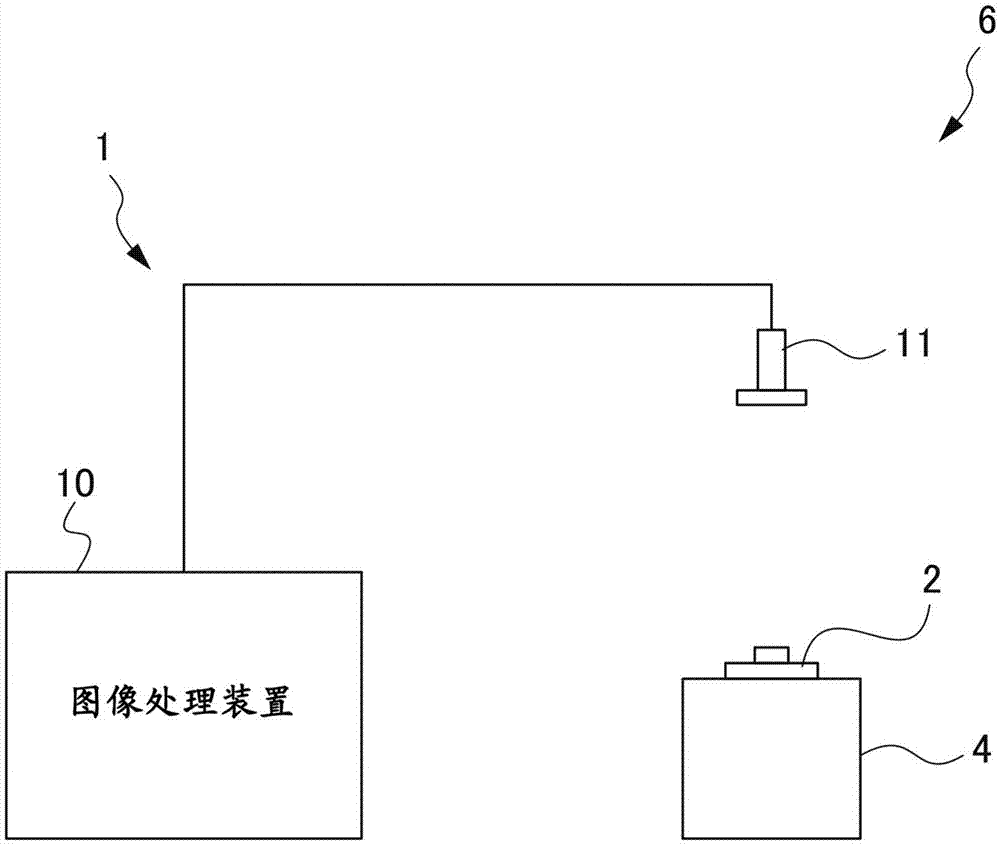
图1是表示固定了适用本实施方式的图像处理系统的视觉传感器位置的装置的例子的示意图。
图2是表示适用本实施方式的图像处理系统的视觉传感器位置移动的装置的例子的示意图。
图3是本实施方式的图像处理系统的功能框图。
图4表示制成模型图案的过程的流程图。
图5是表示在图像中指定模型图案指定区域的情况的图。
图6是表示由多个特征点构成的模型图案的图。
图7是表示删除模型图案的修正处理中不需要的特征点的情况的图。
图8是表示追加模型图案的修正处理中的特征点的情况的图。
图9是表示对模型图案的修正处理中的特征点的位置、姿势以及明亮度等物理量进行修正的情况的图。
图10是表示模型图案的学习过程的流程图。
图11是表示对整体图像应用遮蔽来删除不需要的特征点的情况的图。
图12是示意表示本发明的一实施方式涉及的连接有多个视觉传感器的图像处理系统的例子的图。
图13是示意表示本发明的一实施方式涉及的连接有多个图像处理装置的图像处理系统的例子的图。
符号说明
1、201、301-图像处理系统
5-输入图像(输入形状信息)
10-图像处理装置(输入图像取得部)
11-视觉传感器(输入图像取得部)
31-模型图案取得部
35-操作面板(模型图案修正部)
40-机器学习器
50-模型图案
具体实施方式
以下,参照附图,说明本发明的优选的实施方式。本发明的一个实施方式涉及的图像处理系统1是基于表示对象物2的像的特征的模型图案50,从输入图像5检测所述对象物的像的系统。首先,针对适用本实施方式的图像处理系统1的装置,说明2个例子。
图1是表示固定了适用本实施方式的图像处理系统1的视觉传感器11的位置的装置6的例子的示意图。如图1所示,对象物2被设置在工作台4上。视觉传感器11是用于拍摄对象物2的照相机。视觉传感器11通过支承单元(省略图示)固定在能够拍摄对象物2的位置上。视觉传感器11取得的图像信息被发送到图像处理装置10。图像处理装置10基于从视觉传感器11接收到的输入图像5(图5参照),通过后述的图像处理,检测对象物2的像。
在图1中,说明了视觉传感器11的位置被固定的例子。接着,参照图2说明视觉传感器11的位置移动的情况。图2是表示适用本实施方式的图像处理系统1的视觉传感器11的位置移动的装置7的例子的示意图。另外,有时对与参照图1说明的装置6的结构共通或者相同的结构附加相同的符号并省略该说明。
图2表示在前端安装有机械手21的手臂型机器人20。本例的视觉传感器11被固定在成为机器人20的手指的机械手21上。机械手21是通过机器人20或自身的机构进行移动的可动部。因此,视觉传感器11的位置也会移动。进行图像处理的图像处理装置10构成为能够与控制机器人20的运动等的机器人控制装置25进行通信,从而能够在图像处理装置10与机器人20之间彼此进行信息的交换。图像处理装置10在考虑机器人20以及机械手21的移动或状态的同时,基于来自视觉传感器11的输入图像5(图5参照),通过后述的图像处理,进行对象物2的像的检测。
如上述说明,本实施方式的图像处理系统1均可适用于视觉传感器11的位置为固定型的装置6以及视觉传感器11的位置为可动型的装置7中。接着,对图像处理系统1进行的图像处理进行说明。图3是本实施方式的图像处理系统1的功能框图。
如图3所示,本实施方式的图像处理系统1具备:进行图像处理的计算机即图像处理装置10、取得输入图像5的视觉传感器11、操作者对由输入图像5生成的模型图案50进行修正等的操作面板(操作部)35、显示输入图像5或模型图案50等的图像信息的显示装置(输出部)36。
图像处理装置10通过cpu和具备存储预定软件的存储介质等的计算机来实现。本实施方式的图像处理装置10包括模型图案取得部31、状态观测部32、存储部33、机器学习器40。
模型图案取得部31取得从视觉传感器11取得的输入图像5生成的模型图案50以及与模型图案50的修正相关的修正信息。状态观测部32取得输入图像5作为输入数据。本实施方式的修正信息是取得操作者进行修正时的操作者生成信息作为修正信息。
存储部33存储与图像处理装置10相关的各种信息。本实施方式的存储部33存储将输入图像5与模型图案50以及修正信息关联起来而得的多个组信息作为学习数据。以下,将存储部33中存储的学习数据的集合称为学习数据集来进行说明。
机器学习器40基于存储部33中存储的学习数据集进行机器学习取得学习模型,使得输出用于从输入图像5适当生成模型图案50的生成信息。通过让机器学习器40对输入和输出的关系进行学习,使得取出的输出与成为推定对象的生成信息一致,由此能够根据输入图像5推定生成信息。在本实施方式中,根据由包含多层神经网络的神经网络构建的学习模型来进行机器学习。由包含输入层、输出层、中间层的神经网络构建的学习模型能够使用适当的方式。例如,能够适用cnn(convolutionalneuralnetwork,卷积神经网络)。
在本实施方式中,将对象物2、视觉传感器11以及图像处理装置10作为环境,将操作者使用操作面板35修正模型图案50时的修正信息和输入图像5的对(组)作为正解数据(训练数据)。修正信息是构成修正后的模型图案50、生成模型图案50时指定的模型图案指定区域60、模型图案50的要素(后述的特征点)的物理量的修正量或权重等。机器学习器40通过使用学习数据的集合进行机器学习,取得从输入图像(输入数据)映射目标的数据(生成信息)的函数。
接着,对制成模型图案50的例子进行说明。图4是表示制成模型图案50的过程的流程图。图5是表示在图像中指定模型图案指定区域60的情况的图。图6表示由多个特征点p_i构成的模型图案50的图。
如图5所示,将想要示教的对象物2作为模型图案50配置于视觉传感器11的视野内,拍摄该对象物2的图像,取得包含对象物2的输入图像5(步骤s101)。此时,视觉传感器11与对象物2的位置关系优选为与实际使用时检测对象物2时的位置关系相同的位置关系。
在拍摄的图像中,将反映了对象物2的区域指定为模型图案50的区域(步骤s102)。以下,将在该步骤s102中指定的区域称为模型图案指定区域60。本实施方式的模型图案指定区域60以包围对象物2的方式指定成矩形或圆形。如后所述,将该模型图案指定区域60存储为修正信息(操作者生成信息),并能够用于机器学习中。
接着,进行特征点的提取(步骤s103)。特征点构成模型图案50。从模型图案指定区域60提取多个特征点p_i(i=1~np)。能够使用各种方法作为特征点p_i的提取方法。在本实施方式中,将图像中亮度梯度较大的点且为了取得对象物的轮廓形状而能够使用的边缘点用作特征点p_i。
边缘点的物理量具有该边缘点的位置、亮度梯度方向、亮度梯度的大小等。若将边缘点的亮度梯度的方向定义为特征点的姿势,则能够与位置一起定义特征点的位置姿势。存储边缘点的物理量即边缘点的位置、姿势(亮度梯度的方向)、亮度梯度的大小作为特征点的物理量。
定义模型图案坐标系51,基于模型图案坐标系51以及原点o,以特征点p_i的姿势矢量v_pi或位置矢量t_pi等来进行表现。就模型图案坐标系51中设定的原点o而言,例如将构成模型图案50的全部的特征点p_i的重心定义为原点o。另外,原点o的定义方法能够采用从特征点p_i选择任意1点等适当的方法。另外,使用模型图案坐标系51的方法也是一例,能够使用其他方法表示特征点p_i的位置或姿势。另外,模型图案坐标系51的轴方向(姿势)还可以例如为从构成模型图案50的特征点p_i选择任意2点,将从其中一个朝向另一个的方向定义为x轴方向,将与该x轴方向正交的方向定义为y轴方向。另外,在制成模型图案50的图像中,能够定义成图像坐标系和模型图案坐标系51为平行。如此,能够根据情况来适当变更模型图案坐标系51以及原点o的设定。另外,提取边缘点作为特征点的方法本身是记载于非专利文献1的公知技术,省略其他详细说明。
接着,基于提取的特征点p_i的物理量进行模型图案50的生成(步骤s104)。提取的特征点p_i的物理量作为构成模型图案50的特征点p_i存储于存储部33。在本实施方式中,在模型图案指定区域60内定义模型图案坐标系51,根据用图像坐标系70(图5参照)表现的值,通过用模型图案坐标系51(参照图6)表现的值来存储特征点p_i的位置或姿势。
需要修正模型图案50时,进行模型图案的修正(步骤s105)。该步骤s105中模型图案50的修正是操作者进行的。该步骤s105中被操作的信息作为修正信息存储于存储部33。另外,在未进行修正的情况下,也可以将未进行修正的信息作为修正信息进行存储。
接着,对在步骤s105中存储的修正信息的例子进行说明。首先,对删除不需要的特征点p_i的例子进行说明。在以下的说明中,将不需要的特征点p_i作为不需要的特征点d进行说明。
图7是表示将模型图案50的修正处理中不需要的特征点d进行了遮蔽55的情况的图。如图7所示,有在模型图案50的生成过程中提取不需要的特征点d的情况。操作者操作操作面板35使得以在显示装置36的操作画面上包含不需要的特征点d的方式施加遮蔽55。然后,对施加遮蔽55的区域内的特征点d(特征点p_i)进行删除。由删除了特征点d的多个特征点p_i构成的模型图案50作为修正后的模型图案50被存储于存储部33中。在本方法中,能够将使施加遮蔽55的区域为0、使未施加遮蔽55的区域为1的遮蔽图像存储为修正信息(训练数据)。另外,可以将删除不需要的特征点d之后的模型图案50自身作为修正信息(训练数据)。
接着,说明将对构成模型图案50的多个特征点p_i的权重进行变更而得的信息作为修正信息用于机器学习的例子。表示特征点p_i的权重的权重信息是能够在匹配模型图案50的特征点p_i和输入图像5的特征点时的计算一致度中使用的信息。例如,若将图7中特征点d的权重设为0,则可以将该特征点d视为删除的特征点,从构成模型图案50的特征点p_i中删除不需要的特征点d可以得到付与权重。默认将模型图案50的特征点p_i的权重设为1,操作者通过遮蔽55来指定变更权重的位置等能够变更权重。在本方法中,能够存储将与权重成比例的整数值作为各像素值的权重图像、或者赋予权重后的模型图案50作为修正信息。
接着,说明对模型图案50追加必要的特征点p_i的例子。在以下的说明中说明将追加的特征点p_i作为要追加的特征点a。图8是表示追加模型图案50的修正处理中的特征点a的情况的图。如图8所示,存在未提取出应提取的特征点p_i的情况,还存在想要追加特征点a的情况。
操作者在操作画面上对想要追加特征点p_i的位置配置线段56(参照图8的点划线)。在该线段56上以适当的间隔配置特征点a。并且,在存储部33中存储追加了特征点a的模型图案50。在该方法中,能够将追加了的线段56、追加了的特征点a以及追加了特征点a而得的模型图案50等作为修正信息进行存储。
接着,对修正模型图案50的特征点p_i的位置、姿势以及明亮度等物理量的例子进行说明。图9是表示模型图案50的修正处理中的修正特征点p_i的位置、姿势以及明亮度等物理量的情况的图。在以下的说明中,将修正后的特征点p_i作为修正后的特征点c进行说明。另外,在图9中,以虚线表示修正对象的特征点p_i。
如图9所示,存在想要修正特征点p_i的位置、姿势、明亮度的情况。操作者在操作画面上修正特征点p_i的位置。并且,将修正对象的特征点p_i被置换到修正后的特征点c的模型图案50作为新的模型图案50存储于存储部33。在此情况下,可以将修正后的特征点c、反映了位置修正后的模型图案50等作为修正信息进行存储。
以上,说明了作为学习数据被存储于存储部33的修正信息的例子。接着,对本实施方式的图像处理装置10进行的机器学习的处理进行说明。图10是表示模型图案50的学习的过程的流程图。
取得输入图像5(步骤s201)。这里取得的输入图像5可以是模型图案指定区域60内的部分图像。取得的输入图像5存储于存储部33中。
对模型图案50进行示教,根据需要进行模型图案50的修正(步骤202)。通过步骤s201和步骤s202的处理,能够取得1个输入数据即输入图像5与正解数据即修正信息的对(组),存储这些信息。为了取得n个学习数据的对,重复n次步骤s201和步骤s202的处理。通过执行n次步骤s201、步骤s202的处理,取得多个(n个)学习数据。这些n个学习数据的集合成为学习数据集。
使用n个学习数据的集合即学习数据集进行学习(步骤s203)。为了生成模型图案50,取得输入图像5(步骤s204)。向机器学习器40输入新的输入图像,生成模型图案生成信息(s205)。生成从输入图像5和模型图案生成信息反映了学习结果的模型图案50(s206)。
接着,作为步骤s203的处理的一例,说明将操作者使用遮蔽55的修正处理作为修正信息进行学习的情况。通过以下的过程进行学习处理。
(1)从取得的n个学习数据集中取出1个学习数据。
(2)接着,从学习数据的输入图像5中,切下包含于修正信息中的模型图案指定区域60的图像。
(3)将输入图像5的各像素值输入到学习模型中,生成遮蔽55的图像。
(4)计算修正信息(学习数据)的遮蔽图像与所生成的遮蔽55的图像之间的误差。
(5)在学习模型中通过误差反向传播法反向传播误差,更新学习模型的参数。
在(1)~(5)的处理中,将输入图像作为输入数据,使用将编辑后的遮蔽55的图像作为标签而得的训练数据,来进行基于机器学习器40的机器学习。
接着,对使用学习模型的模型图案50的生成进行说明,该学习模型对使用遮蔽55的修正处理进行学习。该处理与步骤s204、s205的处理相应,通过以下的流程进行。
(1)操作者在输入图像5上指定模型图案指定区域60。
(2)从模型图案指定区域60切下部分图像。
(3)以通常的处理从部分图像生成模型图案50。
(4)将部分图像(输入图像)输入到学习模型中,得到适合于部分图像的遮蔽55的图像(生成信息)。
(5)将遮蔽图像适用于所生成的模型图案50中,删除应用遮蔽55的范围的特征点d。
经过(1)~(5)的处理,若将输入图像5输入到进行学习的机器学习器40,则自动输出反映了学习结果的遮蔽55的图像,由此自动删除遮蔽55的范围的不需要的特征点d。由此,生成最终反映了学习结果的模型图案50。
图11是表示将遮蔽55应用于整体图像来删除不需要的特征点d’的情况的图。如图11所示,能够省略切下部分图像的处理,使用输入图像5的整体。在该方法中,也可以以遮蔽55应用于模型图案指定区域60以外的方式,向输入图像5整体实施处理。此时的处理通过以下的过程进行。
(1)将输入图像5输入到学习模型,得到遮蔽图像。
(2)以通常的处理从输入图像5生成模型图案50。
(3)将遮蔽55的图像适用于生成的模型图案50中,施加有遮蔽55的特征点d’被删除。
经过(1)~(3)的处理,自动删除不需要的特征点d’,生成最终反映了学习结果的模型图案50。
根据上述实施方式,达到以下的效果。
图像处理系统1具备:模型图案取得部31,其取得从输入图像5生成的模型图案50;操作面板(模型图案修正部)35,其修正由模型图案取得部31取得的模型图案50;机器学习器40,通过使用了学习数据集合的监督学习,来生成用于从输入图像5生成模型图案50的模型图案生成信息,该学习数据集合是将由操作面板35修正而得的模型图案50的修正信息与输入图像5关联起来而得的,图像处理系统1能够使用新输入的输入图像5和模型图案生成信息来生成反映了学习结果的模型图案。由此,为了针对各种的输入图像5取得适当的模型图案50,学习操作者进行的作业工序,即使是未知的图像在用户没有操作的情况下,也能够取得反映了学习结果的适当的模型图案50。
另外,在本实施方式中,输入图像5是由视觉传感器11拍摄的图像信息。由此,通过使用由视觉传感器11拍摄的实际的输入图像,能够进一步取得与实际作业相对应的学习模型。
另外,在本实施方式中,修正信息是设定给构成模型图案50的特征点(要素)p_i的权重信息,模型图案生成信息可以作为用于将权重信息设定给构成模型图案50的特征点p_i的信息。此时,基于生成信息来设定从输入图像5生成的构成模型图案50的特征点p_i的权重。由此,对多个特征点p_i中哪个特征点p_i重要或者不需要进行学习,即使使用了在学习中没有使用的其他图像的情况下,在操作者不进行操作的情况下也能够取得删除了不需要的特征点d的模型图案50。
另外,在本实施方式中,修正信息是指定为作为输入图像5中的模型图案50的区域的信息,模型图案生成信息可以作为用于指定作为输入图像5中的模型图案50的区域的信息。此时,从输入图像5基于模型图案生成信息来指定模型图案的区域。由此,对在输入图像5中应以何种程度的大小来设定用于提取模型图案50的范围进行学习,在操作者不进行操作的情况下自动指定用于提取模型图案50的模型图案指定区域60,能够以适当的范围提取特征点p_i,能够生成适当的模型图案50。
另外,在本实施方式中,修正信息是构成模型图案50的特征点p_i的位置、姿势、明亮度等物理量,模型图案生成信息能够作为用于设定构成模型图案50的特征点p_i的物理量的信息。此时,基于模型图案生成信息来设定从输入图像5取得的构成模型图案50的特征点p_i的物理量。由此,学习操作者对特征点p_i的位置、姿势、明亮度等物理量进行的修正。另外,将为了追加特征点a而编辑的图形作为训练数据进行机器学习,若将输入图像5新输入到机器学习器40,则输出反映了在必要的部分追加特征点a的适当的图形的模型图案50。
另外,在本实施方式中,修正信息是表示模型图案50本身的信息,模型图案生成信息能够设为用于从输入图像5生成模型图案50的信息(例如,函数或算法)。此时,基于模型图案生成信息,从输入图像5生成最终的模型图案50。由此,机器学习器40将输入图像5作为输入将由操作者最终生成的模型图案50作为训练数据来进行学习,由此在操作者不进行操作的情况下将输入图像5输入到机器学习器40,由此能够自动生成适当的模型图案50。
在上述实施方式中,说明了使用边缘点作为构成模型图案50的特征点的例子,但是并不限定于该结构。接着,说明使用与上述实施方式不同的方法作为生成模型图案50的方法的情况。
首先,对通过边缘点以外的方法提取特征点的方法进行说明。特征点还能够通过边缘点以外的各种的方法检测。例如,可以使用像sift(scale-invariantfeaturetransform,尺度不变特征转换)那样的特征点。另外,从图像提取sift特征点的方法本身是记载于非专利文献2的公知技术,省略其详细说明。
另外,可以通过以符合映现到图像的对象物2的轮廓线的方式配置线段、矩形、圆等几何图形,来制成模型图案50。此时,可以通过在构成轮廓线的几何图形上以适当的间隔设置特征点,来制成模型图案50。另外,模型图案能够使用由各像素构成的图像。
在上述实施方式中,将由视觉传感器(照相机)11检测到的图像作为输入图像5,但是也可以是通过其他手段取得的图像。例如,还能够在输入图像5中使用cad数据。在为2维cad数据时,能够通过与使用上述的几何图形的方法相同的方法来制成模型图案。另外,在为3维cad数据时,可以将以cad数据表现的对象物2的形状投影到图像上,从投影的像中提取特征点。
如下述进行使用cad数据的模型图案50的制成。
(1)定义在视觉传感器(照相机)11拍摄的图像(拍摄面)上配置原点o的局部坐标系。
(2)通过预先校准视觉传感器(照相机)11,能够将以局部坐标系表现的3维点变换成所拍摄的图像上的2维点。
(3)在局部坐标系中虚拟地配置表现为cad数据的对象物2。用局部坐标系来表现所配置的cad数据。视觉传感器(照相机)11和对象物2的相对关系设定成与实际检测对象物时的相对关系大致相同。
(4)以预定间隔从轮廓线取得轮廓线上的3维点组。若有必要,则从cad数据中指定用作模型图案的轮廓线。
(5)将3维点组投影到用视觉传感器(照相机)11拍摄的图像上,求出图像坐标系上的2维点组。若在cad数据上指定明暗的方向,则还可以附加亮度梯度的方向。在此,明暗的方向表示以轮廓线作为边界的两个区域中哪一个是亮的。
(6)变换成用模型坐标系来表现所求出的图像坐标系上的2维点组,作为特征点而存储于存储部33中。
如以上说明,输入图像5可以是基于cad数据生成的图像信息。如此,可以对输入图像5使用各种方式。例如,还可以使用距离图像或3维点组数据作为输入图像5。
另外,在上述实施方式中,在例子中说明了由连接有单独的视觉传感器11的图像处理装置10构成的图像处理系统1,但是并不限定于该构成。接着,对与上述实施方式不同的构成的图像处理系统进行说明。另外,在以下的例子中,针对与上述实施方式相同的结构添加相同的符号,并省略其详细的说明。
图12是示意性地表示本发明的一实施方式涉及的连接有多个视觉传感器11的图像处理系统201的例子的图。在图12中,n个视觉传感器11作为输入图像取得部经由网络总线110连接于单元控制器100上。单元控制器100具有与上述的图像处理装置10相同的功能,取得分别从n个视觉传感器11取得的输入图像5。在图12中省略图示,1个或者多个操作部与网络总线110相连,经由该操作部能够修正模型图案50。通过操作部的操作而生成的修正信息与对应的输入图像5形成组,作为学习数据存储于单元控制器100中。
如此,在图12表示的图像处理系统201中,机器学习器40取得单元控制器100中存储的学习数据集合来进行监督学习。在本例中还可以逐次在线处理学习处理。
图13是示意性地表示本发明的一实施方式涉及的连接有多个图像处理装置10的图像处理系统301的例子的图。在图13中,m个图像处理装置10作为输入图像取得部经由网络总线110与单元控制器100相连。图像处理装置10分别连接1个或多个视觉传感器11。图像处理系统301整体一共具备n个视觉传感器11。
如此,在图13示出的例子中,图像处理装置10分别取得的修正信息与输入图像5一起自动或者手动地被发送到单元控制器100。单元控制器100将从多个图像处理装置10发送的学习数据集合存储为学习数据集,进行机器学习,构建学习模型。能够在各图像处理装置10中使用学习模型。
图13所示的图像处理系统301具备作为输入图像取得部的多个图像处理装置10,各图像处理装置10能够彼此使用由机器学习器40的监督学习得到的学习结果。在本例中也可以逐次在线处理学习处理。
以上,对本发明的优选实施方式进行了说明,但是本发明并不局限于上述的实施方式,还可以进行适当变更。
例如,可以将针对模型图案50的修正而进行的操作者操作本身记录为修正信息。此时,机器学习器40将用于编辑模型图案50的操作序列作为训练数据进行学习,若将输入图像5输入到进行了学习的机器学习器40,则输出编辑模型图案50的操作序列。
在上述实施方式中,将由特征点的集合构成的模型图案作为例子进行说明,也可以将从输入图像切下的部分图像作为模型图案,还可以将线段等图形组合而成图案作为模型图案。可以用各种方法从输入形状信息来生成,模型图案的生成方法还可以采用适当的方法。
在上述实施方式中,作为模型图案修正部,以操作面板35涉及的操作者的修正为例进行了说明,但是并不局限于该构成。还可以将匹配的结果、自动进行的修正处理作为修正信息来进行机器学习。此时,进行修正处理的软件或设备成为模型图案修正部。
在上述实施方式中,主要说明了使用输入图像5作为输入形状信息的例子,但是输入形状信息也可以是cad数据或3维点组数据。即,未必一定是图像本身,只要是表示形状的信息,即使不通过图像也能适用本发明。
在上述实施方式中,为了便于说明,而将图像处理系统1、201、301与图像处理装置10相区别来进行说明,但是并不限于系统或装置的名称,即使是单独的图像处理装置,只要具备本发明的要件,则也相当于图像处理系统。
- 还没有人留言评论。精彩留言会获得点赞!